 哈工大訊飛聯合實驗室發布的中文ELECTRA系列預訓練模型再迎新成員
哈工大訊飛聯合實驗室發布的中文ELECTRA系列預訓練模型再迎新成員

哈工大訊飛聯合實驗室發布的中文ELECTRA系列預訓練模型再迎新成員。我們基于大規模法律文本訓練出中文法律領域ELECTRA系列模型,并且在法律領域自然語言處理任務中獲得了顯著性能提升。歡迎各位讀者下載試用相關模型。
項目地址:http://electra.hfl-rc.com
中文法律領域ELECTRA
我們在20G版(原版)中文ELECTRA的基礎上加入了高質量2000萬裁判文書數據進行了二次預訓練,在不丟失大規模通用數據上學習到的語義信息,同時使模型對法律文本更加適配。本次發布以下三個模型:
legal-ELECTRA-large, Chinese:24-layer,1024-hidden, 16-heads, 324M parameters
legal-ELECTRA-base, Chinese:12-layer,768-hidden, 12-heads, 102M parameters
legal-ELECTRA-small, Chinese: 12-layer, 256-hidden, 4-heads, 12M parameters
快速加載
哈工大訊飛聯合實驗室發布的所有中文預訓練語言模型均可通過huggingface transformers庫進行快速加載訪問,請登錄我們的共享頁面獲取更多信息。
https://huggingface.co/HFL
模型鍵值如下:
hfl/chinese-legal-electra-large-discriminator
hfl/chinese-legal-electra-large-generator
hfl/chinese-legal-electra-base-discriminator
hfl/chinese-legal-electra-base-generator
hfl/chinese-legal-electra-small-discriminator
hfl/chinese-legal-electra-small-generator
效果評測
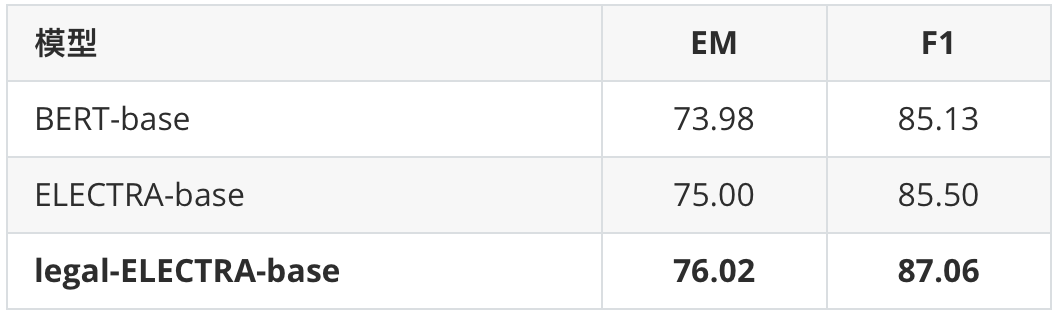
我們在罪名預測以及要素抽取任務上進行了基線測試。其中罪名預測任務使用的是CAIL 2018數據,要素抽取任務為in-house實際應用。可以看到本次發布的法律領域ELECTRA模型均相比通用ELECTRA模型獲得了顯著性能提升。
表1罪名預測任務
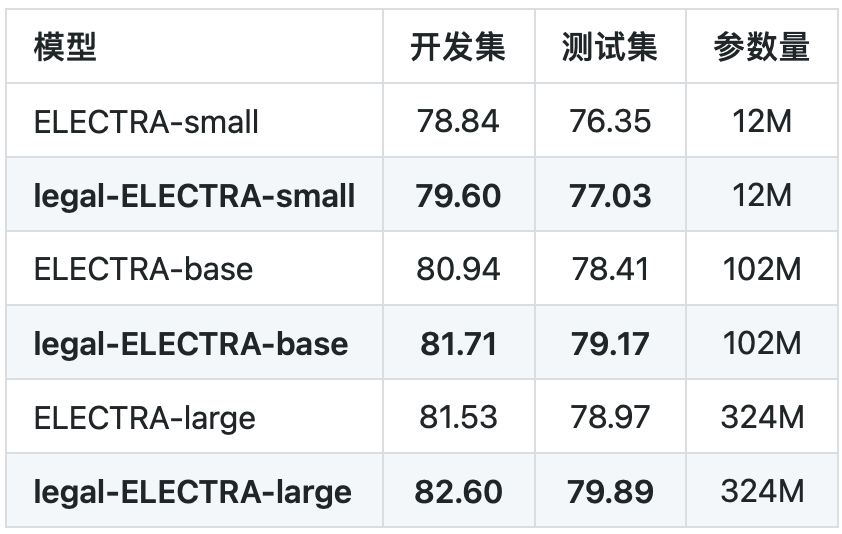
表2要素抽取任務
其他相關資源
TextBrewer知識蒸餾工具
http://textbrewer.hfl-rc.com
中文BERT、RoBERTa、RBT系列模型
http://bert.hfl-rc.com
中文XLNet系列模型
http://xlnet.hfl-rc.com
中文MacBERT模型
http://macbert.hfl-rc.com
責任編輯:xj
原文標題:哈工大訊飛聯合實驗室發布法律領域ELECTRA預訓練模型
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
算法
+關注
關注
23文章
4784瀏覽量
98066 -
深度學習
+關注
關注
73文章
5599瀏覽量
124398 -
訓練模型
+關注
關注
1文章
37瀏覽量
4071
原文標題:哈工大訊飛聯合實驗室發布法律領域ELECTRA預訓練模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
3年10億,攜手攻堅:“AI計算開放架構聯合實驗室”協同創新計劃正式啟動

北京化工大學與昱櫟技術聯合實驗室正式揭牌

科大訊飛發布訊飛星火X1.5及系列AI產品
強強聯合:之江實驗室與沐曦股份共建智算集群聯合實驗室
光峰科技與深圳技術大學簽署聯合實驗室合作協議
兆易創新與納微半導體數字能源聯合實驗室揭牌,加速高效電源管理方案落地
傳音控股與DXOMARK聯合影像實驗室落成
高鴻信安出席飛騰基礎軟件聯合實驗室第四屆年會
飛騰基礎軟件聯合實驗室第四屆年會暨技術交流分享會順利召開
愛普生與南山電子晶體電路評估聯合測試實驗室成立
奧迪威攜手華南理工大學共建聯合創新實驗室,校企深度合作助力產業升級

實驗室安全管理成焦點,漢威科技賦能實驗室安全升級
中汽信科牽頭成立汽車北斗應用聯合實驗室
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

"大模型+智能體"雙驅動!中控技術×大華股份成立視覺AI聯合實驗室




 工商網監
工商網監
評論