") 預(yù)訓(xùn)練語言模型設(shè)計(jì)的理論化認(rèn)識(shí)
預(yù)訓(xùn)練語言模型設(shè)計(jì)的理論化認(rèn)識(shí)

在這篇文章中,我會(huì)介紹一篇最新的預(yù)訓(xùn)練語言模型的論文,出自MASS的同一作者。這篇文章的亮點(diǎn)是:將兩種經(jīng)典的預(yù)訓(xùn)練語言模型(MaskedLanguage Model, Permuted Language Model)統(tǒng)一到一個(gè)框架中,并且基于它們的優(yōu)勢和缺點(diǎn),取長補(bǔ)短,提出了一個(gè)新的預(yù)訓(xùn)練語言模型----MPNet,其混合了MLM和PLM各自的優(yōu)勢,達(dá)到了比兩者更好的效果,在Natural Language Understanding和NaturalLanguageGeneration任務(wù)中,都取得了較好的結(jié)果。實(shí)驗(yàn)表明MPNet在大量下游任務(wù)中超越了MLM和PLM,從而證明了pretrain方法中的2個(gè)關(guān)鍵點(diǎn):
被預(yù)測的token之間的依賴關(guān)系 (MPNet vs MLM)
整個(gè)序列的位置信息 (MPNet vs PLM)
MPNet: Masked and Permuted Pre-training for Language Understanding(https://arxiv.org/pdf/2004.09297.pdf)
【小小說】這篇論文我很喜歡,讀下來有一種打通了任督二脈一般行云流水的感覺。在本文中,我會(huì)從BERT和XLNet的統(tǒng)一理論框架講起,然后引出作者如何得到MPNet這一訓(xùn)練方式,接著會(huì)介紹一下作者具體實(shí)現(xiàn)上用到的方法。希望本文可以讓你對預(yù)訓(xùn)練語言模型的設(shè)計(jì)有一個(gè)更加理論化的認(rèn)識(shí)。
1. BERT和XLNet各自的優(yōu)缺點(diǎn)
?既然是從BERT和XLNet到MPNet,那么當(dāng)然是要先從這兩者講起。大家對BERT應(yīng)該比較熟悉,它是劃時(shí)代的工作,可以說從BERT開始,NLP領(lǐng)域正式進(jìn)入了“預(yù)訓(xùn)練模型”的時(shí)代。而XLNet是隨后的重磅之作,在這一節(jié)中,我們先來回顧一下它們。?
「BERT」: Masked Language Model , 使用了雙邊的context信息,但是忽略了masked token之間的依賴關(guān)系
「XLNet」: Permuted Language Model , 保留了masked token之間的依賴關(guān)系,但是預(yù)測的時(shí)候每個(gè)token只能看到permuted sequence中的前置位的token的信息,不能看到所有token的信息。(p.s. 不知道XLNet的寶寶辛苦去復(fù)習(xí) 【論文串講】從GPT和BERT到XLNet )
作者分別從input和output兩個(gè)角度總結(jié)了兩者的優(yōu)缺點(diǎn)分別存在的地方:
「Input Discrepancy」: 在Natural Language Understanding的任務(wù)中,模型可以見到完整的input sentence,因此要求在預(yù)訓(xùn)練階段,input要盡可能輸入完整的信息
MLM中,token的語言信息是不完整的,不過位置信息是保留的(通過position embedding,p.s. 想具體了解如何通過position embedding保留的,請移步參考 【經(jīng)典精讀】Transformer模型深度解讀 中"使用Positional Encoding帶來的獨(dú)特優(yōu)勢"這部分的內(nèi)容)
PLM中,每個(gè)被預(yù)測的token只能“看”到被打亂的序列中位于它自己前面的token,而不能像MLM一樣“看”到兩側(cè)的token。
「Output Dependency」:
MLM中,輸出的token,即在input端被mask掉的token,是「互相獨(dú)立的」。也就是說這些被mask掉的token之間是假定沒有context層面的關(guān)系的。
PLM規(guī)避了MLM中的問題,被預(yù)測的token之間也存在context層面的關(guān)系。
「總結(jié)一下就是:」
?「PLM在output dependency的問題上處理得比MLM好,但是預(yù)訓(xùn)練階段和fine-tune階段之間的差異比MLM的更大。」?
2. 統(tǒng)一MLM和PLM的優(yōu)化目標(biāo)
?了解了BERT和XLNet各自的優(yōu)缺點(diǎn)和適用的場景后,本文的作者試圖從一個(gè)統(tǒng)一的視角去總結(jié)這兩種預(yù)訓(xùn)練模型,而這個(gè)總結(jié),引出了后來的MPNet。?
基于以上兩點(diǎn)觀察,本文的作者提出了統(tǒng)一Masked Language Model和Permuted Language Model的想法,并且起名叫「M」asked and「P」ermuted Language Model,縮寫「MPNet」,意在取兩者之長,避兩者之短。
2.1. 統(tǒng)一優(yōu)化目標(biāo)的提出
MLM: 由于Masked Language Model中的獨(dú)立性假設(shè)“每個(gè)被mask的位置的token之間是彼此獨(dú)立的”,我們可以換一種方式看待Masked Language Model: 把Masked tokens統(tǒng)一挪到序列的末尾,這樣做并不會(huì)改變模型的任何部分,只是我們的看待方式變了。
重新看待Masked Language Model
2. PLM: 原順序 被打亂成
,然后最右邊的兩個(gè)token 和 就被選作要預(yù)測的token。
重新看待Permuted Language Model
基于上述的討論,作者給出了統(tǒng)一MLM和PLM訓(xùn)練目標(biāo)的框架:將沒有被mask的token放在左邊,而將需要被預(yù)測的token(被mask掉的)放在右邊。
「MLM」

「PLM」
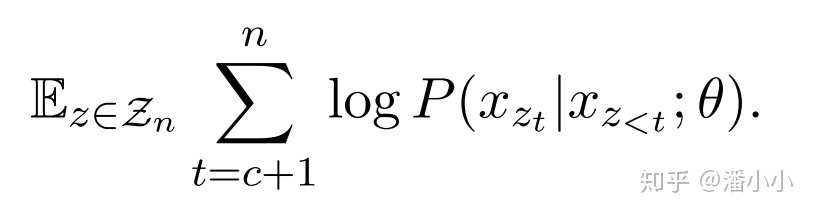
其中,是序列的其中一個(gè)permutation,表示在該permutation中的第 位,表示位置小于的所有位置。
2.2. 討論
MLM和PLM的訓(xùn)練目標(biāo)公式非常接近,唯一的區(qū)別在于,MLM條件概率的條件部分是 和 ; 而PLM的條件部分是,它們的區(qū)別是:
MLM比PLM多了 這個(gè)條件,也就是比PLM多了關(guān)于序列長度的信息(一個(gè)[M]就是一個(gè)位置)。
PLM比MLM多了被預(yù)測部分token之間的相關(guān)性:PLM的 是隨著預(yù)測的進(jìn)行(t的變化)而動(dòng)態(tài)變化的,MLM的 對于整個(gè)模型預(yù)測過程進(jìn)行是恒定不變的。
3. 提出MPNet
?
基于上一節(jié)的總結(jié),作者按照相同的思路提出了MPNet的預(yù)訓(xùn)練目標(biāo)
?
「a. MPNet的預(yù)訓(xùn)練目標(biāo)」
我們既要像MLM那樣,在預(yù)測時(shí)獲取到序列長度的信息;又要像PLM那樣,在預(yù)測后一個(gè)token時(shí),以前面的所有token(包含前置位被預(yù)測出來的)為條件。MPNet做到了:
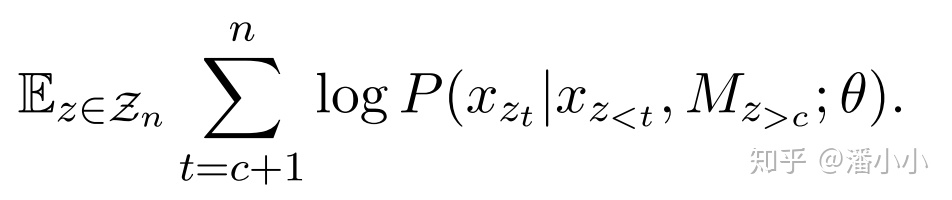
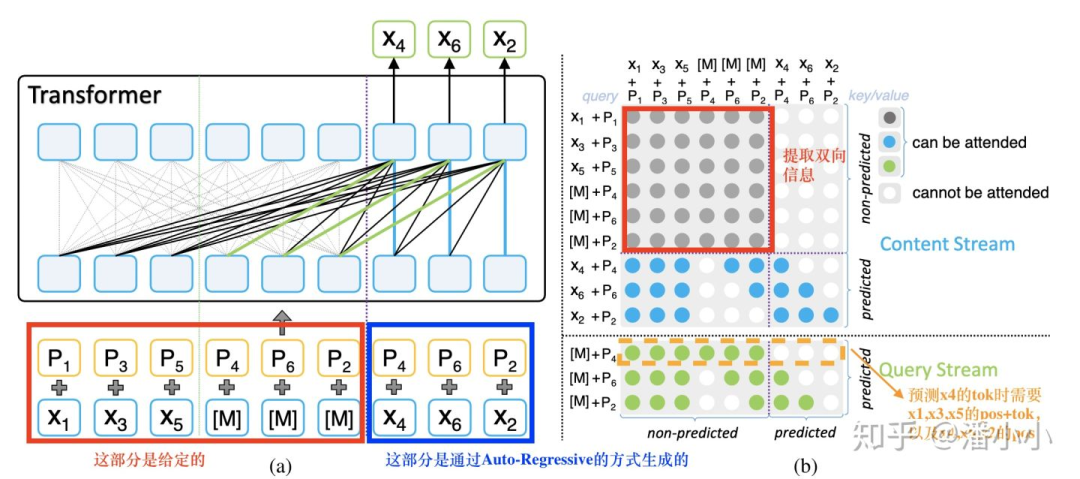
MPNet示意圖
(b)圖中灰色的部分是encoder端的bidirectional self-attention
(b)圖中藍(lán)色和綠色的部分分別是decoder端的two stream self-attention的content stream和query stream (two stream self-attention的具體定義請參考 【論文串講】從GPT和BERT到XLNet ),這里提一下,content stream相當(dāng)于query stream右移一步。
(a)圖中黑色的線+綠色的線即對應(yīng)了(b)圖中的綠色點(diǎn),(a)圖中黑色的線+藍(lán)色的線即對應(yīng)了(b)圖中的藍(lán)色點(diǎn)。
(b)圖中的行對應(yīng)著query position,列對應(yīng)著column position。
「b. ”位置補(bǔ)償“」
由于用到了Permuted Language Model的思想,所以MPNet和XLNet一樣,也要使用two-stream self-attention。想要實(shí)現(xiàn)預(yù)訓(xùn)練目標(biāo)中的 ,在實(shí)現(xiàn)上作者提出了“位置補(bǔ)償”(positioncompensation),也就是說,在預(yù)測過程的每一步,query stream和contentstream都可以看到N(N即序列長度)個(gè)token,具體結(jié)合圖中的例子來說就是,
預(yù)測 時(shí): 已知 , , , , , , , ,
預(yù)測 時(shí): 已知 , , , , , , , , ,
預(yù)測 時(shí): 已知 , , , , , , , , , ,
也就是說,無論預(yù)測到哪一步, , ,
, , , 這6個(gè)位置信息都可見。我們回顧一下XLNet,作一下對比:
預(yù)測 時(shí): 已知 , , , , , ,
預(yù)測 時(shí): 已知 , , , , , , , ,
預(yù)測 時(shí): 已知 , , , , , , , , , ,
可以看出,在預(yù)測 時(shí),比MPNet少了 , ,在預(yù)測 時(shí),比MPNet少了 。
「c. 總結(jié)」

MPNet有效性來自于它保留了更多的信息
通過上面的詳細(xì)講解,相信到這兒大家也明白了:MPNet保留的信息是BERT和XLNet的并集,第一,它利用PLM的自回歸特性,規(guī)避了MLM的獨(dú)立性假設(shè),在預(yù)測后面token時(shí)也利用了之前預(yù)測出來的token;第二,它利用MLM建模中自帶的序列信息,規(guī)避了PLM在預(yù)測前面的token時(shí)不知道序列整體的長度的缺點(diǎn)。這兩點(diǎn)保證了MPNet完美揚(yáng)長避短,因此在下游任務(wù)中完美擊敗了前兩者。
給我們的啟發(fā)
致力于彌合pre-train階段和下游任務(wù)fine-tune階段的預(yù)訓(xùn)練目標(biāo),盡可能減少訓(xùn)練和預(yù)測過程中信息的損失,是研究預(yù)訓(xùn)練模型的重中之重,也是預(yù)訓(xùn)練模型領(lǐng)域整體的發(fā)展方向。讀預(yù)訓(xùn)練系列論文的時(shí)候一定要抓住這個(gè)核心線索去讀。
責(zé)任編輯:xj
原文標(biāo)題:【論文串講】從BERT和XLNet到MPNet
文章出處:【微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
PLM
+關(guān)注
關(guān)注
2文章
148瀏覽量
22086 -
nlp
+關(guān)注
關(guān)注
1文章
491瀏覽量
23280 -
訓(xùn)練模型
+關(guān)注
關(guān)注
1文章
37瀏覽量
4071
原文標(biāo)題:【論文串講】從BERT和XLNet到MPNet
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
什么是大模型,智能體...?大模型100問,快速全面了解!

在Ubuntu20.04系統(tǒng)中訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型的一些經(jīng)驗(yàn)
基于大規(guī)模人類操作數(shù)據(jù)預(yù)訓(xùn)練的VLA模型H-RDT

龍芯中科與文心系列模型開展深度技術(shù)合作
兆芯率先展開文心系列模型深度技術(shù)合作
海思SD3403邊緣計(jì)算AI數(shù)據(jù)訓(xùn)練概述
大模型時(shí)代的深度學(xué)習(xí)框架

請問如何在imx8mplus上部署和運(yùn)行YOLOv5訓(xùn)練的模型?
用PaddleNLP為GPT-2模型制作FineWeb二進(jìn)制預(yù)訓(xùn)練數(shù)據(jù)集

自動(dòng)化標(biāo)注技術(shù)推動(dòng)AI數(shù)據(jù)訓(xùn)練革新
憶聯(lián)PCIe 5.0 SSD支撐大模型全流程訓(xùn)練



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論