") 預(yù)訓(xùn)練語(yǔ)言模型的字典描述
預(yù)訓(xùn)練語(yǔ)言模型的字典描述

今天給大家?guī)?lái)一篇IJCAI2022浙大和阿里聯(lián)合出品的采用對(duì)比學(xué)習(xí)的字典描述知識(shí)增強(qiáng)的預(yù)訓(xùn)練語(yǔ)言模型-DictBERT,全名為《Dictionary Description Knowledge Enhanced Language Model Pre-training via Contrastive Learning》
又鴿了許久,其實(shí)最近看到一些有趣的論文,大多以知乎想法的形式發(fā)了,感興趣可以去看看,其實(shí)碼字還是很不易的~
介紹
預(yù)訓(xùn)練語(yǔ)言模型(PLMs)目前在各種自然語(yǔ)言處理任務(wù)中均取得了優(yōu)異的效果,并且部分研究學(xué)者將外部知識(shí)(知識(shí)圖譜)融入預(yù)訓(xùn)練語(yǔ)言模型中后獲取了更加優(yōu)異的效果,但具體場(chǎng)景下的知識(shí)圖譜信息往往是不容易獲取的,因此,我們提出一種新方法DictBert,將字典描述信息作為外部知識(shí)增強(qiáng)預(yù)訓(xùn)練語(yǔ)言模型,相較于知識(shí)圖譜的信息增強(qiáng),字典描述更容易獲取。
在預(yù)訓(xùn)練階段,提出來(lái)兩種新的預(yù)訓(xùn)練任務(wù)來(lái)訓(xùn)練DictBert模型,通過(guò)掩碼語(yǔ)言模型任務(wù)和對(duì)比學(xué)習(xí)任務(wù)將字典知識(shí)注入到DictBert模型中,其中,掩碼語(yǔ)言模型任務(wù)為字典中詞條預(yù)測(cè)任務(wù)(Dictionary Entry Prediction);對(duì)比學(xué)習(xí)任務(wù)為字典中詞條描述判斷任務(wù)(Entry Description Discrimination)。
在微調(diào)階段,我們將DictBert模型作為可插拔的外部知識(shí)庫(kù),對(duì)輸入序列中所包含字典中的詞條信息作為外部隱含知識(shí)內(nèi)容,注入到輸入中,并通過(guò)注意機(jī)制來(lái)增強(qiáng)輸入的表示,最終提升模型表征效果。
模型
字典描述知識(shí)
字典是一種常見(jiàn)的資源,它列出了某一種語(yǔ)言所包含的字/詞,并通過(guò)解釋性描述對(duì)其進(jìn)行含義的闡述,常常也會(huì)指定它們的發(fā)音、來(lái)源、用法、同義詞、反義詞等,如下表所示,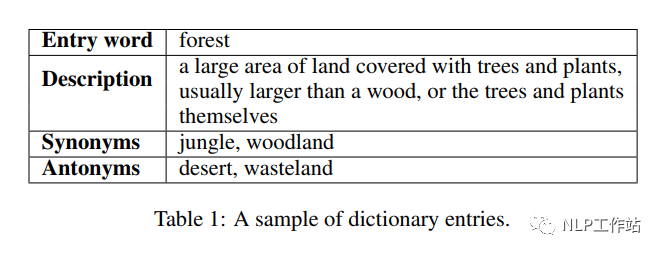 我們主要利用四種信息進(jìn)行模型的預(yù)訓(xùn)練,包括:詞條、描述、同義詞和反義詞。在詞條預(yù)測(cè)任務(wù)中,利用字典的詞條及其描述進(jìn)行知識(shí)學(xué)習(xí);在詞條描述判斷任務(wù)中,利用同義詞和反義詞來(lái)進(jìn)行對(duì)比學(xué)習(xí),從而學(xué)習(xí)到知識(shí)表征。
我們主要利用四種信息進(jìn)行模型的預(yù)訓(xùn)練,包括:詞條、描述、同義詞和反義詞。在詞條預(yù)測(cè)任務(wù)中,利用字典的詞條及其描述進(jìn)行知識(shí)學(xué)習(xí);在詞條描述判斷任務(wù)中,利用同義詞和反義詞來(lái)進(jìn)行對(duì)比學(xué)習(xí),從而學(xué)習(xí)到知識(shí)表征。
預(yù)訓(xùn)練任務(wù)
預(yù)訓(xùn)練任務(wù)主要包含字典中詞條預(yù)測(cè)任務(wù)和字典中詞條描述判斷任務(wù),如下圖所示。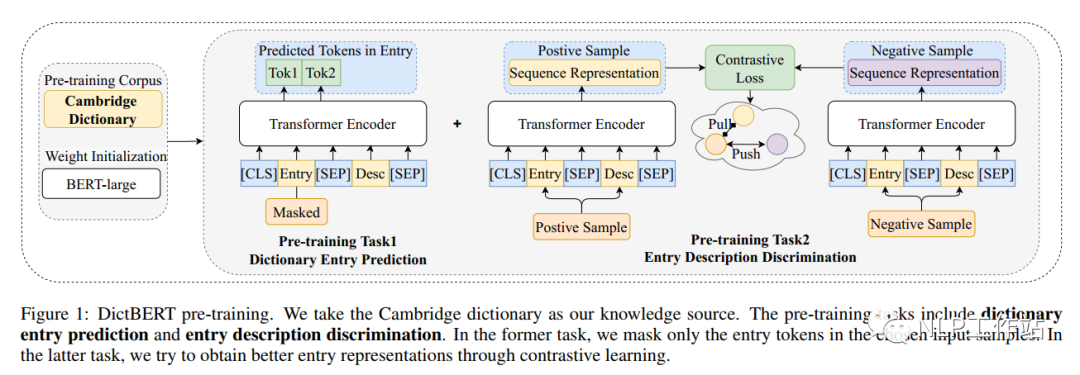 詞條預(yù)測(cè)任務(wù),實(shí)際上是一個(gè)掩碼語(yǔ)言模型任務(wù),給定詞條和它對(duì)于的描述,然后將詞條的內(nèi)容使用特殊字符[MASK]進(jìn)行替換,最終將其[MASK]內(nèi)容進(jìn)行還原。注意,當(dāng)詞條包含多個(gè)token時(shí),需要將其全部掩掉。
詞條預(yù)測(cè)任務(wù),實(shí)際上是一個(gè)掩碼語(yǔ)言模型任務(wù),給定詞條和它對(duì)于的描述,然后將詞條的內(nèi)容使用特殊字符[MASK]進(jìn)行替換,最終將其[MASK]內(nèi)容進(jìn)行還原。注意,當(dāng)詞條包含多個(gè)token時(shí),需要將其全部掩掉。
詞條描述判斷任務(wù),實(shí)際上是一個(gè)對(duì)比學(xué)習(xí)任務(wù),而對(duì)比學(xué)習(xí)就是以拉近相似數(shù)據(jù),推開(kāi)不相似數(shù)據(jù)為目標(biāo),有效地學(xué)習(xí)數(shù)據(jù)表征。如下表所示, 對(duì)于詞條“forest”,正例樣本為同義詞“woodland”,負(fù)例樣本為反義詞“desert”。對(duì)比學(xué)習(xí)中,分別對(duì)原始詞條+描述、正例樣本+描述和負(fù)例樣本+描述進(jìn)行模型編碼,獲取、和,獲取對(duì)比學(xué)習(xí)損失,
對(duì)于詞條“forest”,正例樣本為同義詞“woodland”,負(fù)例樣本為反義詞“desert”。對(duì)比學(xué)習(xí)中,分別對(duì)原始詞條+描述、正例樣本+描述和負(fù)例樣本+描述進(jìn)行模型編碼,獲取、和,獲取對(duì)比學(xué)習(xí)損失,
最終,模型預(yù)訓(xùn)練的損失為
其中,為0.4,為0.6。
微調(diào)任務(wù)
在微調(diào)過(guò)程中,將DictBert模型作為可插拔的外部知識(shí)庫(kù),如下圖所示,首先識(shí)別出輸入序列中所包含字典中的詞條信息,然后通過(guò)DictBert模型獲取外部信息表征,再通過(guò)三種不同的方式進(jìn)行外部知識(shí)的注入,最終將其綜合表征進(jìn)行下游具體的任務(wù)。并且由于可以事先離線對(duì)一個(gè)字典中所有詞條進(jìn)行外部信息表征獲取,因此,在真實(shí)落地場(chǎng)景時(shí)并不會(huì)增加太多的額外耗時(shí)。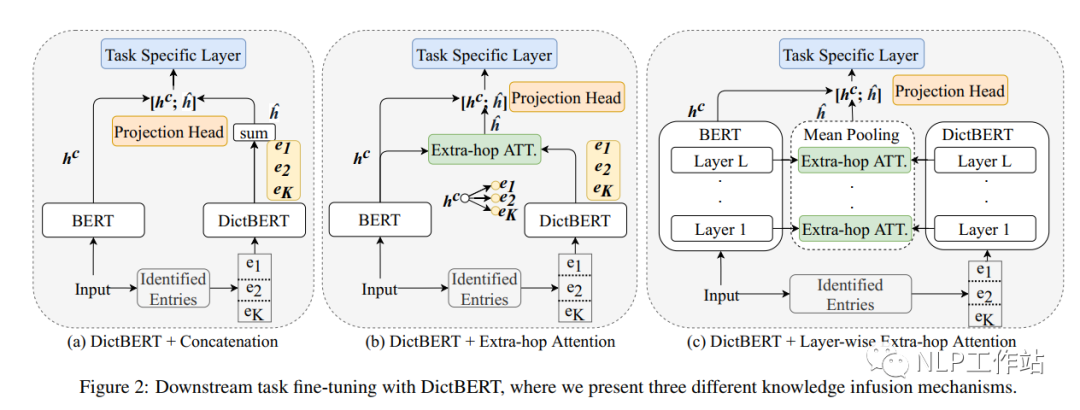 知識(shí)注入的方式包含三種:
知識(shí)注入的方式包含三種:
Pooled Output Concatenation,即將所有詞條的信息表征進(jìn)行求和,然后與原始模型的進(jìn)行拼接,最終進(jìn)行下游任務(wù);
Extra-hop Attention,即將所有詞條的信息表征對(duì)進(jìn)行attition操作,獲取分布注意力后加權(quán)求和的外部信息表征,然后與原始模型的進(jìn)行拼接,最終進(jìn)行下游任務(wù);
Layer-wise Extra-hop Attention,即將所有詞條的信息表征對(duì)每一層的進(jìn)行attition操作,獲取每一層分布注意力后加權(quán)求和的外部信息表征,然后對(duì)其所有層進(jìn)行mean-pooling操作,然后與原始模型的進(jìn)行拼接,最終進(jìn)行下游任務(wù);
結(jié)果
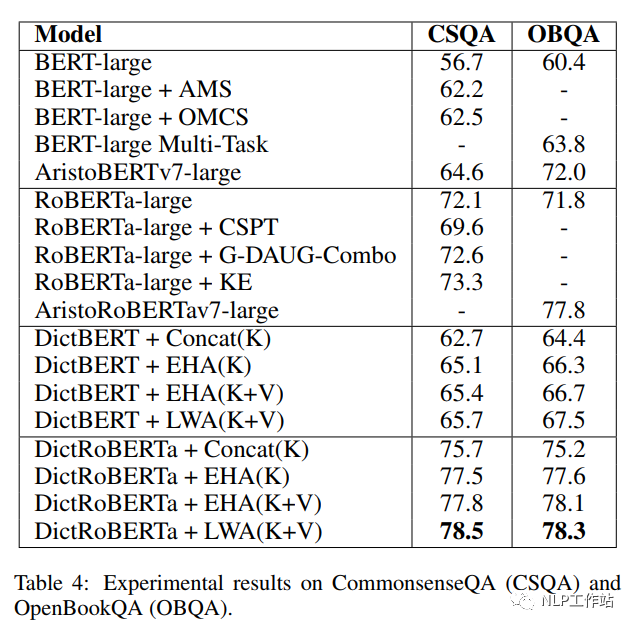
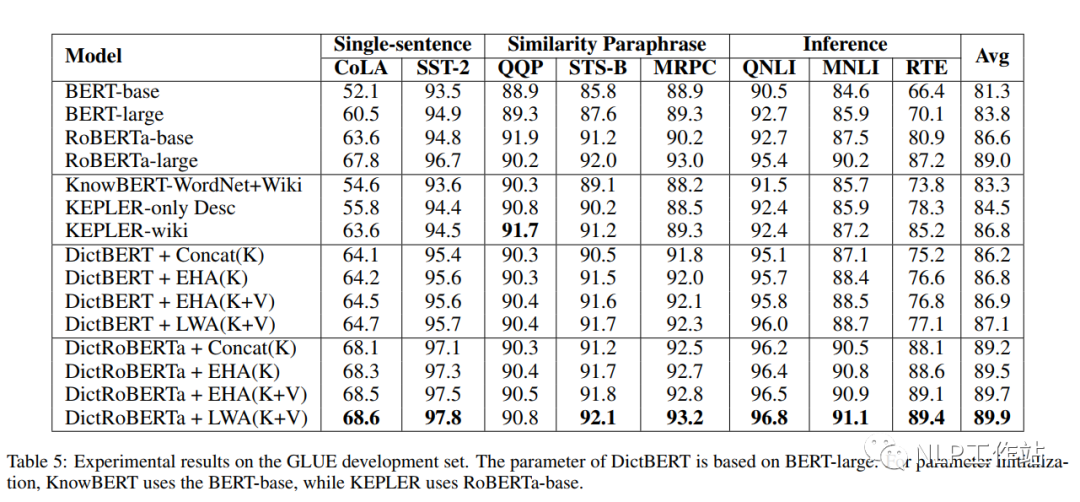
如下表所示,采用劍橋字典進(jìn)行預(yù)訓(xùn)練后的DictBert模型,在CoNLL2003、TACRED、CommonsenseQA、OpenBookQA和GLUE上均有提高。其中,Concat表示Pooled Output Concatenation方式,EHA表示Extra-hop Attention,LWA表示Layer-wise Extra-hop Attention,K表示僅采用詞條進(jìn)行信息表征,K+V表示采用詞條和描述進(jìn)行信息表征。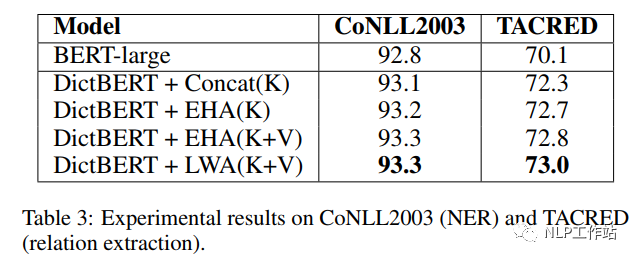
總結(jié)
挺有意思的一篇論文吧,相較于知識(shí)圖譜來(lái)說(shuō),字典確實(shí)較容易獲取,并在不同領(lǐng)域中,也比較好通過(guò)爬蟲(chóng)的形式進(jìn)行詞條和描述的獲取;并且由于字典的表征可以進(jìn)行離線生成,所以對(duì)線上模型的耗時(shí)并不明顯,主要在attention上。
-
編碼
+關(guān)注
關(guān)注
6文章
1040瀏覽量
57090 -
字典
+關(guān)注
關(guān)注
0文章
13瀏覽量
7886 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
572瀏覽量
11336
原文標(biāo)題:IJCAI2022 | DictBert:采用對(duì)比學(xué)習(xí)的字典描述知識(shí)增強(qiáng)的預(yù)訓(xùn)練語(yǔ)言模型
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
一文詳解知識(shí)增強(qiáng)的語(yǔ)言預(yù)訓(xùn)練模型
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的基礎(chǔ)技術(shù)
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的預(yù)訓(xùn)練
預(yù)訓(xùn)練語(yǔ)言模型設(shè)計(jì)的理論化認(rèn)識(shí)
如何向大規(guī)模預(yù)訓(xùn)練語(yǔ)言模型中融入知識(shí)?




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論