 利用Arm i8mm指令優化llama.cpp
利用Arm i8mm指令優化llama.cpp

本文將為你介紹如何利用 Arm i8mm 指令,具體來說,是通過帶符號 8 位整數矩陣乘加指令 smmla,來優化 llama.cpp 中 Q6_K 和 Q4_K 量化模型推理。
llama.cpp 量化
llama.cpp 是一個開源的 C++ 庫,用于運行大語言模型 (LLM),針對加速 CPU 推理進行了優化。通過量化等技術(例如 8 位或 4 位整數格式)來減少內存占用并加快計算速度,從而實現在消費級和服務器級硬件上高效部署模型。
llama.cpp 支持多種量化方式。量化可在模型精度和性能之間取得平衡。數據量越小,推理速度越快,但可能會因困惑度升高而致使精度降低。例如,Q8_0 采用 8 位整數表示一個數據點,而 Q6_K 則將數據量縮減至 6 位。
量化以塊為單位進行,同一個塊中的數據點共享一個縮放因子。例如,Q8_0 的處理以 32 個數據點為一個塊,具體過程如下:
從原始數據中提取 32 個浮點值,記為 f[0:32]
計算絕對值的最大值,即 mf = max(abs(f[0:32]))
計算縮放因子:scale_factor = mf / (max(int8)) = mf / 127
量化:q[i] = round(f[i] / scale_factor)
反量化:v[i] = q[i] * scale_factor
Q6_K 則更為復雜。如下圖所示,數據點分為兩個層級:
一個超級塊包含 256 個數據點,并對應一個浮點格式的超級塊縮放因子
每個超級塊由 16 個子塊組成。每個子塊包含 16 個數據點,這些數據點共享一個整數格式的子塊級縮放因子。

圖 1:Llama.cpp Q6_K 量化
利用 Arm i8mm 指令
優化 llama.cpp
與大多數人工智能 (AI) 工作負載相同,在 LLM 推理過程中,大部分 CPU 周期都耗費在矩陣乘法運算上。Arm i8mm(具體是指 smmla 指令)能夠有效加速 8 位整數矩陣乘法運算。
為了說明 smmla 指令的作用及其高效性,假設我們要對下圖中的兩個矩陣進行乘法運算。
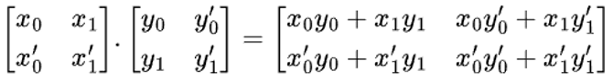
圖 2:矩陣乘法
按照教科書上的方法,我們可以逐一計算輸出矩陣中的四個標量,即第一個輸出標量是矩陣 x 的第一行與矩陣 y 的第一列的內積。依此類推,需要進行四次內積運算。
還有一種更高效的方法,即外積法。如下圖所示,我們可以用矩陣 x 的第一列乘以矩陣 y 的第一行,一次性得出四個部分輸出標量。將這兩個部分輸出相加就能得到結果,這樣只需要兩次外積運算即可。
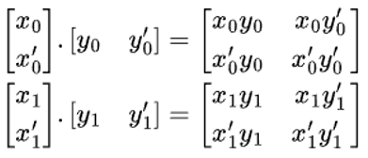
圖 3:外積
smmla 指令實現了向量級別的外積運算,如下圖所示。請注意,vmmlaq_s32 是實現 smmla 指令的編譯器內建函數。
每個輸入向量 (int8x16) 被拆分為兩個 int8x8 向量
計算四對 int8x8 向量的內積
將結果存儲到輸出向量 (int32x4) 的四個通道中
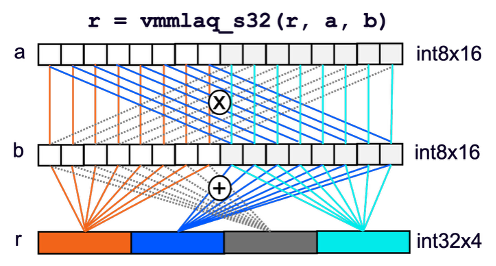
圖 4:smmla 指令
借助 smmla 指令,我們可以通過同時處理兩行和兩列來加速矩陣乘法。如下圖所示,計算步驟如下:
從矩陣 x 中加載兩行數據 (int8x16) 到 vx0 和 vx1,從矩陣 y 中加載兩列數據到 vy0 和 vy1
對 vx0 和 vx1 進行“壓縮”操作,將這兩個向量的下半部分合并為一個向量,上半部分合并為另一個向量。這是確保 smmla 指令正確工作的必要步驟。對 vy0 和 vy1 執行相同操作
使用兩條 smmla 指令計算四個臨時標量結果
處理下一個數據塊并累積臨時結果,直到處理完所有數據
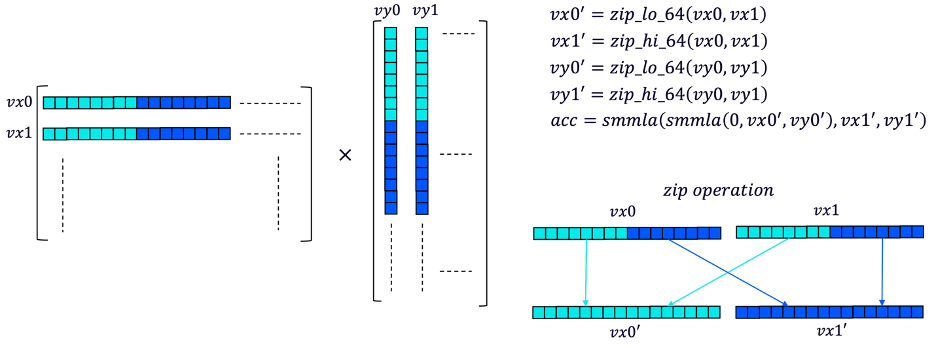
圖 5:使用 smmla 指令進行矩陣乘法
我們利用 smmla 指令對 llama.cpp 的 Q6_K 和 Q4_K 矩陣乘法內核進行了優化,并在 Arm Neoverse N2 平臺上進行了測試,觀察到性能有顯著提升。下圖展示了 Q6_K 優化前后 llama.cpp 的性能對比,其中:
S_TG 代表詞元生成速度,數值越高代表性能越好
S_PP 代表提示詞預填充速度,數值越高代表性能越好
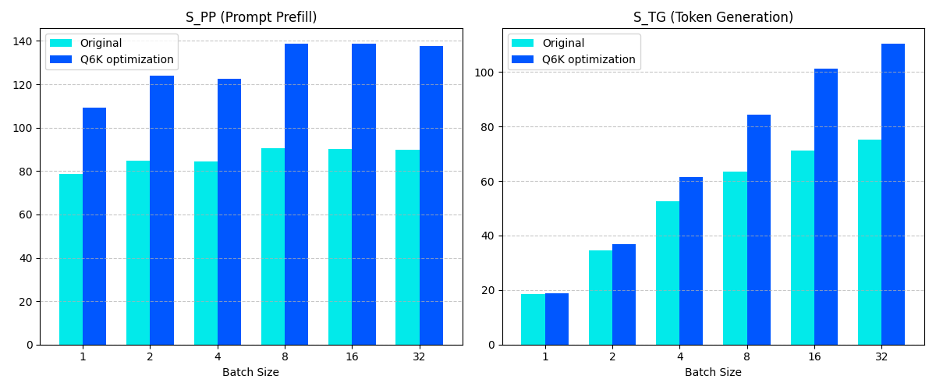
圖 6:Arm i8mm 提升 llama.cpp Q6_K 模型性能
上游補丁
[1]利用 Arm i8mm 優化 llama.cpp Q6_K 內核:
https://github.com/ggml-org/llama.cpp/pull/13519
[2]利用 Arm i8mm 優化 llama.cpp Q4_K 內核:
https://github.com/ggml-org/llama.cpp/pull/13886
-
ARM
+關注
關注
135文章
9576瀏覽量
392936 -
指令
+關注
關注
1文章
623瀏覽量
37622 -
開源
+關注
關注
3文章
4270瀏覽量
46328 -
模型
+關注
關注
1文章
3783瀏覽量
52201
原文標題:一文詳解如何利用 Arm i8mm 指令優化 llama.cpp
文章出處:【微信號:Arm社區,微信公眾號:Arm社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【飛騰派4G版免費試用】仙女姐姐的嵌入式實驗室之五~LLaMA.cpp及3B“小模型”OpenBuddy-StableLM-3B
將Deepseek移植到i.MX 8MP|93 EVK的步驟
《電子發燒友電子設計周報》聚焦硬科技領域核心價值 第21期:2025.07.21--2025.07.25
《電子發燒友電子設計周報》聚焦硬科技領域核心價值 第22期:2025.07.28--2025.08.1
【CIE全國RISC-V創新應用大賽】基于 K1 AI CPU 的大模型部署落地
ARM程序設計優化策略與技術

如何優化 Llama 3 的輸入提示
K1 AI CPU基于llama.cpp與Ollama的大模型部署實踐

Arm Neoverse N2平臺實現DeepSeek-R1滿血版部署

RISC-V CPU 上 3 倍推理加速!V-SEEK:在 SOPHON SG2042 上加速 14B LLM




 工商網監
工商網監
評論