 強化學習與智能駕駛決策規劃
強化學習與智能駕駛決策規劃

本文介紹了強化學習與智能駕駛決策規劃。智能駕駛中的決策規劃模塊負責將感知模塊所得到的環境信息轉化成具體的駕駛策略,從而指引車輛安全、穩定的行駛。真實的駕駛場景往往具有高度的復雜性及不確定性。如何制定一套泛化能力強的決策規劃機制是智能駕駛目前面臨的難點之一。強化學習是一種從經驗中總結的學習方式,并從長遠的角度出發,尋找解決問題的最優方案。近些年來,強化學習在人工智能領域取得了重大突破,因而成為了解決智能駕駛決策規劃問題的一種新的思路。
01.強化學習的介紹
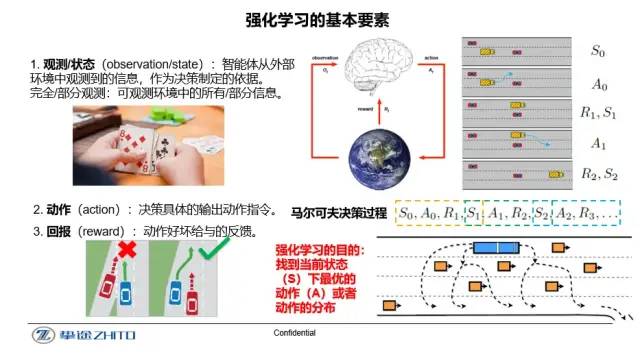
強化學習(Reinforcement Learning)近些年來是人工智能的一個前言領域,屬于機器學習的一個重要分支。從定義上來講,強化學習可以通過經驗探索來學習到解決問題的最優策略,即累計回報值最大的動作選取策略。在沒有任何初始經驗的情況下,強化學習可以通過平衡探索未知動作的可能性,學習到解決問題的最優方法,從而達到自我學習的目的。因此,強化學習與其他機器學習算法的一個顯著區別為不依賴初始人工標注數據集的大小,探索式的自我學習可大幅度的節省人力成本。近些年來,隨著深度學習的迅速發展,將深度學習與強化學習相結合的深度強化學習成為人工智能研究的熱門領域之一,并在游戲、控制等領域取得了令人矚目的成就。
02.智能駕駛決策規劃的任務

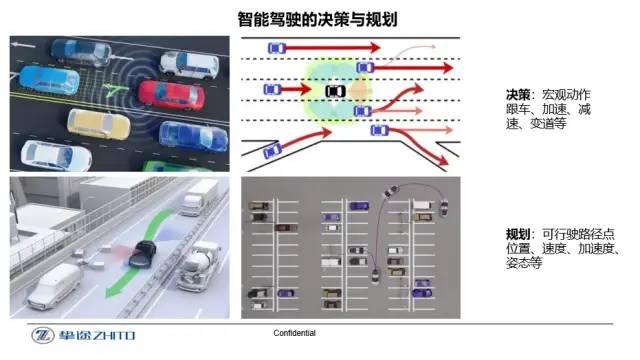
智能駕駛的主要目的是為人們提供安全、舒適及高效的出行體驗。大多數的交通事故產生的原因來自于駕駛員人為因素,例如疲勞駕駛、情緒駕駛以及路況判斷失誤等。因此,合理的選擇駕駛行為及路線規劃是智能駕駛的一個重要環節。其中,行為決策負責在接收到全局路徑后,根據從感知模塊得到的環境信息(車輛速度、障礙物及道路信息等),做出具體的行為決策(如變道、跟車、減速等)。而規劃的任務則是在接收到決策層的宏觀動作指令之后,將其轉化成一條更加具體的行駛軌跡,從而能夠生成一系列控制信號(油門、方向盤轉角、剎車等),實現車輛的自動行駛。如何應對不同的路況信息將做出合理的決策與規劃是無人駕駛智能化的一個重要指標。
03.決策規劃目前的難點
由于實際的交通場景千變萬化,道路結構差異大(高速、十字路口、停車場等),如何去設計一套通用性強的決策規劃機制是目前困擾著智能駕駛的一個主要難題。同時,其他交通參與者的行為存在不確定性,不僅需要對其行為做預測,還需要考慮本車與其他交通參與者的博弈。因此,需要對時刻變化的外部環境做出快速及準確的響應。如何應對感知模塊提供的信息做不到100%的準確和100%的全覆蓋也是智能車在決策規劃時要考慮的重要因素。
04.強化學習對于智能駕駛決策規劃的意義
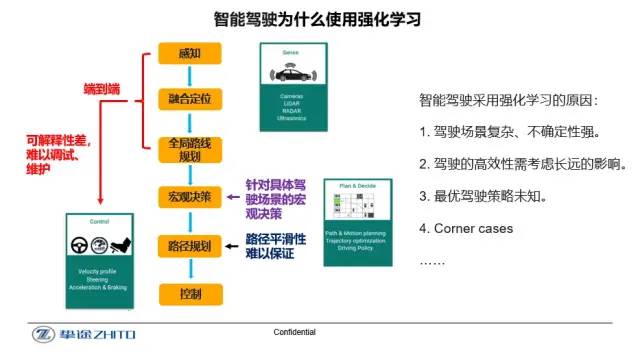
強化學習適用于求解具有時序性的決策問題,這正與智能駕駛的決策過程相契合。結合神經網絡的深度強化學習框架可以增加駕駛場景的泛化能力。同時,考慮部分不可觀測環境的強化學習流程可以評估交通參與者的不確定性,并通過預測與推演的方式從長遠的角度出發來尋求最優的駕駛方案。更重要的是,強化學習由于其自身具有應對外部環境改變而產生進化的能力。當未知的corner case產生時,智能體可以通過改變自身的駕駛策略來適應并探索學習到解決該問題的方法。
-
人工智能
+關注
關注
1815文章
50053瀏覽量
264525 -
智能駕駛
+關注
關注
5文章
3000瀏覽量
51242 -
強化學習
+關注
關注
4文章
270瀏覽量
11950
原文標題:強化學習對于智能駕駛決策規劃的意義
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
自動駕駛中常提的離線強化學習是什么?

強化學習會讓自動駕駛模型學習更快嗎?

多智能體強化學習(MARL)核心概念與算法概覽

上汽別克至境E7首發搭載Momenta R6強化學習大模型
如何訓練好自動駕駛端到端模型?

今日看點:智元推出真機強化學習;美國軟件公司SAS退出中國市場
什么是自動駕駛決策系統?發展有何挑戰?

自動駕駛中常提的“強化學習”是個啥?

無人駕駛:智能決策與精準執行的融合
自動駕駛中Transformer大模型會取代深度學習嗎?

AI智能體的技術應用與未來圖景
NVIDIA Isaac Lab可用環境與強化學習腳本使用指南

18個常用的強化學習算法整理:從基礎方法到高級模型的理論技術與代碼實現

【「零基礎開發AI Agent」閱讀體驗】+初品Agent
詳解RAD端到端強化學習后訓練范式




 工商網監
工商網監
評論