這是RISC-V跑大模型系列的第二篇文章,主要教大家如何將LLaMA移植到RISC-V環境里。
2023-07-17 16:16:20 2177
2177 
這是RISC-V跑大模型系列的第三篇文章,前面我們為大家介紹了如何在RISC-V下運行LLaMA,本篇我們將會介紹如何為LLaMA提供中文支持。
2023-07-17 17:15:471565 
英特爾廣泛的AI硬件組合及開放的軟件環境,為Meta發布的Llama 2模型提供了極具競爭力的選擇,進一步助力大語言模型的普及,推動AI發展惠及各行各業。 ? 大語言模型(LLM)在生成文本、總結
2023-07-25 09:56:261273 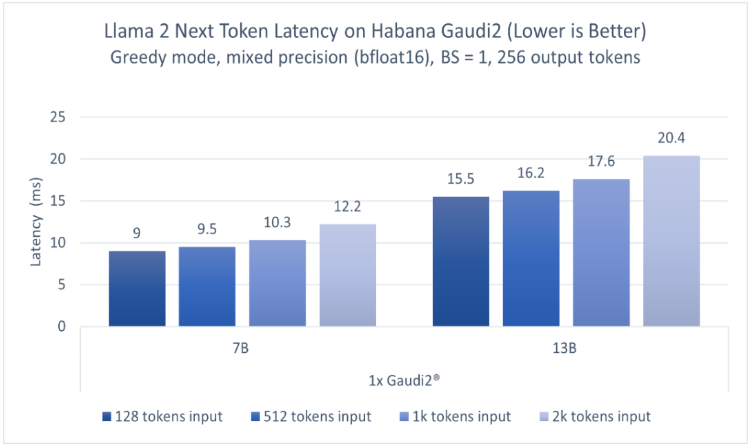
Llama 2是 Meta 發布了其最新的大型語言模型,Llama2 是基于 Transformer 的人工神經網絡,以一系列單詞作為輸入,遞歸地預測下一個單詞來生成文本。
2023-08-06 11:06:301149 
llama.cpp 的代碼結構比較直觀,如下所示,為整體代碼結構中的比較核心的部分的代碼結構
2023-11-07 09:23:274796 
LLama.cpp 支持x86,arm,gpu的編譯。
2024-01-22 09:10:163455 
本文將為你介紹如何利用 Arm i8mm 指令,具體來說,是通過帶符號 8 位整數矩陣乘加指令 smmla,來優化 llama.cpp 中 Q6_K 和 Q4_K 量化模型推理。
2025-07-24 09:51:551630 
借助 NVIDIA AI Foundry,企業和各國現在能夠使用自有數據與 Llama 3.1 405B 和 NVIDIA Nemotron 模型配對,來構建“超級模型” NVIDIA AI
2024-07-24 09:39:451105 
KEYPAD LEGEND TILE LLAMA
2023-03-29 22:35:13
llama2.c 是一個用純 C 語言實現的輕量級推理引擎,無需依賴任何第三方庫即可高效地進行推理任務。與 llama.cpp 相比,其代碼更加直觀易懂,并且可以在 PC、嵌入式 Linux 乃至
2024-09-18 23:58:41
Q2_K 量化版本的 Qwen2.5-14B。
Q2_K 顯存占用:約 5.8GB。
系統預留:1GB。
KV Cache (上下文) 空間:約 1.5GB。
性能優化 :通過 numctl 或
2025-11-27 14:43:13
預訓練語言模型。該模型最大的特點就是基于以較小的參數規模取得了優秀的性能,根據官網提供的信息,LLaMA的模型包含4個版本,最小的只有70億參數,最大的650億參數,但是其性能相比較之前的OPT
2023-12-22 10:18:11
安裝了 OpenVINO? GenAI 2024.4。
使用以下命令量化 Llama 3.1 8B 模型:
optimum-cli export openvino -m meta-llama
2025-06-25 07:20:23
無法在 OVMS 上運行來自 Meta 的大型語言模型 (LLM),例如 LLaMa2。
從 OVMS GitHub* 存儲庫運行 llama_chat Python* Demo 時遇到錯誤。
2025-03-05 08:07:06
訓練),并且和Vision結合的大模型也逐漸多了起來。所以怎么部署大模型是一個 超級重要的工程問題 ,很多公司也在緊鑼密鼓的搞著。 目前效果最好討論最多的開源實現就是LLAMA,所以我這里討論的也是基于 LLAMA的魔改部署 。 基于LLAMA的finetune模型
2023-05-23 15:08:476309 
「我們在MMLU上復現了LLaMA 65B的評估,得到了61.4的分數,接近官方分數(63.4),遠高于其在Open LLM Leaderboard上的分數(48.8),而且明顯高于獵鷹(52.7)。」
2023-06-09 16:43:141452 
這是一組由 Meta 開源的大型語言模型,共有 7B、13B、33B、65B 四種版本。其中,LLaMA-13B 在大多數數據集上超過了 GPT-3(175B),LLaMA-65B 達到了和 Chinchilla-70B、PaLM-540B 相當的水平。
2023-06-11 11:24:201155 
既然已經有了成功ChatGPT這一成功的案例,大家都想基于LLaMA把這條路再走一遍,以期望做出自己的ChatGPT。
2023-07-04 15:07:254647 
這是RISC-V跑大模型系列的第二篇文章,主要教大家如何將LLaMA移植到RISC-V環境里。
2023-07-10 10:10:381823 
通過線性插值RoPE擴張LLAMA context長度最早其實是在llamacpp項目中被人發現,有人在推理的時候直接通過線性插值將LLAMA由2k拓展到4k,性能沒有下降,引起了很多人關注。
2023-07-14 16:58:171092 要點 — ?? 高通 計劃從2024 年起,在旗艦智能手機和PC上支持基于Llama 2的AI部署,賦能開發者使用驍龍平臺的AI能力,推出激動人心的全新生成式AI應用。 ?? 與僅僅使用云端AI部署
2023-07-19 10:00:021211 
高通計劃從2024年起,在旗艦智能手機和PC上支持基于Llama 2的AI部署,賦能開發者使用驍龍平臺的AI能力,推出激動人心的全新生成式AI應用。
2023-07-19 10:00:031386 因此,高通技術公司計劃支持基于llama 2的終端ai部署,以創建新的、有趣的ai應用程序。通過這種方式,客戶、合作伙伴和開發者可以構建智能模擬器、生產力應用程序、內容制作工具和娛樂等的使用案例。驍龍?賦能實現的新終端ai體驗,即使在飛行模式下,也可以在沒有網絡連接的地區運行。
2023-07-19 10:26:381089 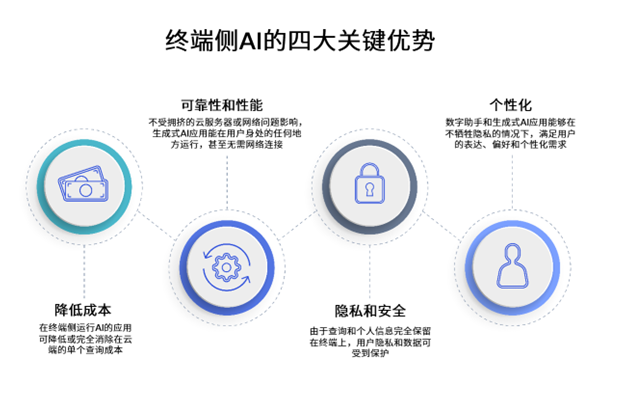
作為Meta首批合作伙伴之一,亞馬遜云科技宣布客戶可以通過Amazon SageMaker JumpStart來使用Meta開發的Llama 2基礎模型。
2023-07-21 16:10:591886 模型結構為Transformer結構,與Llama相同的是采用RMSNorm歸一化、SwiGLU激活函數、RoPE位置嵌入、詞表的構建與大小,與Llama不同的是增加GQA(分組查詢注意力),擴增了模型輸入最大長度,語料庫增加了40%。
2023-07-23 12:36:542113 
英特爾廣泛的AI硬件組合及開放的軟件環境,為Meta發布的Llama 2模型提供了極具競爭力的選擇,進一步助力大語言模型的普及,推動AI發展惠及各行各業。 大語言模型(LLM)在生成文本、總結和翻譯
2023-07-24 19:31:56912 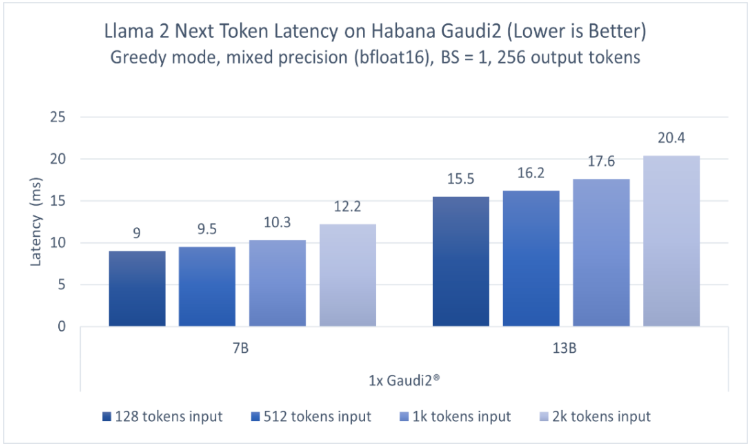
和 Windows 上支持 Llama 2 大型語言模型(LLM)系列 。Llama 2 旨在幫助開發者和組織構建生成式人工智能工具和體驗。Meta 和微軟共同致力于實現“讓人工智能惠及更多人”的愿景
2023-07-26 10:35:011047 
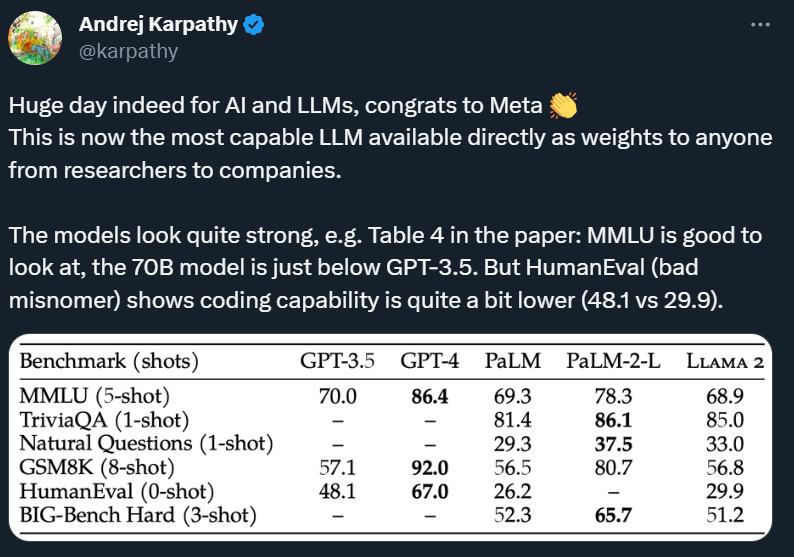
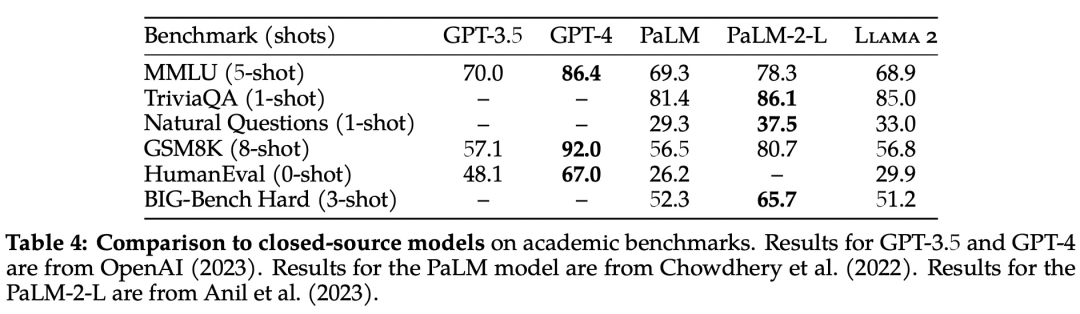
與所有LLM一樣,Llama 2偶爾會產生不正確或不可用的答案,但Meta介紹Llama的論文聲稱,它在學術基準方面與OpenAI的GPT 3.5不相上下,如MMLU(衡量LLM在57門STEM科目中的知識)和GSM8K(衡量LLM對數學的理解)。
2023-08-02 16:17:251297 
隨著 Llama 2 的逐漸走紅,大家對它的二次開發開始流行起來。前幾天,OpenAI 科學家 Karpathy 利用周末時間開發了一個明星項目 llama2.c,借助 GPT-4,該項目僅用
2023-08-02 16:25:281058 
IBM 企業就緒的 AI 和數據平臺?watsonx?不斷推出新功能。IBM 宣布,計劃在 watsonx 的 AI 開發平臺?watsonx.ai?上納入?Meta?的 700?億參數 Llama
2023-08-09 20:35:01959 Code Llama 的卓越功能源自行業領先的 AI 算法。其核心模型由包含編程語言、編碼模式和最佳實踐的大規模數據集訓練而成。自然語言處理(NLP)技術則讓 Code Llama 有能力理解開發者的輸入,并生成與上下文相匹配的代碼建議。
2023-08-21 15:15:021403 目前大部分開源LLM模型都是基于transformers庫來做的,它們的結構大部分都和Llama大同小異。
2023-08-23 11:44:074669 
Meta 發布的 Llama 2,是新的 SOTA 開源大型語言模型(LLM)。Llama 2 代表著 LLaMA 的下一代版本,可商用。Llama 2 有 3 種不同的大小 —— 7B、13B 和 70B 個可訓練參數。
2023-08-23 15:40:092136 2023 年 8 月 24 日 – MediaTek今日宣布利用Meta新一代開源大語言模型(LLM)Llama 2 以及MediaTek先進的AI處理器(APU)和完整的AI開發平臺
2023-08-24 13:41:03551 
今天,Meta發布了Code Llama,一款可以使用文本提示生成代碼的大型語言模型(LLM)。
2023-08-25 09:06:572439 
據路透社報道,meta計劃推出全新編程人工智能模型:Code Llama,可以根據文字提示來編寫計算機代碼,或協助開發者編程。這一AI工具將免費提供。
2023-08-25 11:39:001291 Meta公司表示,Meta發布了一種名為Code Llama的工具,該工具建立在其Llama 2大型語言模型的基礎上,用于生成新代碼和調試人工編寫的工作。 Code Llama將使用與Llama 2
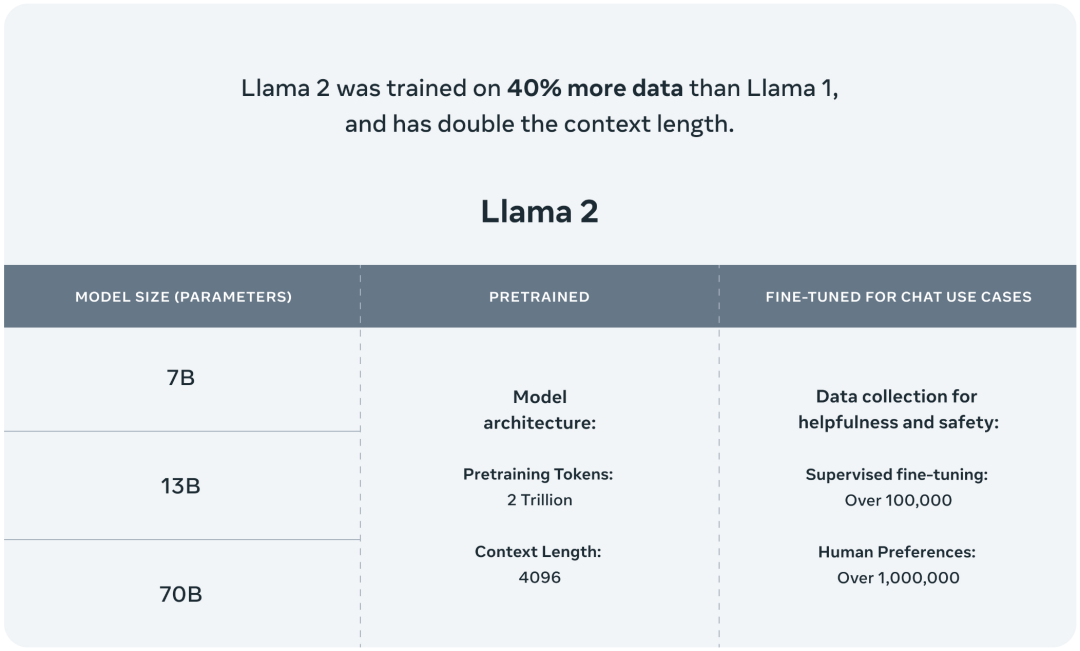
2023-08-28 16:56:392062 時隔半年后,Meta AI在周二發布了最新一代開源大模型Llama 2。相較于今年2月發布的Llama 1,訓練所用的token翻了一倍至2萬億,同時對于使用大模型最重要的上下文長度限制,Llama 2也翻了一倍。Llama 2包含了70億、130億和700億參數的模型。
2023-08-29 16:50:101919 針對 GPU 計算特點,在顯存允許的情況下,XTuner 支持將多條短數據拼接至模型最大輸入長度,以此最大化 GPU 計算核心的利用率,可以顯著提升訓練速度。例如,在使用 oasst1 數據集微調 Llama2-7B 時,數據拼接后的訓練時長僅為普通訓練的 50% 。
2023-09-04 16:12:263285 
1. 1800億參數,世界頂級開源大模型Falcon官宣!碾壓LLaMA 2,性能直逼GPT-4 原文: https://mp.weixin.qq.com/s
2023-09-08 19:15:022212 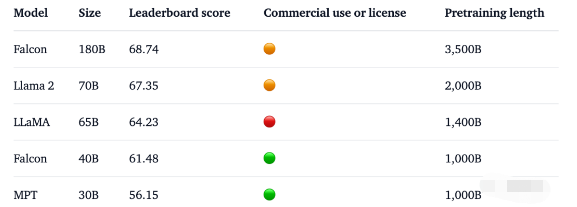
從 GPT-3,Gopher 到 LLaMA,大模型有更好的性能已成為業界的共識。但相比之下,單個 GPU 的顯存大小卻增長緩慢,這讓顯存成為了大模型訓練的主要瓶頸,如何在有限的 GPU 內存下訓練大模型成為了一個重要的難題。
2023-09-11 16:08:491166 
? 世界最強開源大模型 Falcon 180B 忽然火爆全網,1800億參數,Falcon 在 3.5 萬億 token 完成訓練,性能碾壓 Llama 2,登頂 Hugging Face 排行榜
2023-09-18 09:29:052713 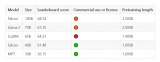
的浪潮信息NF5468服務器大幅提升了LLaMA大模型的微調訓練性能。目前該產品已具備交付能力,客戶可以進行下單采購。
2023-09-22 11:16:313293 使用QLoRA對Llama 2進行微調是我們常用的一個方法,但是在微調時會遇到各種各樣的問題
2023-09-22 14:27:212591 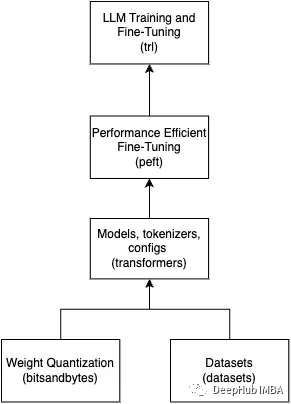
4,096,并對算法細節進行了優化,加速了推理速度,讓 Llama2 的性能有了很大的提升,能夠和 ChatGPT 相媲美。 Llama2 大模型旨在處理廣泛的語言任務,包括文本生成、機器翻譯、問題回答、代碼生成等等。該模型經過大規模的訓練,能夠理解并生成文本,為各種應用提供強大的自然語言處理能力。它的多
2023-10-13 20:35:021608 
MathOctopus在多語言數學推理任務中,表現出了強大的性能。MathOctopus-7B 可以將LLmMA2-7B在MGSM不同語言上的平均表現從22.6%提升到40.0%。更進一步,MathOctopus-13B也獲得了比ChatGPT更好的性能。
2023-11-08 10:37:57995 
在備受關注的人工智能領域,英偉達表示,h200將進一步提高性能。llama 2(700億個llm)的推理速度是h100的兩倍。未來的軟件更新有望為h200帶來更多的性能和改進。
2023-11-14 10:49:161904 微軟發布 Orca 2 LLM,這是 Llama 2 的一個調優版本,性能與包含 10 倍參數的模型相當,甚至更好。
2023-12-26 14:23:161097 據悉,Code Llama工具于去年8月份上線,面向公眾開放且完全免費。此次更新的Code Llama 70B不僅能處理更多復雜查詢,其在HumanEval基準測試中的準確率高達53%,超越GPT-3.5的48.1%,然而與OpenAI公布的GPT-4準確率(67%)仍有一定差距。
2024-01-30 10:36:181429 Meta近日宣布了其最新版本的AI代碼生成模型Code Llama70B,并稱其為“目前最大、最優秀的模型”。這一更新標志著Meta在AI代碼生成領域的持續創新和進步。
2024-01-30 18:21:042138 近日,Meta宣布推出了一款新的開源大模型Code Llama 70B,這是其“Code Llama家族中體量最大、性能最好的模型版本”。這款新模型提供三種版本,并免費供學術界和商業界使用。
2024-01-31 09:24:181731 Meta 發布的 LLaMA 2,是新的 sota 開源大型語言模型 (LLM)。LLaMA 2 代表著 LLaMA 的下一代版本,并且具有商業許可證。
2024-02-21 16:00:212196 此款模型支持Keras 3.0、PyTorch等工具進行調試,適用于低性能設備如筆記本電腦和物聯網,且被譽為相較同類產品性能更為優越,關鍵基準測試結果顯示其“超出Meta Llama-2模型顯著優勢”。
2024-02-22 10:16:47934 同一天,NVIDIA發布了H200的性能評估報告,表明在與美國Meta公司的大型語言模型——LLM“Llama 2”的對比中,H200使AI導出答案的處理速度最高提升了45%。
2024-04-01 09:36:592139 據了解,人工智能安全企業 DeepKeep日前發表了一份評估報告。報告指出,Meta公司旗下LlamA 2大型語言模型在13個風險評估類別中的表現僅為4項合格。
2024-04-18 14:45:261192 Meta決定將Llama 3的80億參數版開源,以期讓更多人能夠接觸到尖端的AI技術。全球范圍內的開發者、研究員以及對AI充滿好奇的人士均可參與其中,進行游戲開發、模型構建與實驗探索。
2024-04-19 10:21:191456 H100芯片的計算機集群訓練Llama 3。Llama 3最大參數規模超4000億,訓練token超15萬億,訓練數據規模差不多是Llama 2的七倍。而且訓練效率比Ll
2024-04-19 17:00:311518 高通和Meta合作優化Meta Llama 3大語言模型,支持在未來的驍龍旗艦平臺上實現終端側執行。
2024-04-20 09:13:081331 4月18日,Meta 正式發布 Llama 3,包括8B 和 70B 參數的大模型,官方號稱有史以來最強大的開源大模型。
2024-04-20 09:20:12954 
前天,智算領域迎來一則令人振奮的消息:Meta正式發布了備受期待的開源大模型——Llama3。Llama3的卓越性能Meta表示,Llama3在多個關鍵基準測試中展現出卓越性能,超越了業內先進的同類
2024-04-22 08:33:251380 
在人工智能領域,大型語言模型(LLMs)的發展速度令人震驚。2024年4月18日,Meta正式開源了LLama系列的新一代大模型Llama3,在這一領域中樹立了新的里程碑。
2024-04-26 09:42:141512 
英特爾豐富的AI產品——面向數據中心的至強處理器,邊緣處理器及AI PC等產品為開發者提供最新的優化,助力其運行Meta新一代大語言模型Meta Llama 3
2024-04-28 11:16:421197 高通與Meta攜手合作,共同推動Meta的Llama 3大語言模型(LLM)在驍龍驅動的各類終端設備上實現高效運行。此次合作致力于優化Llama 3在智能手機、個人電腦、VR/AR頭顯及汽車等領域的執行性能。
2024-05-09 10:37:58872 亞馬遜云科技近日宣布,Meta公司最新發布的兩款Llama 3基礎模型——Llama 3 8B和Llama 3 70B,現已正式上線并集成至Amazon SageMaker JumpStart平臺。這兩款先進的生成文本模型,具備8k的上下文長度,經過精心的預訓練和微調,旨在支持廣泛的AI應用場景。
2024-05-09 10:39:42838 Llama3 是Meta最新發布的開源大語言模型(LLM), 當前已開源8B和70B參數量的預訓練模型權重,并支持指令微調。
2024-05-10 10:34:031927 
Firefly開源團隊推出了Llama3部署包,提供簡易且完善的部署教程,過程無需聯網,簡單快捷完成本地化部署。點擊觀看Llama3快速部署教程:Step.1準備部署包進入Firefly下載中心
2024-06-06 08:02:301695 
近日,科技巨頭Meta在其X平臺上正式宣布推出了一款革命性的LLM編譯器,這一模型家族基于Meta Code Llama構建,并融合了先進的代碼優化和編譯器功能。LLM編譯器的推出,標志著Meta在人工智能領域的又一重大突破,將為軟件開發和編譯器優化帶來全新的可能性。
2024-06-29 17:54:012202 Meta 基金會創始人兼首席執行官馬克·扎克伯格先生近日在個人博客頁面(7月23日)發表長文,詳細闡述了他對于開源人工智能生態系統的構想與展望,尤其肯定了Llama作為“AI業界的Linux”所具有的巨大潛能。
2024-07-24 15:10:191223 科技巨頭Meta近期震撼發布了其最新的開源人工智能(AI)模型——Llama 3.1,這一舉措標志著Meta在AI領域的又一重大突破。Meta創始人馬克·扎克伯格親自站臺,盛贊Llama 3.1為“業內頂尖水準”的AI模型,并自信地表示它能夠與OpenAI、谷歌等業界巨頭的同類產品一較高下。
2024-07-24 18:25:462084 近日,Meta對外宣布推出迄今為止最強大的開源模型——Llama3.1 405B,同時還發布了全新優化升級的70B和8B版本,技術革新的浪潮再次洶涌來襲!在此,我們滿懷欣喜地向您宣告,PerfXCloud平臺現已成功接入Llama3.1,為您呈上超乎想象的開發新體驗。
2024-07-25 10:26:321089 本文從搭建環境開始,一步一步幫助讀者實現只用五行代碼便可將Llama3.1模型部署在英特爾 酷睿 Ultra 處理器上。
2024-07-26 09:51:433958 
我們很高興宣布,Llama 3.1 系列模型已添加到 Vertex AI Model Garden,這包括全新的 405B,即 Meta 迄今為止功能最強大、用途最廣泛的模型。這些模型的添加,表明
2024-08-02 15:42:421031 北京2024年8月23日?/美通社/ -- 近日,浪潮信息發布源2.0-M32大模型4bit和8bit量化版,性能比肩700億參數的LLaMA3開源大模型。4bit量化版推理運行顯存僅需
2024-08-25 22:06:251028 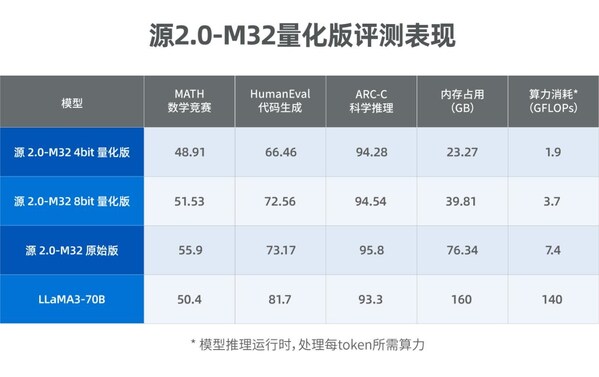
近日,PerfXCloud完成重大更新,上架了面壁小鋼炮 MiniCPM 系列的端側多模態模型 MiniCPM-Llama3-V 2.5,現已對平臺用戶免費開放體驗!
2024-08-27 18:20:151067 
英偉達公司宣布推出 Llama-3.1-Nemotron-51B AI 模型,這個AI大模型是源自 Meta 公司的 Llama-3.1-70B?大模型,基于使用了神經架構搜索(NAS)方法,推理
2024-09-26 17:30:061275 近日,AMD在Huggingface平臺上正式推出了自家首款“小語言模型”——AMD-Llama-135m。這款模型以其獨特的推測解碼功能,吸引了業界的廣泛關注。
2024-09-30 16:38:231913 亞馬遜云科技宣布,Meta的新一代模型Llama 3.2,包括其首款多模態模型,現已在Amazon Bedrock和Amazon SageMaker中正式可用。
2024-10-11 09:20:011216 亞馬遜云科技近日宣布,Meta公司的新一代模型Llama 3.2已在其平臺上正式上線。該模型包括Meta首款多模態模型,現已在Amazon Bedrock和Amazon SageMaker中全面可用。
2024-10-11 18:08:021002 前面我們分享了《三步完成Llama3在算力魔方的本地量化和部署》。2024年9月25日,Meta又發布了Llama3.2:一個多語言大型語言模型(LLMs)的集合。
2024-10-12 09:39:152075 
在人工智能領域,語言模型的發展一直是研究的熱點。隨著技術的不斷進步,我們見證了從簡單的關鍵詞匹配到復雜的上下文理解的轉變。 一、Llama 3 語言模型的核心功能 上下文理解 :Llama 3 能夠
2024-10-27 14:15:511221 隨著人工智能技術的飛速發展,我們見證了一代又一代的AI模型不斷突破界限,為各行各業帶來革命性的變化。在這場技術競賽中,Llama 3和GPT-4作為兩個備受矚目的模型,它們代表了當前AI領域的最前
2024-10-27 14:17:081723 使用LLaMA 3(Large Language Model Family of AI Alignment)進行文本生成,可以通過以下幾種方式實現,取決于你是否愿意在本地運行模型或者使用現成的API
2024-10-27 14:21:361612 在自然語言處理(NLP)的快速發展中,我們見證了從基于規則的系統到基于機器學習的模型的轉變。隨著深度學習技術的興起,NLP領域迎來了新的突破。Llama 3,作為一個假設的先進NLP模型,代表了這一
2024-10-27 14:22:511073 Llama 3 模型,假設是指一個先進的人工智能模型,可能是一個虛構的或者是一個特定領域的術語。 1. 數據預處理 數據是任何機器學習模型的基礎。在訓練之前,確保數據質量至關重要。 數據清洗 :去除
2024-10-27 14:24:001134 在當今快速發展的技術時代,各行各業都在尋求通過人工智能(AI)來提高效率、降低成本并增強用戶體驗。Llama 3,作為一個先進的AI平臺,以其強大的數據處理能力和用戶友好的界面,成為了眾多行業的新寵
2024-10-27 14:28:121115 1. 設計與構建質量 Llama 3的設計延續了其前代產品的簡潔風格,同時在細節上進行了優化。機身采用了輕質材料,使得整體重量得到了有效控制,便于攜帶。此外,Llama 3的表面處理工藝也有
2024-10-27 14:30:511238 評估Llama 3(假設這是一個虛構的人工智能模型或系統)的輸出質量,可以通過以下幾個步驟來進行: 定義質量標準 : 在開始評估之前,需要明確什么是“高質量”的輸出。這可能包括準確性、相關性、一致性
2024-10-27 14:32:461022 Llama 3模型與其他AI工具的對比可以從多個維度進行,包括但不限于技術架構、性能表現、應用場景、定制化能力、開源與成本等方面。以下是對Llama 3模型與其他一些主流AI工具的對比分析: 一
2024-10-27 14:37:041677 優化輸入提示(prompt engineering)是提高人工智能模型輸出質量的關鍵步驟。對于Llama 3這樣的模型,優化輸入提示可以幫助模型更準確地理解用戶的意圖,從而生成更相關和高質量的內容
2024-10-27 14:39:461184 在人工智能領域,對話系統的發展一直是研究的熱點之一。隨著技術的進步,我們見證了從簡單的基于規則的系統到復雜的基于機器學習的模型的轉變。Llama 3,作為一個假設的先進對話系統,其架構設計融合了
2024-10-27 14:41:021764 在人工智能(AI)的快速發展中,開源AI模型扮演著越來越重要的角色。它們不僅推動了技術的創新,還促進了全球開發者社區的合作。Llama 3,作為一個新興的AI項目,與開源AI模型的關系密切,這種關系
2024-10-27 14:42:541115 在科技迅猛發展的今天,人工智能和機器學習已經成為推動社會進步的重要力量。Llama 3,作為一個劃時代的產品,正以其獨特的設計理念和卓越的性能,預示著未來科技的新方向。 一、Llama 3的核心
2024-10-27 14:44:581192 近日,Meta在開源Llama 3.2的1B與3B模型后,再次為人工智能領域帶來了新進展。10月24日,Meta正式推出了這兩個模型的量化版本,旨在進一步優化模型性能,拓寬其應用場景。
2024-10-29 11:05:251251 Ollama 是一個開源的大語言模型服務工具,它的核心目的是簡化大語言模型(LLMs)的本地部署和運行過程,請參考《Gemma 2+Ollama在算力魔方上幫你在LeetCode解題》,一條命令完成
2024-11-23 17:22:254547 
Llama 3.2 模型集擴展了 Meta Llama 開源模型集的模型陣容,包含視覺語言模型(VLM)、小語言模型(SLM)和支持視覺的更新版 Llama Guard 模型。與 NVIDIA 加速
2024-11-20 09:59:471373 的Llama 3.3 70B模型在性能上表現出色,與同行業的其他大模型相比毫不遜色。更重要的是,其在成本上展現出了更強的競爭力,使得更多的企業和開發者能夠負擔得起這一先進的技術。 這兩大模型的推出,再次掀起了AI領域的競爭浪潮。隨著技術的不斷進化,AI的使用門檻正在逐步降低,不
2024-12-09 14:50:231053 ?在人工智能領域,Meta的最新動作再次引起了全球的關注。今天,我們見證了Meta發布的 Llama 3.3 70B 模型,這是一個開源的人工智能模型,它不僅令人印象深刻,而且在性能上達到了一個
2024-12-18 16:46:37951 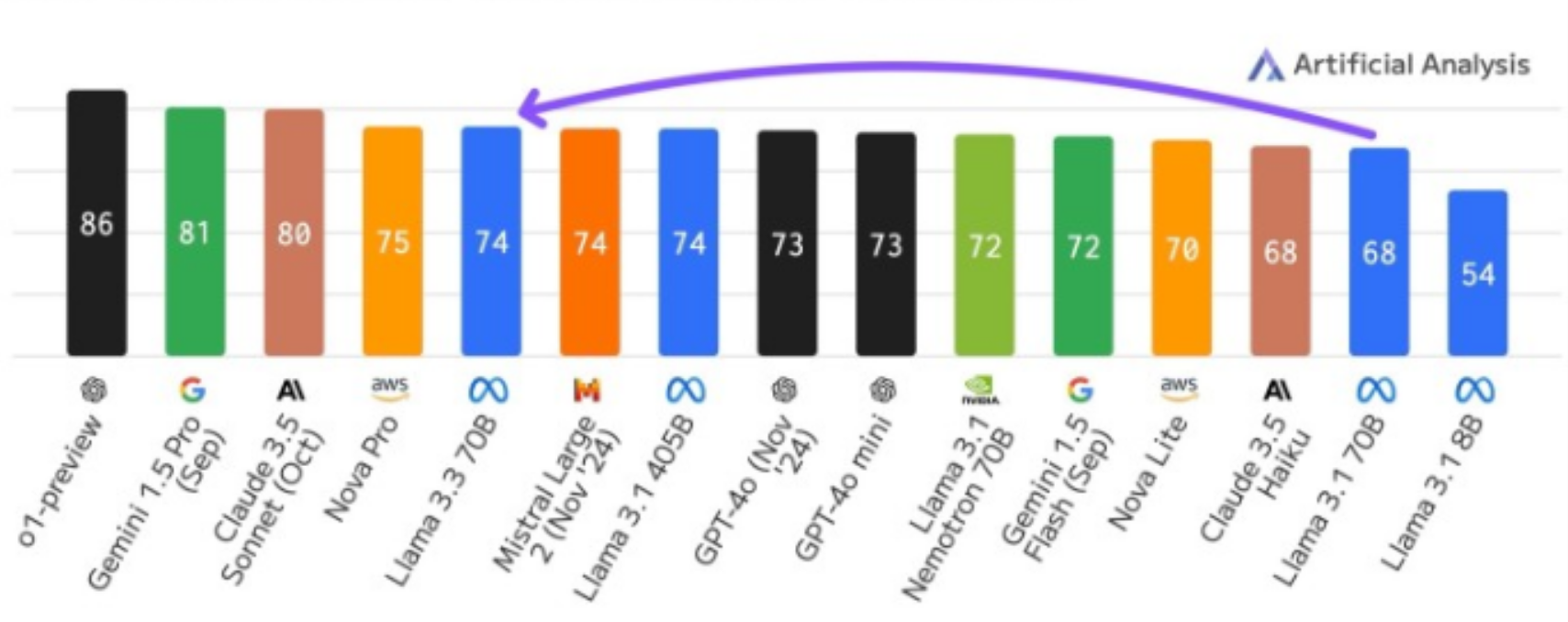
作為 NVIDIA NIM 微服務,開放式 Llama Nemotron 大語言模型和 Cosmos Nemotron 視覺語言模型可在任何加速系統上為 AI 智能體提供強效助力。
2025-01-09 11:11:401330
 電子發燒友App
電子發燒友App
















 工商網監
工商網監
評論