 電子發(fā)燒友App
電子發(fā)燒友App



摘要:?摘要傳統(tǒng)的數(shù)據(jù)分析經(jīng)常使用的工具是Hadoop或Spark在使用之前環(huán)境是需要用戶自己去搭建的。隨著業(yè)務(wù)逐漸向云遷移如何在云上進(jìn)行大數(shù)據(jù)分析是需要解決的問題。為此阿里云提供了一項(xiàng)很重要的服務(wù)——大數(shù)據(jù)計(jì)算服務(wù)MaxCompute。
摘要:傳統(tǒng)的數(shù)據(jù)分析,經(jīng)常使用的工具是Hadoop或Spark,在使用之前環(huán)境是需要用戶自己去搭建的。隨著業(yè)務(wù)逐漸向云遷移,如何在云上進(jìn)行大數(shù)據(jù)分析是需要解決的問題。為此,阿里云提供了一項(xiàng)很重要的服務(wù)——大數(shù)據(jù)計(jì)算服務(wù)MaxCompute。本視頻中,上海駐云科技的專家將帶領(lǐng)大家了解如何使用阿里云的大數(shù)據(jù)計(jì)算服務(wù)MaxCompute來進(jìn)行數(shù)據(jù)分析的。
演講嘉賓簡(jiǎn)介:
翟永東,來自上海駐云科技。上海駐云科技是阿里云的合作伙伴之一,其宗旨是幫助客戶將自己的業(yè)務(wù)系統(tǒng)遷移到云上,公司在云上會(huì)使用阿里云的一些大數(shù)據(jù)產(chǎn)品幫助用戶做數(shù)據(jù)分析。
以下內(nèi)容根據(jù)演講嘉賓視頻分享以及PPT整理而成。
關(guān)于MaxCompute更多精彩文章,請(qǐng)移步云棲社區(qū)MaxCompute公眾號(hào)!
本次的分享主要分為三部分:
一、企業(yè)云上搭建的數(shù)據(jù)分析平臺(tái):該部分主要介紹阿里云搭建的數(shù)據(jù)分析平臺(tái)整體架構(gòu)和分析流程。
二、大數(shù)據(jù)計(jì)算服務(wù)MaxCompute:該部分主要介紹了大數(shù)據(jù)計(jì)算服務(wù)MaxCompute的具體情況,包括特點(diǎn)、使用場(chǎng)景、功能組成以及使用過程中的注意事項(xiàng),同時(shí)介紹了駐云科技使用MaxCompute完成的客戶案例。
一、企業(yè)云上搭建的數(shù)據(jù)分析平臺(tái)
在了解MaxCompute之前,我們先來了解一下目前阿里云上搭建的數(shù)據(jù)分析平臺(tái)整體架構(gòu)(如下圖)。最左側(cè)是數(shù)據(jù)源,在幫用戶做數(shù)據(jù)分析的時(shí)候,首先需要明確數(shù)據(jù)源是在什么地方,比如線下的數(shù)據(jù)庫(kù)如MySQL、SQLserver或Oracle,還有一些是在自己業(yè)務(wù)系統(tǒng)里面,比如服務(wù)器的日志等,目前有的用戶也將數(shù)據(jù)存放在NoSQL的數(shù)據(jù)庫(kù)中,總之?dāng)?shù)據(jù)源多種多樣,數(shù)據(jù)源的位置是首先需要明確的;然后需要把數(shù)據(jù)抽取到云端,用于在云上進(jìn)行數(shù)據(jù)分析,不管用戶是否使用云服務(wù),都可以使用數(shù)據(jù)集成技術(shù)將離線或?qū)崟r(shí)數(shù)據(jù)抽取到阿里云與數(shù)據(jù)處理相關(guān)的服務(wù)中,對(duì)于離線數(shù)據(jù)使用的是數(shù)據(jù)集成CDP,對(duì)于流式計(jì)算產(chǎn)生的實(shí)時(shí)數(shù)據(jù)使用的是DataHub;所抽取的數(shù)據(jù)會(huì)用到三個(gè)與數(shù)據(jù)處理相關(guān)的服務(wù),一個(gè)是MaxCompute用來做離線計(jì)算,一個(gè)是分析型數(shù)據(jù)庫(kù)做在線數(shù)據(jù)分析,類似于OLAP場(chǎng)景,最后一個(gè)是流式計(jì)算于正常流式計(jì)算服務(wù);這三個(gè)服務(wù)處理過的數(shù)據(jù)可以通過SQL、MapReduce、Graph或機(jī)器學(xué)習(xí)的方式進(jìn)行分析;經(jīng)過分析的數(shù)據(jù)結(jié)果最終可以通過阿里云的數(shù)據(jù)應(yīng)用進(jìn)行展示,大數(shù)據(jù)領(lǐng)域中的一個(gè)子領(lǐng)域是數(shù)據(jù)可視化,關(guān)注如何將數(shù)據(jù)分析結(jié)果進(jìn)行展示,阿里云針對(duì)這點(diǎn)提供了很多數(shù)據(jù)應(yīng)用,主要的應(yīng)用又兩個(gè),一個(gè)是QuickBI,將結(jié)果通過報(bào)表的形式進(jìn)行展示,另外一個(gè)是DataV,通過大圖形式進(jìn)行展示。以上是在云端比較完整的數(shù)據(jù)處理分析流程,在以上過程中,阿里云會(huì)提供一個(gè)可視化的平臺(tái),讓用戶以可見的方式進(jìn)行數(shù)據(jù)處理與分析,不像傳統(tǒng)的數(shù)據(jù)處理需要通過命令行,缺乏交互性,上手難度高。
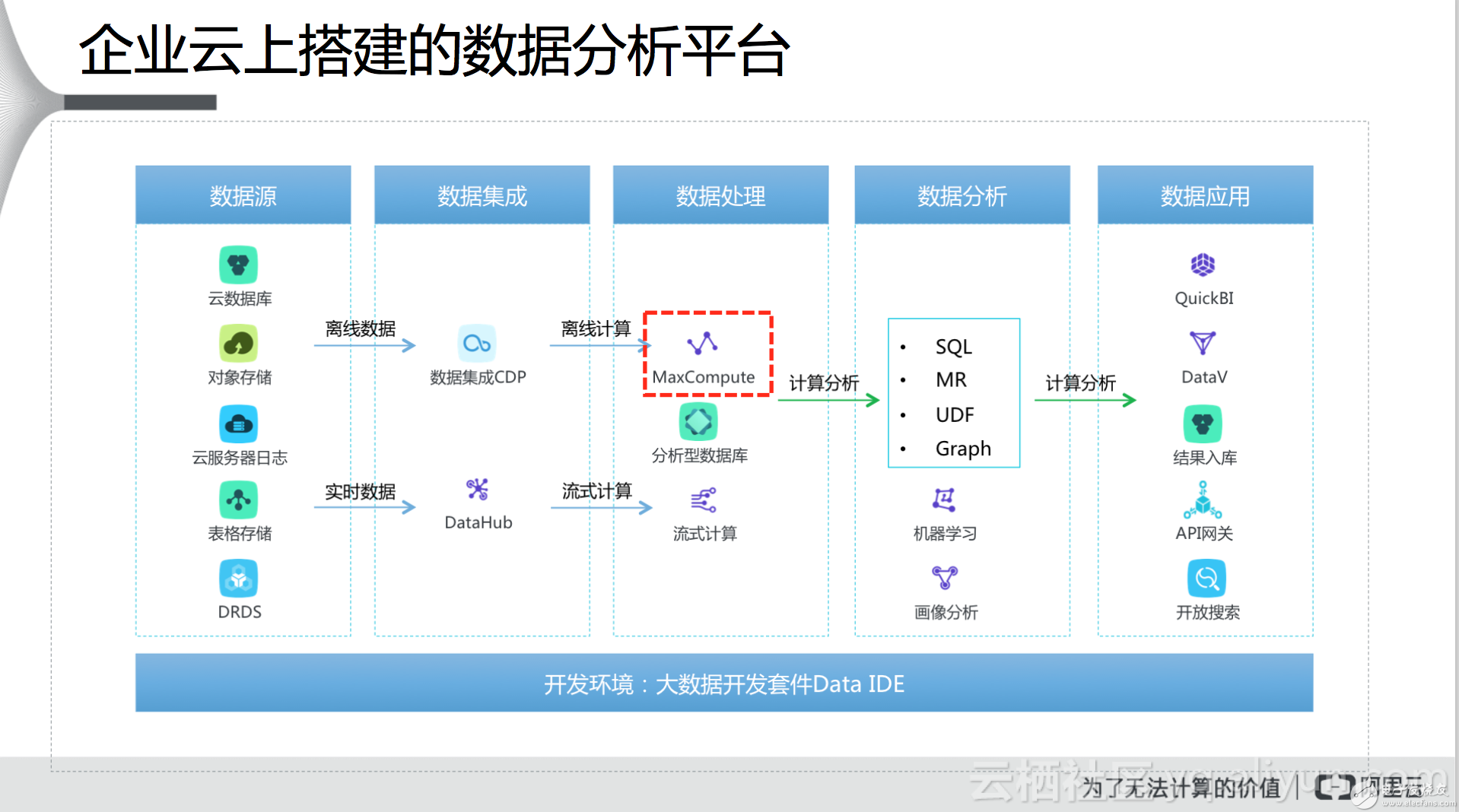
上述過程中,用的比較多的是MaxCompute服務(wù),這也是我們今天介紹的重點(diǎn)——如何使用MaxCompute進(jìn)行數(shù)據(jù)分析。
二、大數(shù)據(jù)計(jì)算服務(wù)MaxCompute
介紹
MaxCompute原來叫做ODPS,它是阿里云自主研發(fā)的支持離線數(shù)據(jù)分析的服務(wù),離線計(jì)算說明數(shù)據(jù)處理的實(shí)時(shí)性要求沒有那么高,目前的處理能力可以達(dá)到TB/PB級(jí)別,阿里云曾經(jīng)用了六個(gè)小時(shí)對(duì)100個(gè)PB的數(shù)據(jù)完成了處理。目前MaxCompute被廣泛應(yīng)用于數(shù)據(jù)分析、挖掘、商業(yè)智能等領(lǐng)域,另外,阿里巴巴的數(shù)據(jù)業(yè)務(wù)都運(yùn)行在MaxCompute之上。
特點(diǎn)海量運(yùn)算觸手可得。MaxCompute可以理解為阿里云已經(jīng)為用戶搭建好了數(shù)據(jù)處理的平臺(tái),平臺(tái)背后有上萬臺(tái)的服務(wù)器集群支持,可以根據(jù)數(shù)據(jù)規(guī)模自動(dòng)調(diào)整集群存儲(chǔ)和計(jì)算能力,最大化發(fā)揮數(shù)據(jù)的價(jià)值。對(duì)于用戶來講,只需要將自己的數(shù)據(jù)上傳,就可以對(duì)數(shù)據(jù)進(jìn)行處理和分析,而不需要自己搭建數(shù)據(jù)處理環(huán)境。
服務(wù)“開箱即用”。MaxCompute服務(wù)的使用不需要任何的復(fù)雜配置,只需要簡(jiǎn)單的幾步操作,就可以上傳數(shù)據(jù),分析數(shù)據(jù)并得到分析結(jié)果。之前有一個(gè)企業(yè)客戶是做手機(jī)軟件數(shù)據(jù)收集的,收集的是手機(jī)用戶app使用相關(guān)的行為數(shù)據(jù),通過這些數(shù)據(jù)分析手機(jī)用戶的應(yīng)用偏好,然后將結(jié)果賣給第三方的公司,比如廣告或app的應(yīng)用廠商。這家企業(yè)起初選擇的是Hadoop來進(jìn)行數(shù)據(jù)分析,因?yàn)镠adoop的存在時(shí)間比較久了,發(fā)展較為成熟,同時(shí)也是開源的,但是企業(yè)缺少使用Hadoop進(jìn)行大數(shù)據(jù)分析的技術(shù)人員,現(xiàn)有的開發(fā)人員和技術(shù)人員只能自己去學(xué)習(xí)如何搭建Hadoop環(huán)境,如何使用Hadoop去做數(shù)據(jù)分析,整個(gè)Hadoop的研究學(xué)習(xí)差不多耗費(fèi)了半年時(shí)間,僅僅使用了兩臺(tái)服務(wù)器,可以想象如果服務(wù)器變多,復(fù)雜度又會(huì)大大提升。最終,由于業(yè)務(wù)上沒有因?yàn)镠adoop的研究使用出現(xiàn)什么進(jìn)展。該企業(yè)轉(zhuǎn)向了MaxCompute服務(wù),底層的集群如何搭建他們不需要關(guān)心,只需要將數(shù)據(jù)上傳、然后按照業(yè)務(wù)需求進(jìn)行分析即可。
數(shù)據(jù)存儲(chǔ)安全可靠。使用MaxCompute的安全性可以得到保障,實(shí)現(xiàn)的技術(shù)是三重備份防止數(shù)據(jù)丟失,另外還有一些讀寫鑒權(quán)、應(yīng)用沙箱、系統(tǒng)沙箱等多層次安全機(jī)制來保證數(shù)據(jù)之間訪問的時(shí)候不會(huì)出現(xiàn)不安全的因素。
多用戶協(xié)作。MaxCompute是在云上提供服務(wù)的,只要是阿里云的用戶,都可以在云上使用它來進(jìn)行數(shù)據(jù)分析,支持多用戶協(xié)作。傳統(tǒng)數(shù)據(jù)分析中會(huì)出現(xiàn)“數(shù)據(jù)孤島”,即企業(yè)中不同業(yè)務(wù)部門都有自己的數(shù)據(jù),數(shù)據(jù)之間互相不透明,從而導(dǎo)致信息孤島。而使用MaxCompute可以將整個(gè)企業(yè)中所有業(yè)務(wù)部門的數(shù)據(jù)打通,減少數(shù)據(jù)孤島,在保障數(shù)據(jù)安全的前提下最大化工作效率。
按量付費(fèi)。這一點(diǎn)其實(shí)的是和云服務(wù)是類似的,根據(jù)用戶的實(shí)際使用方式和需求進(jìn)行收費(fèi),這樣可以避免像傳統(tǒng)的數(shù)據(jù)分析集群空閑而導(dǎo)致的資源浪費(fèi),最大化降低數(shù)據(jù)的使用成本。另外,MaxCompute目前支持包年包月的計(jì)費(fèi)形式,因?yàn)橛行┯脩暨M(jìn)行數(shù)據(jù)分析的次數(shù)比較頻繁,比如每天業(yè)務(wù)結(jié)束之后都會(huì)進(jìn)行結(jié)算處理,這種情況下使用按量付費(fèi)可能不那么劃算,而更適合使用包年包月的形式。
MaxCompute的使用場(chǎng)景
基于SQL構(gòu)建大規(guī)模數(shù)據(jù)倉(cāng)庫(kù)系統(tǒng)和BI系統(tǒng)
傳統(tǒng)情況下,可以通過第三方的服務(wù)和開源的技術(shù)搭建企業(yè)數(shù)據(jù)倉(cāng)庫(kù)系統(tǒng),現(xiàn)在可以基于MaxCompute在云上方便地搭建。
基于DAG/Graph構(gòu)建大型分布式系統(tǒng)
DAG是Spark中的有向無環(huán)圖,MaxCompute也是支持這種類似于Spark的計(jì)算方式的;另外MaxCompute也支持Graph的計(jì)算方式,比如在社交領(lǐng)域中(游戲)所做的社交分析。在所構(gòu)建的大型分布式系統(tǒng)中,可以通過SDK的方式來調(diào)用底層的MapReduce來進(jìn)行數(shù)據(jù)分析處理。
基于統(tǒng)計(jì)和機(jī)器學(xué)習(xí)的大數(shù)據(jù)統(tǒng)計(jì)和數(shù)據(jù)挖掘
并不是說MaxCompute本身支持機(jī)器學(xué)習(xí),而是可以和機(jī)器學(xué)習(xí)來結(jié)合使用。因?yàn)槟玫綌?shù)據(jù)后,在數(shù)據(jù)處理之前會(huì)對(duì)數(shù)據(jù)進(jìn)行清洗和預(yù)處理,處理完之后可以將這些數(shù)據(jù)交給機(jī)器學(xué)習(xí)平臺(tái),在機(jī)器學(xué)習(xí)平臺(tái)中做一些深入的機(jī)器學(xué)習(xí)處理算法,比如可以將MaxCompute的結(jié)果作為訓(xùn)練的數(shù)據(jù)給機(jī)器學(xué)習(xí)平臺(tái)進(jìn)行訓(xùn)練并建立模型。MaxCompute中提供專門的接口來對(duì)接機(jī)器學(xué)習(xí)平臺(tái)
MaxCompute的功能組成
MaxCompute的主要功能包括以下四個(gè):
數(shù)據(jù)上傳下載。數(shù)據(jù)原本是存放在自己的數(shù)據(jù)源中,想要使用MaxCompute進(jìn)行數(shù)據(jù)分析,需要將數(shù)據(jù)上傳到MaxCompute中,如果數(shù)據(jù)不在MaxCompute中,是沒有辦法做數(shù)據(jù)分析的,上傳之后處理計(jì)算的結(jié)果還可以進(jìn)行下載。數(shù)據(jù)的上傳下載主要用到的是Tunnel?的模塊,可使用的方式有兩種,一種是Tunnel SDK,另一種是tunnel命令行工具。此外還可以借助第三方的集成插件來做數(shù)據(jù)的上傳和下載,比如阿里云專門的數(shù)據(jù)集成方式以及阿里云開源服務(wù)DataX。
SQL便捷開發(fā)。數(shù)據(jù)的上傳后就可以進(jìn)行分析,首先可以使用SQL,MaxCompute支持SQL的使用來輔助計(jì)算,這個(gè)SQL和常用的SQL是類似的(百分之九十以上兼容)。大家如果熟悉Hive(Hadoop開源生態(tài)的一員,通過SQL語句做數(shù)據(jù)分析)的話會(huì)發(fā)現(xiàn),MaxCompute支持的SQL和Hive的風(fēng)格類似。因?yàn)镠ive是開源的,有很多人用過,阿里云在推出MaxCompute的時(shí)候,如果使用全新的SQL風(fēng)格,用戶的學(xué)習(xí)成本會(huì)增加,而使用和其他工具類似的風(fēng)格,用戶學(xué)習(xí)起來也比較容易。
自定義函數(shù)。在使用SQL進(jìn)行計(jì)算的時(shí)候,有些沒有辦法通過內(nèi)置的函數(shù)來解決,這時(shí)候就可以使用MaxCompute支持的自定義函數(shù)功能來解決。目前所支持的自定義函數(shù)包括自定義標(biāo)量函數(shù)、自定義表值函數(shù)和自定義聚組函數(shù)。
分布式編程模型。如果有些場(chǎng)景比較復(fù)雜,通過SQL沒辦法解決,可以使用MaxCompute支持的分布式編程模型,用戶可以自己編寫應(yīng)用邏輯來做數(shù)據(jù)分析。其中,所支持的分布式編程模型有兩種,一種是MapReduce,用戶可以自己寫mapper和reducer來進(jìn)行數(shù)據(jù)分析;另外一種是Graph,通過圖計(jì)算的方式來對(duì)數(shù)據(jù)進(jìn)行分析。
?
上述的功能究竟該選擇哪個(gè)呢?我們通過下圖來幫助大家進(jìn)行功能的選擇。首先,在使用的時(shí)候用戶需要明確數(shù)據(jù)是否已經(jīng)上傳到MaxCompute,如果沒有,可以通過Tunnel或第三方的一些工具上傳數(shù)據(jù);數(shù)據(jù)上傳之后看是否可以使用簡(jiǎn)單的SQL語句來處理,如果可以使用,則建議首先使用SQL來做處理;如果通過簡(jiǎn)函數(shù)功能不足,無法使用SQL來進(jìn)行處理,這個(gè)時(shí)候可以考慮是否可以使用自定義函數(shù)(UDF)來進(jìn)行處理。如果可以,則需要編寫自定義函數(shù),使用SQL調(diào)用UDF來處理數(shù)據(jù);否則,考慮使用MR或Graph的方式來對(duì)數(shù)據(jù)進(jìn)行處理。之所以這樣建議功能選擇,是基于由簡(jiǎn)到難的考慮,使用SQL是最簡(jiǎn)單的,UDF自定義函數(shù)難度提高,但本質(zhì)還是基于SQL,基于MR或Graph的方式涉及到使用Java做應(yīng)用開發(fā),需要對(duì)框架熟悉,才能對(duì)數(shù)據(jù)做相應(yīng)的處理和分析,難度最大。
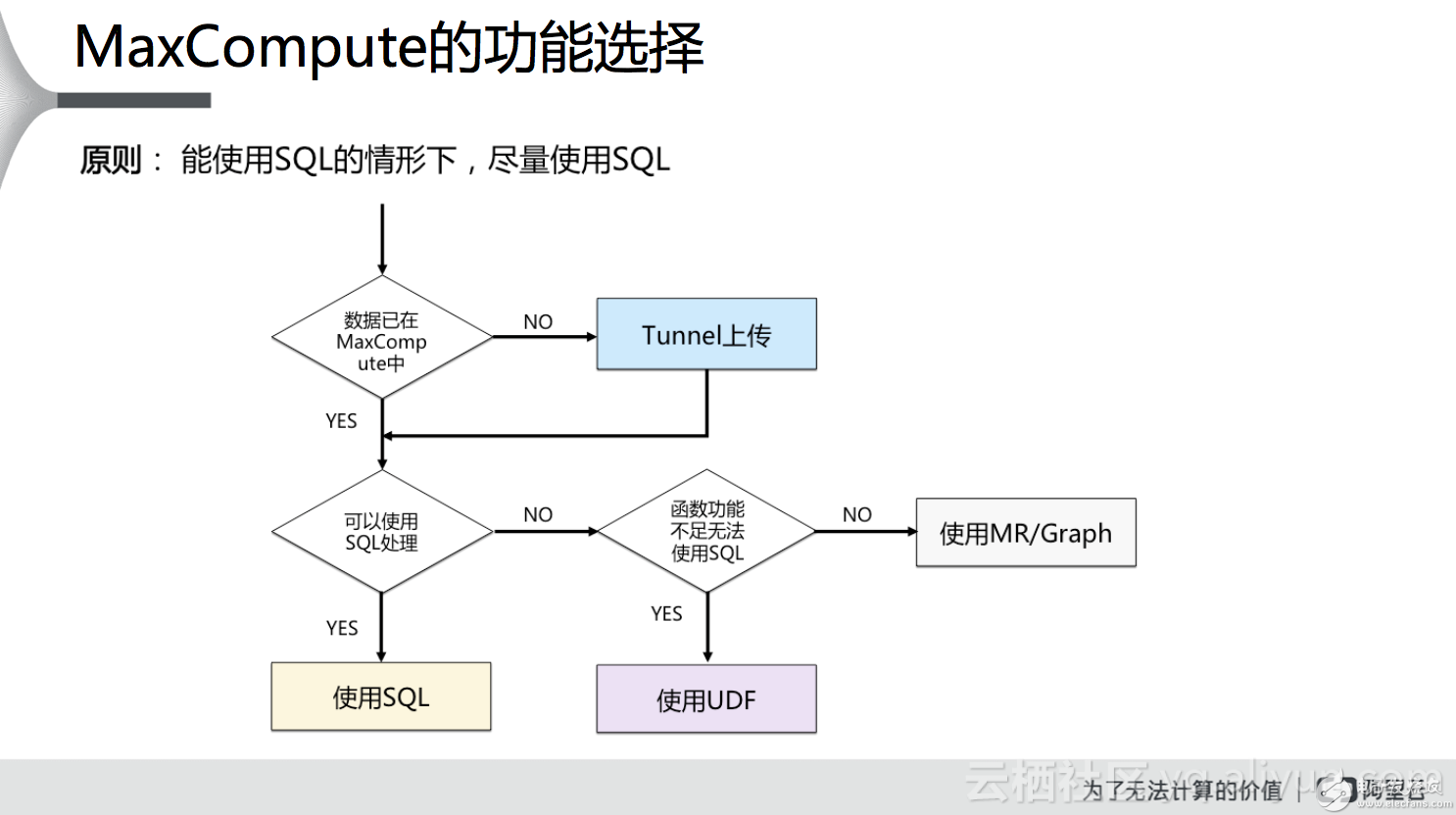
接下來的介紹一下云端進(jìn)行數(shù)據(jù)分析的過程中,需要用戶參與的工作主要有兩個(gè),一個(gè)是自定義函數(shù)UDF的開發(fā),另一個(gè)是編寫MapReduce。
自定義函數(shù)UDF的開發(fā)。第一步首先用戶需要在本地將開發(fā)UDF的環(huán)境安裝配置好,阿里云的UDF開發(fā)語言以Java為主,其他語音如Python也在逐步支持。如果用Java進(jìn)行開發(fā),那相應(yīng)的開發(fā)環(huán)境如Eclipse等需要安裝,開發(fā)完成后可以使用本地模式進(jìn)行測(cè)試。第二步是將開發(fā)并測(cè)試通過的UDF導(dǎo)出生成Jar包。第三步是使用odpscmd命令將本地生成的Jar包上傳到MaxCompute,將其作為資源來使用。第四步是在MaxCompute中,基于上傳的Jar包資源生成自定義函數(shù)。最后一步是在MaxCompute中寫SQL語句并測(cè)試使用自定義函數(shù)。
MapReduce開發(fā)。MapReduce開發(fā)的核心是編寫mapper和reducer,和傳統(tǒng)的Hadoop中的MapReduce的編寫是類似的,只是MaxCompute做了很好的封裝,很多代碼都幫助用戶寫好了。MaxCompute中MapReduce的開發(fā)流程是:第一步安裝配置環(huán)境;第二步開發(fā)MapReduce程序;第三步在本地模式下測(cè)試腳本;第四步在開發(fā)測(cè)試完沒有問題后,導(dǎo)出Jar包供云端使用;第五步將Jar包上傳至MaxCompute項(xiàng)目空間;第六步在MaxCompute中使用MapReduce。其中本地測(cè)試有兩個(gè)好處,一個(gè)是不會(huì)對(duì)線上的環(huán)境產(chǎn)生影響,另一個(gè)是只需要編寫測(cè)試的數(shù)據(jù)就可以在本地進(jìn)行測(cè)試。
MaxCompute使用的注意事項(xiàng)
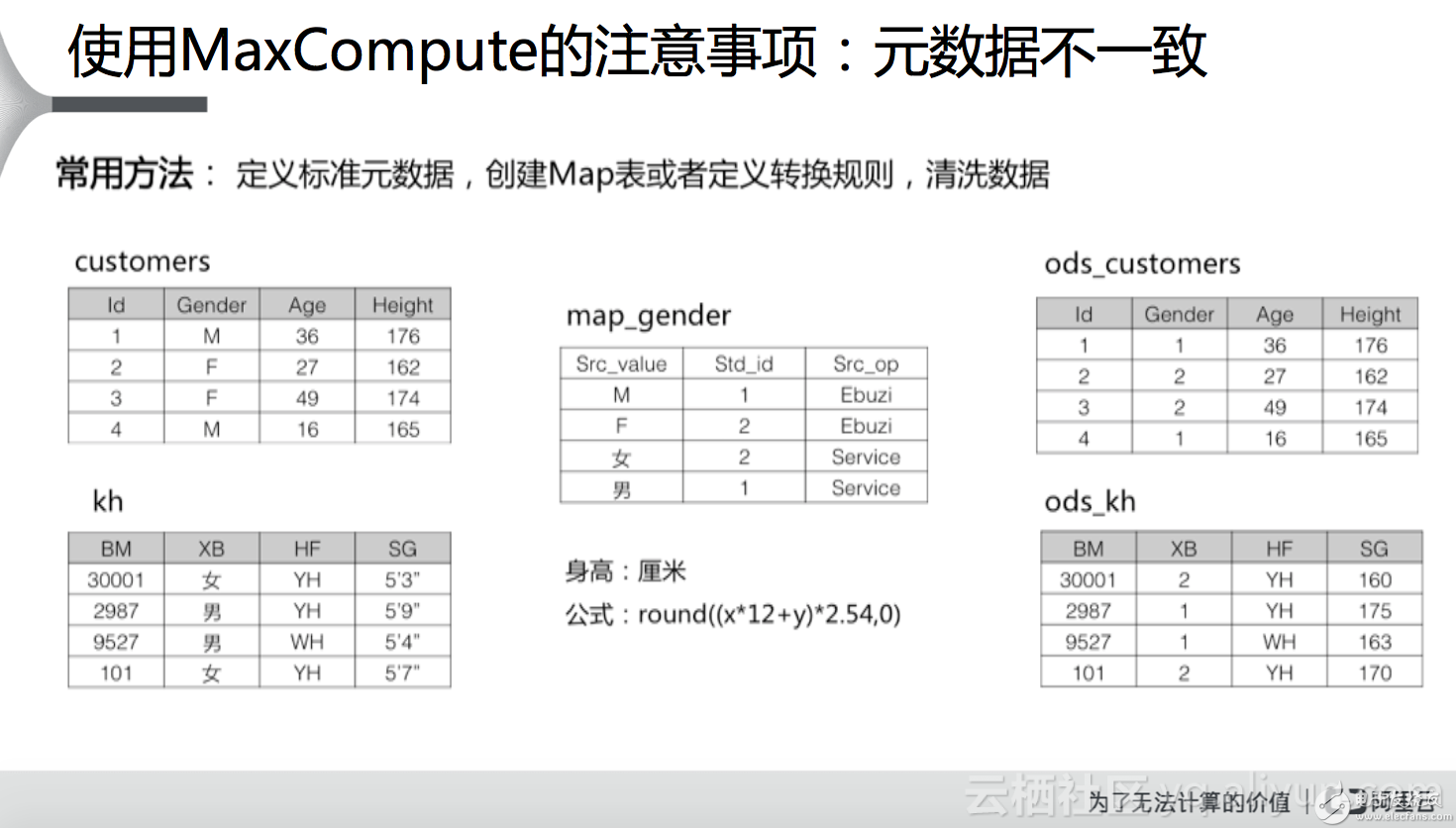
元數(shù)據(jù)不一致。大家在使用MaxCompute進(jìn)行數(shù)據(jù)處理的時(shí)候,經(jīng)常會(huì)面臨元數(shù)據(jù)不一致的情況。東方航空大數(shù)據(jù)開發(fā)人員曾經(jīng)說過一件很有意思的事情,那就是東航現(xiàn)在不知道自己有多少架飛機(jī),究其原因是因?yàn)閮?nèi)部的元數(shù)據(jù)沒有保持一致,或者說數(shù)據(jù)缺乏標(biāo)準(zhǔn)的定義。這種情況下常用的方法是定義標(biāo)準(zhǔn)的元數(shù)據(jù),創(chuàng)建Map表或者定義轉(zhuǎn)換規(guī)則,清洗數(shù)據(jù)。舉個(gè)簡(jiǎn)單的例子,比如現(xiàn)在有兩張表,customers表和kh表(如下圖),都與用戶信息相關(guān),customers表中性別(Gender)使用M代表男性,F代表女性,而在kh表中性別(XB)男性使用“男”表示,女性使用“女”表示;另外可以發(fā)現(xiàn),除了性別,這兩張表中對(duì)于身高的定義也是是不一致的,前者采用的是厘米為單位的身高計(jì)量方式,而后者采用的是尺寸的計(jì)量方式。這種情況下數(shù)據(jù)分析過程中如果兩個(gè)表需要做join,就沒有辦法做分析,所以說需要對(duì)元數(shù)據(jù)進(jìn)行統(tǒng)一。具體怎么做呢?比方說創(chuàng)建一張map_gender的表,對(duì)涉及到性別的元數(shù)據(jù)進(jìn)行統(tǒng)一,比如用1來表示男性,2來表示女性,再比如統(tǒng)一用厘米為單位來計(jì)量身高,對(duì)于尺寸為單位的計(jì)量,通過公式進(jìn)行轉(zhuǎn)換。這樣的好處是生成圖最右側(cè)的兩張表,表中的元數(shù)據(jù)便實(shí)現(xiàn)了統(tǒng)一,便于數(shù)據(jù)分析。
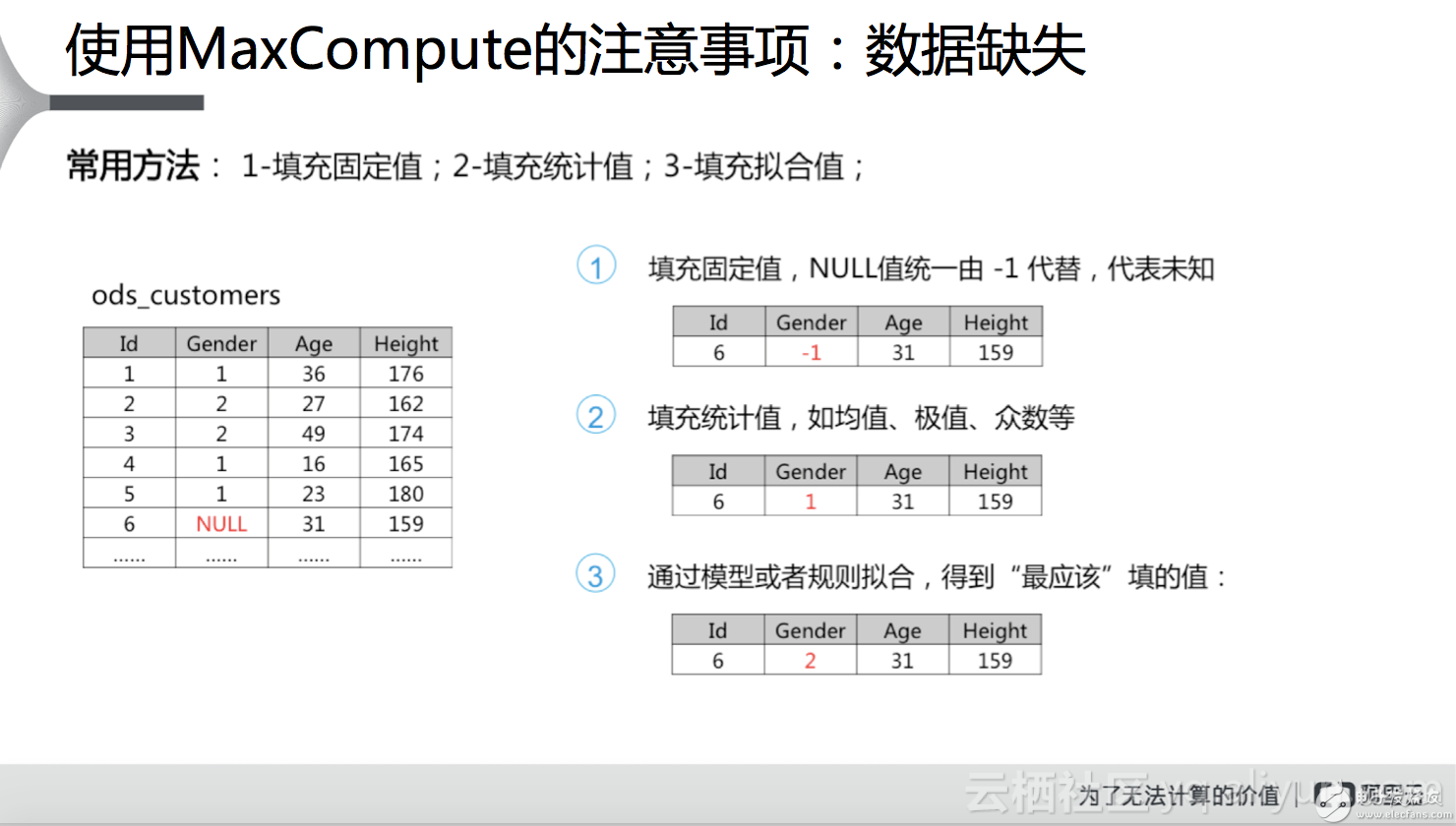
數(shù)據(jù)缺失。在做數(shù)據(jù)分析的時(shí)候,不能夠保證收集的數(shù)據(jù)一定是完全的,數(shù)據(jù)總歸會(huì)出現(xiàn)缺失的情況,在這種情況下,我們來看一下該怎么處理。如果數(shù)據(jù)缺失比較少的話,可以簡(jiǎn)單的扔掉不予考慮,比如有一億條數(shù)據(jù),有一萬行數(shù)據(jù)是缺失的,這一萬行數(shù)據(jù)的缺失對(duì)整個(gè)結(jié)果影響不大,這個(gè)時(shí)候就可以不考慮這一萬行數(shù)據(jù)的缺失;而如果這一億行數(shù)據(jù)缺失了六七千萬行,那算出的數(shù)據(jù)肯定是不可靠的,這個(gè)時(shí)候就不能簡(jiǎn)單的丟棄。常用的方法有三種,最簡(jiǎn)單的是填充固定值,比如下圖左邊的表中有一行性別是缺失的,可以置-1,代表這一行的性別值缺失或未知;第二種方式是填充統(tǒng)計(jì)值,如平均值、極值或眾數(shù)等;前兩種方法都存在一定的隨機(jī)性,可靠性不高,隨著機(jī)器學(xué)習(xí)算法的普及,經(jīng)常使用的第三種方式是擬合,通過模型或者規(guī)則進(jìn)行擬合,得到最應(yīng)該填的值,這個(gè)結(jié)果是相對(duì)來講更可靠的,更加接近于真實(shí)的值。還有一種情況是在數(shù)據(jù)收集的時(shí)候數(shù)據(jù)就缺失了,比如通過滴滴打車收集的數(shù)據(jù)來分析企業(yè)的加班情況,但是某些企業(yè)可能會(huì)有自己的班車或者其他的原因,這樣就導(dǎo)致有些數(shù)據(jù)本身就沒有收集到,這種情況的數(shù)據(jù)缺失對(duì)于結(jié)果的影響會(huì)更大。
數(shù)據(jù)倉(cāng)庫(kù)的搭建。在使用MaxCompute搭建數(shù)據(jù)倉(cāng)庫(kù)的時(shí)候,建議使用分層的方式,比如分成ODS、EDW和ADM三種不同的層次來進(jìn)行搭建,其中ODS實(shí)現(xiàn)準(zhǔn)時(shí)、跨領(lǐng)域的運(yùn)營(yíng)細(xì)節(jié)的查詢,已獲得細(xì)粒度的運(yùn)營(yíng)數(shù)據(jù)展現(xiàn);EDW層實(shí)現(xiàn)基于歷史數(shù)據(jù)的統(tǒng)計(jì)分析和數(shù)據(jù)挖掘,已獲得客戶深層次的特征和市場(chǎng)發(fā)展規(guī)律;ADM層在數(shù)據(jù)的基礎(chǔ)上進(jìn)行加工匯總形成的指標(biāo)數(shù)據(jù)存儲(chǔ)分析型和加工匯總型數(shù)據(jù)。這樣做的好處是結(jié)構(gòu)清晰,功能明確,任何變動(dòng)可以很快的完成修改。另外,分層搭建數(shù)倉(cāng)的時(shí)候,表的命名有一定的要求,比如ODS層中的表中含有ODS,直接告訴用戶這張表是在ODS層,或者明確表標(biāo)明表應(yīng)用的業(yè)務(wù)域。
應(yīng)用案例
最后向大家介紹駐云科技曾經(jīng)做過的一個(gè)客戶案例,是幫助某智慧商場(chǎng)搭建大數(shù)據(jù)架構(gòu),如下圖所示。商場(chǎng)的需求是了解每一層的商鋪銷量,如果商鋪的銷量很低,就把它關(guān)掉;另外還想要了解用戶的購(gòu)物習(xí)慣,為用戶做精準(zhǔn)推送。為了滿足商場(chǎng)需求,需要分析的數(shù)據(jù)來源有很多,除了線下數(shù)據(jù)庫(kù),還有一些文本數(shù)據(jù),駐云通過編寫shell腳本對(duì)文本數(shù)據(jù)進(jìn)行清洗,然后存放在阿里云的OSS中,OSS可以作為MaxCompute的外部表,不需要導(dǎo)入MaxCompute便可以進(jìn)行分析,雖然性能會(huì)有一定的損失,但相對(duì)于其所帶來的靈活性,損失是可以接受的。不同數(shù)據(jù)源的數(shù)據(jù)導(dǎo)入MaxCompute可以使用的方法有多種,除了阿里云提供的數(shù)據(jù)集成服務(wù),還可以采用第三方或者開源工具DataX,這種方式的好處是可以實(shí)現(xiàn)靈活定制。所有數(shù)據(jù)整合到MaxCompute中后便可以進(jìn)行分析,分析完后結(jié)果展示的方式有兩種,第一種是將MaxCompute的分析結(jié)果通過數(shù)據(jù)集成的方式導(dǎo)入到阿里云的RDS中,然后在Data-V中進(jìn)行展示。為什么需要導(dǎo)入到RDS中而不是直接導(dǎo)入Data-V呢?需要注意的是,MaxCompute實(shí)現(xiàn)的是離線計(jì)算,實(shí)時(shí)性要求是不高的,而Data-V是一個(gè)大屏,對(duì)數(shù)據(jù)的實(shí)時(shí)性要求很高,所以一般的過程是將結(jié)果先導(dǎo)入到數(shù)據(jù)庫(kù)中,然后從數(shù)據(jù)庫(kù)中再讀取相關(guān)數(shù)據(jù)在Data-V中做大圖展示。還有一種方式是不做大屏展示,而是做報(bào)表分析,這種情況下可以將MaxCompute的數(shù)據(jù)直接在Quick-BI中展示,也可以在阿里云的ADS數(shù)據(jù)庫(kù)進(jìn)行存儲(chǔ)和二次分析,分析完之后再在Quick-BI中展現(xiàn)。這兩種方式的展現(xiàn)形式有一定的重合性,比如二維的餅圖等,但是Data-V可以展現(xiàn)三維地圖等形式,通過大屏很直觀的展現(xiàn)。這兩種展現(xiàn)方式可以根據(jù)需求選擇。
本文為云棲社區(qū)原創(chuàng)內(nèi)容,未經(jīng)允許不得轉(zhuǎn)載。





























 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論