 關于語言模型和對抗訓練的工作
關于語言模型和對抗訓練的工作

論文:Adversarial Training for Large NeuralLangUageModels
源碼:https://github.com/namisan/mt-dnn
TL;DR
本文把對抗訓練用到了預訓練和微調兩個階段,對抗訓練的方法是針對embedding space,通過最大化對抗損失、最小化模型損失的方式進行對抗,在下游任務上取得了一致的效果提升。
有趣的是,這種對抗訓練方法不僅能夠在BERT上有提高,而且在RoBERTa這種已經預訓練好的模型上也能有所提高,說明對抗訓練的確可以幫助模型糾正易錯點。
方法:ALUM(大型神經語言模型的對抗性訓練)
實現:在embedding space添加擾動,最大化對抗損失
應用:任何基于Transformer的語言模型的預訓練或微調
預備知識
BPE編碼
為了解決詞匯表外單詞的問題,使用Byte-Pair Encoding(BPE)(Sennrich et al.,2015)或其變體(Kudo and Richardson,2018)將標記劃分為子詞單元,生成固定大小的子詞詞匯,以便在訓練文本語料庫中緊湊地表示單詞。
BPE詞表既存在char-level級別的字符,也存在word-level級別的單詞。通過BPE得到了更加合適的詞表,這個詞表可能會出現一些不是單詞的組合,但是這個本身是有意義的一種形式。
流程:
確定subword詞表大小
統計每一個連續字節對的出現頻率,并保存為code_file。這個是git中learn-bpe完成
將單詞拆分為字符序列并在末尾添加后綴“ ”,而后按照code_file合并新的subword,首先合并頻率出現最高的字節對。例如單詞birthday,分割為['b', 'i', 'r', 't', 'h', 'd', 'a', 'y'],查code_file,發現'th'出現的最多,那么合并為['b', 'i', 'r', 'th', 'd', 'a', 'y'],最后,字符序列合并為['birth', 'day']。然后去除'',變為['birth', 'day'],將這兩個詞添加到詞表。這個是apply-bpe完成。
重復第3步直到達到第2步設定的subword詞表大小或下一個最高頻的字節對出現頻率為1
模型:ALUM
基于幾個關鍵想法:
擾動embedding空間,優于直接對輸入文本應用擾動。
通過虛擬對抗訓練為標準目標添加正則化項。
其中預訓練階段 ,微調階段
因為有最大化操作,所以訓練昂貴。有利于embedding鄰域的標簽平滑。
文中觀點:
虛擬對抗訓練優于傳統對抗訓練,特別是當標簽可能有噪聲時。
例如,BERT pretraining使用masked words作為自監督的標簽,但在許多情況下,它們可以被其他詞取代,形成完全合法的文本。但BERT中,給到被替換的word的標簽均為負。
首先使用標準目標(1)訓練模型;然后使用虛擬對抗訓練(3)繼續訓練。
第4-6行為求最大梯度步驟,以找到使對抗性損失最大化的擾動(反局部平滑性)。K越大的近似值越高,但成本更高。為了在速度和性能之間取得良好的平衡,本文實驗K=1.
泛化與魯棒性
文中表示,通過使用ALUM進行對抗性的預訓練,能夠提高廣泛的NLP任務的泛化和魯棒性(如后述實驗結論所示)。之前的研究較多發現,對抗訓練會損害泛化能力。
先前關于泛化和魯棒性之間沖突的工作通常集中在有監督的學習環境中。調和兩者的一些初顯成果也利用了未標記的數據,例如自訓練(Raghunathan等人,2020年)。
此外,假設通過擾動embedding空間而不是輸入空間,NLP中的對抗訓練可能無意中偏向于流形擾動而不是規則擾動。
什么是流形
流形學習的觀點:認為我們所觀察到的數據實際上是由一個低維流形映射到高維空間的。由于數據內部特征的限制,一些高維中的數據會產生維度上的冗余,實際上這些數據只要比較低的維度的維度就能唯一的表示。
所以直觀上來講,一個流形好比是一個d維的空間,在一個m維的空間中(m>d)被扭曲之后的結果。需要注意的是流形不是一個形狀,而是一個空間。舉個例子,比如說一塊布,可以把它看成一個二維的平面,這是一個二維的空間,現在我們把它扭一扭(三維空間),它就變成了一個流形,當然不扭的時候,它也是一個流形,歐氏空間是流形的一種特殊情況。
實驗
提升泛化能力
BERT BASE是使用與Devlin等人相同的設置訓練的標準BERT base模型。(即1M步,batch size = 256)。
BERT+BASE與BERT BASE相似,不同之處在于其訓練步數為1.6M,與對抗預訓練所需時間大致相同(ALUM BERT-BASE)。
ALUM BERT-BASE是一個BERT模型,使用與BERT BASE相同的設置進行訓練,但最后的500K步驟使用ALUM。每一個對抗訓練步驟大約比標準訓練步驟長1.5倍。

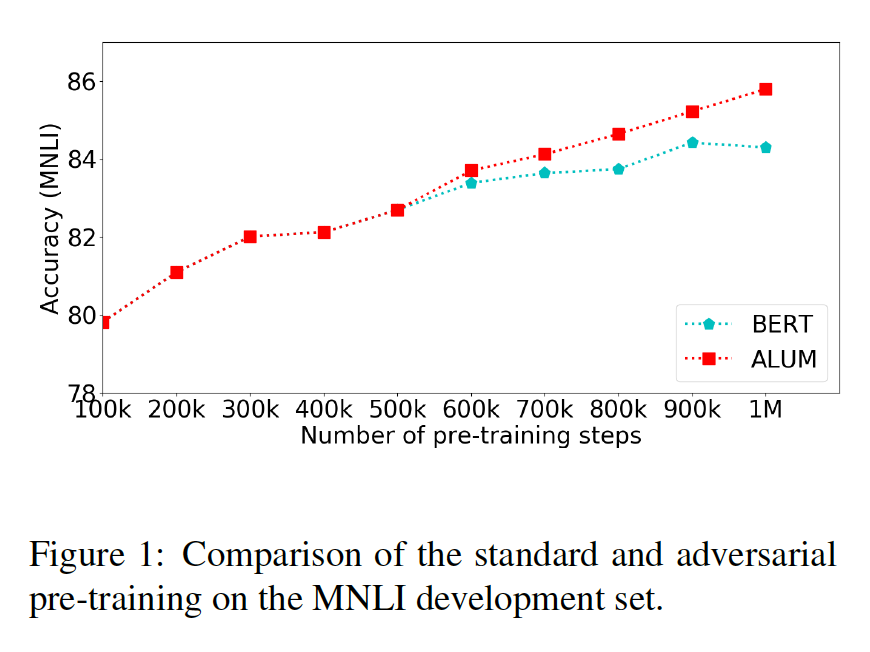
可以觀察到后500k加了ALUM后提升明顯。
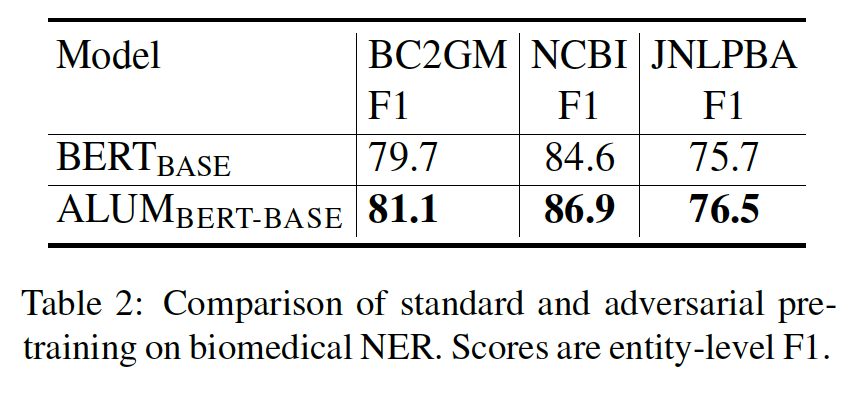
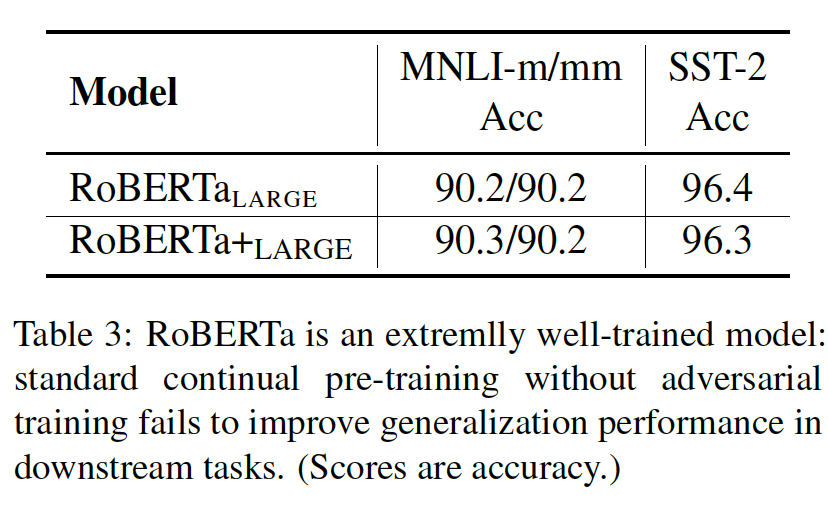
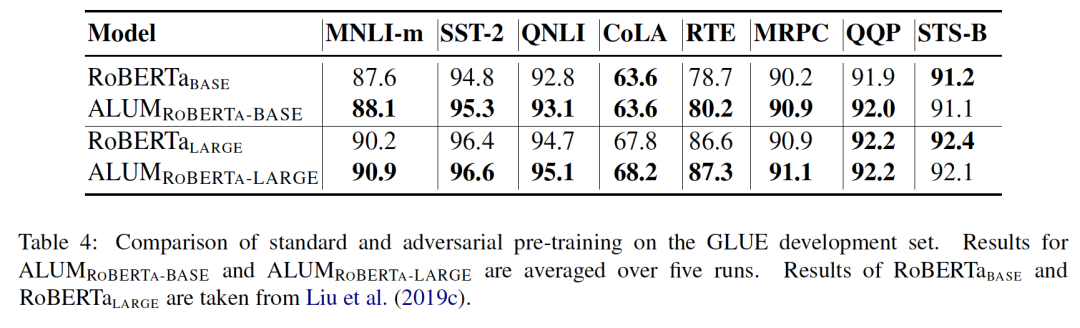
提升魯棒性
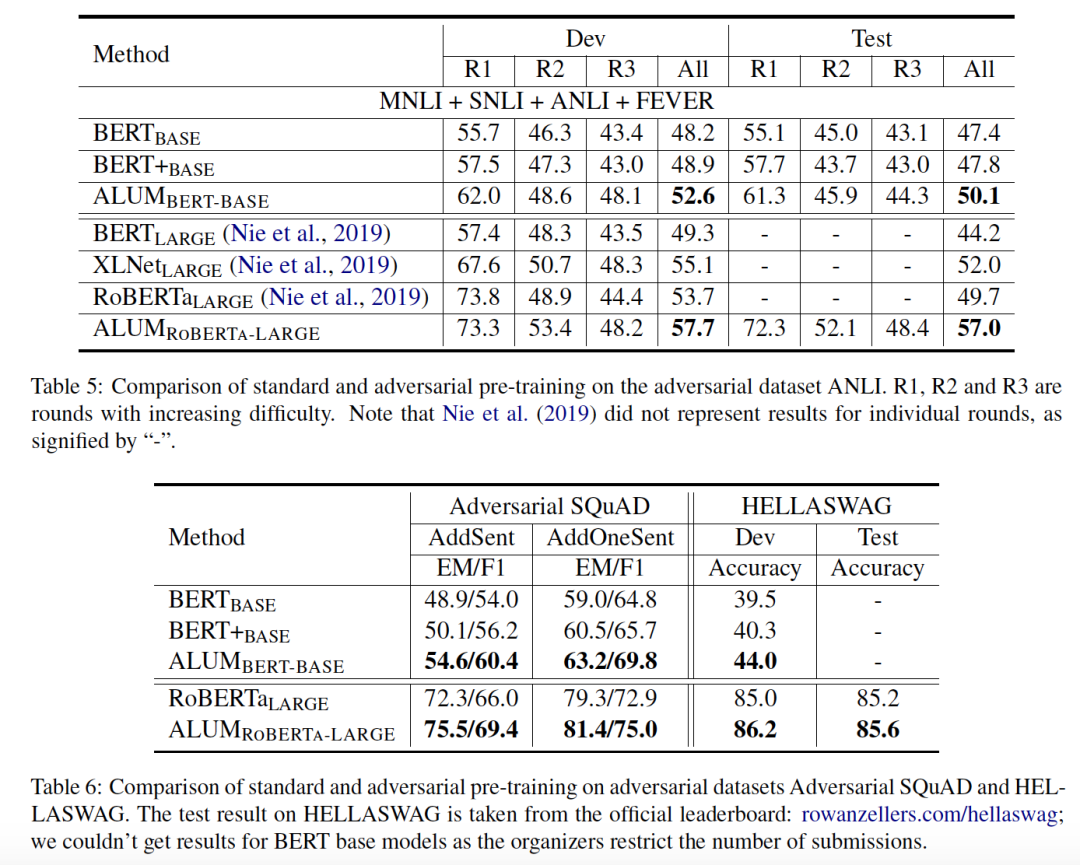
結合對抗預訓練和對抗微調
之前都是在預訓練階段做的對抗,ALUM RoBERTa-LARGE-SMART在預訓練和微調階段均做對抗。
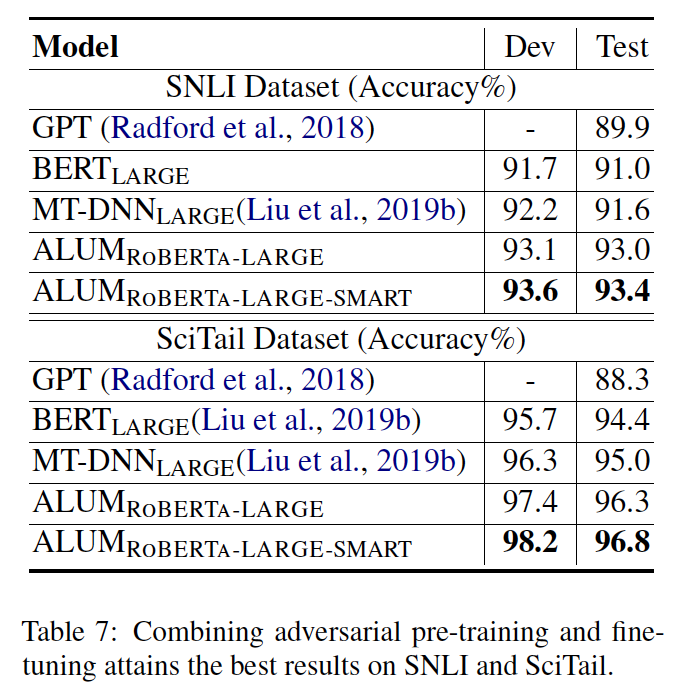
結論
提出了一種通用的對抗性訓練算法ALUM:
對抗預訓練可以顯著提高泛化能力和魯棒性。
ALUM大大提高了BERT和RoBERTa在各種NLP任務中的準確性,并且可以與對抗微調相結合以獲得進一步的收益。
未來的發展方向:
進一步研究對抗性預訓練在提高泛化和魯棒性方面的作用;
對抗性訓練加速;
將ALUM應用于其他領域。
責任編輯:xj
原文標題:【微軟ALUM】當語言模型遇到對抗訓練
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
微軟
+關注
關注
4文章
6741瀏覽量
107850 -
算法
+關注
關注
23文章
4784瀏覽量
98038 -
語言模型
+關注
關注
0文章
571瀏覽量
11310 -
nlp
+關注
關注
1文章
491瀏覽量
23280
原文標題:【微軟ALUM】當語言模型遇到對抗訓練
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
從訓練到推理:大模型算力需求的新拐點已至

什么是大模型,智能體...?大模型100問,快速全面了解!
在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
ai_cube訓練模型最后部署失敗是什么原因?
沐曦MXMACA軟件平臺在大模型訓練方面的優化效果

恩智浦eIQ Time Series Studio工具使用教程之模型訓練
請問如何在imx8mplus上部署和運行YOLOv5訓練的模型?
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

數據標注服務—奠定大模型訓練的數據基石
標貝數據標注服務:奠定大模型訓練的數據基石

利用RAKsmart服務器托管AI模型訓練的優勢
?VLM(視覺語言模型)?詳細解析




 工商網監
工商網監
評論