使用Isaac Gym來強化學習mycobot抓取任務
2023-04-11 14:57:12 9692
9692 
什么是深度強化學習? 眾所周知,人類擅長解決各種挑戰性的問題,從低級的運動控制(如:步行、跑步、打網球)到高級的認知任務。
2023-07-01 10:29:502121 
Facebook近日推出ReAgent強化學習(reinforcement learning)工具包,首次通過收集離線反饋(offline feedback)來實現策略評估(policy evaluation)。
2019-10-19 09:38:411956 的幫助,它提到了在MCU配置下查看內存映射,但我似乎找不到這個對話框,也沒有提到如何導航到這個對話框。還有其他人遇到過這個問題嗎?任何人都可以幫我解決這個問題嗎?謝謝 #STVD寫保護模擬器以上來自于谷歌
2018-11-15 10:56:49
海,我在verilog中真的很新。當我模擬我的程序時,我得到了錯誤:模擬器:904 - 無法刪除以前的模擬文件isim / cache_memorytest_isim_beh.exe.sim
2020-04-03 08:47:23
設置
Log message: A03d00/JSAPP
當你看到不斷更新的日志時,你會不會崩潰
因為 No-filters 模式下模擬器會輸出系統所有日志信息,這個模式在開發中并不使用,可用
2025-05-23 10:46:39
Morello指令模擬器(Morello IE)是一個軟件開發人員和研究人員想要試驗Morello體系結構的工具。它允許您在非Morello環境中的AArch64Linux系統上運行用戶空間
2023-08-08 07:55:41
μVision調試器支持用于實施用戶定義外設的模擬器接口。
該接口稱為高級通用模擬器接口(AGSI)。
AGSI提供了一種靈活、簡單的方法,可將新的用戶定義的外設直接添加到μVision。
它提供了
2023-09-04 08:14:11
強化學習的另一種策略(二)
2019-04-03 12:10:44
汽車駕駛模擬器控制系統的原理是什么?汽車駕駛模擬器控制系統的功能有哪些?怎樣去設計一種汽車駕駛模擬器控制系統?
2021-05-17 06:36:41
一:深度學習DeepLearning實戰時間地點:1 月 15日— 1 月18 日二:深度強化學習核心技術實戰時間地點: 1 月 27 日— 1 月30 日(第一天報到 授課三天;提前環境部署 電腦
2021-01-10 13:42:26
`飛行模擬器,顧名思義也就是模擬飛行器飛行的設備。用來應對真實世界在飛行過程中會遇到的空氣動力、氣象、地理環境、飛行系統等,并且將仿真操控和飛行感官反饋給用戶。飛行模擬器對飛機駕駛艙各個部位進行了
2020-09-07 17:20:34
模擬器作為嵌入式系統研究的基礎研發工具,可輔助系統體系結構調優、軟硬件協同設計。本文實現了具有良好配置性及可擴展性的ArmSim 模擬器,該模擬器是針對ARM 處理器的全
2009-08-10 10:12:22 34
34 汽車駕駛模擬器新一代實時場景系統的開發:本論文總結了汽車駕駛模擬器新一代實時場景系統的設計和開發工作。汽車駕駛模擬器新一代實時場景系統是汽車駕駛模擬器的重要組
2009-08-23 23:10:3355 DSP完成的實時信號模擬器
前言
在通信、雷達等數字信號處理系統的設計中,信號模擬器發揮著至關重要的作用。模擬器用來模擬實際工作過程中信
2010-01-07 10:33:011951 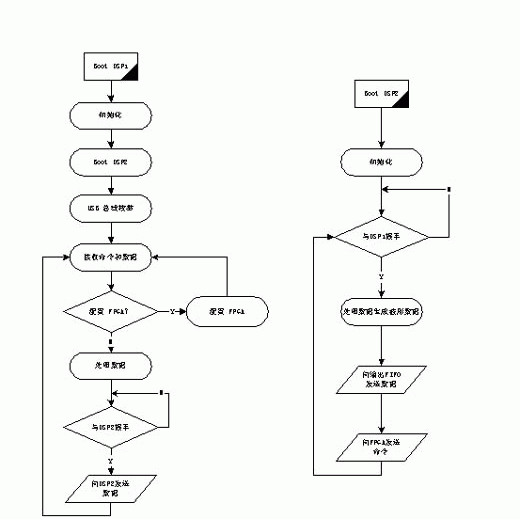
基于FPGA嵌入式系統的雷達信號模擬器
在現代雷達系統的研制和調試過程中,對雷達性能和指標的測試是一個重要環節,在這個環節中,利用模擬目標信號的方式與外場
2010-02-06 09:25:451030 
寬帶短波信道模擬器是一種運用仿真技術對真實的短波信道進行模擬的儀器。首先指出數字下變頻在寬帶短波信道模擬器中的作用。然后,闡述了數字下變頻中的數控振蕩器、CIC 濾波器
2011-09-15 18:30:212882 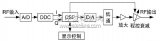
采用該方法可對精密測距模擬器的系統延時時間進行準確測量,從而有效地解決精密測距模擬器系統延時定標問題,以滿足實際需求。
2011-11-11 14:28:4230 強化學習在RoboCup帶球任務中的應用_劉飛
2017-03-14 08:00:000 Xilinx基于QEMU系統模擬器Xilinx/QEMU可用于模擬運行Zynq Linux的運行與調試。
2018-07-04 07:50:0010066 與監督機器學習不同,在強化學習中,研究人員通過讓一個代理與環境交互來訓練模型。當代理的行為產生期望的結果時,它得到正反饋。例如,代理人獲得一個點數或贏得一場比賽的獎勵。簡單地說,研究人員加強了代理人的良好行為。
2018-07-13 09:33:0025157 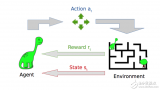
深度強化學習DRL自提出以來, 已在理論和應用方面均取得了顯著的成果。尤其是谷歌DeepMind團隊基于深度強化學習DRL研發的AlphaGo,將深度強化學習DRL成推上新的熱點和高度,成為人工智能歷史上一個新的里程碑。因此,深度強化學習DRL非常值得研究。
2018-06-29 18:36:0028671 薩頓在專訪中(再次)科普了強化學習、深度強化學習,并談到了這項技術的潛力,以及接下來的發展方向:預測學習
2017-12-27 09:07:1511877 本文提出了一種LCS和LS-SVM相結合的多機器人強化學習方法,LS-SVM獲得的最優學習策略作為LCS的初始規則集。LCS通過與環境的交互,能更快發現指導多機器人強化學習的規則,為強化學習系統
2018-01-09 14:43:490 在風儲配置給定前提下,研究風電與儲能系統如何有機合作的問題。核心在于風電與儲能組成混合系統參與電力交易,通過合作提升其市場競爭的能力。針對現有研究的不足,在具有過程化樣本的前提下,引入強化學習算法
2018-01-27 10:20:502 傳統上,強化學習在人工智能領域占據著一個合適的地位。但強化學習在過去幾年已開始在很多人工智能計劃中發揮更大的作用。
2018-03-03 14:16:564677 ,能夠實現對處理器設計的驗證。處理器體系結構模擬器在處理器研究和設計領域具有重要作用。 處理器體系結構模擬器按照模擬層次可以劃分為系統級模擬器和用戶級模擬器。系統級模擬器支持操作系統運行,并且允許用戶在操作系
2018-03-12 16:13:220 讓我們在強化學習社區感興趣的問題上應用隨機搜索。深度強化學習領域一直把大量時間和精力用于由OpenAI維護的、基于MuJoCo模擬器的一套基準測試中。這里,最優控制問題指的是讓一個有腿機器人在一個
2018-04-01 09:35:004894 
用強化學習方法教機器人(模擬器里的智能體),能學會的動作花樣繁多,細致到拿東西、豪放到奔跑都能搞定,還可以給機器人設置一個明確的目的。但是,總難免上演一些羞恥或驚喜play。
2018-04-13 11:00:3210302 強化學習是智能系統從環境到行為映射的學習,以使獎勵信號(強化信號)函數值最大,強化學習不同于連接主義學習中的監督學習,主要表現在教師信號上,強化學習中由環境提供的強化信號是對產生動作的好壞作一種評價
2018-05-30 06:53:001741 當我們使用虛擬的計算機屏幕和隨機選擇的圖像來模擬一個非常相似的測試時,我們發現,我們的“元強化學習智能體”(meta-RL agent)似乎是以類似于Harlow實驗中的動物的方式在學習,甚至在被顯示以前從未見過的全新圖像時也是如此。
2018-05-16 09:03:395238 
Atmel 小貼士 vi模擬器的使用
2018-07-11 00:17:004837 自動駕駛汽車首先是人工智能問題,而強化學習是機器學習的一個重要分支,是多學科多領域交叉的一個產物。今天人工智能頭條給大家介紹強化學習在自動駕駛的一個應用案例,無需3D地圖也無需規則,讓汽車從零開始在二十分鐘內學會自動駕駛。
2018-07-10 09:00:295635 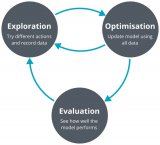
前段時間,OpenAI的游戲機器人在Dota2的比賽中贏了人類的5人小組,取得了團隊勝利,是強化學習攻克的又一游戲里程碑。
2018-07-13 08:56:015357 
強化學習是人工智能基本的子領域之一,在強化學習的框架中,智能體通過與環境互動,來學習采取何種動作能使其在給定環境中的長期獎勵最大化,就像在上述的棋盤游戲寓言中,你通過與棋盤的互動來學習。
2018-07-15 10:56:3718466 
這些具有一定難度的任務 OpenAI 自己也在研究,他們認為這是深度強化學習發展到新時代之后可以作為新標桿的算法測試任務,而且也歡迎其它機構與學校的研究人員一同研究這些任務,把深度強化學習的表現推上新的臺階。
2018-08-03 14:27:265366 結合 DL 與 RL 的深度強化學習(Deep Reinforcement Learning, DRL)迅速成為人工智能界的焦點。
2018-08-09 10:12:436868 強化學習作為一種常用的訓練智能體的方法,能夠完成很多復雜的任務。在強化學習中,智能體的策略是通過將獎勵函數最大化訓練的。獎勵在智能體之外,各個環境中的獎勵各不相同。深度學習的成功大多是有密集并且有效的獎勵函數,例如電子游戲中不斷增加的“分數”。
2018-08-18 11:38:574166 強化學習(RL)研究在過去幾年取得了許多重大進展。強化學習的進步使得 AI 智能體能夠在一些游戲上超過人類,值得關注的例子包括 DeepMind 攻破 Atari 游戲的 DQN,在圍棋中獲得矚目的 AlphaGo 和 AlphaGo Zero,以及在 Dota2 對戰人類職業玩家的Open AI Five。
2018-08-31 09:20:494363 強化學習是一種非常重要 AI 技術,它能使用獎勵(或懲罰)來驅動智能體(agents)朝著特定目標前進,比如它訓練的 AI 系統 AlphaGo 擊敗了頂尖圍棋選手,它也是 DeepMind 的深度
2018-09-03 14:06:303344 之前接觸的強化學習算法都是單個智能體的強化學習算法,但是也有很多重要的應用場景牽涉到多個智能體之間的交互。
2018-11-02 16:18:1522830 本文作者通過簡單的方式構建了強化學習模型來訓練無人車算法,可以為初學者提供快速入門的經驗。
2018-11-12 14:47:395433 電池模擬器的作用是取代現有的電池,模擬真實電池的輸出狀態和電池的充放電特性,并可以按用戶的需要,隨時改變多種條件,快速驗證待測設備在不同電池條件下的響應
2018-12-21 10:06:4417860 OpenAI 近期發布了一個新的訓練環境 CoinRun,它提供了一個度量智能體將其學習經驗活學活用到新情況的能力指標,而且還可以解決一項長期存在于強化學習中的疑難問題——即使是廣受贊譽的強化算法在訓練過程中也總是沒有運用監督學習的技術。
2019-01-01 09:22:003042 
強化學習(RL)能通過獎勵或懲罰使智能體實現目標,并將它們學習到的經驗轉移到新環境中。
2018-12-24 09:29:563716 在一些情況下,我們會用策略函數(policy, 總得分,也就是搭建的網絡在測試集上的精度(accuracy),通過強化學習(Reinforcement Learning)這種通用黑盒算法來優化。然而,因為強化學習本身具有數據利用率低的特點,這個優化的過程往往需要大量的計算資源。
2019-01-28 09:54:225819 首先將多個 CPU核心 與 單個GPU 相關聯。多個模擬器在CPU內核上以并行進程運行,并且這些進程以同步方式執行環境步驟。在每個步驟中,將所有單獨的觀察結果收集到批處理中以進行推理,在提交最后一個
2019-02-13 09:31:193234 
Google AI 與 DeepMind 合作推出深度規劃網絡 (PlaNet),這是一個純粹基于模型的智能體,能從圖像輸入中學習世界模型,完成多項規劃任務,數據效率平均提升50倍,強化學習又一突破。
2019-02-17 09:30:283940 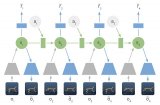
仿真模擬器可以模擬在目標終端上運行bada應用的效果.讓我們能夠在發布到真機上運行前在本地模擬環境中對我們的應用進行充分調試,測試.仿真模擬器使用本地調試器,使我們能夠很好
2019-04-02 14:35:111053 近日,Reddit一位網友根據近期OpenAI Five、AlphaStar的表現,提出“深度強化學習是否已經到達盡頭”的問題。
2019-05-10 16:34:592987 該強化學習環境的核心是一種先進的足球游戲模擬,稱為“足球引擎”,它基于一個足球游戲版本經大量修改而成。根據兩支對方球隊的輸入動作,模擬了足球比賽中的常見事件和場景,包括進球、犯規、角球和點球、越位等。
2019-06-15 10:33:184825 強化學習非常適合實現自主決策,相比之下監督學習與無監督學習技術則無法獨立完成此項工作。
2019-12-10 14:34:571666 本文檔的主要內容詳細介紹的是深度強化學習的筆記資料免費下載。
2020-03-10 08:00:000 強化學習(RL)是現代人工智能領域中最熱門的研究主題之一,其普及度還在不斷增長。 讓我們看一下開始學習RL需要了解的5件事。
2020-05-04 18:14:004154 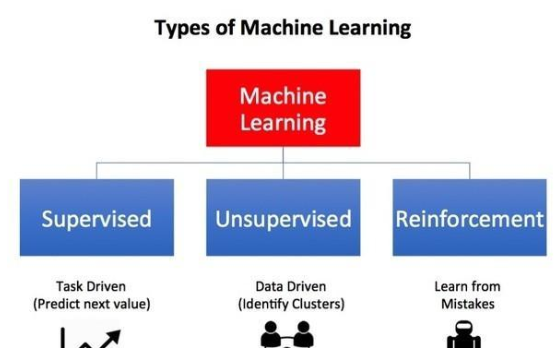
深度學習DL是機器學習中一種基于對數據進行表征學習的方法。深度學習DL有監督和非監督之分,都已經得到廣泛的研究和應用。強化學習RL是通過對未知環境一邊探索一邊建立環境模型以及學習得到一個最優策略。強化學習是機器學習中一種快速、高效且不可替代的學習算法。
2020-06-13 11:39:407088 近期,有不少報道強化學習算法在 GO、Dota 2 和 Starcraft 2 等一系列游戲中打敗了專業玩家的新聞。強化學習是一種機器學習類型,能夠在電子游戲、機器人、自動駕駛等復雜應用中運用人工智能。
2020-07-27 08:50:151212 Viet Nguyen就是其中一個。這位來自德國的程序員表示自己只玩到了第9個關卡。因此,他決定利用強化學習AI算法來幫他完成未通關的遺憾。
2020-07-29 09:30:163423 強化學習屬于機器學習中的一個子集,它使代理能夠理解在特定環境中執行特定操作的相應結果。目前,相當一部分機器人就在使用強化學習掌握種種新能力。
2020-11-06 15:33:492130 深度強化學習是深度學習與強化學習相結合的產物,它集成了深度學習在視覺等感知問題上強大的理解能力,以及強化學習的決策能力,實現了...
2020-12-10 18:32:501078 RLax(發音為“ relax”)是建立在JAX之上的庫,它公開了用于實施強化學習智能體的有用構建塊。。報道:深度強化學習實驗室作者:DeepRL ...
2020-12-10 18:43:231332 本文主要介紹深度強化學習在任務型對話上的應用,兩者的結合點主要是將深度強化學習應用于任務型對話的策略學習上來源:騰訊技術工程微信號
2020-12-10 19:02:451545 ADSIM模擬器
2021-03-23 13:50:5715 根據真實環境的狀態轉移數據來預定義環境動態模型,隨后在通過環境動態模型進行策略學習的過程中無須再與環境進行交互。在無模型強化學習中,智
2021-04-08 11:41:5811 深度強化學習(DRL)作為機器學習的重要分攴,在 Alphago擊敗人類后受到了廣泛關注。DRL以種試錯機制與環境進行交互,并通過最大化累積獎賞最終得到最優策略。強化學習可分為無模型強化學習和模型化
2021-04-12 11:01:529 Control of Bipedal Robots)為題,已被機器人國際學術頂會 ICRA 收錄。 通過強化學習,它能自己走路,并能進行自我恢復。在現實世界中,通過反復試
2021-04-13 09:35:093021 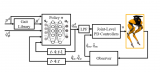
利用深度強化學習技術實現路口信號控制是智能交通領域的硏究熱點。現有硏究大多利用強化學習來全面刻畫交通狀態以及設計有效強化學習算法以解決信號配時問題,但這些研究往往忽略了信號燈狀態對動作選擇的影響以及
2021-04-23 15:30:5321 移動群智感知系統需要為用戶提供個性化隱私保護,以吸引更多用戶參與任務。然而,由于惡意攻擊者的存在,用戶提升隱私保護力度會導致位置可用性變差,降低任務分配效率。針對該問題,提出了一種基于強化學習的用戶
2021-05-08 15:12:172 目前壯語智能信息處理研究處于起步階段,缺乏自動詞性標注方法。針對壯語標注語料匱乏、人工標注費時費力而機器標注性能較差的現狀,提出一種基于強化學習的壯語詞性標注方法。依據壯語的文法特點和中文賓州樹庫
2021-05-14 11:29:3514 壓邊力控制策略的學習優化。基于深度強化學習的壓邊力優化算法,利用深度神經網絡處理巨大的狀態空間,避免了系統動力學的擬合,并且使用一種新的網絡結構來構建策略網絡,將壓邊力策略劃分為全局與局部兩部分,提高了壓邊
2021-05-27 10:32:390 在多核嵌入式操作系統中,中央處理器對共享最后一級緩存( Last Level cache,LIC)的資源調度決定了各用戶進程的指令周期數( Instructions Per Cycle,IPC
2021-05-31 15:54:176 基于深度強化學習的無人機控制律設計方法
2021-06-23 14:59:1046 基于強化學習的虛擬場景角色乒乓球訓練
2021-06-27 11:34:3362 使用Matlab進行強化學習電子版資源下載
2021-07-16 11:17:090 強化學習 (Reinforcement Learning) 是一種指導機器人在現實世界完成導航和執行操作的熱門方法,其本身可以簡化并表示為剛性物體 [1](即受外力作用時不會變形的固體物理對象)之間
2021-08-24 11:06:584438 突破.由于融合了深度學習強大的表征能力和強化學習有效的策略搜索能力,深度強化學習已經成為實現人工智能頗有前景的學習范式.然而,深度強化學習在多Agent 系統的研究與應用中,仍存在諸多困難和挑戰,以StarCraft II 為代表的部分觀測環境下的多Agent學習仍然很難達到理想效果.本文簡要介紹了深度Q
2022-01-18 10:08:012300 
定標記訓練數據的情況下獲得正確的輸出 無監督學習(UL):關注在沒有預先存在的標簽的情況下發現數據中的模式 強化學習(RL) : 關注智能體在環境中如何采取行動以最大化累積獎勵 通俗地說,強化學習類似于嬰兒學習和發現世界,如果有獎勵(正強化),嬰兒可能會執行一個行
2022-12-20 14:00:021678 電子發燒友網站提供《ESP32上的深度強化學習.zip》資料免費下載
2022-12-27 10:31:451 作者:Siddhartha Pramanik 來源:DeepHub IMBA 目前流行的強化學習算法包括 Q-learning、SARSA、DDPG、A2C、PPO、DQN 和 TRPO。這些算法
2023-02-03 20:15:061744 本文介紹了強化學習與智能駕駛決策規劃。智能駕駛中的決策規劃模塊負責將感知模塊所得到的環境信息轉化成具體的駕駛策略,從而指引車輛安全、穩定的行駛。真實的駕駛場景往往具有高度的復雜性及不確定性。如何制定
2023-02-08 14:05:162890 RX 系列模擬器/調試器 V.1.00 用戶手冊
2023-04-20 19:25:050 SuperH 模擬器/調試器 V.9.09.00 用戶手冊的補充信息
2023-04-21 19:22:420 用于用戶開放接口的 SM+ 系統模擬器 (U18212CA2V0UM00)
2023-04-28 19:35:030 用于用戶開放接口的 SM+ 系統模擬器 (U18212EJ2V0UM00)
2023-05-04 19:19:120 強化學習(RL)是人工智能的一個子領域,專注于決策過程。與其他形式的機器學習相比,強化學習模型通過與環境交互并以獎勵或懲罰的形式接收反饋來學習。
2023-06-09 09:23:23930 的情況下獲得正確的輸出無監督學習(UL):關注在沒有預先存在的標簽的情況下發現數據中的模式強化學習(RL):關注智能體在環境中如何采取行動以最大化累積獎勵通俗地說,強
2023-01-05 14:54:051714 
電子發燒友網站提供《人工智能強化學習開源分享.zip》資料免費下載
2023-06-20 09:27:281 摘要:基于強化學習的目標檢測算法在檢測過程中通常采用預定義搜索行為,其產生的候選區域形狀和尺寸變化單一,導致目標檢測精確度較低。為此,在基于深度強化學習的視覺目標檢測算法基礎上,提出聯合回歸與深度
2023-07-19 14:35:020 訊維模擬矩陣在深度強化學習智能控制系統中的應用主要是通過構建一個包含多種環境信息和動作空間的模擬矩陣,來模擬和預測深度強化學習智能控制系統在不同環境下的表現和效果,從而優化控制策略和提高系統的性能
2023-09-04 14:26:361155 
終端模擬器是Linux操作系統中常用的工具,它提供了一個圖形界面來模擬命令行環境。終端模擬器不僅可以執行命令行操作,還具有許多功能和特性,如多標簽頁、自定義配置、分屏顯示等,使得用戶可以更加
2023-09-08 16:36:011910 
擴散模型(diffusion model)在 CV 領域甚至 NLP 領域都已經有了令人印象深刻的表現。最近的一些工作開始將 diffusion model 用于強化學習(RL)中來解決序列決策問題
2023-10-02 10:45:021711 
強化學習是機器學習的方式之一,它與監督學習、無監督學習并列,是三種機器學習訓練方法之一。 在圍棋上擊敗世界第一李世石的 AlphaGo、在《星際爭霸2》中以 10:1 擊敗了人類頂級職業玩家
2023-10-30 11:36:405374 
HUAWEI DevEco Studio 開發和環境中彈出如下對話框 , 點擊 Agree 同意 ; ? 此時會彈出如下模擬器對話框 : ? 選擇 P40 手機設備 , 雙擊該條目
2024-01-26 15:02:514072 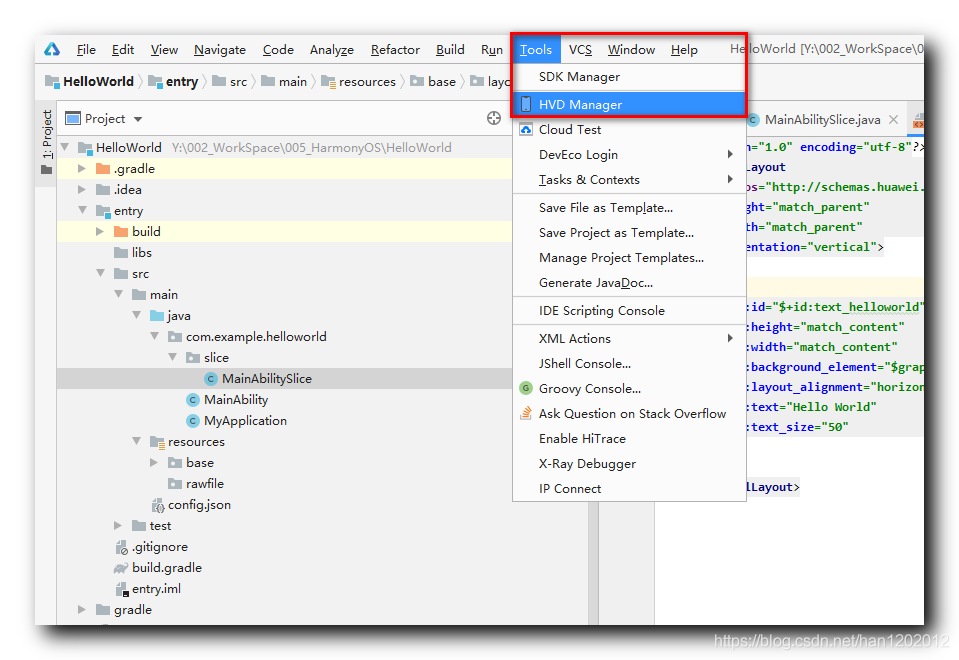
更快更好地學習。我們的想法是找到最優數量的特征和最有意義的特征。在本文中,我們將介紹并實現一種新的通過強化學習策略的特征選擇。我們先討論強化學習,尤其是馬爾可夫決策
2024-06-05 08:27:46971 電池模擬器是一種強大的工具,能夠在模擬真實電池的輸出狀態和充放電特性方面發揮重要作用。它可以準確地模擬電池的充放電狀態、放電深度、開路電壓和內部電阻等關鍵參數,用戶可根據需要隨時調整這些條件,以快速
2024-06-11 16:05:581981 
光伏模擬器是一種用于模擬太陽能光伏電池工作原理和性能的軟硬件設備。它能夠提供光伏電池在不同光照、溫度和環境條件下的電流、電壓、功率等參數,用于測試和評估光伏電池的性能,并幫助開發、優化和驗證光伏系統
2024-10-30 17:12:511313 
的計算圖和自動微分功能,非常適合實現復雜的強化學習算法。 1. 環境(Environment) 在強化學習中,環境是一個抽象的概念,它定義了智能體(agent)可以執行的動作(actions)、觀察到
2024-11-05 17:34:281515 電網模擬器是一種能夠模擬實際電網運行狀態的裝置,它在電力系統的規劃、設計、測試和維護中發揮著至關重要的作用。了解電網模擬器的工作原理對于優化電力系統的設計和提升其運行效率具有重要意義。 電網模擬器
2025-01-09 16:58:451489 本文主要比較了基于氙燈和基于LED的太陽能模擬器在光譜匹配、時間穩定性和光照均勻性等方面的性能。通過測量多種太陽能電池的電流-電壓(I-V)響應和光譜響應(SR),評估了兩種模擬器在模擬太陽光
2025-07-24 11:31:19631 
[首發于智駕最前沿微信公眾號]在談及自動駕駛時,有些方案中會提到“強化學習(Reinforcement Learning,簡稱RL)”,強化學習是一類讓機器通過試錯來學會做決策的技術。簡單理解
2025-10-23 09:00:37477 
 電子發燒友App
電子發燒友App








 工商網監
工商網監
評論