 源2.0-M32大模型發布量化版 運行顯存僅需23GB 性能可媲美LLaMA3
源2.0-M32大模型發布量化版 運行顯存僅需23GB 性能可媲美LLaMA3

北京2024年8月23日/美通社/ -- 近日,浪潮信息發布源2.0-M32大模型4bit和8bit量化版,性能比肩700億參數的LLaMA3開源大模型。4bit量化版推理運行顯存僅需23.27GB,處理每token所需算力約為1.9 GFLOPs,算力消耗僅為同等當量大模型LLaMA3-70B的1/80。而LLaMA3-70B運行顯存為160GB,所需算力為140GFLOPs。
源2.0-M32量化版是"源"大模型團隊為進一步提高模算效率,降低大模型部署運行的計算資源要求而推出的版本,通過采用領先的量化技術,將原模型精度量化至int4和int8級別,并保持模型性能基本不變。源2.0-M32量化版提高了模型部署加載速度和多線程推理效率,在不同硬件和軟件環境中均能高效運行,降低了模型移植和部署門檻,讓用戶使用更少的計算資源,就能獲取源2.0-M32大模型的強大能力。
源2.0-M32大模型是浪潮信息"源2.0"系列大模型的最新版本,其創新性地提出和采用了"基于注意力機制的門控網絡"技術,構建包含32個專家(Expert)的混合專家模型(MoE),模型運行時激活參數為37億,在業界主流基準評測中性能全面對標700億參數的LLaMA3開源大模型,大幅提升了模型算力效率。
模型量化(Model Quantization)是優化大模型推理的一種主流技術,它顯著減少了模型的內存占用和計算資源消耗,從而加速推理過程。然而,模型量化可能會影響模型的性能。如何在壓縮模型的同時維持其精度,是量化技術面臨的核心挑戰。
源2.0-M32大模型研發團隊深入分析當前主流的量化方案,綜合評估模型壓縮效果和精度損失表現,最終采用了GPTQ量化方法,并采用AutoGPTQ作為量化框架。為了確保模型精度最大化,一方面定制化適配了適合源2.0-M32結構的算子,提高了模型的部署加載速度和多線程推理效率,實現高并發推理;另一方面對需要量化的中間層(inter_layers)進行了嚴格評估和篩選,確定了最佳的量化層。從而成功將模型精度量化至int4和int8級別,在模型精度幾乎無損的前提下,提升模型壓縮效果、增加推理吞吐量和降低計算成本,使其更易于部署到移動設備和邊緣設備上。
評測結果顯示,源2.0-M32量化版在多個業界主流的評測任務中性能表現突出,特別是在MATH(數學競賽)、ARC-C(科學推理)任務中,比肩擁有700億參數的LLaMA3大模型。
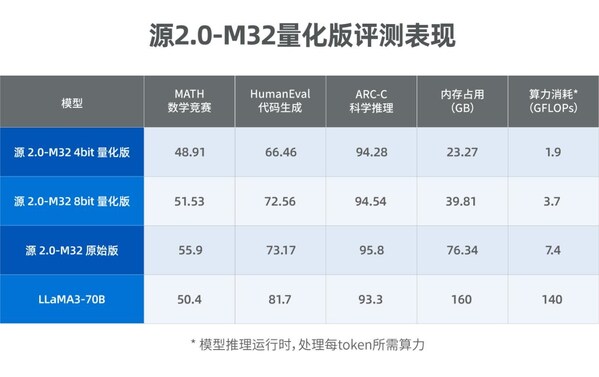
總之,源2.0-M32大模型量化版在保持推理性能的前提下,顯著降低了計算資源消耗和內存占用,其采用的GPTQ量化方法通過精細調整,成功將模型適配至int4和int8精度級別。通過定制化算子優化,源2.0-M32量化版實現了模型結構的深度適配和性能的顯著提升,確保在不同硬件和軟件環境中均能高效運行。未來,隨著量化技術的進一步優化和應用場景的拓展,源2.0-M32量化版有望在移動設備和邊緣計算等領域發揮更廣泛的作用,為用戶提供更高效的智能服務。
源2.0-M32量化版已開源,下載鏈接如下:
Hugging Face平臺下載鏈接:
https://huggingface.co/IEITYuan/Yuan2-M32-gguf-int4
https://huggingface.co/IEITYuan/Yuan2-M32-hf-int4
https://huggingface.co/IEITYuan/Yuan2-M32-hf-int8
modelscope平臺下載鏈接:
https://modelscope.cn/models/IEITYuan/Yuan2-M32-gguf-int4
https://modelscope.cn/models/IEITYuan/Yuan2-M32-HF-INT4
https://modelscope.cn/models/IEITYuan/Yuan2-M32-hf-int8
審核編輯 黃宇
-
開源
+關注
關注
3文章
4203瀏覽量
46125 -
算力
+關注
關注
2文章
1528瀏覽量
16740 -
大模型
+關注
關注
2文章
3648瀏覽量
5179
發布評論請先 登錄
登臨科技KS系列GPU產品全面適配MiniMax M2.5模型

阿里巴巴開源全新一代大模型千問Qwen3.5-Plus

如何在Arm Neoverse N2平臺上提升llama.cpp擴展性能
【CIE全國RISC-V創新應用大賽】基于 K1 AI CPU 的大模型部署落地
大規模專家并行模型在TensorRT-LLM的設計

ALINX VD100低功耗端側大模型部署方案,運行3B模型功耗僅5W?!




 工商網監
工商網監
評論