 NeurIPS 2023 | 擴散模型解決多任務強化學習問題
NeurIPS 2023 | 擴散模型解決多任務強化學習問題

擴散模型(diffusion model)在 CV 領域甚至 NLP 領域都已經有了令人印象深刻的表現。最近的一些工作開始將 diffusion model 用于強化學習(RL)中來解決序列決策問題,它們主要利用 diffusion model 來建模分布復雜的軌跡或提高策略的表達性。
但是, 這些工作仍然局限于單一任務單一數據集,無法得到能同時解決多種任務的通用智能體。那么,diffusion model 能否解決多任務強化學習問題呢?我們最近提出的一篇新工作——“Diffusion Model is an Effective Planner and Data Synthesizer for Multi-Task Reinforcement Learning”,旨在解決這個問題并希望啟發后續通用決策智能的研究:

論文鏈接:
https://arxiv.org/abs/2305.18459

背景
數據驅動的大模型在 CV 和 NLP 領域已經獲得巨大成功,我們認為這背后源于模型的強表達性和數據集的多樣性和廣泛性。基于此,我們將最近出圈的生成式擴散模型(diffusion model)擴展到多任務強化學習領域(multi-task reinforcement learning),利用 large-scale 的離線多任務數據集訓練得到通用智能體。 目前解決多任務強化學習的工作大多基于 Transformer 架構,它們通常對模型的規模,數據集的質量都有很高的要求,這對于實際訓練來說是代價高昂的。基于 TD-learning 的強化學習方法則常常面臨 distribution-shift 的挑戰,在多任務數據集下這個問題尤甚,而我們將序列決策過程建模成條件式生成問題(conditional generative process),通過最大化 likelihood 來學習,有效避免了 distribution shift 的問題。

方法
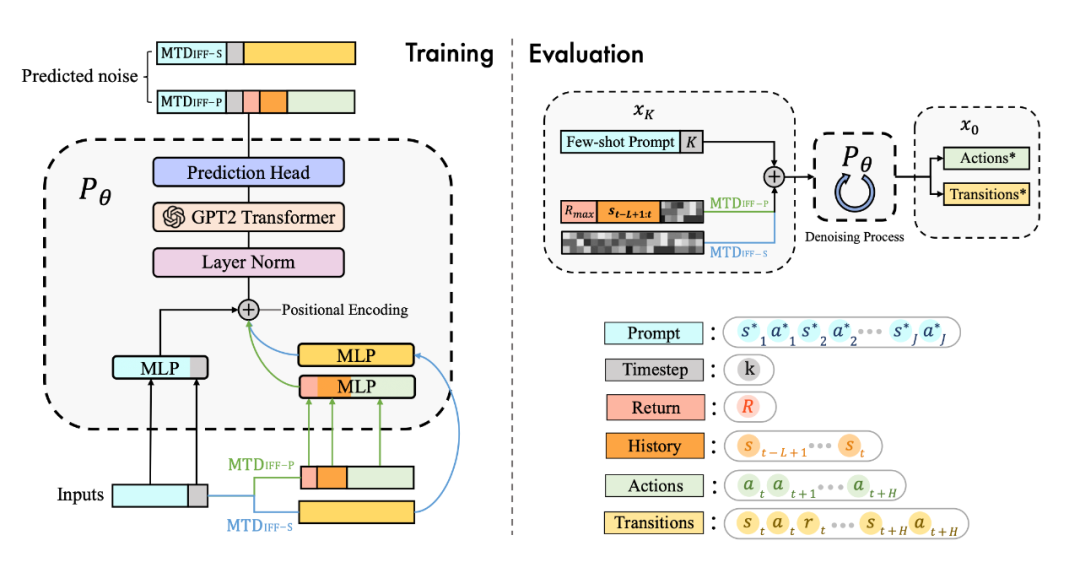
具體來說,我們發現 diffusion model 不僅能很好地輸出 action 進行實時決策,同樣能夠建模完整的(s,a,r,s')的 transition 來生成數據進行數據增強提升強化學習策略的性能,具體框架如圖所示:
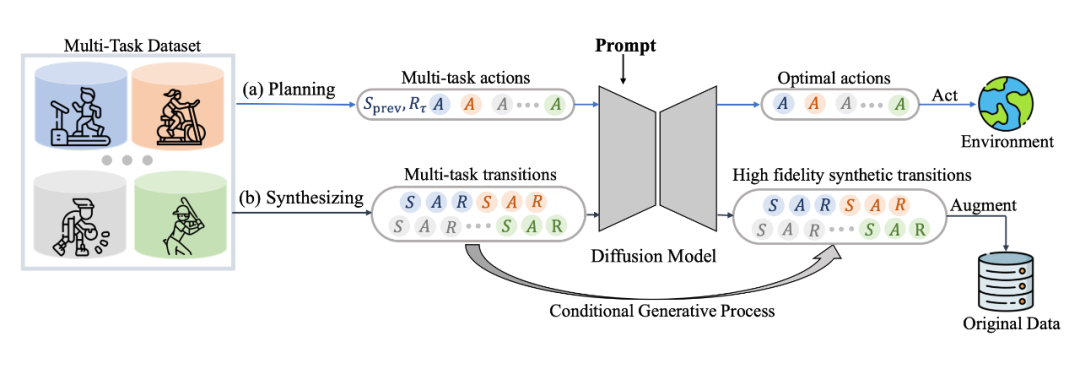
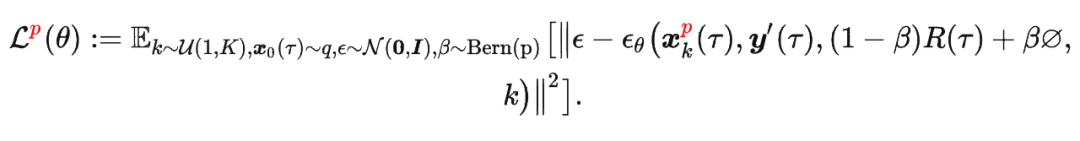 其中
其中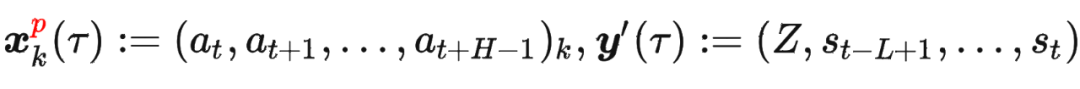 是軌跡的標準化累積回報, 是 Demonstration Prompt,可以表示為:
是軌跡的標準化累積回報, 是 Demonstration Prompt,可以表示為:

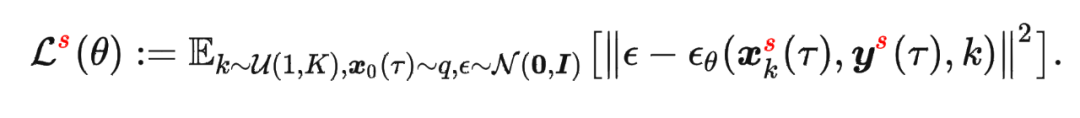 其中
其中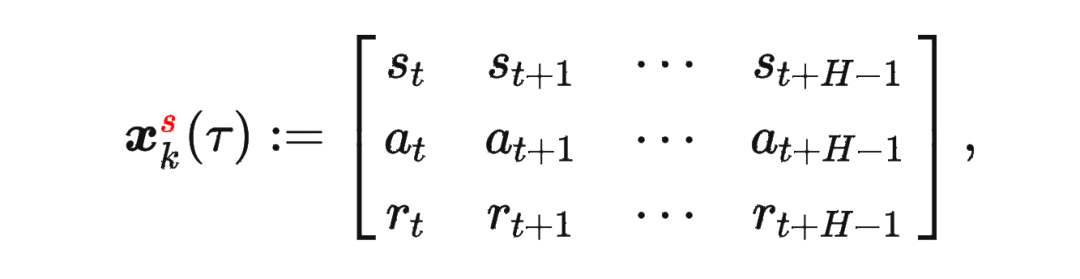
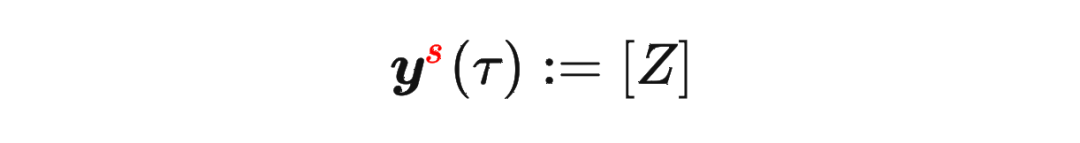

模型結構
為了更好地建模多任務數據,并且統一多樣化的輸入數據,我們用 transformer 架構替換了傳統的 U-Net 網絡,網絡結構圖如下:

實驗
我們首先在 Meta-World MT50 上開展實驗并與 baselines 進行比較,我們在兩種數據集上進行實驗,分別是包含大量專家數據,從 SAC-single-agent 中的 replay buffer 中收集到的 Near-optimal data(100M);以及從 Near-optimal data 中降采樣得到基本不包含專家數據的 Sub-optimal data(50M)。實驗結果如下:
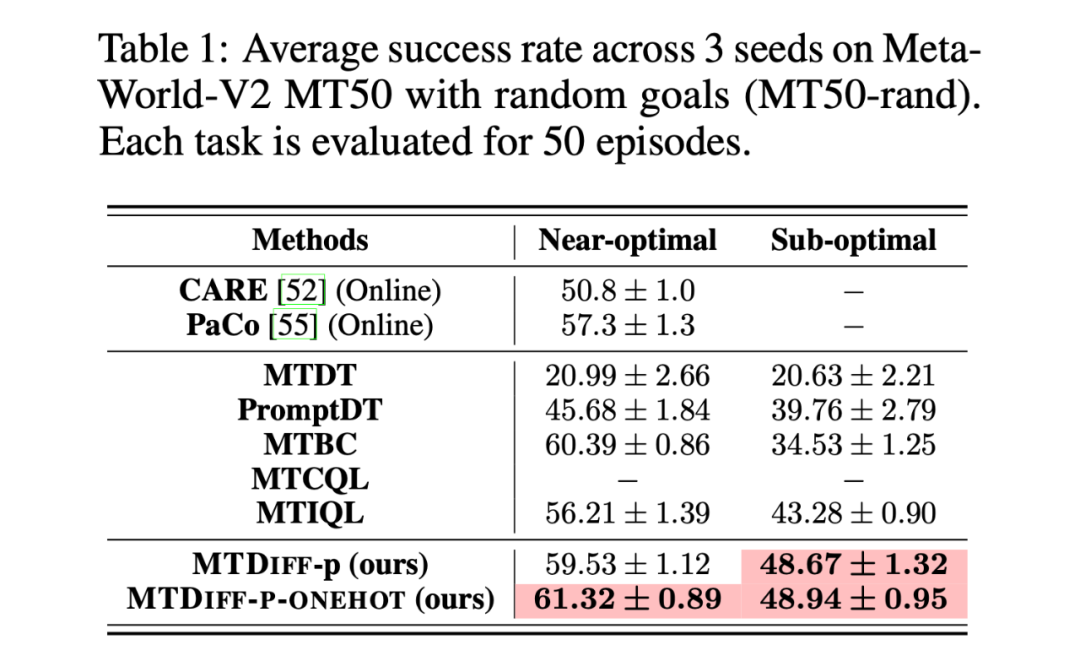
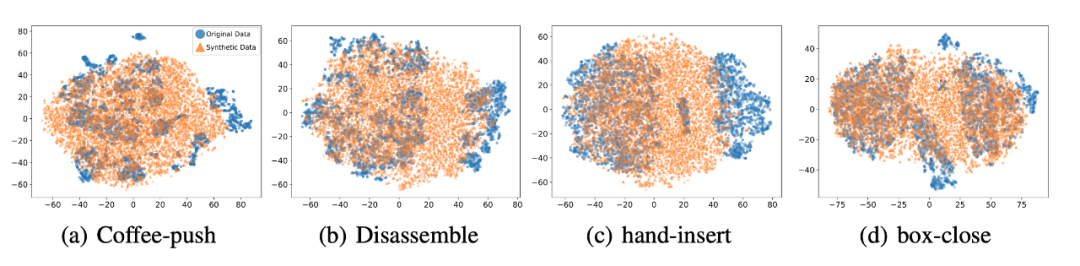
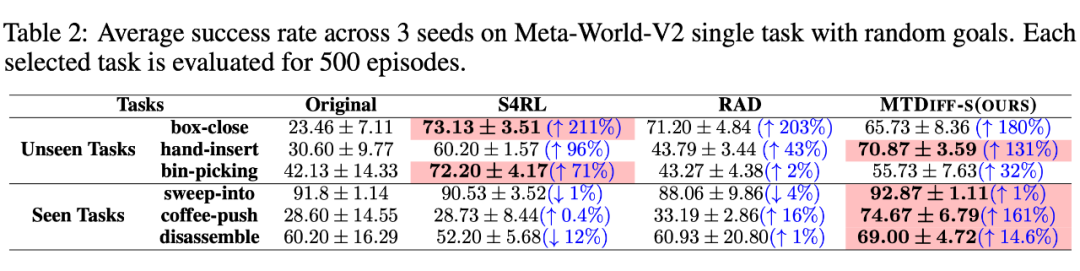 我們選取 45 個任務的 Near-optimal data 訓練 ,從表中我們可以觀察到在 見過的任務上,我們的方法均取得了最好的性能。甚至給定一段 demonstration prompt, 能泛化到沒見過的任務上并取得較好的表現。我們選取四個任務對原數據和 生成的數據做 T-SNE 可視化分析,發現我們生成的數據的分布基本匹配原數據分布,并且在不偏離的基礎上擴展了分布,使數據覆蓋更加全面。
我們選取 45 個任務的 Near-optimal data 訓練 ,從表中我們可以觀察到在 見過的任務上,我們的方法均取得了最好的性能。甚至給定一段 demonstration prompt, 能泛化到沒見過的任務上并取得較好的表現。我們選取四個任務對原數據和 生成的數據做 T-SNE 可視化分析,發現我們生成的數據的分布基本匹配原數據分布,并且在不偏離的基礎上擴展了分布,使數據覆蓋更加全面。

總結
我們提出了一種基于擴散模型(diffusion model)的一種新的、通用性強的多任務強化學習解決方案,它不僅可以通過單個模型高效完成多任務決策,而且可以對原數據集進行增強,從而提升各種離線算法的性能。我們未來將把 遷移到更加多樣、更加通用的場景,旨在深入挖掘其出色的生成能力和數據建模能力,解決更加困難的任務。同時,我們會將 遷移到真實控制場景,并嘗試優化其推理速度以適應某些需要高頻控制的任務。
原文標題:NeurIPS 2023 | 擴散模型解決多任務強化學習問題
文章出處:【微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
物聯網
+關注
關注
2948文章
48066瀏覽量
417697
原文標題:NeurIPS 2023 | 擴散模型解決多任務強化學習問題
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
上汽奧迪E5 Sportback車型升級搭載全新Momenta強化學習大模型
近日,上汽奧迪宣布旗下 E5 Sportback 車型升級搭載 全新Momenta 強化學習大模型。
上汽大眾ID. ERA 9X全球首發搭載Momenta R7強化學習世界模型
3月30日,Momenta R7強化學習世界模型全球首發搭載車型——上汽大眾ID. ERA 9X正式開啟預售。
Momenta R6強化學習大模型上車東風日產NX8
3月20日,東風日產NX8技術暨預售發布會在廣州舉辦,官宣Momenta R6強化學習大模型正式上車東風日產新能源SUV——NX8。以全球頂級大廠合力,融合先鋒科技力量,打造更適配全家出行的智能SUV,開啟合資品牌智能化全新賽道。
Momenta強化學習大模型助力別克至境世家純電版正式上市
3月17日,別克至境世家純電版正式上市,這是別克與Momenta強化學習大模型的又一次深度聯手。融合別克在MPV市場深耕27年的技術積淀,以更從容的智慧駕控,重新定義豪華與自在的出行體驗。
Momenta R7強化學習世界模型即將推出
3月16日,上汽大眾舉辦以“人本科技”為主題的ID. ERA技術發布會,首次揭曉了ID. ERA 系列包括智能輔助駕駛在內的諸多核心技術亮點。會上,Momenta CEO曹旭東正式宣布:Momenta R7強化學習世界模型即將推出,并將全球首發搭載于上汽大眾全新旗艦SUV
自動駕駛中常提的離線強化學習是什么?
[首發于智駕最前沿微信公眾號]在之前談及自動駕駛模型學習時,詳細聊過強化學習的作用,由于強化學習能讓大模型通過交互學到策略,不需要固定的規則

強化學習會讓自動駕駛模型學習更快嗎?
[首發于智駕最前沿微信公眾號]在談及自動駕駛大模型訓練時,有的技術方案會采用模仿學習,而有些會采用強化學習。同樣作為大模型的訓練方式,強化學習

多智能體強化學習(MARL)核心概念與算法概覽
訓練單個RL智能體的過程非常簡單,那么我們現在換一個場景,同時訓練五個智能體,而且每個都有自己的目標、只能看到部分信息,還能互相幫忙。這就是多智能體強化學習

上汽別克至境E7首發搭載Momenta R6強化學習大模型
別克至境家族迎來新成員——大五座智能SUV別克至境E7首發。新車將搭載Momenta R6強化學習大模型,帶來全場景的智能出行體驗。
國內七大基于大模型的發射任務調度與過程保障分系統軟件介紹
)、多模態AI、數字孿生與強化學習等前沿技術,聚焦發射任務的智能規劃、資源調度、過程保障與應急響應,是當前全球航天領域智能化升級的核心載體。 ? ?系統軟件供應可以來這里,這個首肌開始是幺伍扒,中間是幺幺叁叁,最后一個是泗柒泗
今日看點:智元推出真機強化學習;美國軟件公司SAS退出中國市場
智元推出真機強化學習,機器人訓練周期從“數周”減至“數十分鐘” ? 近日,智元機器人宣布其研發的真機強化學習技術,已在與龍旗科技合作的驗證產線中成功落地。據介紹,此次落地的真機強化學習方案,機器人
發表于 11-05 09:44
?1140次閱讀
自動駕駛中常提的“強化學習”是個啥?
[首發于智駕最前沿微信公眾號]在談及自動駕駛時,有些方案中會提到“強化學習(Reinforcement Learning,簡稱RL)”,強化學習是一類讓機器通過試錯來學會做決策的技術。簡單理解

NVIDIA Isaac Lab可用環境與強化學習腳本使用指南
Lab 是一個適用于機器人學習的開源模塊化框架,其模塊化高保真仿真適用于各種訓練環境,Isaac Lab 同時支持模仿學習(模仿人類)和強化學習(在嘗試和錯誤中進行學習),為所有機器

快速入門——LuatOS:sys庫多任務管理實戰攻略!
在嵌入式開發中,多任務管理是提升系統效率的關鍵。本教程專為快速入門設計,聚焦LuatOS的sys庫,通過實戰案例帶你快速掌握多任務創建、調度與同步技巧。無論你是零基礎新手還是希望快速提升開發效率
18個常用的強化學習算法整理:從基礎方法到高級模型的理論技術與代碼實現
本來轉自:DeepHubIMBA本文系統講解從基本強化學習方法到高級技術(如PPO、A3C、PlaNet等)的實現原理與編碼過程,旨在通過理論結合代碼的方式,構建對強化學習算法的全面理解。為確保內容




 工商網監
工商網監
評論