") 字符感知預(yù)訓(xùn)練模型CharBERT
字符感知預(yù)訓(xùn)練模型CharBERT

本期推送介紹了哈工大訊飛聯(lián)合實驗室在自然語言處理重要國際會議COLING 2020上發(fā)表的工作,提出了一種字符感知預(yù)訓(xùn)練模型CharBERT,在多個自然語言處理任務(wù)中取得顯著性能提升,并且大幅度提高了模型的魯棒性。本文以高分被COLING 2020錄用,且獲得審稿人的最佳論文獎推薦(Recommendation for Best Paper Award)。
簡介
目前預(yù)訓(xùn)練語言模型在NLP領(lǐng)域的大部分任務(wù)上都得到了顯著的效果提升,其中絕大部分模型都是基于subword的子詞粒度構(gòu)建表示,這樣幾乎可以避免OOV(out-of-vocab)的產(chǎn)生。但這種基于子詞粒度的表示也存在兩個問題:1)不完整,只能構(gòu)建子詞粒度的表示,而喪失了全詞及字符的信息;2)不魯棒,字符上一個小的變化就會導(dǎo)致整個切詞組合的變化。我們可以通過下面一個示例來說明這兩個問題。

圖1 單詞backhand內(nèi)部結(jié)構(gòu)示例
一個單詞的內(nèi)部結(jié)構(gòu)可以表示成三層的樹:根節(jié)點-全詞;孩子節(jié)點-子詞;葉子節(jié)點-字符。以BPE(Byte-Pair Encoding)[1]為代表的子詞粒度表示方法只可以表示孩子節(jié)點的信息,而喪失了根和葉子節(jié)點的信息。如果字符序列出現(xiàn)了噪音或者拼寫錯誤(如去掉了字符k),那么整個子詞組合就會完全變化,輸入到模型中的表示也就完全不一樣了,因此魯棒性較差。以CoNLL-2003 NER的開發(fā)集為例,我們基于BERT[2]的tokenizer切詞后統(tǒng)計發(fā)現(xiàn)28%的名詞會被切分成多個子詞。如果隨機刪除所有名詞中的任意一個字符,78%的詞會切分成如圖1這樣完全不一樣的組合。由此可以看出,不完整與不魯棒問題是具有統(tǒng)計顯著性的問題。
繼續(xù)看圖1中的示例。如果我們仔細觀察字符信息對應(yīng)的葉子節(jié)點,可以發(fā)現(xiàn)在去掉字符k后,葉子節(jié)點只有一個節(jié)點發(fā)生了變化,信息的變化量從孩子節(jié)點的100%降低為12.5%。另外,我們也可以通過字符信息構(gòu)建出全詞級別的表示,從而將詞的各級信息完整地表示出來。因此,我們將在目前預(yù)訓(xùn)練模型的架構(gòu)上,融合字符信息來解決上述兩個問題。
基于預(yù)訓(xùn)練模型的字符融合具有兩個挑戰(zhàn):1)如何建模字符序列;2)如何融合字符與原有基于subword的計算。我們在方法上主要解決了這兩個問題,其主要貢獻如下:
我們提出了一種字符感知預(yù)訓(xùn)練模型CharBERT,可以在已有預(yù)訓(xùn)練模型的基礎(chǔ)上融合字符層級的信息;
我們在問答、文本分類和序列標注三類任務(wù)的8個數(shù)據(jù)集上進行了驗證,發(fā)現(xiàn)CharBERT可以在BERT和RoBERTa[3]兩個基線上有明顯的效果提升;
我們通過字符攻擊的方式構(gòu)造了這三類任務(wù)對應(yīng)的噪音測試集合,發(fā)現(xiàn)CharBERT可以大幅度提升模型的魯棒性。
模型與方法
主要架構(gòu)
因為要同時融合預(yù)訓(xùn)練模型原有的subword粒度計算和基于字符的計算,我們整體上采用的雙通道的架構(gòu),具體如下圖2所示。其中我們設(shè)計了兩大模塊:字符編碼器Character Encoder和交互融合模塊Heterogeneous Interaction來解決上述字符融合的兩個問題。其中Character Encoder基于Bi-GRU構(gòu)造了上下文的字符表示,Heterogeneous Interaction通過融合和分拆兩步計算進行兩個信息流的交互式融合。
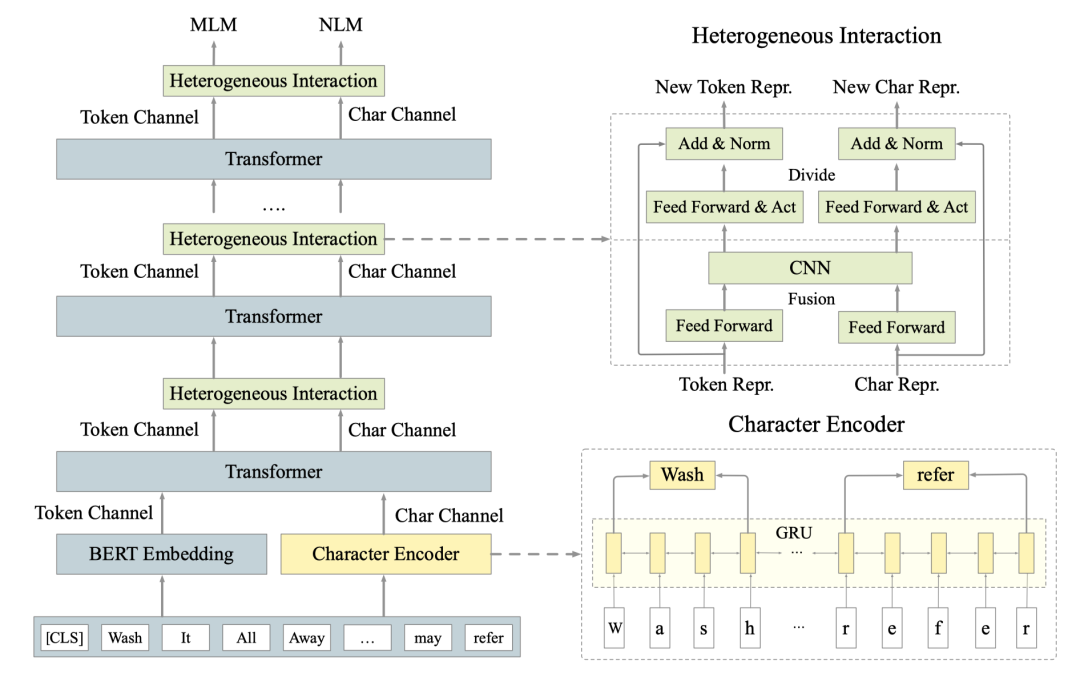
圖2 CharBERT模型圖
Character Encoder的輸入是字符序列,輸出與BERT Embedding具有相同shape的字符表示。Heterogeneous Interaction在每個transformer之后進行兩個信息流的融合計算,因此其輸入和輸出具有相同的shape。
Character Encoder
字符編碼器的結(jié)構(gòu)如圖3所示,主要基于Bi-GRU構(gòu)建上下文的字符表示。
圖3 Character Encoder示意圖
我們將整個輸入序列看成字符序列,詞之間使用一個空字符隔開。將每個字符映射成一個固定大小的embedding后,使用Bi-GRU構(gòu)建每一個字符的表示,然后將每個詞的首尾字符的表示拼接作為每個詞對應(yīng)的表示,對應(yīng)公式如下:
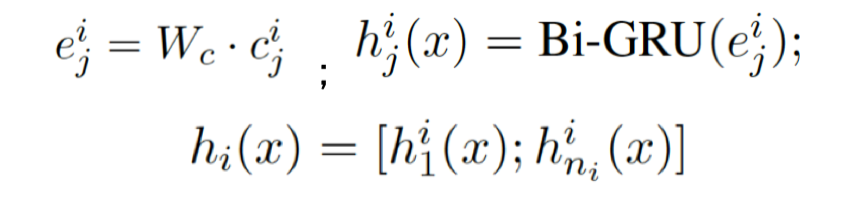
其中ni表示第i個詞的長度,h表示通過字符信息構(gòu)建的詞向量。基于Bi-GRU的字符表示,在每個詞的首尾字符位置是帶上下文信息的,所以將其拼接作為詞的表示。
Heterogeneous Interaction
由于來自原始預(yù)訓(xùn)練模型的表示和來源于character encoder基于字符的表示是異構(gòu)的,很難通過簡單操作將二者融合起來。因此我們設(shè)計了交互式的融合模塊Heterogeneous Interaction, 在每一個transformer層計算后進行迭代式融合,其結(jié)構(gòu)如圖4所示。
圖4 異構(gòu)交互模塊示意圖
該模塊主要包含兩步:融合和分拆。在融合過程中,先對各自表示進行轉(zhuǎn)換后,使用CNN抓取局部特征將兩個來源的信息融合到一起:
在分拆過程中,各自進行新的轉(zhuǎn)換然后基于殘差構(gòu)造各自不同的表示:
融合的目的是讓兩個來源的信息相互補充,分拆是為了各自保持住自己獨有的特征,也為后面不同的預(yù)訓(xùn)練任務(wù)做準備。
無監(jiān)督字符預(yù)訓(xùn)練
為了讓模型更好地學(xué)習(xí)詞內(nèi)部的字符特征,我們設(shè)計了一種無監(jiān)督的字符預(yù)訓(xùn)練任務(wù)NLM(Noisy LM)。通過字符的增刪改自動構(gòu)造一定比例的字符噪音,再通過NLM任務(wù)進行原始序列還原,具體計算如圖5所示。
圖5 NLM預(yù)訓(xùn)練任務(wù)示例
需要注意的是,因為在引入字符噪音之后,每個詞對應(yīng)的切詞組合會變化,因此我們在NLM任務(wù)中預(yù)測粒度是全詞而不是子詞,在預(yù)訓(xùn)練過程中我們需要額外構(gòu)造一個全詞詞表,而該詞表在fine-tuning階段是不需要的。另外,對于原始預(yù)訓(xùn)練模型計算的分支,我們在預(yù)訓(xùn)練階段仍然保持做MLM(Masked LM)任務(wù),該任務(wù)預(yù)測的詞與NLM任務(wù)不交叉,在該部分處理和預(yù)測的詞是不帶噪音的。
下游任務(wù)精調(diào)
NLP中絕大部分分類任務(wù)可以分成兩類:token-level分類(如序列標注)和sequence-level分類(如文本分類)。對于token-level的分類,我們將CharBERT兩個分支的表示拼接進行預(yù)測。對于sequence-level的分類,目前大部分預(yù)訓(xùn)練模型使用‘[CLS]’位做預(yù)測。因為該位置不帶有有效的字符序列,所以我們將兩個分支的表示拼接后取平均再做分類。
實驗
實驗設(shè)置
為了保持對比的公平性,我們不引入額外數(shù)據(jù),僅使用英文維基百科數(shù)據(jù)(12G,2500M words)進行預(yù)訓(xùn)練。由于算力有限,我們只基于BERT和RoBERTa的base模型進行實驗,額外增加的模塊共占用5M的參數(shù)量。預(yù)訓(xùn)練過程進行了320K步迭代,使用兩張32GB顯存的NVIDIA Tesla V100的GPU訓(xùn)練5天左右。我們將MLM中mask的比例從BERT的15%調(diào)低到10%,而NLM中將序列中15%的詞使用隨機增刪改的方式引入噪音。
通用評估
我們在問答、文本分類和序列標注三類任務(wù)中做模型通用效果的評估。其中問答方面我們基于SQuAD 1.1和2.0兩個版本的閱讀理解數(shù)據(jù)集,文本分類基于CoLA、MRPC、QQP和QNLI四個單句和句對分類數(shù)據(jù)集,序列標注方面基于CoNLL-2003 NER和Penn Treebank POS分類數(shù)據(jù)集。主要結(jié)果如下表1和表2所示。
表1閱讀理解、文本分類結(jié)果
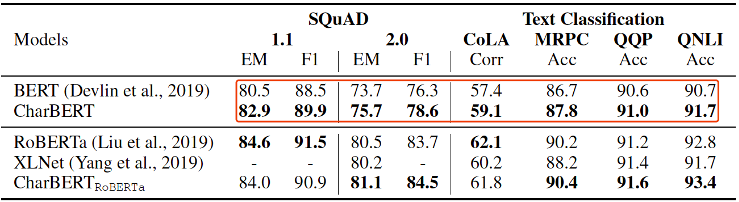
表2命名實體識別、詞性標注結(jié)果
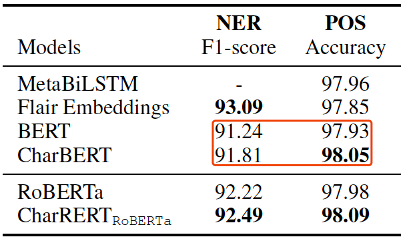
在通用效果的評估上,我們基于BERT的提升比較顯著,但是在RoBERTa的基線上由于baseline的增高,提升比較微弱。另外,在各個任務(wù)的提升幅度上,大致上是序列標注>閱讀理解>文本分類,可能是因為字符信息在序列標注任務(wù)上更為重要。
魯棒性評估
我們基于上述三類任務(wù)進行了魯棒性評估。在該部分評估集的構(gòu)建上,我們主要按照之前的工作[4]通過四種方式進行字符層級的攻擊:dropping, adding, swapping和keyboard。與之前工作不同的是,我們同時考慮問答、文本分類和序列標注三類任務(wù),而不僅僅是某一類任務(wù)上的魯棒性,整體魯棒性對比結(jié)果如下表3所示。
表3魯棒性測試
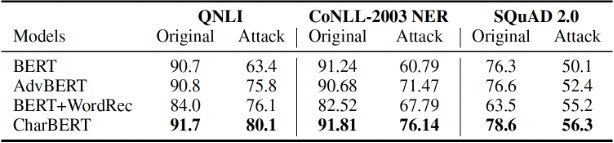
其中AdvBERT是我們基于BERT進行與CharBERT同樣數(shù)據(jù)和超參的預(yù)訓(xùn)練,BERT+WordRec是之前工作[4]在BERT之前增加了一個詞糾正器,Original是原始測試集,Attack是攻擊集合。我們可以看到BERT在攻擊集合上效果下降很大,說明BERT的表示在字符攻擊上確實不魯棒。CharBERT在保持原有集合效果提升的前提下,大幅度提升了BERT的魯棒性。以其中QNLI的數(shù)據(jù)進行具體對比,我們可以發(fā)現(xiàn)各模型效果變化如下。
圖6QNLI上不同模型的魯棒性對比
我們可以看到BERT效果下降幅度超過30%,另外兩個baseline模型效果降幅明顯縮小,而CharBERT下降幅度為12%,顯著超過了所有模型。
分析
為了進一步探究文首所提出的預(yù)訓(xùn)練模型不完整和不魯棒的問題,我們基于CoNLL-2003 NER數(shù)據(jù)的測試集做了進一步分析。
Word vs. Subword
針對不完整性問題,我們將測試集中所有的詞按照是否會被BERT tokenizer切分成多個子詞分成‘Word’和‘Subword’兩個子集合,前者不會被切分(如‘a(chǎn)pple’)而后者會被切分成多個子詞(如‘backhand’)。實際上,‘Subword’部分只包含了所有詞的17.8%但是包含了所有實體的45.3%。CharBERT和BERT在整體與兩個子集合中的效果如下圖7所示。
圖7CoNLL-2003 NER上性能表現(xiàn)對比
首先,對比同一個模型在不同集合上的表現(xiàn),我們發(fā)現(xiàn)‘Word’集合上的效果都要遠高于‘Subword’集合,這說明切分成多個詞確實對模型效果有直接影響,子詞粒度的表示應(yīng)該客觀上存在不充分的問題。對比同一個集合下不同模型的表現(xiàn),我們發(fā)現(xiàn)CharBERT在‘Word’集合上的提升是0.29%,而在‘Subword’集合上的提升是0.68%,這說明主要的提升來源于‘Subword’集合,也就是說我們通過融入字符信息,可以有效提升切分成多個子詞部分的效果,緩解了表示上的不完整問題。
魯棒性分析
針對預(yù)訓(xùn)練模型的魯棒性問題,我們探究預(yù)訓(xùn)練的表示在字符噪音下的變化。我們定義了一個敏感性指標分析模型輸出的詞向量在噪音下的變化量,從而分析模型對噪音的敏感程度,其具體計算如下:
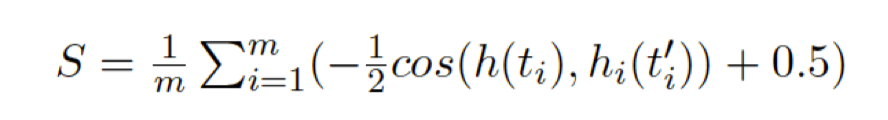
其中m是集合中詞的總數(shù),模型敏感性S本質(zhì)上是模型在整個集合所有序列輸出的表示在引入噪音后的cosine距離均值,如果一個模型對噪音完全不敏感,那么前后表示不變,S=0。對應(yīng)到具體一個序列,我們也可以對每一個詞計算引入噪音后的表示變化,如圖8所示。
圖8CoNLL-2003 NER敏感度測試
我們發(fā)現(xiàn)對于沒有引入噪音的詞如‘I’、‘it’三個模型輸出表示的變化量區(qū)別不大。而對于引入字符噪音的詞如‘think-thnik’、’fair-far’,CharBERT的變化量要遠遠大于BERT,而經(jīng)過噪音數(shù)據(jù)進行訓(xùn)練的AdvBERT則明顯低于BERT。在整個集合統(tǒng)計上也具有相同趨勢:S(BERT)=0.0612,S(AdvBERT)=0.0407,S(CharBERT)=0.0986。說明CharBERT通過NLM的預(yù)訓(xùn)練對噪音部分采用了不同方式的表示,與常規(guī)使用噪音數(shù)據(jù)來提升模型魯棒性方式有些不同。直觀上,我們一般認為越不敏感的模型魯棒性越好,但是CharBERT通過對噪音部分不同的建模,在表示變得敏感的同時也提升了魯棒性,這將啟發(fā)我們后續(xù)提升模型魯棒性的路徑也可以有多種方向。
總結(jié)
本文主要基于目前預(yù)訓(xùn)練模型表示粒度上不完整和不魯棒的兩個問題,提出了字符感知預(yù)訓(xùn)練模型CharBERT,通過在已有預(yù)訓(xùn)練架構(gòu)上融入字符信息來解決這些問題。CharBERT在技術(shù)上融合了傳統(tǒng)的CNN、RNN與現(xiàn)在流行的transformer結(jié)構(gòu),在模型特征上具有字符敏感、魯棒和可拓展的特點,可以自然拓展到現(xiàn)在基于transformer的各種預(yù)訓(xùn)練模型上。另外,由于本工作限于英語單個語種和有限的算力,在通用的任務(wù)上效果提升有限。未來可以在更多的語種,尤其是在字符層級帶有更多形態(tài)學(xué)信息的語言上進行適配,同時也可以在噪音種類上拓展到子詞、句子級別的噪音,更全面地提升預(yù)訓(xùn)練模型的魯棒性。
原文標題:COLING 2020 | 字符感知預(yù)訓(xùn)練模型CharBERT
文章出處:【微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
模型
+關(guān)注
關(guān)注
1文章
3752瀏覽量
52111 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8553瀏覽量
136953
原文標題:COLING 2020 | 字符感知預(yù)訓(xùn)練模型CharBERT
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
從訓(xùn)練到推理:大模型算力需求的新拐點已至

什么是大模型,智能體...?大模型100問,快速全面了解!
在Ubuntu20.04系統(tǒng)中訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型的一些經(jīng)驗
基于神經(jīng)網(wǎng)絡(luò)的數(shù)字預(yù)失真模型解決方案
基于大規(guī)模人類操作數(shù)據(jù)預(yù)訓(xùn)練的VLA模型H-RDT

ai_cube訓(xùn)練模型最后部署失敗是什么原因?
大模型時代的深度學(xué)習(xí)框架

恩智浦eIQ Time Series Studio工具使用教程之模型訓(xùn)練
請問如何在imx8mplus上部署和運行YOLOv5訓(xùn)練的模型?
用PaddleNLP為GPT-2模型制作FineWeb二進制預(yù)訓(xùn)練數(shù)據(jù)集

數(shù)據(jù)標注服務(wù)—奠定大模型訓(xùn)練的數(shù)據(jù)基石
標貝數(shù)據(jù)標注服務(wù):奠定大模型訓(xùn)練的數(shù)據(jù)基石




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論