 基于對抗自注意力機制的預訓練語言模型
基于對抗自注意力機制的預訓練語言模型

Introduction
本文提出了 Adversarial Self-Attention 機制(ASA),利用對抗訓練重構 Transformer 的注意力,使模型在被污染的模型結構中得到訓練。 嘗試解決的問題:
大量的證據表明,自注意力可以從 allowing bias 中獲益,allowing bias 可以將一定程度的先驗(如 masking,分布的平滑)加入原始的注意力結構中。這些先驗知識能夠讓模型從較小的語料中學習有用的知識。但是這些先驗知識一般是任務特定的知識,使得模型很難擴展到豐富的任務上。
adversarial training 通過給輸入內容添加擾動來提升模型的魯棒性。作者發現僅僅給 input embedding 添加擾動很難 confuse 到 attention maps. 模型的注意在擾動前后沒有發生變化。
為了解決上述問題,作者提出了 ASA,具有以下的優勢:
最大化 empirical training risk,在自動化構建先驗知識的過程學習得到biased(or adversarial)的結構。
adversial 結構是由輸入數據學到,使得 ASA 區別于傳統的對抗訓練或自注意力的變體。
使用梯度反轉層來將 model 和 adversary 結合為整體。
ASA 天然具有可解釋性。
Preliminary
表示輸入的特征,在傳統的對抗訓練中, 通常是 token 序列或者是 token 的 embedding, 表示 ground truth. 對于由 參數化的模型,模型的預測結果可以表示為 。
2.1 Adversarial training
對抗訓練的目的是旨在通過推近經過擾動的模型預測和目標分布之間的距離來提升模型的魯棒性:
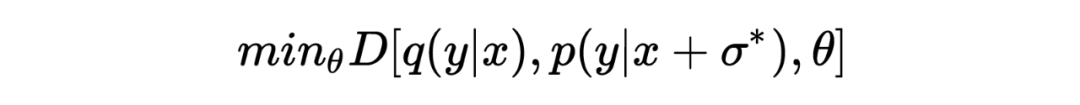
其中 代表經過對抗擾動 擾動后的模型預測, 表示模型的目標分布。 對抗擾動 通過最大化 empirical training risk 獲得:
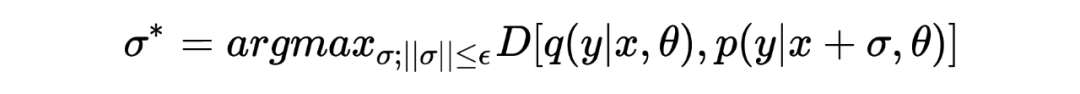
其中 是對 做出的約束,希望在 較小的情況下給模型造成較大的擾動。上述的兩個表示展示的就是對抗的過程。
2.2General Self-Attention
定義自注意力的表達式為:
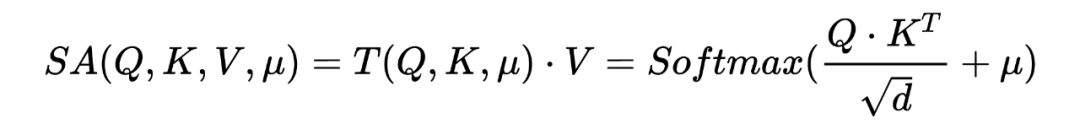
在最普通的自注意力機制中 代表全等矩陣,而之前的研究中, 代表的是用來平滑注意力結構的輸出分布的一定程度的先驗知識。 作者在本文將 定義為元素為 的 binary 矩陣。
Adversarial Self-Attention Mechanism
3.1 Optimization
ASA 的目的是掩蓋模型中最脆弱的注意力單元。這些最脆弱的單元取決于模型的輸入,因此對抗可以表示為由輸入學習到的“meta-knowledge”:,ASA 注意力可以表示為:
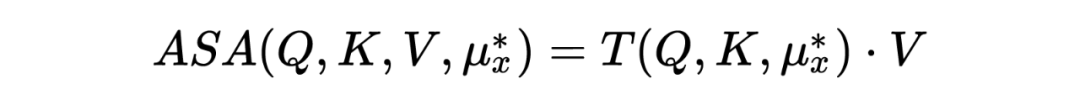
與對抗訓練類似,模型用來最小化如下的 divergence:
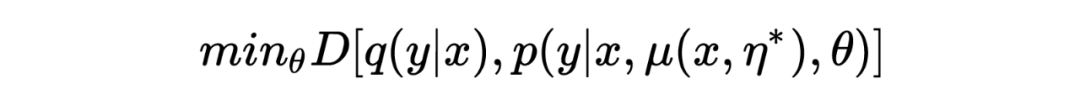
通過最大化 empirical risk 估計得到 :
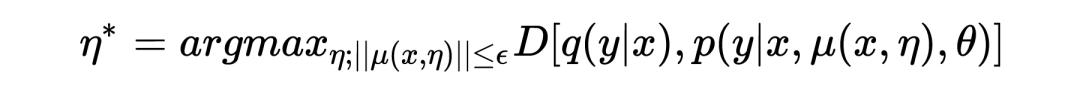
其中 表示的是 的決策邊界,用來防止 ASA 損害模型的訓練。
考慮到 以 attention mask 的形式存在,因此更適合通過約束 masked units 的比例來約束。由于很難測量 。 的具體數值,因此將 hard constraint 轉化為具有懲罰的 unconstraint:
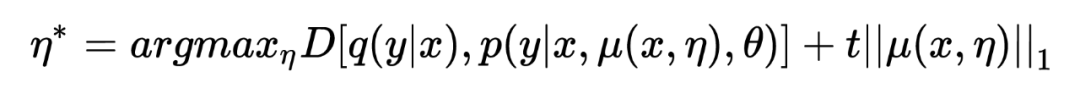
其中 t 用來控制對抗的程度。
3.2 Implementation
作者提出了 ASA 的簡單且快速的實現。
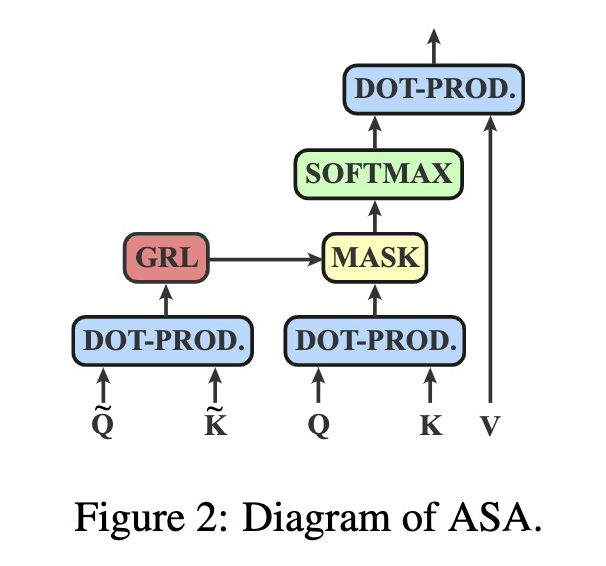
對于第 自注意力層, 可以由輸入的隱層狀態獲得。具體而言,使用線性層將隱層狀態轉化為 以及 ,通過點乘獲得矩陣 ,再通過重參數化技巧將矩陣 binary 化。 由于對抗訓練通常包括 inner maximization 以及 outer minimization 兩個目標,因此至少需要兩次 backward 過程。因此為了加速訓練,作者采用了 Gradient Reversal Layer(GRL)將兩個過程合并。
3.3 Training
訓練目標如下所示:
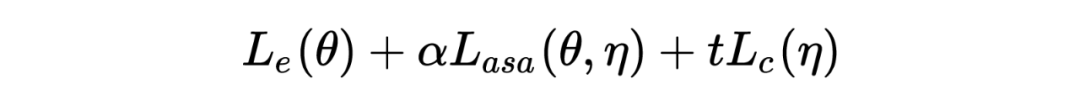
表示 task- specific 損失, 表示加上 ASA 對抗后的損失, 表示對于對于 的約束。
Experiments
4.1Result
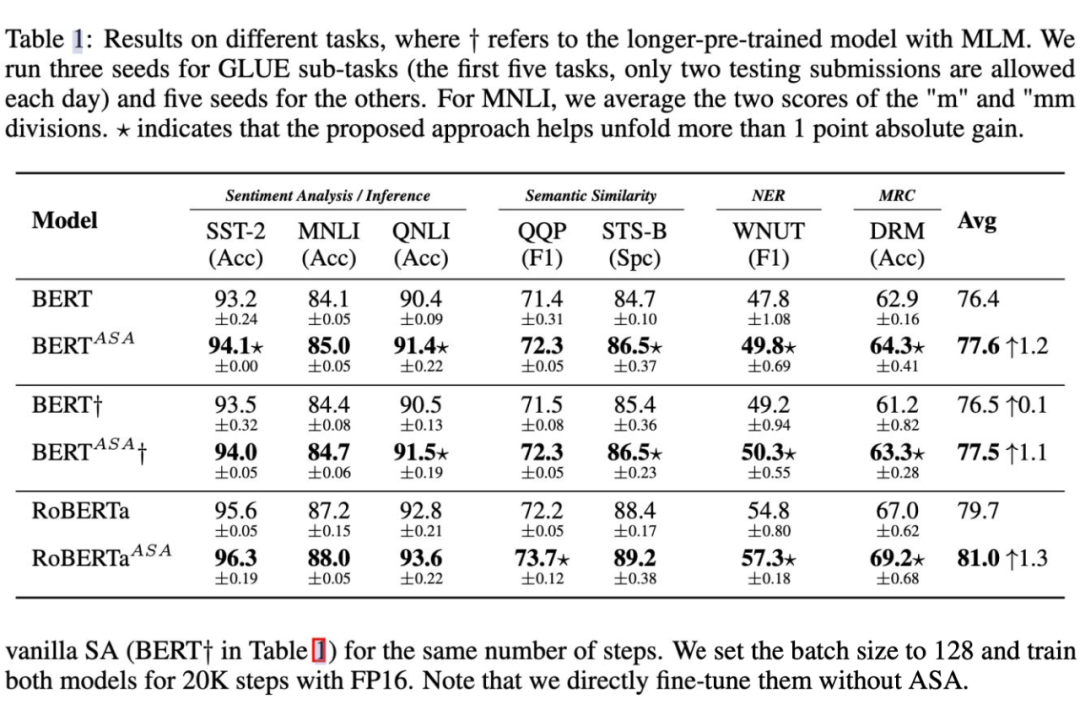
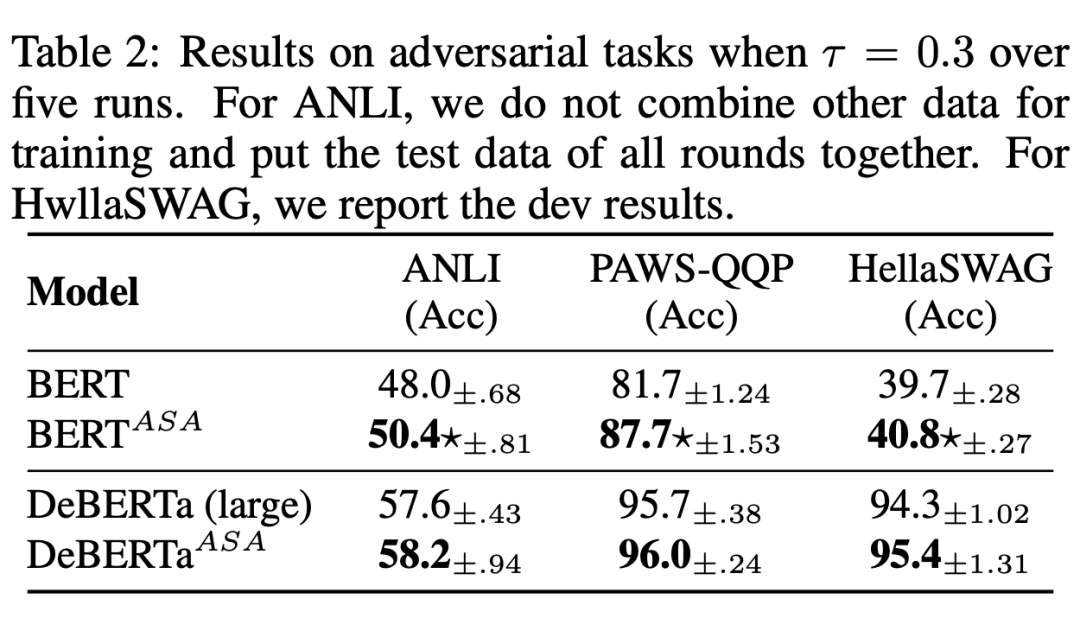
從上表可以看出,在微調方面,ASA 支持的模型始終在很大程度上超過了原始的BERT 和 RoBERTa. 可以看到,ASA 在小規模數據集比如說 STS-B,DREAM 上表現優異(一般認為這些小規模數據集上更容易過擬合)同時在更大規模的數據集上如 MNLI,QNLI 以及 QQP 上仍然有較好的提升,說明了 ASA 在提升模型泛化能力的同時能提升模型的語言表示能力。 如下表所示,ASA 在提升模型魯棒性上具有較大的作用。
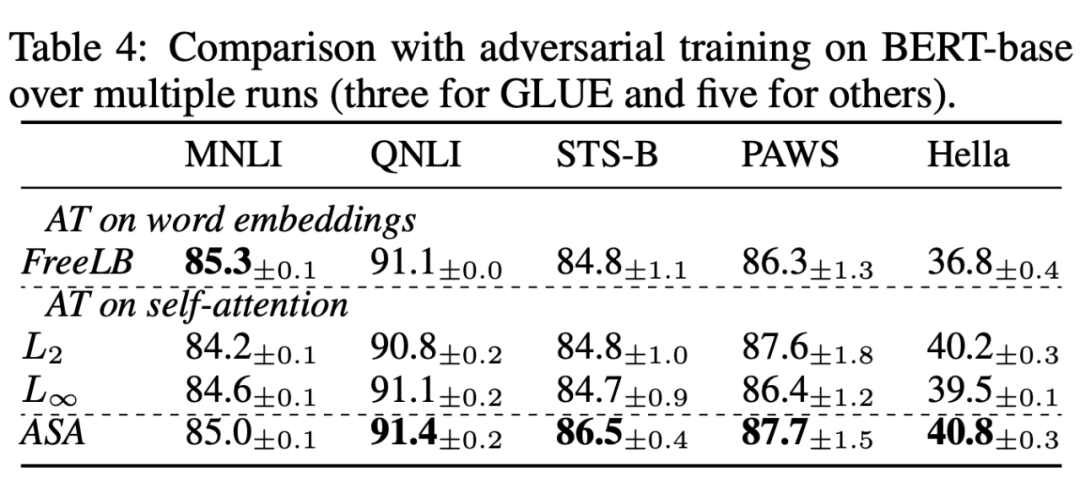
4.2 分析實驗
1. VS. Naive smoothing 將 ASA 與其他注意力平滑方式進行比較。

2. VS. Adversial training 將 ASA 與其他對抗訓練方式進行比較
4.3Visualization
1. Why ASA improves generalization 對抗能夠減弱關鍵詞的注意力而讓非關鍵詞接受更多的注意力。ASA 阻止了模型的懶惰預測,但敦促它從被污染的線索中學習,從而提高了泛化能力。

2. Bottom layers are more vulnerable 可以看到 masking 占比隨著層數由底層到高層逐漸降低,更高的 masking 占比意味著層的脆弱性更高。
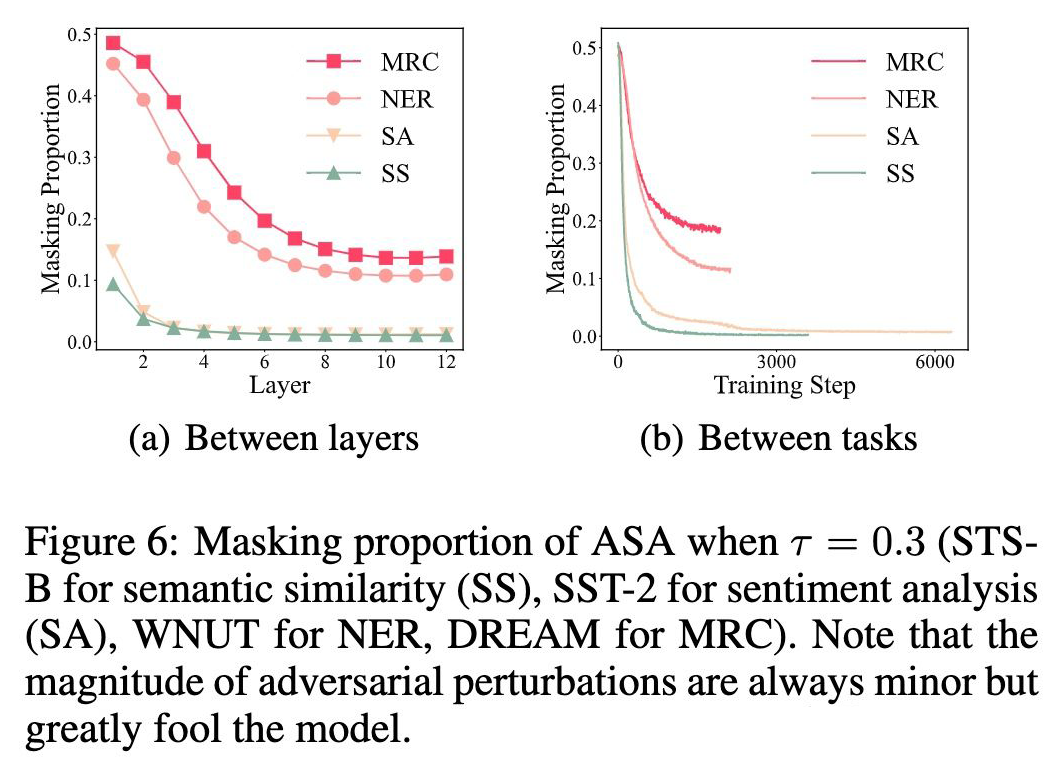
Conclusion
本文提出了 Adversarial Self-Attention mechanism(ASA)來提高預訓練語言模型的泛化性和魯棒性。大量實驗表明本文提出的方法能夠在預訓練和微調階段提升模型的魯棒性。
·審核編輯 :李倩
-
自動化
+關注
關注
31文章
5933瀏覽量
90261 -
語言模型
+關注
關注
0文章
571瀏覽量
11315
原文標題:ICLR2022 | 基于對抗自注意力機制的預訓練語言模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Transformer 入門:從零理解 AI 大模型的核心原理
什么是大模型,智能體...?大模型100問,快速全面了解!

自然場景下注意力如何耳周腦電可靠監測

大語言模型如何處理上下文窗口中的輸入

小白學大模型:大模型加速的秘密 FlashAttention 1/2/3
AI的核心操控:從算法到硬件的協同進化
基于大規模人類操作數據預訓練的VLA模型H-RDT

如何在NVIDIA Blackwell GPU上優化DeepSeek R1吞吐量
【「DeepSeek 核心技術揭秘」閱讀體驗】第三章:探索 DeepSeek - V3 技術架構的奧秘
算力網絡的“神經突觸”:AI互聯技術如何重構分布式訓練范式

AI原生架構升級:RAKsmart服務器在超大規模模型訓練中的算力突破
RAKsmart高性能服務器集群:驅動AI大語言模型開發的算力引擎
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集





 工商網監
工商網監
評論