完善資料讓更多小伙伴認(rèn)識(shí)你,還能領(lǐng)取20積分哦,立即完善>
標(biāo)簽 > gpu
圖形處理器(英語:Graphics Processing Unit,縮寫:GPU),又稱顯示核心、視覺處理器、顯示芯片,是一種專門在個(gè)人電腦、工作站、游戲機(jī)和一些移動(dòng)設(shè)備(如平板電腦、智能手機(jī)等)上圖像運(yùn)算工作的微處理器。
文章:4932個(gè) 瀏覽:135431次 帖子:305個(gè)
基于NVIDIA GPU加速端點(diǎn)使用千問3.5 VLM開發(fā)原生多模態(tài)智能體
阿里巴巴推出了全新開源 千問3.5 系列,專為構(gòu)建原生多模態(tài)智能體而設(shè)計(jì)。該系列的首個(gè)模型是一款總參數(shù)為 397B、具備推理能力的原生視覺語言模型 (V...
大模型推理服務(wù)的彈性部署與GPU調(diào)度方案
7B 模型 FP16 推理需要約 14GB 顯存,70B 模型需要 140GB+,KV Cache 隨并發(fā)數(shù)線性增長(zhǎng),顯存碎片化導(dǎo)致實(shí)際利用率不足 60%。
Kubernetes Pod調(diào)度策略原理與落地指南
Pod調(diào)度是Kubernetes的核心機(jī)制之一,決定了Pod最終運(yùn)行在哪個(gè)節(jié)點(diǎn)上。默認(rèn)調(diào)度器kube-scheduler通過一系列預(yù)選(Filterin...
2026-02-27 標(biāo)簽:gpu數(shù)據(jù)庫kubernetes 145 0

英偉達(dá)微通道液冷板技術(shù)全解析:原理、工藝、優(yōu)勢(shì)與產(chǎn)業(yè)適配
隨著AI算力的爆發(fā)式增長(zhǎng),英偉達(dá)Rubin架構(gòu)GPU等高端芯片的單芯片功耗已逼近2.2kW(2026年最新實(shí)測(cè)數(shù)據(jù)),局部熱點(diǎn)熱流密度最高可達(dá)650W/...
借助NVIDIA CUDA Tile IR后端推進(jìn)OpenAI Triton的GPU編程
NVIDIA CUDA Tile 是基于 GPU 的編程模型,其設(shè)計(jì)目標(biāo)是為 NVIDIA Tensor Cores 提供可移植性,從而釋放 GPU 的...

本博文是系列課程的一部分,旨在幫助開發(fā)者學(xué)習(xí) NVIDIA CUDA Tile 編程,掌握構(gòu)建高性能 GPU 內(nèi)核的方法,并以矩陣乘法作為核心示例。

RK3576開發(fā)板OpenGL性能大起底,這數(shù)據(jù)我真的服了
瑞芯微RK3576芯片作為一款中高端的八核Arm架構(gòu)嵌入式處理器,集成Mali-G52MC3的GPU。本次OpenGL性能測(cè)試,基于觸覺智能RK3576...
FPGA+GPU異構(gòu)混合部署方案設(shè)計(jì)
為滿足對(duì) “納秒級(jí)實(shí)時(shí)響應(yīng)” 與 “復(fù)雜數(shù)據(jù)深度運(yùn)算” 的雙重需求,“FPGA+GPU”異構(gòu)混合部署方案通過硬件功能精準(zhǔn)拆分與高速協(xié)同,突破單一硬件的性...

RSoft GPU加速技術(shù)重塑光子元件設(shè)計(jì)效率革命
在現(xiàn)代光子元件設(shè)計(jì)中,有限時(shí)域差分法(FDTD)是進(jìn)行電磁模擬分析的重要基礎(chǔ)技術(shù)。然而,隨著結(jié)構(gòu)尺寸的縮小和模擬范圍的擴(kuò)大,傳統(tǒng)的 CPU 計(jì)算 可能需...

破解AI服務(wù)器CPU/GPU供電困局:納秒級(jí)瞬態(tài)如何穩(wěn)壓?MHz噪聲怎樣濾除?
本文摘要:AI芯片的算力狂奔,正將其供電網(wǎng)絡(luò)推向極限。核心電壓降至0.8-1.2V,單相電流沖擊達(dá)百安級(jí),導(dǎo)致VRM輸出端出現(xiàn)納秒級(jí)(10-100ns)...

NVIDIA RTX PRO 5000 Blackwell GPU的深度評(píng)測(cè)
NVIDIA RTX PRO 5000 Blackwell 是 NVIDIA RTX 5000 Ada Generation 的升級(jí)迭代產(chǎn)品,其各項(xiàng)核心...

NVIDIA RTX PRO 4000 Blackwell GPU性能測(cè)試
作為 NVIDIA 專業(yè)顯卡產(chǎn)品線中單槽性能的巔峰之作,NVIDIA RTX PRO 4000 Blackwell 在各項(xiàng)核心指標(biāo)上均實(shí)現(xiàn)對(duì)前代 NVI...

如何在NVIDIA Jetson AGX Thor上部署1200億參數(shù)大模型
上一期介紹了如何在 NVIDIA Jetson AGX Thor 上使用 Docker 部署 vLLM 推理服務(wù),以及使用 Chatbox 作為前端調(diào)用...
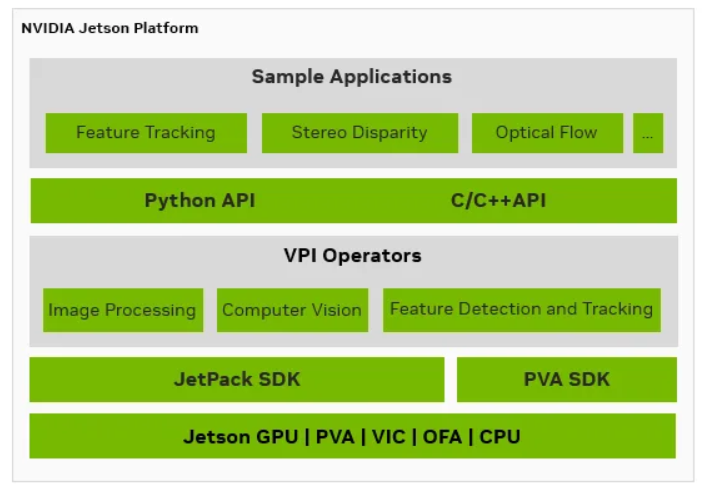
如何在NVIDIA Jetson Thor上提升機(jī)器人感知效率
構(gòu)建自主機(jī)器人需要具備可靠且低延遲的視覺感知能力,以實(shí)現(xiàn)在動(dòng)態(tài)環(huán)境中的深度估計(jì)、障礙物識(shí)別、定位與導(dǎo)航。這些功能對(duì)計(jì)算性能有較高要求。NVIDIA Je...

沐曦股份MXMACA軟件棧3.3.0.X版本技術(shù)解析
近期,沐曦股份發(fā)布了MXMACA軟件棧(以下簡(jiǎn)稱“MACA”)的3.3.0.X版本,MACA套件是面向沐曦曦云C系列、曦思N系列GPU研發(fā)的異構(gòu)計(jì)算軟件...

AI硬件全景解析:CPU、GPU、NPU、TPU的差異化之路,一文看懂!?
CPU作為“通用基石”,支撐所有設(shè)備的基礎(chǔ)運(yùn)行;GPU憑借并行算力,成為AI訓(xùn)練與圖形處理的“主力”;TPU在Google生態(tài)中深耕云端大模型訓(xùn)練;NP...

NVIDIA Omniverse基于Container的部署推流方案
為了讓客戶能夠高效安裝和部署 NVIDIA Omniverse 及 NVIDIA Isaac 平臺(tái),NVIDIA 現(xiàn)已推出簡(jiǎn)單便捷的容器化部署方案,以支...

在Python中借助NVIDIA CUDA Tile簡(jiǎn)化GPU編程
NVIDIA CUDA 13.1 版本新增了基于 Tile 的GPU 編程模式。它是自 CUDA 發(fā)明以來 GPU 編程最核心的更新之一。借助 GPU ...

(HMI)的發(fā)展尤為迅猛。隨著電子電氣架構(gòu)(EEA)的集中化,車輛對(duì)高性能計(jì)算能力的需求顯著提升,GPU(圖形處理單元)的靈活性、可擴(kuò)展性以及高效并行計(jì)...
2025-12-03 標(biāo)簽:gpu自動(dòng)駕駛 9.6k 0

NVIDIA RTX PRO 2000 Blackwell GPU性能測(cè)試
越來越多的應(yīng)用正在使用 AI 加速,而無論工作站的大小或形態(tài)如何,都有越來越多的用戶需要 AI 性能。NVIDIA RTX PRO 2000 Black...
 換一批
換一批
編輯推薦廠商產(chǎn)品技術(shù)軟件/工具OS/語言教程專題
| 電機(jī)控制 | DSP | 氮化鎵 | 功率放大器 | ChatGPT | 自動(dòng)駕駛 | TI | 瑞薩電子 |
| BLDC | PLC | 碳化硅 | 二極管 | OpenAI | 元宇宙 | 安森美 | ADI |
| 無刷電機(jī) | FOC | IGBT | 逆變器 | 文心一言 | 5G | 英飛凌 | 羅姆 |
| 直流電機(jī) | PID | MOSFET | 傳感器 | 人工智能 | 物聯(lián)網(wǎng) | NXP | 賽靈思 |
| 步進(jìn)電機(jī) | SPWM | 充電樁 | IPM | 機(jī)器視覺 | 無人機(jī) | 三菱電機(jī) | ST |
| 伺服電機(jī) | SVPWM | 光伏發(fā)電 | UPS | AR | 智能電網(wǎng) | 國民技術(shù) | Microchip |
| Arduino | BeagleBone | 樹莓派 | STM32 | MSP430 | EFM32 | ARM mbed | EDA |
| 示波器 | LPC | imx8 | PSoC | Altium Designer | Allegro | Mentor | Pads |
| OrCAD | Cadence | AutoCAD | 華秋DFM | Keil | MATLAB | MPLAB | Quartus |
| C++ | Java | Python | JavaScript | node.js | RISC-V | verilog | Tensorflow |
| Android | iOS | linux | RTOS | FreeRTOS | LiteOS | RT-THread | uCOS |
| DuerOS | Brillo | Windows11 | HarmonyOS |
關(guān)注我們的微信

下載發(fā)燒友APP

電子發(fā)燒友觀察

版權(quán)所有 ? 長(zhǎng)沙勒克斯教育咨詢有限公司
湖南省長(zhǎng)沙市開福區(qū)月湖街道匍園路20號(hào)聚恒科技園1棟2301-1房
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023036445號(hào)-105-1
工商網(wǎng)監(jiān)
湘ICP備2023036445號(hào)-105-1
