") 怎樣使用QLoRA對(duì)Llama 2進(jìn)行微調(diào)呢?
怎樣使用QLoRA對(duì)Llama 2進(jìn)行微調(diào)呢?

使用QLoRA對(duì)Llama 2進(jìn)行微調(diào)是我們常用的一個(gè)方法,但是在微調(diào)時(shí)會(huì)遇到各種各樣的問(wèn)題,所以在本文中,將嘗試以詳細(xì)注釋的方式給出一些常見(jiàn)問(wèn)題的答案。這些問(wèn)題是特定于代碼的,大多數(shù)注釋都是針對(duì)所涉及的開(kāi)源庫(kù)以及所使用的方法和類的問(wèn)題。
導(dǎo)入庫(kù)
對(duì)于大模型,第一件事是又多了一些不熟悉的Python庫(kù)。
!pip install -q peft==0.4.0 bitsandbytes==0.40.2 transformers==4.31.0 trl==0.4.7
我們必須首先安裝accelerate, peft, bitsandbytes, transformers和trl。除了transformers,其他的庫(kù)都很陌生
transformers是這里最古老的庫(kù),PyPI上最早的版本(2.0.0)可以追溯到2019年。它是huggingface發(fā)布的庫(kù),可以快速訪問(wèn)文本,圖像和音頻(從hugs的API下載)的機(jī)器學(xué)習(xí)模型。它還提供訓(xùn)練和微調(diào)模型的功能,并可以HuggingFace模型中心共享這些模型。
庫(kù)沒(méi)有像Pytorch或Tensorflow那樣從頭開(kāi)始構(gòu)建神經(jīng)網(wǎng)絡(luò)的抽象層和模塊,它提供了專門針對(duì)模型進(jìn)行優(yōu)化的訓(xùn)練和推理api。transformer是用于LLM微調(diào)的關(guān)鍵Python庫(kù)之一,因?yàn)槟壳按蟛糠值腖LM都是可以通過(guò)它來(lái)加載使用。
bitsandbytes是一個(gè)相對(duì)較新的庫(kù),PyPI上最早的版本時(shí)2021年發(fā)布的。它是CUDA自定義函數(shù)的輕量級(jí)包裝,專門為8位優(yōu)化器、矩陣乘法和量化而設(shè)計(jì)。它主要提供了優(yōu)化和量化模型的功能,特別是對(duì)于llm和transformers模型。它還提供了8位Adam/AdamW、 SGD momentum、LARS、LAMB等函數(shù)。bitsandbytes的目標(biāo)是通過(guò)8位操作實(shí)現(xiàn)高效的計(jì)算和內(nèi)存使用從而使llm更易于訪問(wèn)。
通過(guò)利用8位優(yōu)化和量化技術(shù)可以提高模型的性能和效率。在較小尺寸的消費(fèi)類gpu(如RTX 3090)上運(yùn)行l(wèi)lm存在內(nèi)存瓶頸。所以人們一直對(duì)試圖減少運(yùn)行l(wèi)lm的內(nèi)存需求的權(quán)重量化技術(shù)進(jìn)行研究。bitsandbytes的想法是量化模型權(quán)重的浮點(diǎn)精度,從較大的精度點(diǎn)(如FP32)到較小的精度點(diǎn)(如Int8) (4x4 Float16)。
有一些技術(shù)可以將FP32量化為Int8,包括abmax和零點(diǎn)量化,但由于這些技術(shù)的局限性,bitsandbytes庫(kù)的創(chuàng)建者共同撰寫了LLM.int8()論文以及8位優(yōu)化器,為llm提供有效的量化方法。所以由于bitsandbytes庫(kù)提供的量化技術(shù),這在很大程度上讓我們?cè)谙M(fèi)級(jí)的GPU上可以微調(diào)更大的模型。
Peft允許我們減少將LLM(或其部分)加載到工作內(nèi)存中以進(jìn)行微調(diào)的內(nèi)存需求。與使用較小深度學(xué)習(xí)模型的遷移學(xué)習(xí)技術(shù)不同,在遷移學(xué)習(xí)技術(shù)中,我們需要凍結(jié)像AlexNet這樣的神經(jīng)網(wǎng)絡(luò)的較低層,然后在新任務(wù)上對(duì)分類層進(jìn)行完全微調(diào),而使用llm進(jìn)行這種微調(diào)的成本是巨大的。Parameter Efficient Fine-Tuning(PEFT)方法是一組使llm適應(yīng)下游任務(wù)的方法,例如在內(nèi)存受限的設(shè)備(如T4GPU 提供16GB VRAM)上進(jìn)行摘要或問(wèn)答。
通過(guò)Peft對(duì)LLM的部分進(jìn)行微調(diào),仍然可以獲得與完全微調(diào)相比的結(jié)果。如LoRA和Prefix Tuning是相當(dāng)成功的。peft庫(kù)是一個(gè)HuggingFace庫(kù),它提供了這些微調(diào)方法,這是一個(gè)可以追溯到2023年1月的新庫(kù)。在本文中我們將使用QLoRA,這是一種用于量化llm的低秩自適應(yīng)或微調(diào)技術(shù)。
trl是另一個(gè)HuggingFace庫(kù),trl其實(shí)是自2021年發(fā)布的,但是在2023年1月才被人們熱傳。TRL是Transformer Reinforcement Learning的縮寫也就是Transformer 強(qiáng)化學(xué)習(xí)。它提供了在訓(xùn)練和微調(diào)LLM的各個(gè)步驟中的不同算法的實(shí)現(xiàn)。包括監(jiān)督微調(diào)步驟(SFT),獎(jiǎng)勵(lì)建模步驟(RM)和近端策略優(yōu)化(PPO)步驟。trl也將peft作為一個(gè)依賴項(xiàng),所以可以使用帶有peft方法(例如LoRA)的SFT訓(xùn)練器。
dataset雖然沒(méi)有包含在我們之前的安裝包列表中(這是因?yàn)樗莟ransformers的一個(gè)依賴項(xiàng)),但dataset庫(kù)是huggingface生態(tài)系統(tǒng)中的另一個(gè)重要部分。它可以方便的訪問(wèn)HuggingFace托管的許多公共數(shù)據(jù)集,也就是說(shuō)省去了我們自己寫dataset和dataloader的時(shí)間。
上面這些庫(kù)對(duì)于LLM的任何工作都是至關(guān)重要的。這里做了一個(gè)簡(jiǎn)單的圖片來(lái)總結(jié)這些庫(kù)是如何組合在一起的。
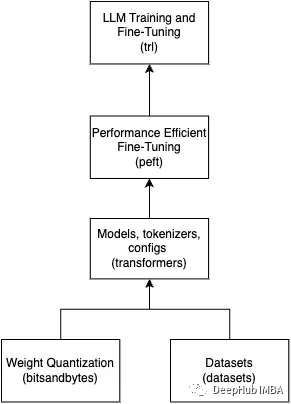
下面讓我們看一下導(dǎo)入
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging,
)
from peft import LoraConfig, PeftModel
from trl import SFTTrainer
我們繼續(xù)分析導(dǎo)入
torch是我們很熟悉的深度學(xué)習(xí)庫(kù),這里我們不需要torch的那些低級(jí)功能,但是它是transformers和trl的依賴,在這里我們需要使用torch來(lái)獲取dtypes(數(shù)據(jù)類型),比如torch.Float16以及檢查GPU的工具函數(shù)。
load_dataset所做的就是加載數(shù)據(jù)集,但是它從HuggingFace數(shù)據(jù)集中心下載到本地。所以這是一個(gè)在線加載程序,但它既高效又簡(jiǎn)單,只需要一行代碼。
dataset = load_dataset(dataset_name, split="train")
因?yàn)槟P秃芏嗨詔ransformer庫(kù)提供了一組稱為Auto classes的類,這些類給出了預(yù)訓(xùn)練模型的名稱/路徑,它可以自動(dòng)推斷出正確的結(jié)構(gòu)并檢索相關(guān)模型。這個(gè)AutoModelForCausalLM是一個(gè)通用的Auto類,用于加載用于因果語(yǔ)言建模的模型。
對(duì)于transformers,HuggingFace提供了兩種類型的語(yǔ)言建模,因果和掩碼掩蔽。因果語(yǔ)言模型包括;GPT-3和Llama,這些模型預(yù)測(cè)標(biāo)記序列中的下一個(gè)標(biāo)記,以生成與輸入數(shù)據(jù)語(yǔ)義相似的文本。AutoModelForCausalLM類將從模型中心檢索因果模型,并加載模型權(quán)重,從而初始化模型。from_pretrained()方法為我們完成了這項(xiàng)工作。
model_name = "NousResearch/Llama-2-7b-chat-hf"
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map=device_map
)
AutoTokenizer是對(duì)文本數(shù)據(jù)進(jìn)行標(biāo)記化。它提供了一種無(wú)需顯式指定標(biāo)記器類就可以初始化和使用不同模型的標(biāo)記器的方便的方法。它也是一個(gè)通用的Auto類,所以它可以根據(jù)提供的模型名稱或路徑自動(dòng)選擇適當(dāng)?shù)臉?biāo)記器。
標(biāo)記器將輸入文本轉(zhuǎn)換為標(biāo)記,這些標(biāo)記是NLP模型使用的基本文本單位。它還提供了額外的功能,如填充、截?cái)嗪妥⒁饬ρ诖a等。AutoTokenizer簡(jiǎn)化了為NLP任務(wù)對(duì)文本數(shù)據(jù)進(jìn)行標(biāo)記的過(guò)程。我們可以看到在下面初始化AutoTokenizer,后面我們會(huì)使用SFTTrainer將初始化的AutoTokenizer作為參數(shù)。
model_name = "NousResearch/Llama-2-7b-chat-hf"
# Load LLaMA tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
BitsAndBytesConfig,前面已經(jīng)說(shuō)了我們使用bitsandbytes進(jìn)行量化。transformer庫(kù)最近添加了對(duì)bitsandbytes的全面支持,因此使用BitsandBytesConfig可以配置bitsandbytes提供的任何量化方法,例如LLM.int8、FP4和NF4。將量化配置傳遞給AutoModelForCausalLM初始化器,這樣在加載模型權(quán)重時(shí)就會(huì)直接使用量化的方法。
#bits and byte config
bnb_config = BitsAndBytesConfig(
load_in_4bit=use_4bit,
bnb_4bit_quant_type=bnb_4bit_quant_type,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=use_nested_quant,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config, #pass to AutoModelForCausalLM
device_map=device_map
)
TrainingArguments非常簡(jiǎn)單。它用于存儲(chǔ)SFTTrainer的所有訓(xùn)練參數(shù)。SFFTrainer接受不同類型的參數(shù),TrainingArguments幫助我們將所有相關(guān)的訓(xùn)練參數(shù)組織到一個(gè)數(shù)據(jù)類中保持代碼的整潔和有組織。
還有一些很好的工具類可以與TrainingArguments一起使用,比如HfArgumentParser可以為TrainingArguments創(chuàng)建一個(gè)參數(shù)解析器,這對(duì)CLI應(yīng)用程序很有用。
#TrainingArguments
training_arguments = TrainingArguments(
output_dir=output_dir,
num_train_epochs=num_train_epochs,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
weight_decay=weight_decay,
fp16=fp16,
bf16=bf16,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=group_by_length,
lr_scheduler_type=lr_scheduler_type,
report_to="tensorboard"
)
在完成微調(diào)之后,我們將使用pipeline進(jìn)行推理。可以選擇各種管道任務(wù)的列表,像“圖像分類”,“文本摘要”等。還可以為任務(wù)選擇要使用的模型。為了定制也可以添加一個(gè)參數(shù)來(lái)進(jìn)行某種形式的預(yù)處理,如標(biāo)記化或特征提取。
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
從transformer導(dǎo)入的最后一個(gè)內(nèi)容是logging。這是一個(gè)日志系統(tǒng),這在調(diào)試代碼時(shí)非常有用。
logging.set_verbosity(logging.CRITICAL)
從peft庫(kù)中導(dǎo)入的LoraConfig數(shù)據(jù)類是一個(gè)配置類,它主要存儲(chǔ)初始化LoraModel所需的配置,LoraModel是PeftTuner的一個(gè)實(shí)例。我們將此配置傳遞給SFTTrainer,它將使用該配置初始化適當(dāng)?shù)膖uner。
# Load LoRA configuration
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM",
)
PeftModel,一旦我們使用一種peft方法(如LoRA)進(jìn)行微調(diào),就需要將LoRA適配器權(quán)重保存到磁盤并在使用時(shí)將它們加載回內(nèi)存。PEFT模塊微調(diào)的權(quán)重,與基本模型權(quán)重是分開(kāi)。使用PeftModel,還可以選擇將將base_model權(quán)重與新微調(diào)的適配器權(quán)重合并(調(diào)整),這樣就得到了一個(gè)完整的新模型。PeftModel.from_pretrained()從內(nèi)存中加載適配器權(quán)重,merge_and_unload()方法將它們與base_model合并。
# Reload base_model in FP16 and merge it with LoRA weights
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map=device_map,
)
model = PeftModel.from_pretrained(base_model, new_model)
model = model.merge_and_unload()
最后一個(gè)導(dǎo)入是SFTTrainer。SFTTrainer是transformer Trainer類的子類。Trainer是一個(gè)功模型訓(xùn)練的泛化API。SFTTrainer在此基礎(chǔ)上增加了對(duì)參數(shù)微調(diào)的支持。有監(jiān)督的微調(diào)步驟是訓(xùn)練因果語(yǔ)言模型(如Llama)用于下游任務(wù)(如指令遵循)的關(guān)鍵步驟。
SFTTrainer支持PEFT,因此我們將與LoRA一起使用SFTTrainer。然后,SFTTrainer將使用LoRA執(zhí)行監(jiān)督微調(diào)。然后我們可以運(yùn)行訓(xùn)練器(train())并保存權(quán)重(save_pretrained())。
#Initialize the SFTTrainer object
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
packing=packing,
)
# Train model
trainer.train()
# Save trained model
trainer.model.save_pretrained(new_model)
對(duì)于引用,我們也總結(jié)了一張圖片

訓(xùn)練參數(shù)
現(xiàn)在我們知道了需要哪些庫(kù)來(lái)調(diào)優(yōu)Llama 2(或任何LLM),也知道了這些庫(kù)中需要的類,并且了解了這些類的功能。下面就是對(duì)前面導(dǎo)入的參數(shù)的介紹
模型和數(shù)據(jù)集名稱:
# The model that you want to train from the Hugging Face hub
model_name = "NousResearch/Llama-2-7b-chat-hf"
# The instruction dataset to use
dataset_name = "mlabonne/guanaco-llama2-1k"
# Fine-tuned model name
new_model = "llama-2-7b-miniguanaco"
model_name、dataset_name和new_model。這些名稱遵循HuggingFace模型及其hub上的數(shù)據(jù)集名稱的格式。
birushuo 給一個(gè)名字“NousResearch/ Llama-2-7b-chat-hf”這個(gè)名字的第一部分NousResearch是一個(gè)研究機(jī)構(gòu),也就是它HuggingFace賬戶的名稱,第二部分是模型名稱lama-2 - 7b-chat-hf。模型命名的建議是給模型提供描述性的名稱,包括有用的信息,如獨(dú)特的模型名稱(lama-2),關(guān)鍵參數(shù)信息(7b),以及一些關(guān)于模型如何工作的其他有用信息(chat-hf)。我們?cè)趎ew_model名稱llama-2-7b-miniguanaco中看到了同樣的規(guī)則,這是我們分配給微調(diào)模型的名稱。這里附加了在miniguanaco上進(jìn)行微調(diào)的數(shù)據(jù)集的名稱。
QLoRA 參數(shù):
# LoRA attention dimension
lora_r = 64
# Alpha parameter for LoRA scaling
lora_alpha = 16
# Dropout probability for LoRA layers
lora_dropout = 0.1
我們將使用的參數(shù)是r (lora_r)、lora_alpha和lora_dropout。這些參數(shù)對(duì)于LoRA來(lái)說(shuō)是最重要的,要理解其中的原因,必須深入了解LoRA的論文,我們只做簡(jiǎn)單的總結(jié):
在神經(jīng)網(wǎng)絡(luò)中,反向傳播算法計(jì)算期望值和實(shí)際值之間的誤差,然后用這個(gè)誤差來(lái)計(jì)算delta,這是神經(jīng)網(wǎng)絡(luò)中權(quán)重對(duì)e的貢獻(xiàn)。如果你有一個(gè)神經(jīng)網(wǎng)絡(luò)的初始權(quán)值W0那么對(duì)于誤差e,我們計(jì)算delta_W0 =?W。然后使用?W來(lái)更新權(quán)重W0 +?W,以減小誤差e。LoRA提出將?W分解為兩組低秩矩陣A和B,使W0 +?W = W0 + BA。而不是使用完整的?W更新,我們使用較小的低秩更新矩陣BA,這就是我們?nèi)绾螌?shí)現(xiàn)相同效率和更低的計(jì)算需求。如果?W的大小為(d × k) (W0的大小),則我們將?W分解為兩個(gè)矩陣:B和A,維度分別為(d × r)和(r × k),其中r為秩。
LoraConfig中的參數(shù)r (lora_r)是決定更新矩陣BA形狀的秩。根據(jù)論文可以設(shè)置一個(gè)小的秩,并且得到很好的結(jié)果。當(dāng)我們更新W0時(shí),可以通過(guò)使用縮放因子α來(lái)控制BA的影響,這個(gè)縮放因子作為學(xué)習(xí)率。比例因子是我們的第二個(gè)參數(shù)(lora_alpha)。最后設(shè)置lora_dropput,這是正則化的典型dropput。
BitsandBytes參數(shù):
# Activate 4-bit precision base model loading
use_4bit = True
# Compute dtype for 4-bit base models
bnb_4bit_compute_dtype = "float16"
# Quantization type (fp4 or nf4)
bnb_4bit_quant_type = "nf4"
# Activate nested quantization for 4-bit base models (double quantization)
use_nested_quant = False
我們正在使用一種稱為QLoRA的量化版本的LoRA,這意味著我們希望在LoRA微調(diào)中使用量化,將量化應(yīng)用于我們前面提到的更新權(quán)重(以及其他可以量化的操作)。
參數(shù)use_4bit(第6行)設(shè)置為True,以使用高保真的4位微調(diào),這是后來(lái)在QLoRA論文中引入的,以實(shí)現(xiàn)比LLM.int8論文中引入的8位量化更低的內(nèi)存要求。
設(shè)置bnb_4bit_compute_dtype(第9行),這是執(zhí)行計(jì)算的數(shù)據(jù)類型(float16)。也就是說(shuō)雖然將權(quán)重通過(guò)4位量化存儲(chǔ),但計(jì)算還是發(fā)生在16位或32位。
使用bnb_4bit_quant_type(第12行),nf4,根據(jù)QLoRA論文,nf4顯示了更好的理論和經(jīng)驗(yàn)性能。
參數(shù)use_nested_quant設(shè)置為False,并將其傳遞給bnb_4bit_use_double_quant。模型在第一次量化之后啟用第二次量化,從而為每個(gè)參數(shù)額外節(jié)省0.4位。
上面一些參數(shù)都是QLoRA的論文提供,如果想深入了解,請(qǐng)查看論文或我們以前的文章
在本文中我們選擇NF4量化FP16 (float16)精度進(jìn)行計(jì)算后,我們應(yīng)該對(duì)Colab T4 GPU (16 GB VRAM)沒(méi)有內(nèi)存限制。我們做個(gè)簡(jiǎn)單的計(jì)算:如果使用Llama-2-7B(70億params)和FP16(沒(méi)有量化),我們得到7B × 2字節(jié)= 14 GB(所需的VRAM)。使用4位量化,我們得到7B × 0.5字節(jié)= ~ 4gb(所需的VRAM)。
訓(xùn)練參數(shù):
# Output directory where the model predictions and checkpoints will be stored
output_dir = "./results"
# Number of training epochs
num_train_epochs = 1
# Enable fp16/bf16 training (set bf16 to True with an A100)
fp16 = False
bf16 = False
# Batch size per GPU for training
per_device_train_batch_size = 4
# Batch size per GPU for evaluation
per_device_eval_batch_size = 4
# Number of update steps to accumulate the gradients for
gradient_accumulation_steps = 1
# Maximum gradient normal (gradient clipping)
max_grad_norm = 0.3
# Initial learning rate (AdamW optimizer)
learning_rate = 2e-4
# Weight decay to apply to all layers except bias/LayerNorm weights
weight_decay = 0.001
# Optimizer to use
optim = "paged_adamw_32bit"
# Learning rate schedule (constant a bit better than cosine)
lr_scheduler_type = "constant"
# Ratio of steps for a linear warmup (from 0 to learning rate)
warmup_ratio = 0.03
# Group sequences into batches with same length
# Saves memory and speeds up training considerably
group_by_length = True
# Save checkpoint every X updates steps
save_steps = 25
# Log every X updates steps
logging_steps = 25
Output_dir(第6行):這是設(shè)置存儲(chǔ)模型預(yù)測(cè)和檢查點(diǎn)的位置,還包括日志
num_train_epochs(第9行):訓(xùn)練的輪次
fp16和bf16(第12行和第13行):我們將它們都設(shè)置為false,因?yàn)槲覀儾粫?huì)使用混合精度訓(xùn)練,因?yàn)橐呀?jīng)有QLoRA了。
per_device_train_batch_size和per_device_eval_batch_size(第16行和第19行):將它們都設(shè)置為4。有足夠的內(nèi)存,可以設(shè)置更高的批處理大小(>8),這將加快訓(xùn)練速度。
Gradient_accumulation_steps(第22行):“梯度累積”指的是在實(shí)際更新模型權(quán)重之前執(zhí)行的向前和向后傳遞的次數(shù)(更新步驟)。在每一次向前和向后傳遞期間,梯度被計(jì)算并累積在一批數(shù)據(jù)上。在累積指定步數(shù)的梯度之后,然后執(zhí)行反向傳遞,計(jì)算這些步驟的平均梯度并相應(yīng)地更新模型權(quán)重。這種方法有助于有效地模擬更大批大小,它減少了每次向前和向后傳遞的內(nèi)存需求。
max_gradient_norm(第25行):如果梯度的范數(shù)(幅度)超過(guò)某個(gè)閾值(由max_grad_norm參數(shù)指定),則梯度裁剪縮小梯度。如果梯度范數(shù)大于max_grad_norm,則梯度將按比例縮小,如果梯度規(guī)范已經(jīng)低于max_grad_norm,則不應(yīng)用縮放。建議從max_grad_norm的較高值開(kāi)始,然后在多個(gè)訓(xùn)練迭代中慢慢縮小它。
learning_rate(第28行):AdamW的學(xué)習(xí)率。AdamW是流行的Adam優(yōu)化器的一個(gè)變體。它結(jié)合了Adam優(yōu)化器和權(quán)重衰減正則化的技術(shù)。
weight_decay(第31行):權(quán)重衰減,也稱為L(zhǎng)2正則化或權(quán)重正則化,是機(jī)器學(xué)習(xí)和深度學(xué)習(xí)中常用的一種正則化技術(shù),用于防止模型對(duì)訓(xùn)練數(shù)據(jù)的過(guò)擬合。它的工作原理是在損失函數(shù)中添加一個(gè)懲罰項(xiàng)。我們使用AdamW和權(quán)重衰減是有意義的,因?yàn)闄?quán)重衰減在微調(diào)期間特別有用,因?yàn)樗兄诜乐惯^(guò)擬合,并確保模型適應(yīng)新任務(wù),同時(shí)保留預(yù)訓(xùn)練中的一些知識(shí)。
optim(第34行):使用AdamW優(yōu)化器,“paged_adamw_32bit”似乎是AdamW優(yōu)化器的一個(gè)特定實(shí)現(xiàn)或變體,我們找到任何關(guān)于他的信息,所以如果你有關(guān)于這方面的信息,請(qǐng)?jiān)谠u(píng)論中留下,謝謝!
lr_scheduler_type(第37行):通常我們?cè)谏疃葘W(xué)習(xí)模型的訓(xùn)練期間使用學(xué)習(xí)率調(diào)度器,以隨時(shí)間調(diào)整學(xué)習(xí)率。
warmup_ratio(第40行):這里我們將“warmup_ratio”設(shè)置為0.03。由于每個(gè)epoch有250個(gè)訓(xùn)練步驟,熱身階段將持續(xù)到前8步(250的3%),在此期間,學(xué)習(xí)率將從0線性增加到指定的初始值2e-4。熱身階段通常用于穩(wěn)定訓(xùn)練,防止梯度爆炸,并允許模型開(kāi)始有效地學(xué)習(xí)。
group_by_length(第44行):這個(gè)參數(shù)設(shè)置為True,會(huì)加快了訓(xùn)練速度。當(dāng)group_by_length設(shè)置為True時(shí),它將訓(xùn)練數(shù)據(jù)集中大致相同長(zhǎng)度的樣本分組到同一批中。這意味著具有相似長(zhǎng)度的序列被分組在一起,減少了所需的填充。也就是說(shuō)批將具有更相似長(zhǎng)度的序列,這將最小化所應(yīng)用的填充量。當(dāng)批處理具有一致的大小時(shí)GPU處理通常更有效,從而縮短訓(xùn)練時(shí)間,這是從LSTM時(shí)代就開(kāi)始的一個(gè)加速技巧。
save_steps和logging_steps(第47行和第50行):這里將兩個(gè)參數(shù)都設(shè)置為25,以控制記錄訓(xùn)練信息和保存檢查點(diǎn)的間隔步驟。
SFTTrainer參數(shù):
max_seq_length = None
# Pack multiple short examples in the same input sequence to increase efficiency
packing = False
最后參數(shù)是特定于SFTTrainer的。
max_seq_length:將max_seq_length設(shè)置為None允許我們不施加最大序列長(zhǎng)度限制,我們不想截?cái)嗷蛱畛渌鼈兊焦潭ㄩL(zhǎng)度,因此將max_seq_length設(shè)置為None允許我們使用數(shù)據(jù)中存在的全部序列長(zhǎng)度。
packing:根據(jù)文檔,ConstantLengthDataset使用這個(gè)參數(shù)來(lái)打包數(shù)據(jù)集的序列。在ConstantLengthDataset上下文中將packing設(shè)置為False可以在處理多個(gè)簡(jiǎn)短示例時(shí)提高效率,我們的數(shù)據(jù)集就是這種情況。通過(guò)將packing設(shè)置為False,允許ConstantLengthDataset將多個(gè)短示例打包到單個(gè)輸入序列中,有效地組合它們。這減少了對(duì)大量填充的需求,并提高了內(nèi)存使用和計(jì)算的效率。
加載數(shù)據(jù)集、基本模型和標(biāo)記器
device_map = {"": 0}
# Load dataset (you can process it here)
dataset = load_dataset(dataset_name, split="train")
# Load tokenizer and model with QLoRA configuration
compute_dtype = getattr(torch, bnb_4bit_compute_dtype)
bnb_config = BitsAndBytesConfig(
load_in_4bit=use_4bit,
bnb_4bit_quant_type=bnb_4bit_quant_type,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=use_nested_quant,
)
# Check GPU compatibility with bfloat16
if compute_dtype == torch.float16 and use_4bit:
major, _ = torch.cuda.get_device_capability()
if major >= 8:
print("=" * 80)
print("Your GPU supports bfloat16: accelerate training with bf16=True")
print("=" * 80)
# Load base model
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map=device_map
)
model.config.use_cache = False
model.config.pretraining_tp = 1
# Load LLaMA tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
# Load LoRA configuration
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM",
)
第5行加載數(shù)據(jù)集。然后在第9行使用gettr函數(shù)將compute_dtype設(shè)置為torch.float16。在第10行,初始化BitsandBytesConfig。
在第17行,我們使用torch.cuda.get_device_capability()函數(shù)檢查GPU與bfloat16的兼容性。該函數(shù)返回支持cuda的GPU設(shè)備的計(jì)算能力。計(jì)算能力表示GPU支持的版本和特性。該函數(shù)返回一個(gè)由兩個(gè)整數(shù)組成的元組,(major, minor),表示GPU的主要和次要計(jì)算能力版本。主要版本表示該計(jì)算能力的主要版本,次要版本表示該計(jì)算能力的次要版本。例如,如果函數(shù)返回(8,0),則表示GPU的計(jì)算能力為8.0版本,次要是0。如果GPU是bfloat16兼容的,那么我們將compute_dtype設(shè)置為torch.Bfloat16,因?yàn)锽float16比f(wàn)loat16更好的精度
然后就是使用AutoModelForCausalLM.from_pretrained加載基本模型,在第31行設(shè)置了model.config。use_cache為False,當(dāng)啟用緩存時(shí)可以減少變量。禁用緩存則在執(zhí)行計(jì)算的順序方面引入了一定程度的隨機(jī)性,這在微調(diào)時(shí)非常有用。
在第32行設(shè)置了model.config.pretraining_tp = 1這里的tp代表張量并行性,根據(jù)這里的Llama 2的提示:
設(shè)置model.config. pretraining_tp = 1不等于1的值將激活更準(zhǔn)確但更慢的線性層計(jì)算,這應(yīng)該更好地匹配原始概率。
然后就是使用model_name加載Llama標(biāo)記器。如果你看一下NousResearch/ lama-2的文件,你會(huì)注意到有一個(gè)tokenizer. model文件。使用model_name, AutoTokenizer可以下載該標(biāo)記器。
在第36行,調(diào)用add_special_tokens({' pad_token ': ' [PAD] '})這是另一個(gè)重要代碼,因?yàn)槲覀償?shù)據(jù)集中的文本長(zhǎng)度可以變化,批處理中的序列可能具有不同的長(zhǎng)度。為了確保批處理中的所有序列具有相同的長(zhǎng)度,需要將填充令牌添加到較短的序列中。這些填充標(biāo)記通常是沒(méi)有任何含義的標(biāo)記,例如。
在第37行,我們?cè)O(shè)置tokenizer. pad_token = tokenizer. eos_token。將pad令牌與EOS令牌對(duì)齊,并使我們的令牌器配置更加一致。兩個(gè)令牌(pad_token和eos_token)都有指示序列結(jié)束的作用。設(shè)置成一個(gè)簡(jiǎn)化了標(biāo)記化和填充邏輯。
在第38行,設(shè)置填充邊,將填充邊設(shè)置為右可以修復(fù)溢出問(wèn)題。
最后在第41行,我們初始化了LoraConfig
訓(xùn)練
# Set training parameters
training_arguments = TrainingArguments(
output_dir=output_dir,
num_train_epochs=num_train_epochs,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
weight_decay=weight_decay,
fp16=fp16,
bf16=bf16,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=group_by_length,
lr_scheduler_type=lr_scheduler_type,
report_to="tensorboard"
)
# Set supervised fine-tuning parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
packing=packing,
)
# Train model
trainer.train()
# Save trained model
trainer.model.save_pretrained(new_model)
在第2行使用前面詳細(xì)討論過(guò)的形參初始化TrainingArguments。然后將TrainingArguments與討論的其他相關(guān)參數(shù)一起傳遞到第30行上的SFTTrainer中。
這里新加的一個(gè)參數(shù)是第27行的dataset_text_field= " text "。dataset_text_field參數(shù)用于指示數(shù)據(jù)集中哪個(gè)字段包含作為模型輸入的文本數(shù)據(jù)。它使datasets 庫(kù)能夠基于該字段中的文本數(shù)據(jù)自動(dòng)創(chuàng)建ConstantLengthDataset,簡(jiǎn)化數(shù)據(jù)準(zhǔn)備過(guò)程。
HuggingFace生態(tài)系統(tǒng)是一個(gè)緊密結(jié)合的庫(kù)生態(tài)系統(tǒng),它在后臺(tái)為你自動(dòng)化了很多工作。
推理
logging.set_verbosity(logging.CRITICAL)
# Run text generation pipeline with our next model
prompt = "What is a large language model?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(f"< s >[INST] {prompt} [/INST]")
print(result[0]['generated_text'])
第6行,管道初始化。然后在第7行使用管道,傳遞使用第5行提示符構(gòu)造的輸入文本。我們使用來(lái)指示序列的開(kāi)始,而添加[INST]和[/INST]作為控制令牌來(lái)指示用戶消息的開(kāi)始和結(jié)束。
~## 用適配器權(quán)重重新加載基本模型
# Reload model in FP16 and merge it with LoRA weights
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map=device_map,
)
model = PeftModel.from_pretrained(base_model, new_model)
model = model.merge_and_unload()
# Reload tokenizer to save it
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
在第2行使用AutoModelForCausalLM.from_pretrained來(lái)(重新)加載基本模型。我們將在沒(méi)有任何量化配置的情況下執(zhí)行此操作,因?yàn)槲覀儾恍枰獙?duì)其進(jìn)行微調(diào),只是想將其與適配器合并。還在第13行重新加載標(biāo)記器,并進(jìn)行與之前在第13 - 14行中所做的相同的修改。
保存
最后我們將剛剛經(jīng)過(guò)微調(diào)的模型及其標(biāo)記器保存到本地或者上傳到HuggingFace。
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)
總結(jié)
peft,tramsformers等庫(kù)簡(jiǎn)化了我們對(duì)于大模型開(kāi)發(fā)的工作流程,并且不需要很多的專業(yè)知識(shí)也可以對(duì)大模型進(jìn)行微調(diào)。但是要得到一個(gè)好的模型是一個(gè)漫長(zhǎng)的過(guò)程,就像我們上面的代碼一樣,看似簡(jiǎn)單實(shí)則復(fù)雜,不僅要了解方法的原理,還要通過(guò)查看論文了解每一個(gè)參數(shù)的含義。
~
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4838瀏覽量
107750 -
適配器
+關(guān)注
關(guān)注
9文章
2129瀏覽量
71288 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8553瀏覽量
136928 -
python
+關(guān)注
關(guān)注
57文章
4876瀏覽量
90024 -
LoRa芯片
+關(guān)注
關(guān)注
0文章
16瀏覽量
7158
發(fā)布評(píng)論請(qǐng)先 登錄
基于Llama2和OpenVIN打造聊天機(jī)器人

【飛騰派4G版免費(fèi)試用】仙女姐姐的嵌入式實(shí)驗(yàn)室之五~LLaMA.cpp及3B“小模型”O(jiān)penBuddy-StableLM-3B
使用 NPU 插件對(duì)量化的 Llama 3.1 8b 模型進(jìn)行推理時(shí)出現(xiàn)“從 __Int64 轉(zhuǎn)換為無(wú)符號(hào) int 的錯(cuò)誤”,怎么解決?
怎樣對(duì)ADC進(jìn)行采集呢
iPhone都能微調(diào)大模型了嘛
使用單卡高效微調(diào)bloom-7b1,效果驚艷

Llama 2性能如何
關(guān)于Llama 2的一切資源,我們都幫你整理好了
8G顯存一鍵訓(xùn)練,解鎖Llama2隱藏能力!XTuner帶你玩轉(zhuǎn)大模型

Falcon-7B大型語(yǔ)言模型在心理健康對(duì)話數(shù)據(jù)集上使用QLoRA進(jìn)行微調(diào)
一種新穎的大型語(yǔ)言模型知識(shí)更新微調(diào)范式

LLaMA 2是什么?LLaMA 2背后的研究工作
Meta Llama 3基礎(chǔ)模型現(xiàn)已在亞馬遜云科技正式可用
如何使用 Llama 3 進(jìn)行文本生成
一種信息引導(dǎo)的量化后LLM微調(diào)新算法IR-QLoRA




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論