") 谷歌、DeepMind重磅推出PlaNet 強(qiáng)化學(xué)習(xí)新突破
谷歌、DeepMind重磅推出PlaNet 強(qiáng)化學(xué)習(xí)新突破

Google AI 與 DeepMind 合作推出深度規(guī)劃網(wǎng)絡(luò) (PlaNet),這是一個(gè)純粹基于模型的智能體,能從圖像輸入中學(xué)習(xí)世界模型,完成多項(xiàng)規(guī)劃任務(wù),數(shù)據(jù)效率平均提升50倍,強(qiáng)化學(xué)習(xí)又一突破。
通過(guò)強(qiáng)化學(xué)習(xí) (RL),對(duì) AI 智能體如何隨著時(shí)間的推移提高決策能力的研究進(jìn)展迅速。
對(duì)于強(qiáng)化學(xué)習(xí),智能體在選擇動(dòng)作 (例如,運(yùn)動(dòng)命令) 時(shí)會(huì)觀察一系列感官輸入(例如,相機(jī)圖像),并且有時(shí)會(huì)因?yàn)檫_(dá)成指定目標(biāo)而獲得獎(jiǎng)勵(lì)。
RL 的無(wú)模型方法 (Model-free) 旨在通過(guò)感官觀察直接預(yù)測(cè)良好的行為,這種方法使 DeepMind 的 DQN 能夠玩雅達(dá)利游戲,使其他智能體能夠控制機(jī)器人。
然而,這是一種黑盒方法,通常需要經(jīng)過(guò)數(shù)周的模擬交互才能通過(guò)反復(fù)試驗(yàn)來(lái)學(xué)習(xí),這限制了它在實(shí)踐中的有效性。
相反,基于模型的 RL 方法 (Model-basedRL) 試圖讓智能體了解整個(gè)世界的行為。這種方法不是直接將觀察結(jié)果映射到行動(dòng),而是允許 agent 明確地提前計(jì)劃,通過(guò) “想象” 其長(zhǎng)期結(jié)果來(lái)更仔細(xì)地選擇行動(dòng)。
Model-based 的方法已經(jīng)取得了巨大的成功,包括 AlphaGo,它設(shè)想在已知游戲規(guī)則的虛擬棋盤(pán)上進(jìn)行一系列的移動(dòng)。然而,要在未知環(huán)境中利用規(guī)劃(例如僅將像素作為輸入來(lái)控制機(jī)器人),智能體必須從經(jīng)驗(yàn)中學(xué)習(xí)規(guī)則或動(dòng)態(tài)。
由于這種動(dòng)態(tài)模型原則上允許更高的效率和自然的多任務(wù)學(xué)習(xí),因此創(chuàng)建足夠精確的模型以成功地進(jìn)行規(guī)劃是 RL 的長(zhǎng)期目標(biāo)。
為了推動(dòng)這項(xiàng)研究挑戰(zhàn)的進(jìn)展,Google AI 與 DeepMind 合作,提出了深度規(guī)劃網(wǎng)絡(luò) (Deep Planning Network, PlaNet),該智能體僅從圖像輸入中學(xué)習(xí)世界模型 (world model),并成功地利用它進(jìn)行規(guī)劃。
PlaNet 解決了各種基于圖像的控制任務(wù),在最終性能上可與先進(jìn)的 model-free agent 競(jìng)爭(zhēng),同時(shí)平均數(shù)據(jù)效率提高了 5000%。研究團(tuán)隊(duì)將發(fā)布源代碼供研究社區(qū)使用。
在 2000 次的嘗試中,PlaNet 智能體學(xué)習(xí)解決了各種連續(xù)控制任務(wù)。以前的沒(méi)有學(xué)習(xí)環(huán)境模型的智能體通常需要多 50 倍的嘗試次數(shù)才能達(dá)到類(lèi)似的性能。
PlaNet 的工作原理
簡(jiǎn)而言之,PlaNet 學(xué)習(xí)了給定圖像輸入的動(dòng)態(tài)模型 (dynamics model),并有效地利用該模型進(jìn)行規(guī)劃,以收集新的經(jīng)驗(yàn)。
與以前的圖像規(guī)劃方法不同,我們依賴(lài)于隱藏狀態(tài)或潛在狀態(tài)的緊湊序列。這被稱(chēng)為latent dynamics model:我們不是直接從一個(gè)圖像到下一個(gè)圖像地預(yù)測(cè),而是預(yù)測(cè)未來(lái)的潛在狀態(tài)。然后從相應(yīng)的潛在狀態(tài)生成每一步的圖像和獎(jiǎng)勵(lì)。
通過(guò)這種方式壓縮圖像,agent 可以自動(dòng)學(xué)習(xí)更抽象的表示,例如對(duì)象的位置和速度,這樣就可以更容易地向前預(yù)測(cè),而不需要沿途生成圖像。
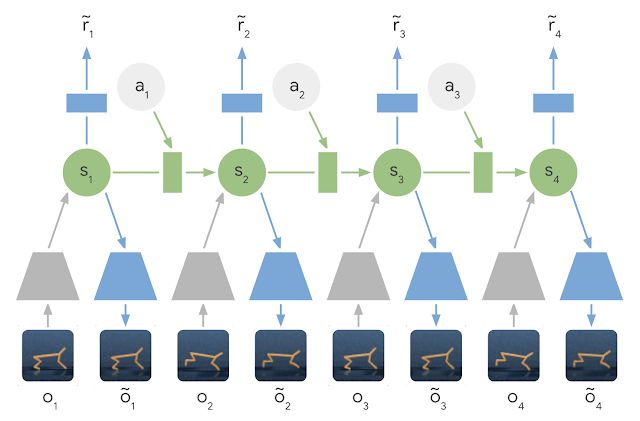
Learned Latent Dynamics Model:在 latent dynamics 模型中,利用編碼器網(wǎng)絡(luò)(灰色梯形) 將輸入圖像的信息集成到隱藏狀態(tài)(綠色) 中。然后將隱藏狀態(tài)向前投影,以預(yù)測(cè)未來(lái)的圖像(藍(lán)色梯形) 和獎(jiǎng)勵(lì)(藍(lán)色矩形)。
為了學(xué)習(xí)一個(gè)精確的 latent dynamics 模型,我們提出了:
循環(huán)狀態(tài)空間模型 (Recurrent State Space Model):一種具有確定性和隨機(jī)性成分的 latent dynamics 模型,允許根據(jù)魯棒規(guī)劃的需要預(yù)測(cè)各種可能的未來(lái),同時(shí)記住多個(gè)時(shí)間步長(zhǎng)的信息。我們的實(shí)驗(yàn)表明這兩個(gè)組件對(duì)于提高規(guī)劃性能是至關(guān)重要的。
潛在超調(diào)目標(biāo) (Latent Overshooting Objective):我們通過(guò)在潛在空間中強(qiáng)制 one-step 和 multi-step 預(yù)測(cè)之間的一致性,將 latent dynamics 模型的標(biāo)準(zhǔn)訓(xùn)練目標(biāo)推廣到訓(xùn)練多步預(yù)測(cè)。這產(chǎn)生了一個(gè)快速和有效的目標(biāo),可以改善長(zhǎng)期預(yù)測(cè),并與任何潛在序列模型兼容。
雖然預(yù)測(cè)未來(lái)的圖像允許我們教授模型,但編碼和解碼圖像 (上圖中的梯形) 需要大量的計(jì)算,這會(huì)減慢智能體的 planning 過(guò)程。然而,在緊湊的潛在狀態(tài)空間中進(jìn)行 planning 是很快的,因?yàn)槲覀冎恍枰A(yù)測(cè)未來(lái)的 rewards 來(lái)評(píng)估一個(gè)動(dòng)作序列,而不是預(yù)測(cè)圖像。
例如,智能體可以想象球的位置和它到目標(biāo)的距離在特定的動(dòng)作中將如何變化,而不需要可視化場(chǎng)景。這允許我們?cè)诿看沃悄荏w選擇一個(gè)動(dòng)作時(shí),將 10000 個(gè)想象的動(dòng)作序列與一個(gè)大的 batch size 進(jìn)行比較。然后執(zhí)行找到的最佳序列的第一個(gè)動(dòng)作,并在下一步重新規(guī)劃。
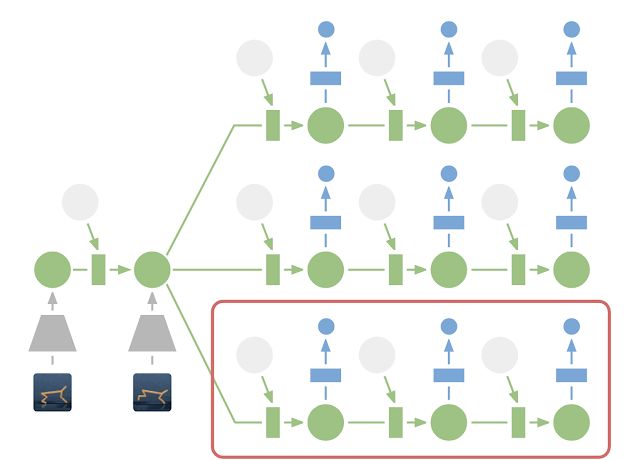
在潛在空間中進(jìn)行規(guī)劃:為了進(jìn)行規(guī)劃,我們將過(guò)去的圖像 (灰色梯形) 編碼為當(dāng)前的隱藏狀態(tài) (綠色)。這樣,我們可以有效地預(yù)測(cè)多個(gè)動(dòng)作序列的未來(lái)獎(jiǎng)勵(lì)。請(qǐng)注意,上圖中昂貴的圖像解碼器 (藍(lán)色梯形) 已經(jīng)消失了。然后,執(zhí)行找到的最佳序列的第一個(gè)操作 (紅色框)。
與我們之前關(guān)于世界模型的工作 (https://worldmodels.github.io/) 相比,PlaNet 在沒(méi)有策略網(wǎng)絡(luò)的情況下工作 —— 它純粹通過(guò) planning 來(lái)選擇行動(dòng),因此它可以從模型當(dāng)下的改進(jìn)中獲益。有關(guān)技術(shù)細(xì)節(jié),請(qǐng)參閱我們的研究論文。
PlaNet vs. Model-Free 方法
我們?cè)谶B續(xù)控制任務(wù)上評(píng)估了 PlaNet。智能體只被輸入圖像觀察和獎(jiǎng)勵(lì)。我們考慮了具有各種不同挑戰(zhàn)的任務(wù):
側(cè)手翻任務(wù):帶有一個(gè)固定的攝像頭,這樣推車(chē)可以移動(dòng)到視線之外。因此,智能體必須吸收并記住多個(gè)幀的信息。
手指旋轉(zhuǎn)任務(wù):需要預(yù)測(cè)兩個(gè)單獨(dú)的對(duì)象,以及它們之間的交互。
獵豹跑步任務(wù):包括難以準(zhǔn)確預(yù)測(cè)的地面接觸,要求模型預(yù)測(cè)多個(gè)可能的未來(lái)。
杯子接球任務(wù):它只在球被接住時(shí)提供一個(gè)稀疏的獎(jiǎng)勵(lì)信號(hào)。這要求準(zhǔn)確預(yù)測(cè)很遠(yuǎn)的未來(lái),并規(guī)劃一個(gè)精確的動(dòng)作序列。
走路任務(wù):模擬機(jī)器人一開(kāi)始是躺在地上,然后它必須先學(xué)會(huì)站立,再學(xué)習(xí)行走。
PlaNet 智能體接受了各種基于圖像的控制任務(wù)的訓(xùn)練。動(dòng)圖顯示了當(dāng)智能體解決任務(wù)時(shí)輸入的圖像。這些任務(wù)提出了不同的挑戰(zhàn):部分可觀察性、與地面的接觸、接球的稀疏獎(jiǎng)勵(lì),以及控制一個(gè)具有挑戰(zhàn)性的雙足機(jī)器人。
這一研究是第一個(gè)使用學(xué)習(xí)模型進(jìn)行規(guī)劃,并在基于圖像的任務(wù)上優(yōu)于 model-free 方法的案例。
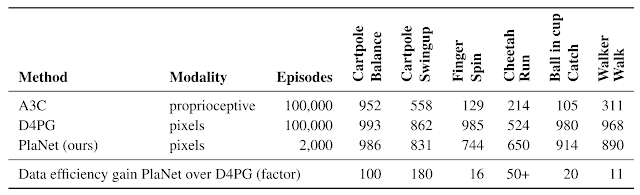
下表將PlaNet與著名的A3C 智能體和 D4PG 智能體進(jìn)行了比較,后者結(jié)合了 model-free RL 的最新進(jìn)展。這些基線數(shù)據(jù)來(lái)自 DeepMind 控制套件。PlaNet 在所有任務(wù)上都明顯優(yōu)于 A3C,最終性能接近 D4PG,同時(shí)與環(huán)境的交互平均減少了 5000%。
所有任務(wù)只需要一個(gè)智能體
此外,我們只訓(xùn)練了一個(gè)單一的 PlaNet 智能體來(lái)解決所有六個(gè)任務(wù)。
在不知道任務(wù)的情況下,智能體被隨機(jī)放置在不同的環(huán)境中,因此它需要通過(guò)觀察圖像來(lái)推斷任務(wù)。
在不改變超參數(shù)的情況下,多任務(wù)智能體實(shí)現(xiàn)了與單個(gè)智能體相同的平均性能。雖然在側(cè)手翻任務(wù)中學(xué)習(xí)速度較慢,但在需要探索的具有挑戰(zhàn)性的步行任務(wù)中,它的學(xué)習(xí)速度要快得多,最終表現(xiàn)也更好。
在多個(gè)任務(wù)上訓(xùn)練的 PlaNet 智能體。智能體觀察前 5 個(gè)幀作為上下文以推斷任務(wù)和狀態(tài),并在給定動(dòng)作序列的情況下提前準(zhǔn)確地預(yù)測(cè) 50 個(gè)步驟。
結(jié)論
我們的結(jié)果展示了構(gòu)建自主 RL 智能體的學(xué)習(xí)動(dòng)態(tài)模型的前景。我們鼓勵(lì)進(jìn)一步的研究,集中在學(xué)習(xí)更困難的任務(wù)的精確動(dòng)態(tài)模型,如三維環(huán)境和真實(shí)的機(jī)器人任務(wù)。擴(kuò)大規(guī)模的一個(gè)可能因素是 TPU 的處理能力。我們對(duì) model-based 強(qiáng)化學(xué)習(xí)帶來(lái)的可能性感到興奮,包括多任務(wù)學(xué)習(xí)、分層規(guī)劃和使用不確定性估計(jì)的主動(dòng)探索。
-
谷歌
+關(guān)注
關(guān)注
27文章
6255瀏覽量
111911 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
273瀏覽量
11994 -
DeepMind
+關(guān)注
關(guān)注
0文章
131瀏覽量
12417
原文標(biāo)題:一個(gè)智能體打天下:谷歌、DeepMind重磅推出PlaNet,數(shù)據(jù)效率提升50倍
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
上汽奧迪E5 Sportback車(chē)型升級(jí)搭載全新Momenta強(qiáng)化學(xué)習(xí)大模型
上汽大眾ID. ERA 9X全球首發(fā)搭載Momenta R7強(qiáng)化學(xué)習(xí)世界模型
Momenta R6強(qiáng)化學(xué)習(xí)大模型上車(chē)東風(fēng)日產(chǎn)NX8
Momenta強(qiáng)化學(xué)習(xí)大模型助力別克至境世家純電版正式上市
Momenta R7強(qiáng)化學(xué)習(xí)世界模型即將推出
自動(dòng)駕駛中常提的離線強(qiáng)化學(xué)習(xí)是什么?

強(qiáng)化學(xué)習(xí)會(huì)讓自動(dòng)駕駛模型學(xué)習(xí)更快嗎?

多智能體強(qiáng)化學(xué)習(xí)(MARL)核心概念與算法概覽

上汽別克至境E7首發(fā)搭載Momenta R6強(qiáng)化學(xué)習(xí)大模型
NVIDIA 推出 Nemotron 3 系列開(kāi)放模型

今日看點(diǎn):智元推出真機(jī)強(qiáng)化學(xué)習(xí);美國(guó)軟件公司SAS退出中國(guó)市場(chǎng)
自動(dòng)駕駛中常提的“強(qiáng)化學(xué)習(xí)”是個(gè)啥?

谷歌DeepMind重磅發(fā)布Genie 3,首次實(shí)現(xiàn)世界模型實(shí)時(shí)交互
NVIDIA Isaac Lab可用環(huán)境與強(qiáng)化學(xué)習(xí)腳本使用指南

18個(gè)常用的強(qiáng)化學(xué)習(xí)算法整理:從基礎(chǔ)方法到高級(jí)模型的理論技術(shù)與代碼實(shí)現(xiàn)




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論