 超大Transformer語言模型的分布式訓練框架
超大Transformer語言模型的分布式訓練框架

NVIDIA Megatron 是一個基于 PyTorch 的框架,用于訓練基于 Transformer 架構的巨型語言模型。本系列文章將詳細介紹Megatron的設計和實踐,探索這一框架如何助力大模型的預訓練計算。
大模型是大勢所趨
近年來,NLP 模型的發展十分迅速,模型的大小每年以1-2個數量級的速度在提升,背后的推動力當然是大模型可以帶來更強大更精準的語言語義理解和推理能力。
截止到去年,OpenAI發布的GPT-3模型達到了175B的大小,相比2018年94M的ELMo模型,三年的時間整整增大了1800倍之多。按此趨勢,預計兩年后,會有100 Trillion參數的模型推出。
另外一個特點是,自從18年 Google 推出 Attention is All You Need論文后,這幾年的模型架構,不管是雙向的BERT,還是生成式的GPT,都是基于Transformer 架構來構建的,通常說的模型有多少層,指的便是有多少個Transformer塊來堆疊起來的。
而且,這類模型的計算量也主要來自于對Transformer塊的處理,其本質上可以轉化成大量的矩陣操作,天然地適合NVIDIA GPU的并行架構。
分布式是大模型訓練的必須
大模型的預訓練對計算、通信帶來的挑戰是不言而喻的。我們以GPT-3 175B 模型為例,分析預訓練對計算量、顯存、通信帶來的挑戰。
GPT-3 175B模型的參數如下:網絡層(Number of layers): 96
句子長度(Sequence length): 2048
隱藏層大小(Hidden layer size): 12288
詞匯表(Vocabulary size):51200
總參數量:約175B
1. 對顯存的挑戰
175B的模型,一個原生沒有經過優化的框架執行,各部分大概需要的顯存空間:
模型參數:700 GB (175B * 4bytes)
參數對應的梯度:700 GB
優化器狀態:1400 GB
所以,一個175B模型共需要大概2.8 TB的顯存空間,這對 GPU 顯存是巨大的挑戰:
1)模型在單卡、單機上存放不下。以 NVIDIA A100 80GB為例,存放此模型需要超過35塊。
2) 必須使用模型并行,并且需要跨機器。主流的A100 服務器是單機八卡,需要在多臺機器之間做模型切分。
2. 對計算的挑戰
基于Transformer 架構的模型計算量主要來自于Transformer層和 logit 層里的矩陣乘,可以得出每個迭代步大致需要的計算量:
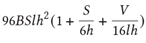
B: 批大小,S:句子長度,l:Transformer 層數,h:隱藏層大小,V:詞匯表大小
這是真實計算量的一個下限,但已是非常接近真實的計算量。關于此公式的詳細說明,請參考 NVIDIA Paper(https://arxiv.org/abs/2104.04473)里的附錄章節。
其中S=2048, l=96, h=12288, V=51200,在我們的實踐中,B = 1536,一共需要迭代大約95000次。代入這次參數到上述公式,可以得到:
一次迭代的計算量:4.5 ExaFLOPS.
完整訓練的計算量:430 ZettaFLOPS (~95K 次迭代)
這是一個巨大的計算量,以最新的 NVIDIA A100 的FP16計算能力 312 TFLOPS來計算,即使不考慮計算效率和擴展性的情況,需要大概16K A100*days的計算量。直觀可以理解為16000塊A100一天的計算量,或者一塊A100 跑43.8年的計算量。
3. 對通信的挑戰
訓練過程中GPU之間需要頻繁的通信,這些通信源于模型并行和數據并行的應用,而不同的并行劃分策略產生的通信模式和通信量不盡相同。
對于數據并行來說,通信發生在后向傳播,用于梯度通信,通信類型為AllReduce,每次后向傳播中的通信量為每個GPU上的模型大小。
對于模型并行來說,稍微復雜些。模型并行通常有橫切和豎切兩種,比如把一個模型按網絡層從左到右橫著擺放,橫切即把每個網絡層切成多份(Intra-layer),每個GPU上計算網絡層的不同切塊,也稱為Tensor(張量)模型并行。豎切即把不同的網絡層切開(Inter-layer),每個GPU上計算不同的網絡層,也稱為Pipeline (流水線)模型并行。
對于Tensor模型并行,通信發生在每層的前向和后向傳播,通信類型為AllReduce,通信頻繁且通信量比較大。
對于Pipeline 模型并行,通信發生在相鄰的切分點,通信類型主要為P2P,每次通信數據量比較少但比較頻繁,而且會引入額外的GPU 空閑等待時間。
稍后會詳細闡述在Transformer 架構上如何應用這兩種模型劃分方式。
更為復雜的是,對于超大的語言模型,通常會采用數據并行 + Tensor 模型并行 + Pipeline 模型并行混合的方式,這使得通信方式錯綜復雜在一起,對系統連接拓撲提出更大的挑戰:能靈活滿足不同劃分策略、不同通信模式下,不同通信組里高效的通信。
總而言之,超大語言模型的預訓練,采用多節點的分布式訓練是必須,而且是基于模型并行的。這就對集群架構和訓練框架提出了嚴苛的設計要求,集群架構要有優化的互聯設計,訓練框架更為重要:不僅僅是結合算法特點對模型做合理切割,更是需要做出結合系統架構特點、軟硬一體的co-design。
為此,NVIDIA 分別提出了優化的分布式框架NVIDIA Megatron 和優化的分布式集群架構 NVIDIA DGX SuperPOD。
優化的分布式框架:NVIDIA Megatron
Megatron設計就是為了支持超大的Transformer模型的訓練的,因此它不僅支持傳統分布式訓練的數據并行,也支持模型并行,包括Tensor并行和Pipeline并行兩種模型并行方式。
1. Tensor 模型并行
上面我們看到,對于一個Transformer塊,主要包括Masked Multi Self Attention和Feed Forward兩個部分,對于Tensor并行,需要把這兩部分都并行化。
對于Feed Forward部分,是由多個全連接層組成的MLP網絡,每個全連接層由矩陣乘和GeLU激活或Dropout組成,在Megatron中,Feed Forward采用兩層全連接層。對于一個全連接層,可以表示為:
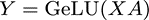
其中X輸入,A為參數矩陣,Y為輸出,則可以有兩種并行方式。
一種是按行的方向把權重矩陣A切分開并按列的方向把輸入X切分開,即: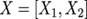
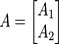 則輸出:
則輸出:
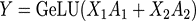
其中括號中的每一項,可以在一個單獨的GPU上獨立的完成,再通過一次AllReduce完成求和操作。
另一種則是按列的方向把權重矩陣A切分開,而不切分輸入,即:
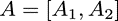
則可以得到同樣按列方向切分開的輸出:
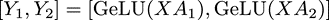
方括號中每一項可以在一個單獨的GPU上獨立的完成,這樣每個GPU上得到部分的最終輸出,大家拼接在一起就是完整輸出,不需要再做AllReduce。
Megatron在計算MLP時采用了這兩種并行方式,具體如下圖所示:
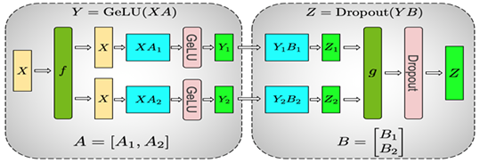
整個MLP的輸入X先通過f放到每一塊GPU上,然后先使用上面提到的按列切分權重矩陣A的方式,在每塊GPU上得到第一層全連接的部分輸出Y1和Y2,然后采用按行切分權重矩陣B,按列切分Y的方式,其中前一層的輸出Y1和Y2剛好滿足Y的切分需求,因此可以直接和B的相應部分做相應的計算而不需要額外操作或通信。這樣得到了最終Z的部分、Z1和Z2,通過g做AllReduce得到最終的Z,再通過相應的激活層或Dropout。
這樣就完成了MLP層的Tensor并行,對于Masked Multi Self Attention層,如下圖所示:
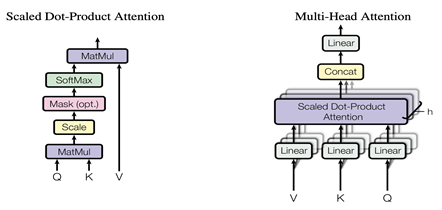
正如它的名字中提到的,它是由多個Self Attention組成的,因此很自然的并行方式就是可以把每個Self Attention分到不同的GPU上去進行計算,這樣每塊GPU上就能夠得到輸出的一部分,最后的Linear全連接層,由于每個GPU上已經有部分輸出,因此可以采用上面全連接層的按行的方向切權重矩陣B并按列的方向切輸入Y的方式直接進行計算,再通過AllReduce操作g得到最終結果。
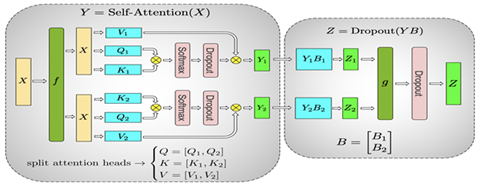
這樣我們就可以完成Transformer塊的Tensor并行。有了Tensor并行,我們可以把模型的每一層進行切分,分散到不同的GPU上,從而訓練比較大的模型。由于Tensor并行會對每一層進行切分,并且需要通信,因此Tensor并行在同一臺機器上,并且有NVLink的加速情況下性能最好。如果模型進一步增大,大到一臺機器可能都放不下整個模型,這時就需要引入另一種并行方式,Pipeline并行。
2. Pipeline 模型并行
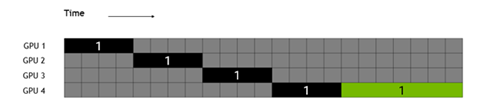
相對于Tensor并行的把模型的每一層內部進行切分,Pipeline并行是會在模型的層之間進行切分,不同的層在不同的GPU或機器節點上進行計算。由于不同的層間有依賴關系,所以如果直接并行會像下圖所示,黑色部分是前向,綠色部分是反向計算,灰色部分是空閑,可以看出GPU的絕大部分時間是在等待。
為了解決這個問題,Megatron把每一個batch分成了更小的microbatch,如下圖所示,把batch 1分成了1a,1b,1c,1d四個microbatch,由于不同的microbatch間沒有數據依賴,因此互相可以掩蓋各自的等待時間,提高GPU利用率,提升整體的性能。
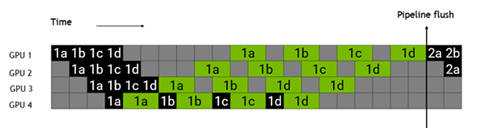
這就是Megatron 核心的兩種模型并行的設計,可以支撐超大的Transformer-based 語言模型,再結合經典的數據并行方式,可以讓大模型的訓練更快。
編輯:jq
-
數據
+關注
關注
8文章
7332瀏覽量
94573 -
NVIDIA
+關注
關注
14文章
5581瀏覽量
109566 -
gpu
+關注
關注
28文章
5177瀏覽量
135155 -
分布式
+關注
關注
1文章
1086瀏覽量
76551 -
MLP
+關注
關注
0文章
57瀏覽量
4975
原文標題:NVIDIA Megatron:超大Transformer語言模型的分布式訓練框架 (一)
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
七大大模型賦能的無人集群分布式協同調度與任務分配系統
大模型ai賦能的無人集群分布式協同調度與任務分配系統
SC-3568HA:解鎖鴻蒙全權限API與分布式能力的工業控制平臺

【節能學院】Acrel-1000DP分布式光伏監控系統在奉賢平高食品 4.4MW 分布式光伏中應用

分布式光伏發電監測系統技術方案

一鍵部署無損網絡:EasyRoCE助力分布式存儲效能革命

雙電機分布式驅動汽車高速穩定性機電耦合控制
潤和軟件StackRUNS異構分布式推理框架的應用案例

潤和軟件發布StackRUNS異構分布式推理框架

算力網絡的“神經突觸”:AI互聯技術如何重構分布式訓練范式

分布式光纖傳感的用途
AI原生架構升級:RAKsmart服務器在超大規模模型訓練中的算力突破
淺談工商企業用電管理的分布式儲能設計
小白學大模型:訓練大語言模型的深度指南




 工商網監
工商網監
評論