 微軟在ICML 2019上提出了一個全新的通用預訓練方法MASS
微軟在ICML 2019上提出了一個全新的通用預訓練方法MASS

微軟亞洲研究院的研究員在 ICML 2019 上提出了一個全新的通用預訓練方法 MASS,在序列到序列的自然語言生成任務中全面超越 BERT 和 GPT。本文帶來論文作者的技術解讀。
從 2018 年開始,預訓練(pre-train) 毫無疑問成為 NLP 領域最熱的研究方向。
借助于 BERT 和 GPT 等預訓練模型,人類在多個自然語言理解任務中取得了重大突破。然而,在序列到序列的自然語言生成任務中,目前主流預訓練模型并沒有取得顯著效果。
為此,微軟亞洲研究院的研究員在 ICML 2019 上提出了一個全新的通用預訓練方法 MASS,在序列到序列的自然語言生成任務中全面超越 BERT 和 GPT。在微軟參加的 WMT19 機器翻譯比賽中,MASS 幫助中 - 英、英 - 立陶宛兩個語言對取得了第一名的成績。
BERT 在自然語言理解(比如情感分類、自然語言推理、命名實體識別、SQuAD 閱讀理解等)任務中取得了很好的結果,受到了越來越多的關注。然而,在自然語言處理領域,除了自然語言理解任務,還有很多序列到序列的自然語言生成任務,比如機器翻譯、文本摘要生成、對話生成、問答、文本風格轉換等。在這類任務中,目前主流的方法是編碼器 - 注意力 - 解碼器框架,如下圖所示。

編碼器 - 注意力 - 解碼器框架
編碼器(Encoder)將源序列文本 X 編碼成隱藏向量序列,然后解碼器(Decoder)通過注意力機制(Attention)抽取編碼的隱藏向量序列信息,自回歸地生成目標序列文本 Y。
BERT 通常只訓練一個編碼器用于自然語言理解,而 GPT 的語言模型通常是訓練一個解碼器。如果要將 BERT 或者 GPT 用于序列到序列的自然語言生成任務,通常只有分開預訓練編碼器和解碼器,因此編碼器 - 注意力 - 解碼器結構沒有被聯合訓練,記憶力機制也不會被預訓練,而解碼器對編碼器的注意力機制在這類任務中非常重要,因此 BERT 和 GPT 在這類任務中只能達到次優效果。
新的預訓練方法 ——MASS
專門針對序列到序列的自然語言生成任務,微軟亞洲研究院提出了新的預訓練方法:屏蔽序列到序列預訓練(MASS: Masked Sequence to Sequence Pre-training)。MASS 對句子隨機屏蔽一個長度為 k 的連續片段,然后通過編碼器 - 注意力 - 解碼器模型預測生成該片段。

屏蔽序列到序列預訓練 MASS 模型框架
如上圖所示,編碼器端的第 3-6 個詞被屏蔽掉,然后解碼器端只預測這幾個連續的詞,而屏蔽掉其它詞,圖中 “_” 代表被屏蔽的詞。
MASS 預訓練有以下幾大優勢:
(1)解碼器端其它詞(在編碼器端未被屏蔽掉的詞)都被屏蔽掉,以鼓勵解碼器從編碼器端提取信息來幫助連續片段的預測,這樣能促進編碼器 - 注意力 - 解碼器結構的聯合訓練;
(2)為了給解碼器提供更有用的信息,編碼器被強制去抽取未被屏蔽掉詞的語義,以提升編碼器理解源序列文本的能力;
(3)讓解碼器預測連續的序列片段,以提升解碼器的語言建模能力。
統一的預訓練框架
MASS 有一個重要的超參數 k(屏蔽的連續片段長度),通過調整 k 的大小,MASS 能包含 BERT 中的屏蔽語言模型訓練方法以及 GPT 中標準的語言模型預訓練方法,使 MASS 成為一個通用的預訓練框架。
當 k=1 時,根據 MASS 的設定,編碼器端屏蔽一個單詞,解碼器端預測一個單詞,如下圖所示。解碼器端沒有任何輸入信息,這時 MASS 和 BERT 中的屏蔽語言模型的預訓練方法等價。

當 k=m(m 為序列長度)時,根據 MASS 的設定,編碼器屏蔽所有的單詞,解碼器預測所有單詞,如下圖所示,由于編碼器端所有詞都被屏蔽掉,解碼器的注意力機制相當于沒有獲取到信息,在這種情況下 MASS 等價于 GPT 中的標準語言模型。

MASS 在不同 K 下的概率形式如下表所示,其中 m 為序列長度,u 和 v 為屏蔽序列的開始和結束位置,x^u:v 表示從位置 u 到 v 的序列片段,x^\u:v 表示該序列從位置 u 到 v 被屏蔽掉。可以看到,當K=1 或者 m 時,MASS 的概率形式分別和 BERT 中的屏蔽語言模型以及 GPT 中的標準語言模型一致。

我們通過實驗分析了屏蔽 MASS 模型中不同的片段長度(k)進行預訓練的效果,如下圖所示。
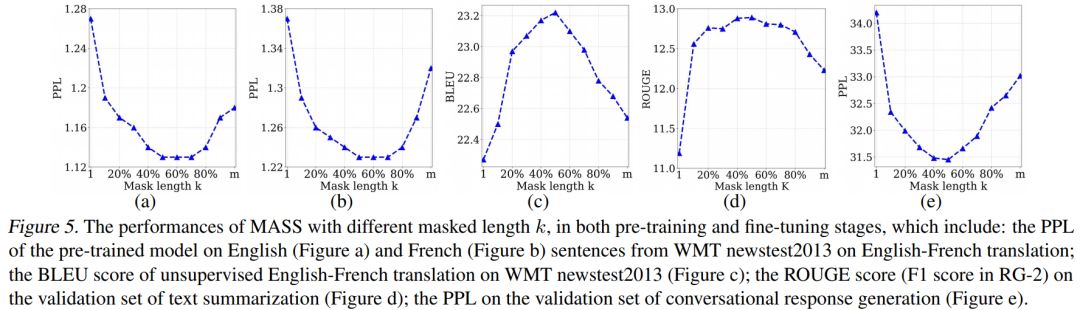
當 k 取大約句子長度一半時(50% m),下游任務能達到最優性能。屏蔽句子中一半的詞可以很好地平衡編碼器和解碼器的預訓練,過度偏向編碼器(k=1,即 BERT)或者過度偏向解碼器(k=m,即 LM/GPT)都不能在該任務中取得最優的效果,由此可以看出 MASS 在序列到序列的自然語言生成任務中的優勢。
序列到序列自然語言生成任務實驗
預訓練流程
MASS 只需要無監督的單語數據(比如 WMT News Crawl Data、Wikipedia Data 等)進行預訓練。MASS 支持跨語言的序列到序列生成(比如機器翻譯),也支持單語言的序列到序列生成(比如文本摘要生成、對話生成)。當預訓練 MASS 支持跨語言任務時(比如英語 - 法語機器翻譯),我們在一個模型里同時進行英語到英語以及法語到法語的預訓練。需要單獨給每個語言加上相應的語言嵌入向量,用來區分不同的語言。我們選取了無監督機器翻譯、低資源機器翻譯、文本摘要生成以及對話生成四個任務,將 MASS 預訓練模型針對各個任務進行精調,以驗證 MASS 的效果。
無監督機器翻譯
在無監督翻譯任務上,我們和當前最強的 Facebook XLM 作比較(XLM 用 BERT 中的屏蔽預訓練模型,以及標準語言模型來分別預訓練編碼器和解碼器),對比結果如下表所示。
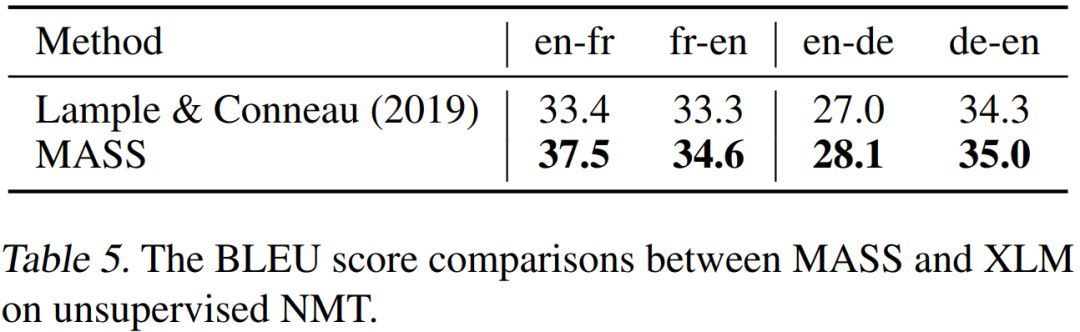
可以看到,MASS 的預訓練方法在 WMT14 英語 - 法語、WMT16 英語 - 德語一共 4 個翻譯方向上的表現都優于 XLM。MASS 在英語 - 法語無監督翻譯上的效果已經遠超早期有監督的編碼器 - 注意力 - 解碼器模型,同時極大縮小了和當前最好的有監督模型之間的差距。
低資源機器翻譯
低資源機器翻譯指的是監督數據有限情況下的機器翻譯。我們在 WMT14 英語 - 法語、WMT16 英語 - 德語上的不同低資源場景上(分別只有 10K、100K、1M 的監督數據)驗證我們方法的有效性,結果如下所示。
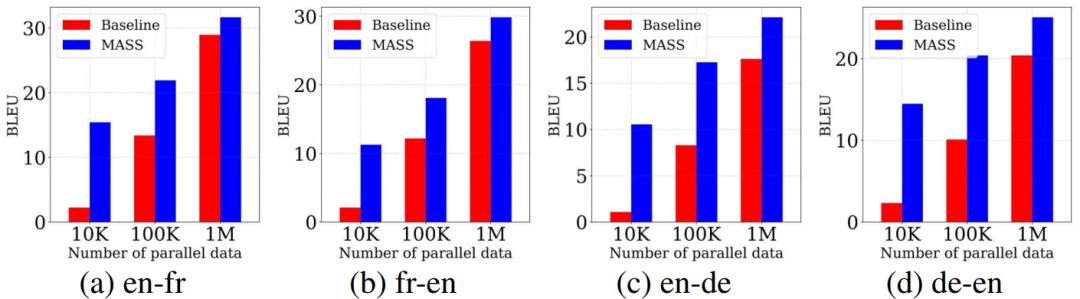
在不同的數據規模下,我們的預訓練方法的表現均比不用預訓練的基線模型有不同程度的提升,監督數據越少,提升效果越顯著。
文本摘要生成
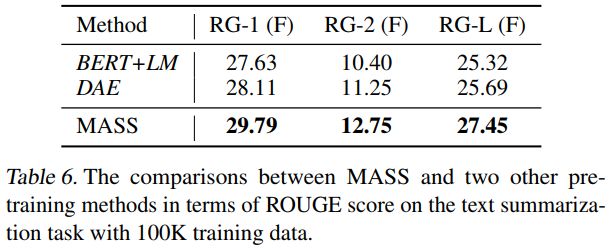
在文本摘要生成(Gigaword Corpus)任務上,我們將 MASS 同 BERT+LM(編碼器用 BERT 預訓練,解碼器用標準語言模型 LM 預訓練)以及 DAE(去噪自編碼器)進行了比較。從下表可以看到,MASS 的效果明顯優于 BERT+LM 以及 DAE。
對話生成
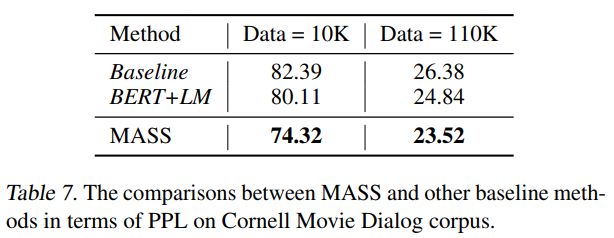
在對話生成(Cornell Movie Dialog Corpus)任務上,我們將 MASS 同 BERT+LM 進行了比較,結果如下表所示。MASS 的 PPL 低于 BERT+LM。
在不同的序列到序列自然語言生成任務中,MASS 均取得了非常不錯的效果。接下來,我們還將測試 MASS 在自然語言理解任務上的性能,并為該模型增加支持監督數據預訓練的功能,以期望在更多自然語言任務中取得提升。未來,我們還希望將 MASS 的應用領域擴展到包含語音、視頻等其它序列到序列的生成任務中。
-
微軟
+關注
關注
4文章
6741瀏覽量
107857 -
編碼器
+關注
關注
45文章
3953瀏覽量
142635 -
自然語言
+關注
關注
1文章
292瀏覽量
13988
原文標題:【ICML 2019】微軟最新通用預訓練模型MASS,超越BERT、GPT!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
無法啟動預安裝的 Ubuntu 23.10 服務器映像怎么解決?
在deepin 25上安裝OpenClaw的步驟及飛書接入方法

是否可以將 Vision Five 2 配置為 SuperSpeed 上的 USB 3.0 mass_storage小工具?
微軟全新AI超級工廠Fairwater在亞特蘭大落成
喜報|華微軟件AI研發持續推進,再添一項核心專利

在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
微軟Visual Studio 2026 發布!AI 深度融合、性能提升

基于大規模人類操作數據預訓練的VLA模型H-RDT

【Sipeed MaixCAM Pro開發板試用體驗】 + 04 + 機器學習YOLO體驗
【「DeepSeek 核心技術揭秘」閱讀體驗】書籍介紹+第一章讀后心得
樹莓派5上的Gemma 2:如何打造高效的邊緣AI解決方案?

【書籍評測活動NO.62】一本書讀懂 DeepSeek 全家桶核心技術:DeepSeek 核心技術揭秘
基于RK3576開發板的yolov11-track多目標跟蹤部署教程

請問如何在imx8mplus上部署和運行YOLOv5訓練的模型?
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集




 工商網監
工商網監
評論