隨著預(yù)訓(xùn)練語(yǔ)言模型(PLMs)的不斷發(fā)展,各種NLP任務(wù)設(shè)置上都取得了不俗的性能。盡管PLMs可以從大量語(yǔ)料庫(kù)中學(xué)習(xí)一定的知識(shí),但仍舊存在很多問(wèn)題,如知識(shí)量有限、受訓(xùn)練數(shù)據(jù)長(zhǎng)尾分布影響魯棒性不好等
2022-04-02 17:21:43 10696
10696 NLP領(lǐng)域的研究目前由像RoBERTa等經(jīng)過(guò)數(shù)十億個(gè)字符的語(yǔ)料經(jīng)過(guò)預(yù)訓(xùn)練的模型匯主導(dǎo)。那么對(duì)于一個(gè)預(yù)訓(xùn)練模型,對(duì)于不同量級(jí)下的預(yù)訓(xùn)練數(shù)據(jù)能夠提取到的知識(shí)和能力有何不同?
2023-03-03 11:21:512687 在之前的內(nèi)容中,我們已經(jīng)介紹過(guò)流水線并行、數(shù)據(jù)并行(DP,DDP和ZeRO)。 今天我們將要介紹最重要,也是目前基于Transformer做大模型預(yù)訓(xùn)練最基本的并行范式:來(lái)自NVIDIA的張量模型
2023-05-31 14:38:234295 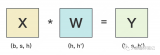
作者:算力魔方創(chuàng)始人/英特爾創(chuàng)新大使劉力 之前我們分享了《從零開(kāi)始訓(xùn)練一個(gè)大語(yǔ)言模型需要投資多少錢(qián)》,其中高昂的預(yù)訓(xùn)練費(fèi)用讓許多對(duì)大模型預(yù)訓(xùn)練技術(shù)感興趣的朋友望而卻步。 應(yīng)廣大讀者的需求,本文將
2025-02-19 16:10:102243 
訓(xùn)練好的ai模型導(dǎo)入cubemx不成功咋辦,試了好幾個(gè)模型壓縮了也不行,ram占用過(guò)大,有無(wú)解決方案?
2023-08-04 09:16:28
Edge Impulse是一個(gè)應(yīng)用于嵌入式領(lǐng)域的在線的機(jī)器學(xué)習(xí)網(wǎng)站,不僅為用戶提供了一些現(xiàn)成的神經(jīng)網(wǎng)絡(luò)模型以供訓(xùn)練,還能直接將訓(xùn)練好的模型轉(zhuǎn)換成能在單片機(jī)MCU上運(yùn)行的代碼,使用方便,容易上手。本文
2021-12-20 06:51:26
本教程以實(shí)際應(yīng)用、工程開(kāi)發(fā)為目的,著重介紹模型訓(xùn)練過(guò)程中遇到的實(shí)際問(wèn)題和方法。在機(jī)器學(xué)習(xí)模型開(kāi)發(fā)中,主要涉及三大部分,分別是數(shù)據(jù)、模型和損失函數(shù)及優(yōu)化器。本文也按順序的依次介紹數(shù)據(jù)、模型和損失函數(shù)
2018-12-21 09:18:02
大語(yǔ)言模型的核心特點(diǎn)在于其龐大的參數(shù)量,這賦予了模型強(qiáng)大的學(xué)習(xí)容量,使其無(wú)需依賴微調(diào)即可適應(yīng)各種下游任務(wù),而更傾向于培養(yǎng)通用的處理能力。然而,隨著學(xué)習(xí)容量的增加,對(duì)預(yù)訓(xùn)練數(shù)據(jù)的需求也相應(yīng)
2024-05-07 17:10:27
特定任務(wù)對(duì)模型進(jìn)行微調(diào)。這種方法的成功不僅是自然語(yǔ)言處理發(fā)展的一個(gè)轉(zhuǎn)折點(diǎn),還為許多現(xiàn)實(shí)世界的應(yīng)用場(chǎng)帶來(lái)了前所未有的性能提升。從廣為人知的GPT到BERT,預(yù)訓(xùn)練的模型參數(shù)量越來(lái)越大預(yù)訓(xùn)練數(shù)據(jù)越來(lái)越多
2024-05-05 12:17:03
其預(yù)訓(xùn)練和微調(diào),直到模型的部署和性能評(píng)估。以下是對(duì)這些技術(shù)的綜述:
模型架構(gòu):
LLMs通常采用深層的神經(jīng)網(wǎng)絡(luò)架構(gòu),最常見(jiàn)的是Transformer網(wǎng)絡(luò),它包含多個(gè)自注意力層,能夠捕捉輸入數(shù)據(jù)中
2024-05-05 10:56:58
從 Open Model Zoo 下載的 FastSeg 大型公共預(yù)訓(xùn)練模型。
運(yùn)行 converter.py 以將 FastSeg 大型模型轉(zhuǎn)換為中間表示 (IR):
python3
2025-03-05 07:22:03
醫(yī)療模型人訓(xùn)練系統(tǒng)是為滿足廣大醫(yī)學(xué)生的需要而設(shè)計(jì)的。我國(guó)現(xiàn)代醫(yī)療模擬技術(shù)的發(fā)展處于剛剛起步階段,大部分仿真系統(tǒng)產(chǎn)品都源于國(guó)外,雖然對(duì)于模擬人仿真已經(jīng)出現(xiàn)一些產(chǎn)品,但那些產(chǎn)品只是就模擬人的某一部分,某一個(gè)功能實(shí)現(xiàn)的仿真,沒(méi)有一個(gè)完整的系統(tǒng)綜合其所有功能。
2019-08-19 08:32:45
種語(yǔ)言模型進(jìn)行預(yù)訓(xùn)練,此處預(yù)訓(xùn)練為自然語(yǔ)言處理領(lǐng)域的里程碑
分詞技術(shù)(Tokenization)
Word粒度:我/賊/喜歡/看/大語(yǔ)言模型
character粒度:我/賊/喜/歡/看/大/語(yǔ)/言
2024-05-12 23:57:34
PyTorch Hub 加載預(yù)訓(xùn)練的 YOLOv5s 模型,model并傳遞圖像進(jìn)行推理。'yolov5s'是最輕最快的 YOLOv5 型號(hào)。有關(guān)所有可用模型的詳細(xì)信息,請(qǐng)參閱自述文件。詳細(xì)示例此示例
2022-07-22 16:02:42
對(duì)自己和一些同學(xué)能有所幫助。 Object Detection API提供了5種網(wǎng)絡(luò)結(jié)構(gòu)的預(yù)訓(xùn)練的權(quán)重,全部是用數(shù)據(jù)集進(jìn)行訓(xùn)練。
2017-12-27 13:43:3917193 ImageNet預(yù)訓(xùn)練方式加快了收斂速度,特別是在訓(xùn)練早期,但隨機(jī)初始化訓(xùn)練可以在訓(xùn)練一段時(shí)間后趕上來(lái)。考慮到前者還要進(jìn)行模型的微調(diào),訓(xùn)練總時(shí)間二者大體相當(dāng)。由于在研究目標(biāo)任務(wù)時(shí)經(jīng)常忽略ImageNet預(yù)訓(xùn)練的成本,因此采用短期訓(xùn)練進(jìn)行的“對(duì)照”比較可能會(huì)掩蓋隨機(jī)初始化訓(xùn)練的真實(shí)表現(xiàn)。
2018-11-24 10:09:017021 正如我們?cè)诒疚闹兴觯琔LMFiT使用新穎的NLP技術(shù)取得了令人矚目的成果。該方法對(duì)預(yù)訓(xùn)練語(yǔ)言模型進(jìn)行微調(diào),將其在WikiText-103數(shù)據(jù)集(維基百科的長(zhǎng)期依賴語(yǔ)言建模數(shù)據(jù)集Wikitext之一)上訓(xùn)練,從而得到新數(shù)據(jù)集,通過(guò)這種方式使其不會(huì)忘記之前學(xué)過(guò)的內(nèi)容。
2019-04-04 11:26:2624417 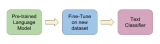
BERT是一種先進(jìn)的深度學(xué)習(xí)模型,它建立在語(yǔ)義理解的深度雙向轉(zhuǎn)換器上。當(dāng)我們?cè)黾觔atch size的大小(如超過(guò)8192)時(shí),此前的模型訓(xùn)練技巧在BERT上表現(xiàn)得并不好。BERT預(yù)訓(xùn)練也需要很長(zhǎng)時(shí)間才能完成,如在16個(gè)TPUv3上大約需要三天。
2019-04-04 16:27:1012233 專門(mén)針對(duì)序列到序列的自然語(yǔ)言生成任務(wù),微軟亞洲研究院提出了新的預(yù)訓(xùn)練方法:屏蔽序列到序列預(yù)訓(xùn)練(MASS: Masked Sequence to Sequence Pre-training
2019-05-11 09:19:043984 
專門(mén)針對(duì)序列到序列的自然語(yǔ)言生成任務(wù),微軟亞洲研究院提出了新的預(yù)訓(xùn)練方法:屏蔽序列到序列預(yù)訓(xùn)練(MASS: Masked Sequence to Sequence Pre-training)。MASS對(duì)句子隨機(jī)屏蔽一個(gè)長(zhǎng)度為k的連續(xù)片段,然后通過(guò)編碼器-注意力-解碼器模型預(yù)測(cè)生成該片段。
2019-05-11 09:34:027956 
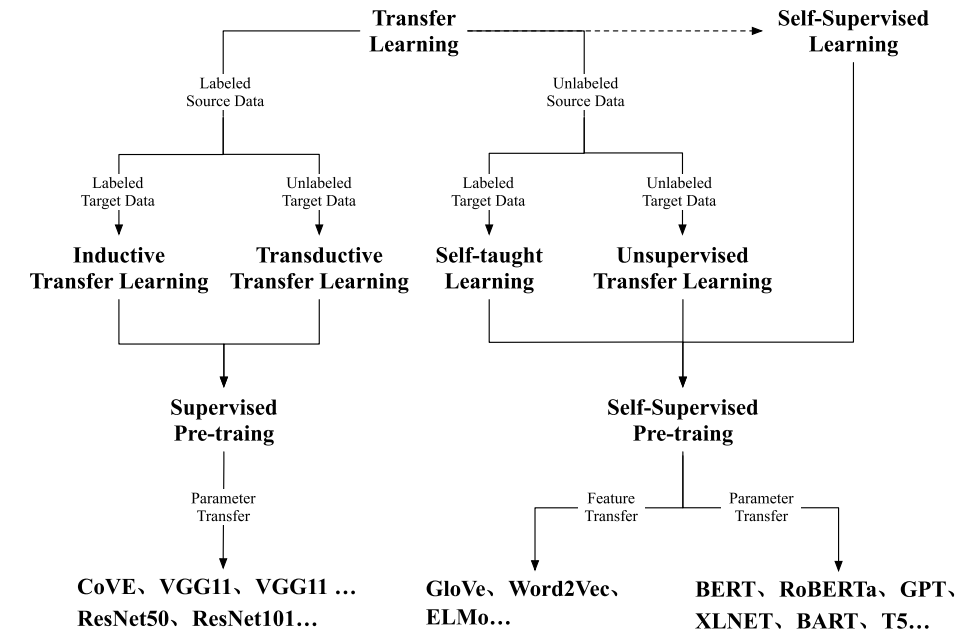
把我們當(dāng)前要處理的NLP任務(wù)叫做T(T稱為目標(biāo)任務(wù)),遷移學(xué)習(xí)技術(shù)做的事是利用另一個(gè)任務(wù)S(S稱為源任務(wù))來(lái)提升任務(wù)T的效果,也即把S的信息遷移到T中。至于怎么遷移信息就有很多方法了,可以直接利用S的數(shù)據(jù),也可以利用在S上訓(xùn)練好的模型,等等。
2019-07-18 11:29:478597 
騰訊優(yōu)圖首個(gè)醫(yī)療AI深度學(xué)習(xí)預(yù)訓(xùn)練模型MedicalNet正式對(duì)外開(kāi)源。據(jù)稱,這是全球第一個(gè)提供多種3D醫(yī)療影像專用預(yù)訓(xùn)練模型的項(xiàng)目,將為全球醫(yī)療AI發(fā)展提供基礎(chǔ)。
2019-08-09 09:17:101605 自然圖像領(lǐng)域中存在著許多海量數(shù)據(jù)集,如ImageNet,MSCOCO。基于這些數(shù)據(jù)集產(chǎn)生的預(yù)訓(xùn)練模型推動(dòng)了分類、檢測(cè)、分割等應(yīng)用的進(jìn)步。
2019-08-20 15:03:162304 如果有一種預(yù)訓(xùn)練方法可以 顯式地 獲取知識(shí),如引用額外的大型外部文本語(yǔ)料庫(kù),在不增加模型大小或復(fù)雜性的情況下獲得準(zhǔn)確結(jié)果,會(huì)怎么樣?
2020-09-27 14:50:052512 在這篇文章中,我會(huì)介紹一篇最新的預(yù)訓(xùn)練語(yǔ)言模型的論文,出自MASS的同一作者。這篇文章的亮點(diǎn)是:將兩種經(jīng)典的預(yù)訓(xùn)練語(yǔ)言模型(MaskedLanguage Model, Permuted
2020-11-02 15:09:363702 本文把對(duì)抗訓(xùn)練用到了預(yù)訓(xùn)練和微調(diào)兩個(gè)階段,對(duì)抗訓(xùn)練的方法是針對(duì)embedding space,通過(guò)最大化對(duì)抗損失、最小化模型損失的方式進(jìn)行對(duì)抗,在下游任務(wù)上取得了一致的效果提升。 有趣的是,這種對(duì)抗
2020-11-02 15:26:492697 
BERT的發(fā)布是這個(gè)領(lǐng)域發(fā)展的最新的里程碑之一,這個(gè)事件標(biāo)志著NLP 新時(shí)代的開(kāi)始。BERT模型打破了基于語(yǔ)言處理的任務(wù)的幾個(gè)記錄。在 BERT 的論文發(fā)布后不久,這個(gè)團(tuán)隊(duì)還公開(kāi)了模型的代碼,并提供了模型的下載版本
2020-11-24 10:08:224540 本期推送介紹了哈工大訊飛聯(lián)合實(shí)驗(yàn)室在自然語(yǔ)言處理重要國(guó)際會(huì)議COLING 2020上發(fā)表的工作,提出了一種字符感知預(yù)訓(xùn)練模型CharBERT,在多個(gè)自然語(yǔ)言處理任務(wù)中取得顯著性能提升,并且大幅度
2020-11-27 10:47:092482 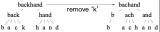
哈工大訊飛聯(lián)合實(shí)驗(yàn)室發(fā)布的中文ELECTRA系列預(yù)訓(xùn)練模型再迎新成員。我們基于大規(guī)模法律文本訓(xùn)練出中文法律領(lǐng)域ELECTRA系列模型,并且在法律領(lǐng)域自然語(yǔ)言處理任務(wù)中獲得了顯著性能提升。歡迎各位讀者
2020-12-26 09:49:264136 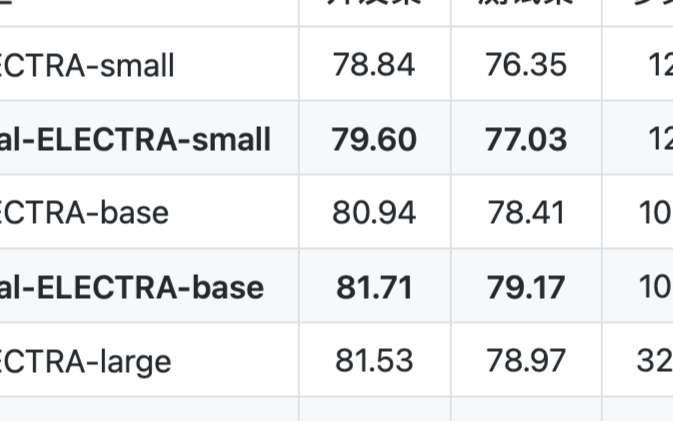
導(dǎo)讀:預(yù)訓(xùn)練模型在NLP大放異彩,并開(kāi)啟了預(yù)訓(xùn)練-微調(diào)的NLP范式時(shí)代。由于工業(yè)領(lǐng)域相關(guān)業(yè)務(wù)的復(fù)雜性,以及工業(yè)應(yīng)用對(duì)推理性能的要求,大規(guī)模預(yù)訓(xùn)練模型往往不能簡(jiǎn)單直接地被應(yīng)用于NLP業(yè)務(wù)中。本文將為
2020-12-31 10:17:113696 
據(jù)消息,北京智源人工智能研究院發(fā)布四個(gè)超大規(guī)模人工智能預(yù)訓(xùn)練模型,統(tǒng)稱為“悟道1.0”,涵蓋中文語(yǔ)言、多模態(tài)、認(rèn)知、蛋白質(zhì)預(yù)測(cè)四個(gè)領(lǐng)域,是幫助國(guó)內(nèi)企業(yè)、機(jī)構(gòu)開(kāi)發(fā)人工智能應(yīng)用的大型基礎(chǔ)設(shè)施。
2021-03-21 10:09:402777 為提高卷積神經(jīng)網(wǎng)絡(luò)目標(biāo)檢測(cè)模型精度并增強(qiáng)檢測(cè)器對(duì)小目標(biāo)的檢測(cè)能力,提出一種脫離預(yù)訓(xùn)練的多尺度目標(biāo)檢測(cè)網(wǎng)絡(luò)模型。采用脫離預(yù)訓(xùn)練檢測(cè)網(wǎng)絡(luò)使其達(dá)到甚至超過(guò)預(yù)訓(xùn)練模型的精度,針對(duì)小目標(biāo)特點(diǎn)
2021-04-02 11:35:50 26
26 在大規(guī)模無(wú)監(jiān)督語(yǔ)料上預(yù)訓(xùn)練的語(yǔ)言模型正逐漸受到自然語(yǔ)言處理領(lǐng)琙硏究者的關(guān)注。現(xiàn)有模型在預(yù)訓(xùn)練階段主要提取文本的語(yǔ)義和結(jié)構(gòu)特征,針對(duì)情感類任務(wù)的復(fù)雜情感特征,在最新的預(yù)訓(xùn)練語(yǔ)言模型BERI(雙向
2021-04-13 11:40:514 自從深度學(xué)習(xí)火起來(lái)后,預(yù)訓(xùn)練過(guò)程就是做圖像或者視頻領(lǐng)域的一種比較常規(guī)的做法,有比較長(zhǎng)的歷史了,而且這種做法很有效,能明顯促進(jìn)應(yīng)用的效果。
2021-04-15 14:48:332597 
作為模型的初始化詞向量。但是,隨機(jī)詞向量存在不具備語(yǔ)乂和語(yǔ)法信息的缺點(diǎn);預(yù)訓(xùn)練詞向量存在¨一詞-乂”的缺點(diǎn),無(wú)法為模型提供具備上下文依賴的詞向量。針對(duì)該問(wèn)題,提岀了一種基于預(yù)訓(xùn)練模型BERT和長(zhǎng)短期記憶網(wǎng)絡(luò)的深度學(xué)習(xí)
2021-04-20 14:29:0619 深度學(xué)習(xí)模型應(yīng)用于自然語(yǔ)言處理任務(wù)時(shí)依賴大型、高質(zhì)量的人工標(biāo)注數(shù)據(jù)集。為降低深度學(xué)習(xí)模型對(duì)大型數(shù)據(jù)集的依賴,提出一種基于BERT的中文科技自然語(yǔ)言處理預(yù)訓(xùn)練模型 ALICE。通過(guò)對(duì)遮罩語(yǔ)言模型進(jìn)行
2021-05-07 10:08:1614 本文關(guān)注于向大規(guī)模預(yù)訓(xùn)練語(yǔ)言模型(如RoBERTa、BERT等)中融入知識(shí)。
2021-06-23 15:07:315934 
/2107.13586.pdf 相關(guān)資源:http://pretrain.nlpedia.ai Part1什么是Prompt Learning 從BERT誕生開(kāi)始,使用下游任務(wù)數(shù)據(jù)微調(diào)預(yù)訓(xùn)練語(yǔ)言模型 (LM)已成為
2021-08-16 11:21:225231 
某一方面的智能程度。具體來(lái)說(shuō)是,領(lǐng)域?qū)<胰斯?gòu)造標(biāo)準(zhǔn)數(shù)據(jù)集,然后在其上訓(xùn)練及評(píng)價(jià)相關(guān)模型及方法。但由于相關(guān)技術(shù)的限制,要想獲得效果更好、能力更強(qiáng)的模型,往往需要在大量的有標(biāo)注的數(shù)據(jù)上進(jìn)行訓(xùn)練。 近期預(yù)訓(xùn)練模型的
2021-09-06 10:06:534733 
、新加坡國(guó)立大學(xué) 鏈接:https://arxiv.org/pdf/2109.11797.pdf 提取摘要 預(yù)訓(xùn)練的視覺(jué)語(yǔ)言模型 (VL-PTMs) 在將自然語(yǔ)言融入圖像數(shù)據(jù)中顯示出有前景的能力,促進(jìn)
2021-10-09 15:10:423888 
大模型的預(yù)訓(xùn)練計(jì)算。 大模型是大勢(shì)所趨 近年來(lái),NLP 模型的發(fā)展十分迅速,模型的大小每年以1-2個(gè)數(shù)量級(jí)的速度在提升,背后的推動(dòng)力當(dāng)然是大模型可以帶來(lái)更強(qiáng)大更精準(zhǔn)的語(yǔ)言語(yǔ)義理解和推理能力。 截止到去年,OpenAI發(fā)布的GPT-3模型達(dá)到了175B的大小,相比2018年94M的ELMo模型,三年的時(shí)間整整增大了
2021-10-11 16:46:054364 
大模型的預(yù)訓(xùn)練計(jì)算。 上篇主要介紹了大模型訓(xùn)練的發(fā)展趨勢(shì)、NVIDIA Megatron的模型并行設(shè)計(jì),本篇將承接上篇的內(nèi)容,解析Megatron 在NVIDIA DGX SuperPOD 上的實(shí)踐
2021-10-20 09:25:433517 2021 OPPO開(kāi)發(fā)者大會(huì):NLP預(yù)訓(xùn)練大模型 2021 OPPO開(kāi)發(fā)者大會(huì)上介紹了融合知識(shí)的NLP預(yù)訓(xùn)練大模型。 責(zé)任編輯:haq
2021-10-27 14:18:412089 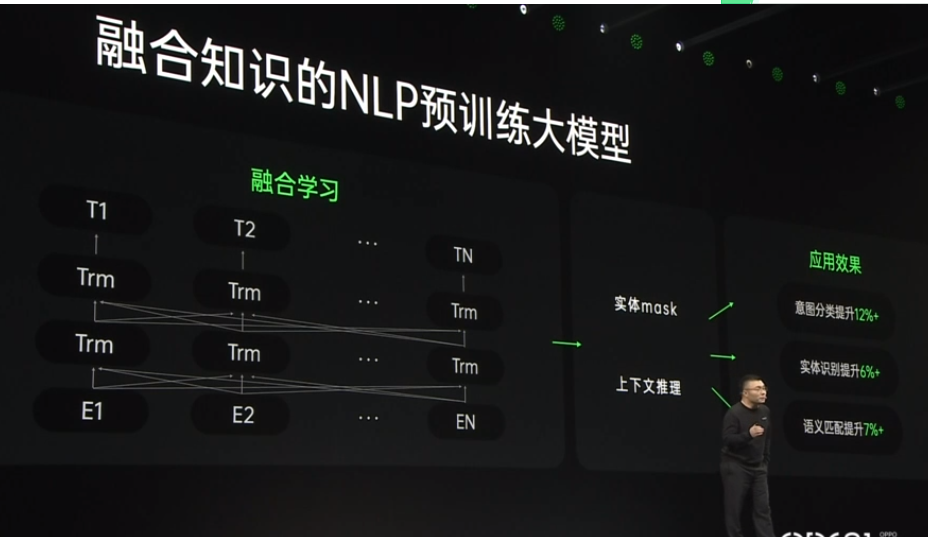
2021年OPPO開(kāi)發(fā)者大會(huì)劉海鋒:融合知識(shí)的NLP預(yù)訓(xùn)練大模型,知識(shí)融合學(xué)習(xí)運(yùn)用在小布助手里面。
2021-10-27 14:48:162751 
淺析碟式離心機(jī)的分離影響因素及模型
2021-11-12 17:10:043 NLP中,預(yù)訓(xùn)練大模型Finetune是一種非常常見(jiàn)的解決問(wèn)題的范式。利用在海量文本上預(yù)訓(xùn)練得到的Bert、GPT等模型,在下游不同任務(wù)上分別進(jìn)行finetune,得到下游任務(wù)的模型。然而,這種方式
2022-03-21 15:33:302813 。一般來(lái)講,領(lǐng)域?qū)<彝ㄟ^(guò)手工構(gòu)建標(biāo)準(zhǔn)數(shù)據(jù)集,然后在這些數(shù)據(jù)集上訓(xùn)練和評(píng)估相關(guān)模型。然而,由于相關(guān)技術(shù)的限制,訓(xùn)練模型往往需要大量的標(biāo)注數(shù)據(jù),以獲得更好、更強(qiáng)大的模型。
2022-04-02 17:26:174003 在這篇文章中,我們將展示如何快速跟蹤 AI 應(yīng)用程序的開(kāi)發(fā),方法是采用預(yù)訓(xùn)練的動(dòng)作識(shí)別模型,使用 NVIDIA TAO Toolkit 自定義數(shù)據(jù)和類對(duì)其進(jìn)行微調(diào),并通過(guò) NVIDIA DeepStream 部署它進(jìn)行推理,而無(wú)需任何 AI 專業(yè)知識(shí)。
2022-04-08 17:26:033571 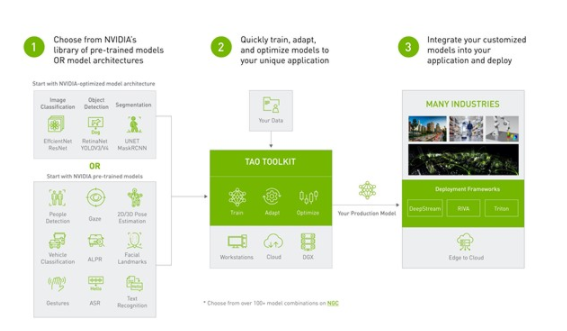
今天給大家介紹的,就是這樣一套不僅擁有上述能力,還直接提供目標(biāo)檢測(cè)、屬性分析、關(guān)鍵點(diǎn)檢測(cè)、行為識(shí)別、ReID等產(chǎn)業(yè)級(jí)預(yù)訓(xùn)練模型的實(shí)時(shí)行人分析工具PP-Human,方便開(kāi)發(fā)者靈活取用及更改!
2022-04-20 10:16:482648 Facebook在Crosslingual language model pretraining(NIPS 2019)一文中提出XLM預(yù)訓(xùn)練多語(yǔ)言模型,整體思路基于BERT,并提出了針對(duì)多語(yǔ)言預(yù)訓(xùn)練的3個(gè)優(yōu)化任務(wù)。后續(xù)很多多語(yǔ)言預(yù)訓(xùn)練工作都建立在XLM的基礎(chǔ)上,我們來(lái)詳細(xì)看看XLM的整體訓(xùn)練過(guò)程。
2022-05-05 15:23:493893 由于亂序語(yǔ)言模型不使用[MASK]標(biāo)記,減輕了預(yù)訓(xùn)練任務(wù)與微調(diào)任務(wù)之間的gap,并由于預(yù)測(cè)空間大小為輸入序列長(zhǎng)度,使得計(jì)算效率高于掩碼語(yǔ)言模型。PERT模型結(jié)構(gòu)與BERT模型一致,因此在下游預(yù)訓(xùn)練時(shí),不需要修改原始BERT模型的任何代碼與腳本。
2022-05-10 15:01:272169 為了減輕上述問(wèn)題,提出了NoisyTune方法,即,在finetune前加入給預(yù)訓(xùn)練模型的參數(shù)增加少量噪音,給原始模型增加一些擾動(dòng),從而提高預(yù)訓(xùn)練語(yǔ)言模型在下游任務(wù)的效果,如下圖所示,
2022-06-07 09:57:323472 多模態(tài)預(yù)訓(xùn)練的數(shù)據(jù)通常來(lái)源于大規(guī)模的模態(tài)間對(duì)齊樣本對(duì)。由于時(shí)序維度的存在,視頻當(dāng)中包含了比圖片更加豐富而冗余的信息。因此,收集大規(guī)模的視頻-文本對(duì)齊數(shù)據(jù)對(duì)用于視頻預(yù)訓(xùn)練存在較高的難度
2022-07-01 11:08:282843 本文對(duì)任務(wù)低維本征子空間的探索是基于 prompt tuning, 而不是fine-tuning。原因是預(yù)訓(xùn)練模型的參數(shù)實(shí)在是太多了,很難找到這么多參數(shù)的低維本征子空間。作者基于之前的工作提出了一個(gè)
2022-07-08 11:28:241837 表示輸入的特征,在傳統(tǒng)的對(duì)抗訓(xùn)練中, 通常是 token 序列或者是 token 的 embedding, 表示 ground truth. 對(duì)于由 參數(shù)化的模型,模型的預(yù)測(cè)結(jié)果可以表示為 。
2022-07-08 16:57:091898 預(yù)訓(xùn)練通常被用于自然語(yǔ)言處理以及計(jì)算機(jī)視覺(jué)領(lǐng)域,以增強(qiáng)主干網(wǎng)絡(luò)的特征提取能力,達(dá)到加速訓(xùn)練和提高模型泛化性能的目的。該方法亦可以用于場(chǎng)景文本檢測(cè)當(dāng)中,如最早的使用ImageNet預(yù)訓(xùn)練模型初始化參數(shù)
2022-08-08 15:33:352094 今天給大家?guī)?lái)一篇IJCAI2022浙大和阿里聯(lián)合出品的采用對(duì)比學(xué)習(xí)的字典描述知識(shí)增強(qiáng)的預(yù)訓(xùn)練語(yǔ)言模型-DictBERT,全名為《Dictionary Description Knowledge
2022-08-11 10:37:551661 另一方面,從語(yǔ)言處理的角度來(lái)看,認(rèn)知神經(jīng)科學(xué)研究人類大腦中語(yǔ)言處理的生物和認(rèn)知過(guò)程。研究人員專門(mén)設(shè)計(jì)了預(yù)訓(xùn)練的模型來(lái)捕捉大腦如何表示語(yǔ)言的意義。之前的工作主要是通過(guò)明確微調(diào)預(yù)訓(xùn)練的模型來(lái)預(yù)測(cè)語(yǔ)言誘導(dǎo)的大腦記錄,從而納入認(rèn)知信號(hào)。
2022-11-03 15:07:081695 隨著B(niǎo)ERT、GPT等預(yù)訓(xùn)練模型取得成功,預(yù)訓(xùn)-微調(diào)范式已經(jīng)被運(yùn)用在自然語(yǔ)言處理、計(jì)算機(jī)視覺(jué)、多模態(tài)語(yǔ)言模型等多種場(chǎng)景,越來(lái)越多的預(yù)訓(xùn)練模型取得了優(yōu)異的效果。
2022-11-08 09:57:196123 為了解決這一問(wèn)題,本文主要從預(yù)訓(xùn)練語(yǔ)言模型看MLM預(yù)測(cè)任務(wù)、引入prompt_template的MLM預(yù)測(cè)任務(wù)、引入verblize類別映射的Prompt-MLM預(yù)測(cè)、基于zero-shot
2022-11-14 14:56:343786 根據(jù)輸入數(shù)據(jù)和目標(biāo)下游任務(wù)的不同,現(xiàn)有的VLP方法可以大致分為兩類:圖像-文本預(yù)訓(xùn)練和視頻-文本預(yù)訓(xùn)練。前者從圖像-文本對(duì)中學(xué)習(xí)視覺(jué)和語(yǔ)言表征的聯(lián)合分布,后者則從視頻-文本對(duì)中建立視頻幀和文本之間的語(yǔ)義關(guān)聯(lián)。
2022-12-14 15:26:091467 NVIDIA 發(fā)布了 TAO 工具套件 4.0 。該工具套件通過(guò)全新的 AutoML 功能、與第三方 MLOPs 服務(wù)的集成以及新的預(yù)訓(xùn)練視覺(jué) AI 模型提高開(kāi)發(fā)者的生產(chǎn)力。該工具套件的企業(yè)版現(xiàn)在
2022-12-15 19:40:061778 BERT類模型的工作模式簡(jiǎn)單,但取得的效果也是極佳的,其在各項(xiàng)任務(wù)上的良好表現(xiàn)主要得益于其在大量無(wú)監(jiān)督文本上學(xué)習(xí)到的文本表征能力。那么如何從語(yǔ)言學(xué)的特征角度來(lái)衡量一個(gè)預(yù)訓(xùn)練模型的究竟學(xué)習(xí)到了什么樣的語(yǔ)言學(xué)文本知識(shí)呢?
2023-03-03 11:20:002347 每個(gè)單詞都依賴于輸入文本與之前生成的單詞。自回歸生成模型只建模了前向的單詞依賴關(guān)系,依次生成的結(jié)構(gòu)也使得自回歸模型難以并行化。目前大部分預(yù)訓(xùn)練生成模型均采用自回歸方式,包括GPT-2,BART,T5等模型。
2023-03-13 10:39:592211 預(yù)訓(xùn)練 AI 模型是為了完成特定任務(wù)而在大型數(shù)據(jù)集上訓(xùn)練的深度學(xué)習(xí)模型。這些模型既可以直接使用,也可以根據(jù)不同行業(yè)的應(yīng)用需求進(jìn)行自定義。 如果要教一個(gè)剛學(xué)會(huì)走路的孩子什么是獨(dú)角獸,那么我們首先應(yīng)
2023-04-04 01:45:022355 使用SOTA的預(yù)訓(xùn)練模型來(lái)通過(guò)遷移學(xué)習(xí)解決現(xiàn)實(shí)的計(jì)算機(jī)視覺(jué)問(wèn)題。
2023-04-23 18:08:412840 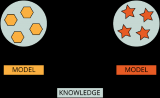
作為深度學(xué)習(xí)領(lǐng)域的 “github”,HuggingFace 已經(jīng)共享了超過(guò) 100,000 個(gè)預(yù)訓(xùn)練模型
2023-05-19 15:57:431717 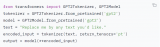
預(yù)訓(xùn)練 AI 模型是為了完成特定任務(wù)而在大型數(shù)據(jù)集上訓(xùn)練的深度學(xué)習(xí)模型。這些模型既可以直接使用,也可以根據(jù)不同行業(yè)的應(yīng)用需求進(jìn)行自定義。
2023-05-25 17:10:091816 vivo AI 團(tuán)隊(duì)與 NVIDIA 團(tuán)隊(duì)合作,通過(guò)算子優(yōu)化,提升 vivo 文本預(yù)訓(xùn)練大模型的訓(xùn)練速度。在實(shí)際應(yīng)用中, 訓(xùn)練提速 60% ,滿足了下游業(yè)務(wù)應(yīng)用對(duì)模型訓(xùn)練速度的要求。通過(guò)
2023-05-26 07:15:031303 
電子發(fā)燒友網(wǎng)站提供《PyTorch教程15.10之預(yù)訓(xùn)練BERT.pdf》資料免費(fèi)下載
2023-06-05 10:53:250 )。對(duì)于更好的泛化模型,或者更勝任的通才,可以在有或沒(méi)有適應(yīng)的情況下執(zhí)行多項(xiàng)任務(wù),大數(shù)據(jù)的預(yù)訓(xùn)練模型越來(lái)越普遍。
給定更大的預(yù)訓(xùn)練數(shù)據(jù),Transformer 架構(gòu)在模型大小和訓(xùn)練計(jì)算增加的??情況
2023-06-05 15:44:291946 
實(shí)驗(yàn)室在 SageMaker Studio Lab 中打開(kāi)筆記本
為了預(yù)訓(xùn)練第 15.8 節(jié)中實(shí)現(xiàn)的 BERT 模型,我們需要以理想的格式生成數(shù)據(jù)集,以促進(jìn)兩項(xiàng)預(yù)訓(xùn)練任務(wù):掩碼語(yǔ)言建模和下一句預(yù)測(cè)
2023-06-05 15:44:401461 前文說(shuō)過(guò),用Megatron做分布式訓(xùn)練的開(kāi)源大模型有很多,我們選用的是THUDM開(kāi)源的CodeGeeX(代碼生成式大模型,類比于openAI Codex)。選用它的原因是“完全開(kāi)源”與“清晰的模型架構(gòu)和預(yù)訓(xùn)練配置圖”,能幫助我們高效閱讀源碼。我們?cè)賮?lái)回顧下這兩張圖。
2023-06-07 15:08:247301 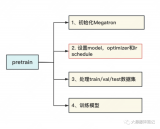
遷移學(xué)習(xí)徹底改變了自然語(yǔ)言處理(NLP)領(lǐng)域,允許從業(yè)者利用預(yù)先訓(xùn)練的模型來(lái)完成自己的任務(wù),從而大大減少了訓(xùn)練時(shí)間和計(jì)算資源。在本文中,我們將討論遷移學(xué)習(xí)的概念,探索一些流行的預(yù)訓(xùn)練模型,并通過(guò)實(shí)際示例演示如何使用這些模型進(jìn)行文本分類。我們將使用擁抱面轉(zhuǎn)換器庫(kù)來(lái)實(shí)現(xiàn)。
2023-06-14 09:30:14682 在一些非自然圖像中要比傳統(tǒng)模型表現(xiàn)更好 CoOp 增加一些 prompt 會(huì)讓模型能力進(jìn)一步提升 怎么讓能力更好?可以引入其他知識(shí),即其他的預(yù)訓(xùn)練模型,包括大語(yǔ)言模型、多模態(tài)模型 也包括
2023-06-15 16:36:111094 
Prompt Tuning 可以讓預(yù)訓(xùn)練的語(yǔ)言模型快速適應(yīng)下游任務(wù)。雖然有研究證明:當(dāng)訓(xùn)練數(shù)據(jù)足夠多的時(shí)候,Prompt Tuning 的微調(diào)結(jié)果可以媲美整個(gè)模型的訓(xùn)練調(diào)優(yōu),但當(dāng)面
2023-06-20 11:04:231369 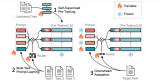
,一定要經(jīng)歷以下幾個(gè)步驟: 模型選擇(Model Selection) :選擇適合任務(wù)和數(shù)據(jù)的模型結(jié)構(gòu)和類型。 數(shù)據(jù)收集和準(zhǔn)備(Data Collection and Preparation) :收集并準(zhǔn)備用于訓(xùn)練和評(píng)估的數(shù)據(jù)集,確保其適用于所選模型。 無(wú)監(jiān)督預(yù)訓(xùn)練(Pretraining) :
2023-06-21 19:55:021138 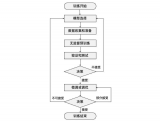
? ? 在這篇文章中,我們將盡可能詳細(xì)地梳理一個(gè)完整的 LLM 訓(xùn)練流程。包括模型預(yù)訓(xùn)練(Pretrain)、Tokenizer 訓(xùn)練、指令微調(diào)(Instruction Tuning)等環(huán)節(jié)。 文末
2023-06-29 10:08:593569 
? ? ? 近年來(lái),基于大數(shù)據(jù)預(yù)訓(xùn)練的多模態(tài)基礎(chǔ)模型 (Foundation Model) 在自然語(yǔ)言理解和視覺(jué)感知方面展現(xiàn)出了前所未有的進(jìn)展,在各領(lǐng)域中受到了廣泛關(guān)注。在醫(yī)療領(lǐng)域中,由于其任務(wù)
2023-07-07 11:10:101896 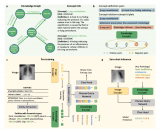
大型語(yǔ)言模型如 ChatGPT 的成功彰顯了海量數(shù)據(jù)在捕捉語(yǔ)言模式和知識(shí)方面的巨大潛力,這也推動(dòng)了基于大量數(shù)據(jù)的視覺(jué)模型研究。在計(jì)算視覺(jué)領(lǐng)域,標(biāo)注數(shù)據(jù)通常難以獲取,自監(jiān)督學(xué)習(xí)成為預(yù)訓(xùn)練的主流方法
2023-07-24 16:55:031232 
現(xiàn)有大模型在預(yù)訓(xùn)練過(guò)程中都會(huì)加入書(shū)籍、論文等數(shù)據(jù),那么在領(lǐng)域預(yù)訓(xùn)練時(shí)這兩種數(shù)據(jù)其實(shí)也是必不可少的,主要是因?yàn)檫@些數(shù)據(jù)的數(shù)據(jù)質(zhì)量較高、領(lǐng)域強(qiáng)相關(guān)、知識(shí)覆蓋率(密度)大,可以讓模型更適應(yīng)考試。
2023-08-09 11:43:292634 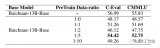
with Deep Generative Models,我認(rèn)為是個(gè)挺強(qiáng)挺有趣的自監(jiān)督方面的工作。DreamTeacher 用于從預(yù)訓(xùn)練的生成網(wǎng)絡(luò)向目標(biāo)圖像 Backbone 進(jìn)行知識(shí)蒸餾,作為一種通用的預(yù)訓(xùn)練機(jī)制
2023-08-11 09:38:491999 
當(dāng)你使用YOLOv8命令行訓(xùn)練模型的時(shí)候,如果當(dāng)前執(zhí)行的目錄下沒(méi)有相關(guān)的預(yù)訓(xùn)練模型文件,YOLOv8就會(huì)自動(dòng)下載模型權(quán)重文件。這個(gè)是一個(gè)正常操作,但是你還會(huì)發(fā)現(xiàn),當(dāng)你在參數(shù)model中指定已有
2023-09-04 10:50:134421 
大規(guī)模預(yù)訓(xùn)練:華為盤(pán)古大模型采用了大規(guī)模預(yù)訓(xùn)練的方法,通過(guò)對(duì)大量的中文語(yǔ)料進(jìn)行預(yù)訓(xùn)練,使模型具有更強(qiáng)的泛化能力和適應(yīng)能力。
2023-09-05 09:58:324746 finetune)、rlhf(optional). ?State of GPT:大神 Andrej 揭秘 OpenAI 大模型原理和訓(xùn)練過(guò)程 。 supervised finetune 一般在 base
2023-09-19 10:00:062184 
因?yàn)榇蟛糠秩耸褂玫?b class="flag-6" style="color: red">模型都是預(yù)訓(xùn)練模型,使用的權(quán)重都是在大型數(shù)據(jù)集上訓(xùn)練好的模型,當(dāng)然不需要自己去初始化權(quán)重了。只有沒(méi)有預(yù)訓(xùn)練模型的領(lǐng)域會(huì)自己初始化權(quán)重,或者在模型中去初始化神經(jīng)網(wǎng)絡(luò)最后那幾個(gè)全連接層的權(quán)重。
2024-01-29 14:25:063530 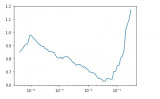
谷歌模型訓(xùn)練軟件主要是指ELECTRA,這是一種新的預(yù)訓(xùn)練方法,源自谷歌AI。ELECTRA不僅擁有BERT的優(yōu)勢(shì),而且在效率上更勝一籌。
2024-02-29 17:37:391308 近日,摩爾線程與滴普科技宣布了一項(xiàng)重要合作成果。摩爾線程的夸娥(KUAE)千卡智算集群與滴普科技的企業(yè)大模型Deepexi已完成訓(xùn)練及推理適配,共同實(shí)現(xiàn)了700億參數(shù)LLaMA2大語(yǔ)言模型的預(yù)訓(xùn)練測(cè)試。
2024-05-30 10:14:061101 預(yù)訓(xùn)練模型(Pre-trained Model)是深度學(xué)習(xí)和機(jī)器學(xué)習(xí)領(lǐng)域中的一個(gè)重要概念,尤其是在自然語(yǔ)言處理(NLP)和計(jì)算機(jī)視覺(jué)(CV)等領(lǐng)域中得到了廣泛應(yīng)用。預(yù)訓(xùn)練模型指的是在大型數(shù)據(jù)集上預(yù)先
2024-07-03 18:20:155530 人臉識(shí)別模型訓(xùn)練流程是計(jì)算機(jī)視覺(jué)領(lǐng)域中的一項(xiàng)重要技術(shù)。本文將詳細(xì)介紹人臉識(shí)別模型的訓(xùn)練流程,包括數(shù)據(jù)準(zhǔn)備、模型選擇、模型訓(xùn)練、模型評(píng)估和應(yīng)用部署等環(huán)節(jié)。 數(shù)據(jù)準(zhǔn)備 數(shù)據(jù)是訓(xùn)練人臉識(shí)別模型的基礎(chǔ)。在數(shù)
2024-07-04 09:19:052621 在人工智能和自然語(yǔ)言處理(NLP)領(lǐng)域,大型語(yǔ)言模型(Large Language Model,簡(jiǎn)稱LLM)的興起極大地推動(dòng)了技術(shù)的進(jìn)步和應(yīng)用的發(fā)展。LLM通過(guò)在大規(guī)模文本數(shù)據(jù)上進(jìn)行預(yù)訓(xùn)練,獲得了
2024-07-10 11:03:484563 能力,逐漸成為NLP領(lǐng)域的研究熱點(diǎn)。大語(yǔ)言模型的預(yù)訓(xùn)練是這一技術(shù)發(fā)展的關(guān)鍵步驟,它通過(guò)在海量無(wú)標(biāo)簽數(shù)據(jù)上進(jìn)行訓(xùn)練,使模型學(xué)習(xí)到語(yǔ)言的通用知識(shí),為后續(xù)的任務(wù)微調(diào)奠定基礎(chǔ)。本文將深入探討大語(yǔ)言模型預(yù)訓(xùn)練的基本原理、步驟以及面臨的挑戰(zhàn)。
2024-07-11 10:11:521581 預(yù)訓(xùn)練和遷移學(xué)習(xí)是深度學(xué)習(xí)和機(jī)器學(xué)習(xí)領(lǐng)域中的兩個(gè)重要概念,它們?cè)谔岣?b class="flag-6" style="color: red">模型性能、減少訓(xùn)練時(shí)間和降低對(duì)數(shù)據(jù)量的需求方面發(fā)揮著關(guān)鍵作用。本文將從定義、原理、應(yīng)用、區(qū)別和聯(lián)系等方面詳細(xì)探討預(yù)訓(xùn)練和遷移學(xué)習(xí)。
2024-07-11 10:12:422703 蘋(píng)果公司在最新的技術(shù)論文中披露了一項(xiàng)重要信息,其全新的人工智能系統(tǒng)Apple Intelligence所依賴的模型并非傳統(tǒng)上大型科技公司首選的NVIDIA GPU,而是選擇了在谷歌設(shè)計(jì)的云端芯片上進(jìn)行預(yù)訓(xùn)練。這一決定不僅打破了行業(yè)常規(guī),還預(yù)示著大型科技公司在AI基礎(chǔ)設(shè)施選擇上正朝著多樣化的方向邁進(jìn)。
2024-07-30 15:00:121201 鷺島論壇數(shù)據(jù)智能系列講座第4期「預(yù)訓(xùn)練的基礎(chǔ)模型下的持續(xù)學(xué)習(xí)」10月30日(周三)20:00精彩開(kāi)播期待與您云相聚,共襄學(xué)術(shù)盛宴!|直播信息報(bào)告題目預(yù)訓(xùn)練的基礎(chǔ)模型下的持續(xù)學(xué)習(xí)報(bào)告簡(jiǎn)介雖然近年來(lái)
2024-10-18 08:09:47953 
,基礎(chǔ)模型。 ? 大模型是一個(gè)簡(jiǎn)稱,完整的叫法,應(yīng)該是“人工智能預(yù)訓(xùn)練大模型”。預(yù)訓(xùn)練,是一項(xiàng)技術(shù),我們后面再解釋。 ? 我們現(xiàn)在口頭上常說(shuō)的大模型,實(shí)際上特指大模型的其中一類,也是用得最多的一類——語(yǔ)言大模型(Large Language Model,也叫大語(yǔ)言模型,簡(jiǎn)稱LLM)。 ? 除了
2024-11-25 09:29:4415751 
深度學(xué)習(xí)領(lǐng)域正在迅速發(fā)展,在處理各種類型的任務(wù)中,預(yù)訓(xùn)練模型變得越來(lái)越重要。Keras 以其用戶友好型 API 和對(duì)易用性的重視而聞名,始終處于這一動(dòng)向的前沿。Keras 擁有專用的內(nèi)容庫(kù),如用
2024-12-20 10:32:00868 作者:算力魔方創(chuàng)始人/英特爾創(chuàng)新大使劉力 《用PaddleNLP在4060單卡上實(shí)踐大模型預(yù)訓(xùn)練技術(shù)》發(fā)布后收到讀者熱烈反響,很多讀者要求進(jìn)一步講解更多的技術(shù)細(xì)節(jié)。本文主要針對(duì)大語(yǔ)言模型的預(yù)訓(xùn)練流程
2025-03-21 18:24:374015 
 電子發(fā)燒友App
電子發(fā)燒友App











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論