") 微調(diào)前給預(yù)訓(xùn)練模型參數(shù)增加噪音提高效果的方法
微調(diào)前給預(yù)訓(xùn)練模型參數(shù)增加噪音提高效果的方法

寫(xiě)在前面
昨天看完NoisyTune論文,做好實(shí)驗(yàn)就來(lái)了。一篇ACL2022通過(guò)微調(diào)前給預(yù)訓(xùn)練模型參數(shù)增加噪音提高預(yù)訓(xùn)練語(yǔ)言模型在下游任務(wù)的效果方法-NoisyTune,論文全稱《NoisyTune: A Little Noise Can Help You Finetune Pretrained Language Models Better》。
paper地址:https://aclanthology.org/2022.acl-short.76.pdf
由于僅加兩行代碼就可以實(shí)現(xiàn),就在自己的數(shù)據(jù)上進(jìn)行了實(shí)驗(yàn),發(fā)現(xiàn)確實(shí)有所提高,為此分享給大家;不過(guò)值得注意的是,「不同數(shù)據(jù)需要加入噪音的程度是不同」,需要自行調(diào)參。
模型
自2018年BERT模型橫空出世,預(yù)訓(xùn)練語(yǔ)言模型基本上已經(jīng)成為了自然語(yǔ)言處理領(lǐng)域的標(biāo)配,「pretrain+finetune」成為了主流方法,下游任務(wù)的效果與模型預(yù)訓(xùn)練息息相關(guān);然而由于預(yù)訓(xùn)練機(jī)制以及數(shù)據(jù)影響,導(dǎo)致預(yù)訓(xùn)練語(yǔ)言模型與下游任務(wù)存在一定的Gap,導(dǎo)致在finetune過(guò)程中,模型可能陷入局部最優(yōu)。
為了減輕上述問(wèn)題,提出了NoisyTune方法,即,在finetune前加入給預(yù)訓(xùn)練模型的參數(shù)增加少量噪音,給原始模型增加一些擾動(dòng),從而提高預(yù)訓(xùn)練語(yǔ)言模型在下游任務(wù)的效果,如下圖所示,
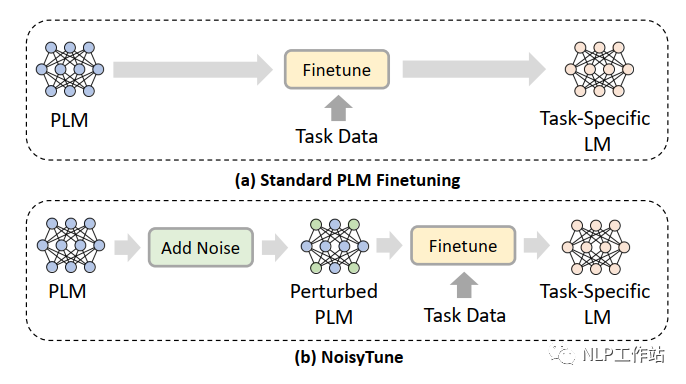
通過(guò)矩陣級(jí)擾動(dòng)(matrix-wise perturbing)方法來(lái)增加噪聲,定義預(yù)訓(xùn)練語(yǔ)言模型參數(shù)矩陣為,其中,表示模型中參數(shù)矩陣的個(gè)數(shù),擾動(dòng)如下:
其中,表示從到范圍內(nèi)均勻分布的噪聲;表示控制噪聲強(qiáng)度的超參數(shù);表示標(biāo)準(zhǔn)差。
代碼實(shí)現(xiàn)如下:
forname,parainmodel.namedparameters():
model.statedict()[name][:]+=(torch.rand(para.size())?0.5)*noise_lambda*torch.std(para)
這種增加噪聲的方法,可以應(yīng)用到各種預(yù)訓(xùn)練語(yǔ)言模型中,可插拔且操作簡(jiǎn)單。
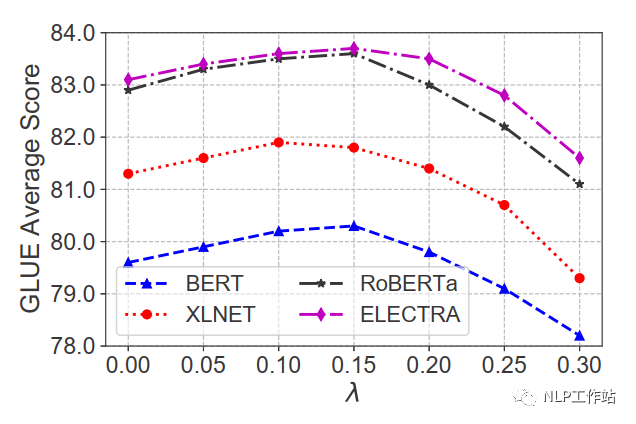
如下表所示,在BERT、XLNET、RoBERTa和ELECTRA上均取得不錯(cuò)的效果。
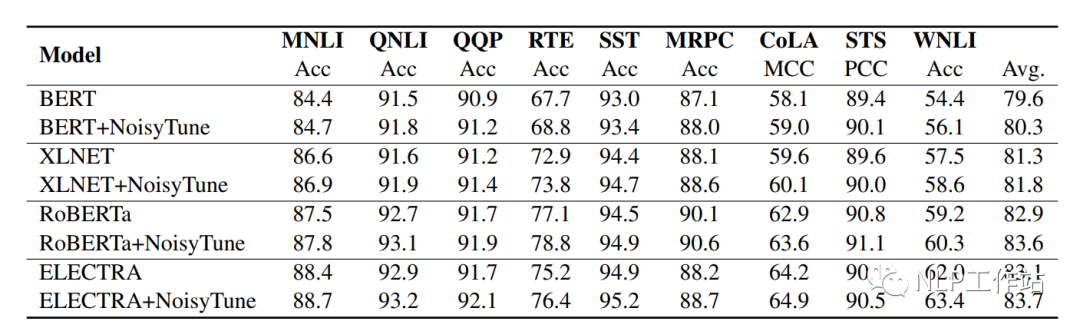
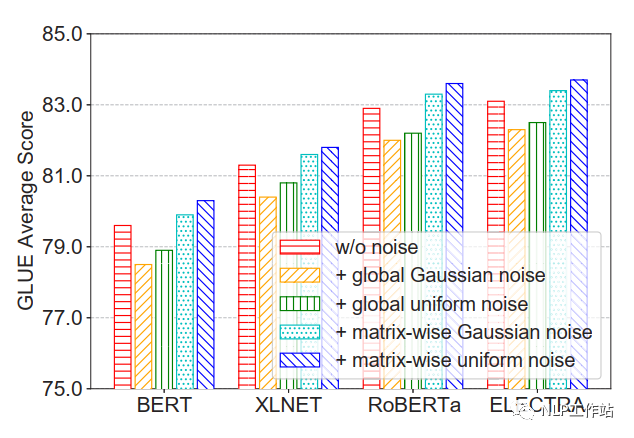
并且比較的四種不同增加噪聲的方法,發(fā)現(xiàn)在矩陣級(jí)均勻噪聲最優(yōu)。
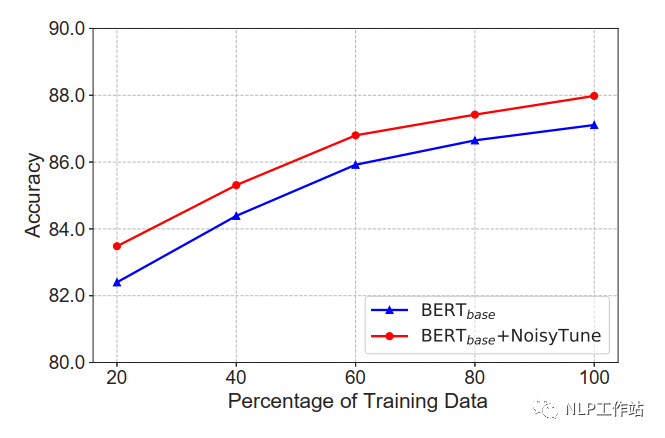
在不同數(shù)據(jù)量下,NoisyTune方法相對(duì)于finetune均有所提高。
在不同噪聲強(qiáng)度下,效果提升不同,對(duì)于GLUE數(shù)據(jù)集,在0.1-0.15間為最佳。
總結(jié)
蠻有意思的一篇論文,加入少量噪音,提高下游微調(diào)效果,并且可插拔方便易用,可以納入到技術(shù)庫(kù)中。
本人在自己的中文數(shù)據(jù)上做了一些實(shí)驗(yàn),發(fā)現(xiàn)結(jié)果也是有一些提高的,一般在0.3%-0.9%之間,但是噪聲強(qiáng)度在0.2時(shí)最佳,并且在噪聲強(qiáng)度小于0.1或大于0.25后,會(huì)比原始效果差。個(gè)人實(shí)驗(yàn)結(jié)果,僅供參考。
審核編輯 :李倩
-
噪音
+關(guān)注
關(guān)注
1文章
171瀏覽量
24539 -
模型
+關(guān)注
關(guān)注
1文章
3751瀏覽量
52099 -
自然語(yǔ)言處理
+關(guān)注
關(guān)注
1文章
630瀏覽量
14667
原文標(biāo)題:ACL2022 | NoisyTune:微調(diào)前加入少量噪音可能會(huì)有意想不到的效果
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
在Ubuntu20.04系統(tǒng)中訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型的一些經(jīng)驗(yàn)
借助NVIDIA Megatron-Core大模型訓(xùn)練框架提高顯存使用效率

基于大規(guī)模人類操作數(shù)據(jù)預(yù)訓(xùn)練的VLA模型H-RDT

利用自壓縮實(shí)現(xiàn)大型語(yǔ)言模型高效縮減

大模型推理顯存和計(jì)算量估計(jì)方法研究
運(yùn)行kmodel模型驗(yàn)證一直報(bào)錯(cuò)怎么解決?
如何高效訓(xùn)練AI模型?這些常用工具你必須知道!
閃存破局“內(nèi)存焦慮”,AI微調(diào)訓(xùn)練增加閃存消耗

請(qǐng)問(wèn)如何在imx8mplus上部署和運(yùn)行YOLOv5訓(xùn)練的模型?
用PaddleNLP為GPT-2模型制作FineWeb二進(jìn)制預(yù)訓(xùn)練數(shù)據(jù)集

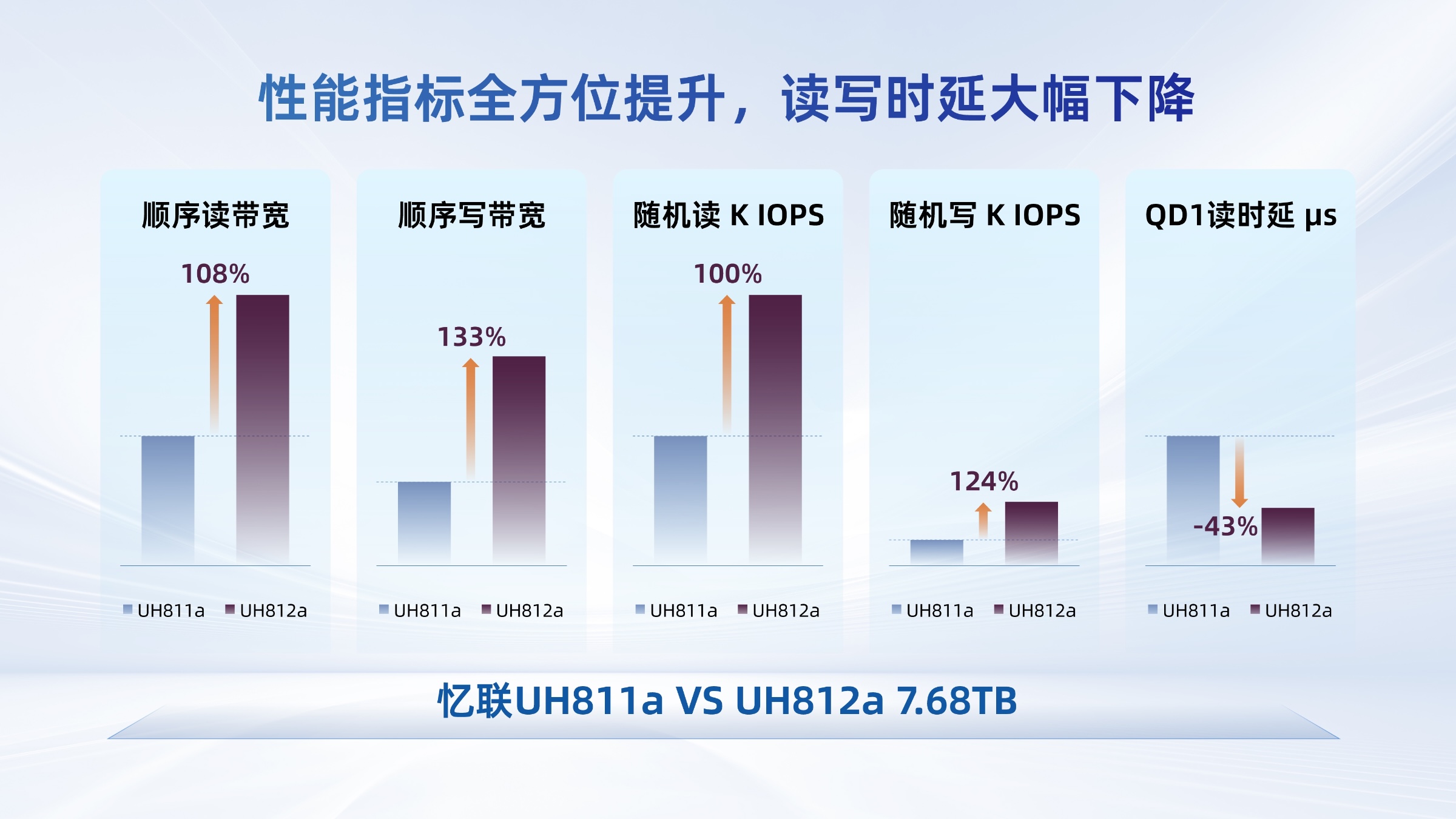
憶聯(lián)PCIe5.0 SSD以軟硬協(xié)同的高可靠性,支撐大模型全流程訓(xùn)練
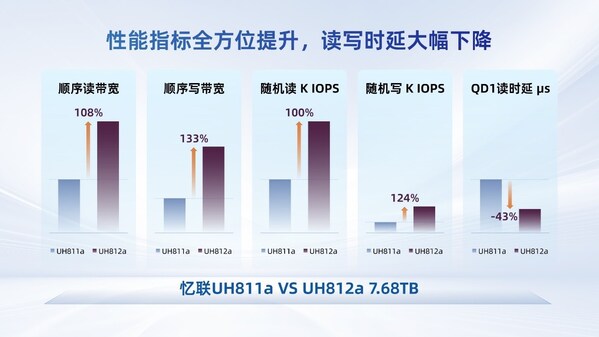
憶聯(lián)PCIe 5.0 SSD支撐大模型全流程訓(xùn)練



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論