 沐曦股份MXMACA軟件棧3.3.0.X版本技術解析
沐曦股份MXMACA軟件棧3.3.0.X版本技術解析

1前言
01版本概述與核心定位
近期,沐曦股份發布了MXMACA軟件棧(以下簡稱“MACA”)的3.3.0.X版本,MACA套件是面向沐曦曦云C系列、曦思N系列GPU研發的異構計算軟件棧核心計算平臺、引擎、運維工具和規范化操作范本,作為沐曦“自主GPGPU硬件+全棧軟件體系”的關鍵協同載體,如圖1所示,MACA承擔著連接硬件算力單元與上層應用生態的核心紐帶作用,覆蓋底層驅動、用戶態接口、編譯器、算子適配、訓練框架、推理框架、行業場景優化等全鏈路能力,是支撐國產GPU生態落地與行業賦能的算力基座。
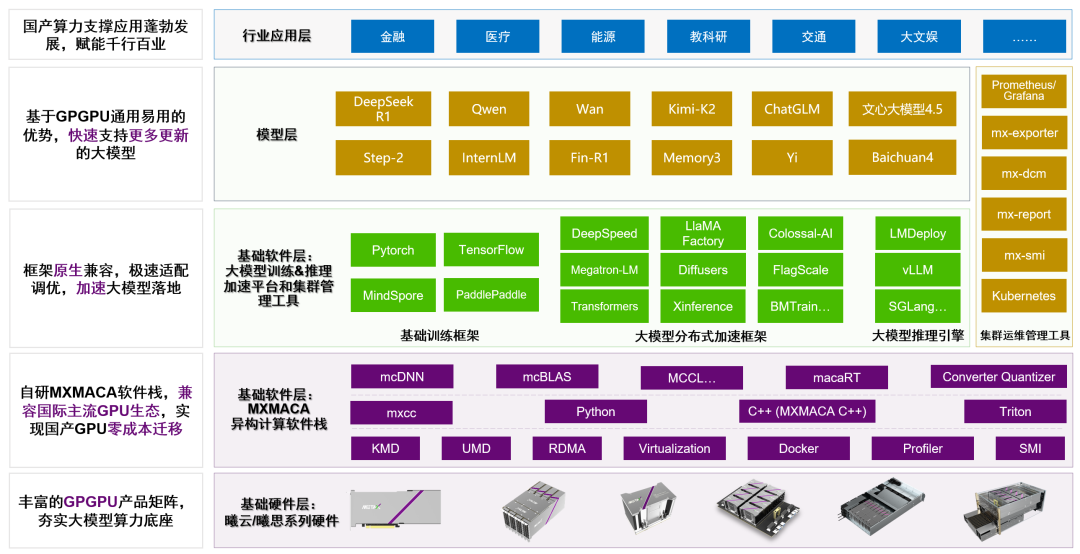
圖1 MACA套件的定位和作用
本次MACA套件版本發布聚焦 “生態強化與場景深度適配”,涵蓋底層基礎能力迭代與主流AI框架、大模型訓推、搜廣推、科學計算等多維度生態適配,但本報告不針對技術細節做全面羅列,而是聚焦版本對行業應用的實際賦能價值,選取核心場景進行深度解析。
本報告圍繞AI領域行業核心場景,系統呈現MACA-3.3.0.X版本的場景適配成果、效能表現及生態價值,向開發者與合作伙伴清晰傳遞沐曦軟硬件協同的行業賦能能力,為相關方的技術選型與產業落地提供專業參考。
02版本測試保障
為確保MACA版本作為核心協同載體的穩定性、功能完整性與性能優越性,切實支撐國產GPU生態落地與行業賦能,每個MACA版本正式發布前均經過多維度、大規模的嚴格測試驗證,構建起覆蓋軟硬件協同優化和行業應用支撐底座的全流程質量管控體系。
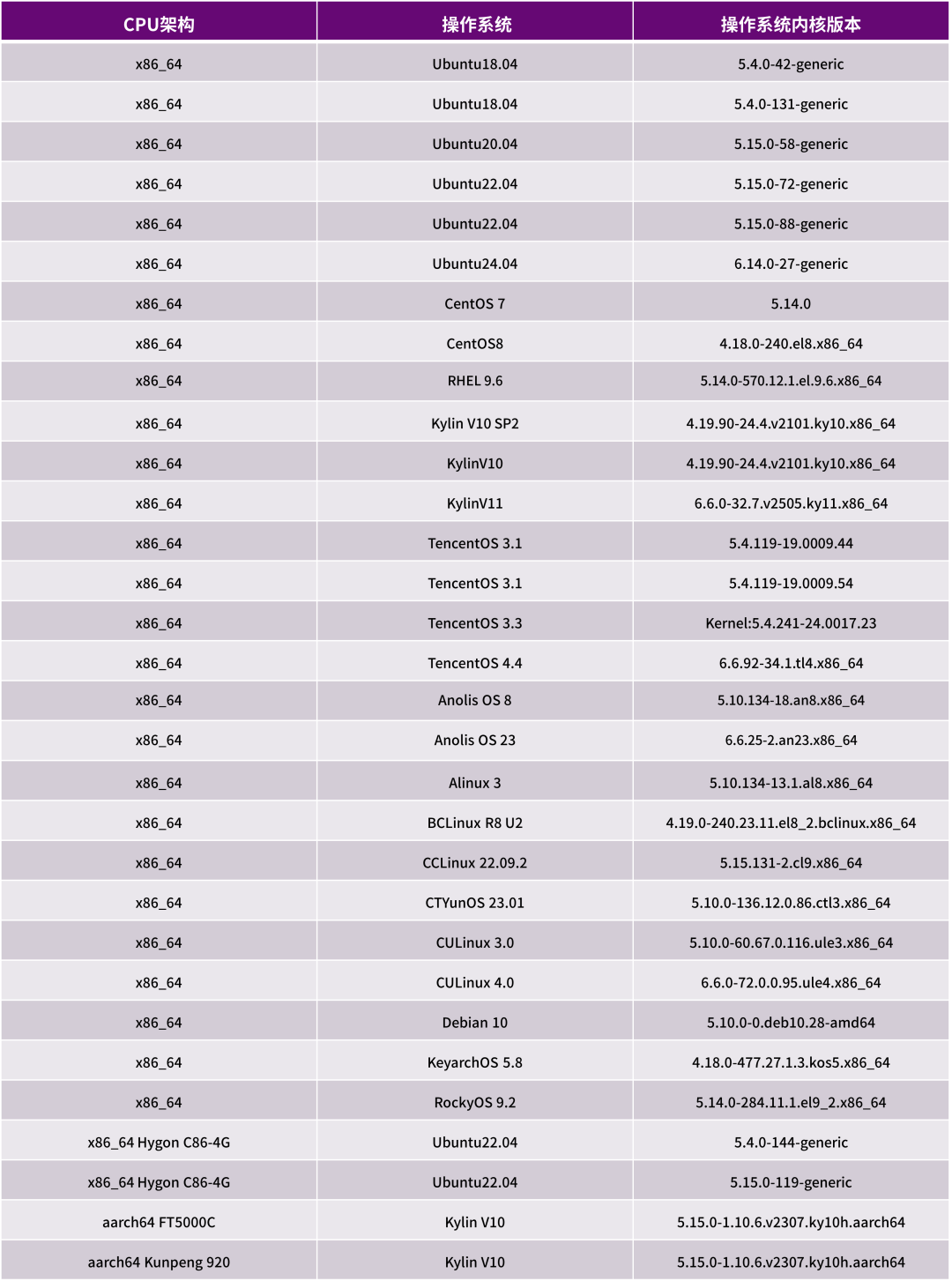
測試體系以行業場景的全面匹配度和覆蓋度為目標,共包含超過1萬5千個MACA軟件棧測試用例和超過1萬個行業相關場景應用測試用例,這些用例在整個測試周期中反復迭代執行,從功能正確性、性能達標率、長期穩定性等多維度驗證產品質量,確保滿足商業落地的嚴苛要求。測試覆蓋近30種國際主流及國產操作系統及內核(如表1所示),僅曦云C系列GPU產品測試相對應的測試就占用超過60000個GPU 小時,以大規模資源投入保障測試的全面性與有效性。
表1 MACA-3.3.0.X版本適配CPU、操作系統和內核對照部分列表
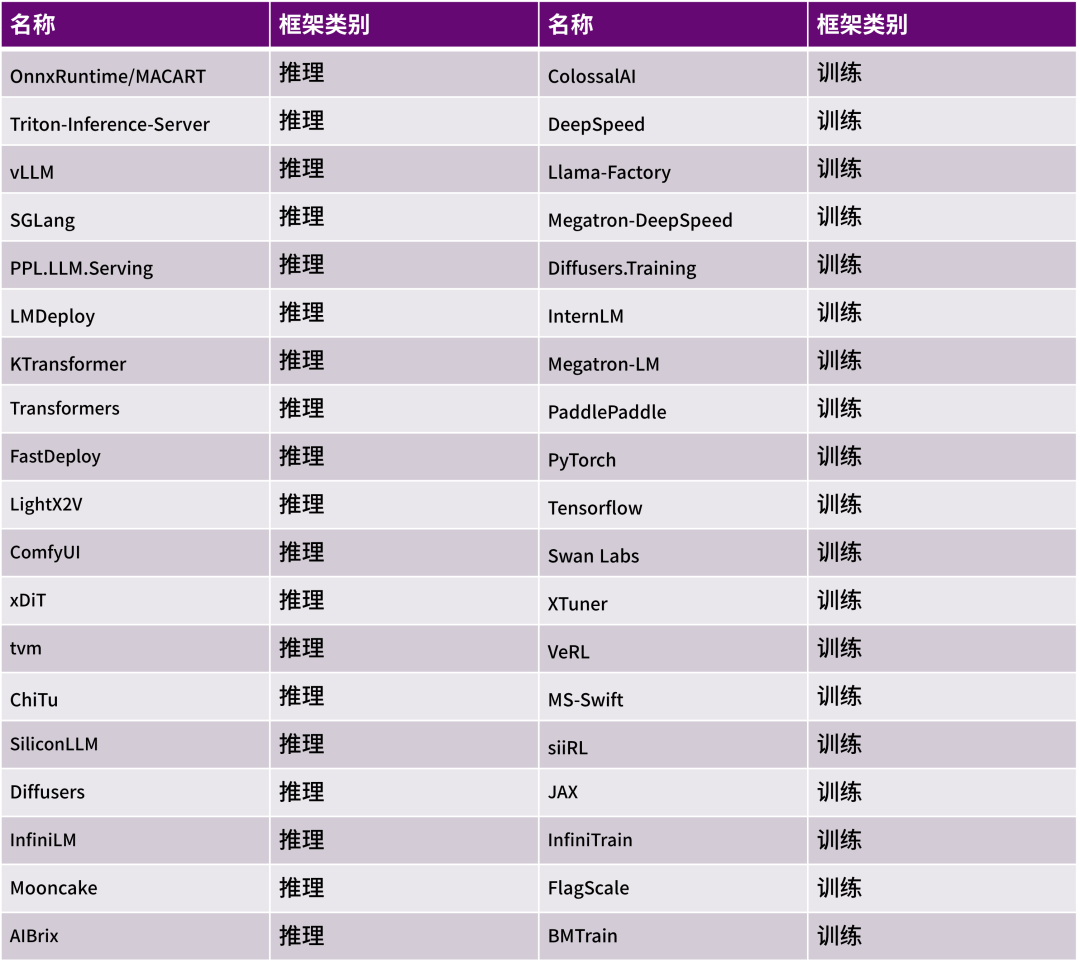
在核心測試模塊覆蓋上,MACA軟件棧測試精準對標全鏈路技術能力。其中,開發效率引擎層的測試能力包括CTS(兼容性測試套件)、編譯器、數學庫(算子庫)、通訊庫、工具鏈、虛擬化、視頻編解碼等基礎模塊,確保底層基礎能力的穩定可靠;涵蓋算子庫廣度以及算子壓力測試(算子庫范圍和數量如表2所示)、用戶態接口的完備性和性能優化測試、集合通信能力驗證等核心模塊。在垂直場景賦能層中,生態適配體系層面則涵蓋PyTorch、TensorFlow、PaddlePaddle為代表的主流AI框架兼容、Megatron-LM、DeepSpeed等大模型訓練框架和vLLM、SGLang等推理框架及加速庫支持以及科學計算場景適配等,針對生態適配體系中的AI框架與模型兼容需求,測試環節專門覆蓋40余種主流AI框架(如表3所示)及接近500個模型類別,每個模型會在多種參數組合和多種GPU配置環境下完成性能驗證,最終每個細分場景下都會輸出超過5000條性能數據,全面保障模型運行效率與兼容性,為開發者提供低成本、高性能運行的堅實保障。
表2 部分常用算子庫及其測試用例數
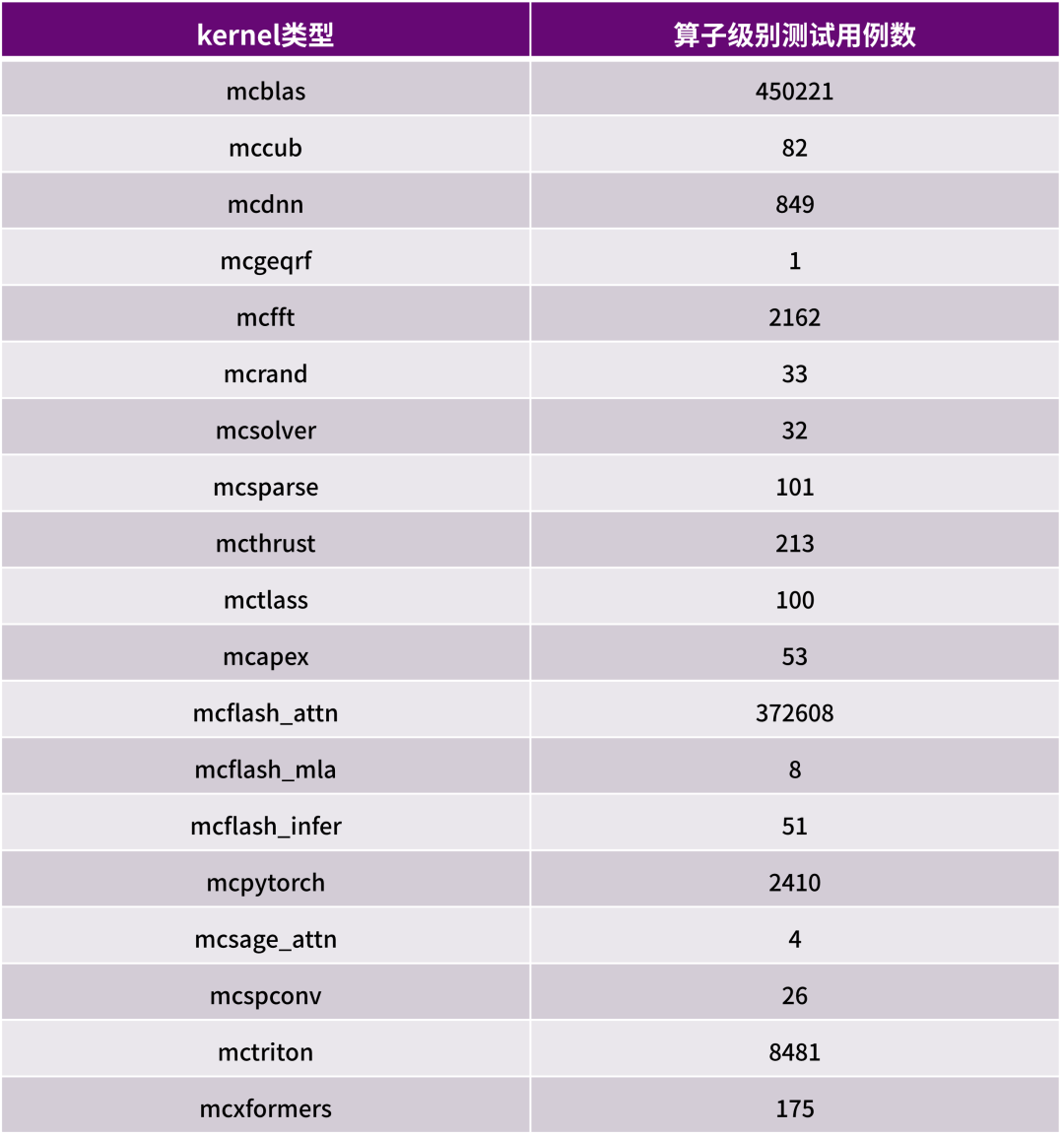
表3 MACA-3.3.0.X版本支持AI框架部分列表
 ? ? ? ? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ? ? ? ?
03核心發布信息匯總
| 核心信息 | |
| 適配硬件 | 沐曦曦云C系列GPU、曦思N系列(基于全自研 GPGPU 核心IP及架構,原生支持全精度計算、MetaXLink 高速互連及硬件級虛擬化、軟切分能力) |
| 版本定位 | 生態強化版:聚焦算子全量覆蓋、主流框架深度兼容、多場景性能優化,全面提升商業落地適配性與開發者使用體驗 |
| 核心升級方向 |
PyTorch 2.8 版本算子全量覆蓋; 大模型訓推性能對標國際旗艦產品; 搜廣推場景多技術棧深度適配; 垂直領域(AI4S、傳統小模型)專項優化 |
| 正式發布時間 |
MACA-3.3.0.X軟件棧于12月8日發布 AI框架適配版本于12月15日發布 |
|
版本迭代 核心亮點 |
MACA SDK: 單機多卡環境下,支持任意數量GPU動態鎖定/解鎖同一主機內存,實現多卡H2D傳輸 優化Stream優先級,即保證Graph額外創建的Stream和Graph Launch API使用的Stream優先級一致 通訊庫: 適配MIXL庫 DeepEP適配Hidden Size和專家數等更多參數規格,以支持更多MoE大模型 分層算法支持多機Reduce Scatter、All Gather通信功能 數學庫: XFormers將attention backend所用的flashAttn2.5.3升級到2.6.3,并支持全部memory efficient forward API功能 mctlassEx新增w8a16 contiguous group gemm接口功能 mcDNN新增int8/fp16 fwd conv+gelu融合功能 FlashMLA支持DeepSeek v3.2所需的sparse prefill和decode功能 MACA PyTorch: 支持 torchcodec-0.6.0 發布PyTorch2.8版本 MACA JAX: 正式發布mcJAX-0.4.34 AI訓推框架 PaddlePaddle: 適配Paddle3.3.0版本 支持Customer Kernel注冊 支持大模型訓推一體 支持科學計算高階微分 vLLM: 適配0.11.0版本發布 SGLang: 適配0.5.4版本發布,并優化性能 |
2生態適配度詳情
1全棧基礎能力:生態全域覆蓋與技術底座革新
1.1PyTorch框架適配與算子全量覆蓋
沐曦MACA-3.3.0.X版本完成了對 PyTorch 2.8 版本的深度適配工作,實現了對原生算子配置文件 native_functions.yaml 中定義算子體系的全面兼容。本次適配覆蓋全部2650個核心算子(其中GPU算子2410個),涵蓋基本算術運算、線性代數操作、卷積/池化類算子、規約操作、隨機采樣、索引與切片快速傅里葉變換(FFT)、Attention等關鍵算子類別;在張量運算維度,同時支持稠密張量與稀疏張量的完整運算邏輯,數據類型層面則覆蓋整數、浮點、布爾、復數及量化類型等多類數據形態,保障了算子能力的完整性與場景適配性。
在此基礎上,沐曦基于該完備的算子系統,進一步完成分布式訓練、torch.compile 等高級特性的適配與落地,實現了從基礎算子層到高階訓練與編譯優化能力的全棧式兼容,為基于 PyTorch 2.8 的各類深度學習訓練與推理場景提供了穩定、全面的底層算子支撐。該適配方案基于沐曦全棧軟件體系打造,向上兼容PyTorch原生接口與核心模塊,向下深度契合自研GPU硬件特性,無需調整工程構建邏輯即可實現現有模型無縫使用。
為保障生態兼容性,MACA套件通過生態適配工具鏈實現構建系統平滑切換,支持C++擴展功能及Megatron-LM、DeepSpeed等主流大模型訓練框架,支持vLLM、SGLang、Tansformers和KTransformer等主流大模型推理框架,兼容Ubuntu、CentOS、RHEL、openEuler、Anolis OS 、銀河麒麟等主流Linux發行版。同時完整支持混合精度訓練、分布式訓練、torch.compile編譯優化與圖模式任務下發的深度集成等關鍵特性,搭配性能分析與優化工具鏈,核心場景性能對標主流GPU水平。此外,通過內存分配優化、數據布局適配等底層調優,進一步釋放硬件算力,結合輕量化部署方案與豐富示例程序,大幅降低使用門檻。不僅夯實了國產GPU的生態基礎,更為深度學習開發者提供了開箱即用、高效穩定的技術支撐,加速AI訓練與推理場景的產業化落地。
1.2第三方開源倉庫資產復用測試
CUDA是GPGPU領域的行業標準,能便捷實現GPU并行編程,支撐各類軟件與框架運行,GitHub上相關項目近3萬個,覆蓋并行計算、科學計算等關鍵場景,影響力遠超同類技術。對于已有資產的適配意義重大:一方面,其適配后可快速接入成熟開源生態,拓展AI、數據處理、氣象預報、計算化學等多元應用場景;另一方面,能滿足HPC軟件、PyTorch 等主流框架需求,降低用戶學習成本,提升平臺競爭力,填補國產異構計算平臺的GPU加速生態空白。
質量保證團隊以GitHub為核心數據源,按 “含CUDA關鍵字且star數量大于1且具有活躍度” 的規則篩選代碼倉,本版本測試選取 4490個倉庫進入正式測試;這些代碼按依賴庫集中于MPI、BLAS等高頻庫,按應用領域可劃分為AI模型和應用、高性能并行計算、氣象模擬、計算化學等場景,按編程語言C/C++原生語言為主。通過 “雙環境驗證+自動化流水線” 的方式推進,最終4490個開源項目適配測試結果如圖2所示:57個暫不可用(編譯失敗11 + 運行失敗 46)、260個修改后可用(含結果不一致45)、4173個直接可用(結果一致),直接適配成功率 92.94%。
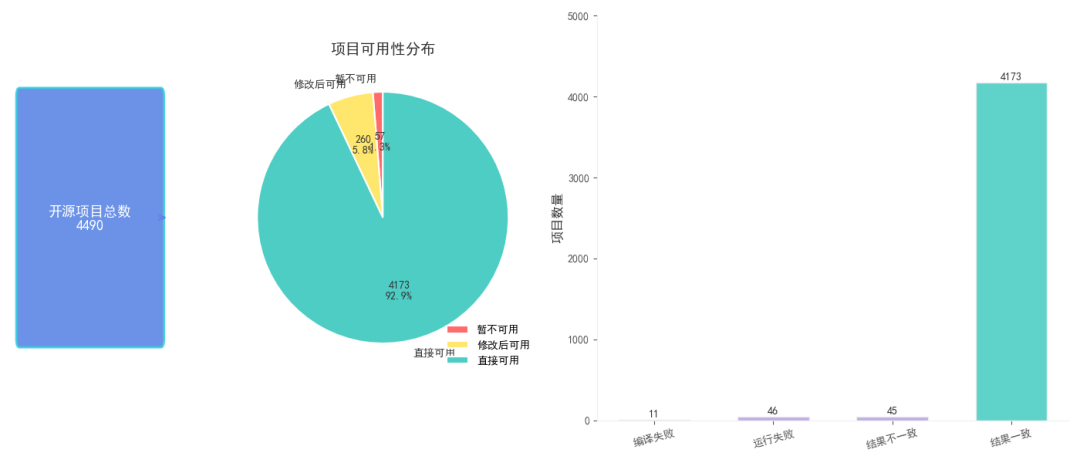
圖2 MACA套件中開源項目適配測試結果
這些直接通過的項目無需額外改動代碼,從GitHub篩選后拿過來即可在MACA平臺穩定運行,覆蓋MPI、BLAS等核心依賴庫及氣象模擬、計算化學等主流應用場景,充分體現了MACA對現有生態的兼容深度。僅小部分項目需手動微調,這類項目共260個、占比5.79%(不足 6%),且修改量極小。主要集中在cmake配置優化、少量頭文件適配或編譯器腳本調整,無需改動核心業務邏輯,平均每個項目手動修改耗時不超過半天。結合自動化流水線的批量驗證能力,整體適配效率與可用性處于行業較好水平,為用戶快速使用并行加速應用提供了可靠支撐。
1.3全棧工具鏈優化與多場景適配主要特性一覽
在開發效率引擎層,MACA套件通過高性能算子庫、智能編譯工具鏈、專業性能分析工具及配套工具庫,構建起降低異構開發門檻的技術體系。其中,六大核心高性能算子庫(mcBLAS、mcDNN、mcFlashAttention 等)針對多 GPU 拓撲優化內存訪問與并行邏輯,如 mcBLAS 支持按 GPU 數量動態切分矩陣,mcFlashAttention 通過三級存儲體系減少跨 GPU 通信;編譯器工具支持 MACA C/C++、Fortran 等多語言,結合指令重排、內存合并、任務自動切分等多 GPU 優化策略,將高級語言轉化為高效可執行程序;性能分析工具則通過系統級追蹤與核函數級指標采集,助力定位計算瓶頸,搭配 mcPytorch、mcTriton 等工具庫,進一步簡化異構開發全流程,相關技術細節如圖3所示。
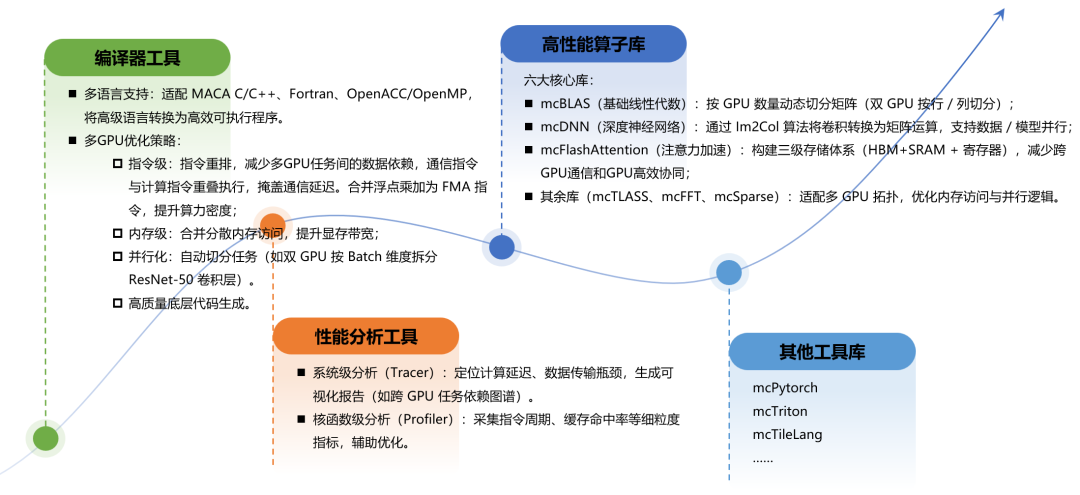
圖3 MACA套件中開發效率引擎——降低異構開發門檻
在垂直場景賦能層,MACA套件圍繞AI與科學計算兩大領域,通過針對性的優化策略與框架適配,實現算力與行業需求的精準融合。AI領域中,訓練優化兼容 PyTorch、BMTrain等框架,依托硬件流水線并行實現通信與計算重疊,優化分布式并行策略;推理優化則適配ONNX Runtime、vLLM、SGLang等框架,采用INT8 量化、KVCache 跨卡管理提升長序列處理效率。科學計算領域通過重構 MPI、BLAS 庫提升內存帶寬,并定向移植 OpenFOAM、GROMACS 等專業科學計算框架,結合容器化部署方案,確保算力能高效支撐流體仿真、分子動力學等垂直場景,完成從算力供給到行業價值轉化的關鍵銜接,具體實施方案如圖4所示。
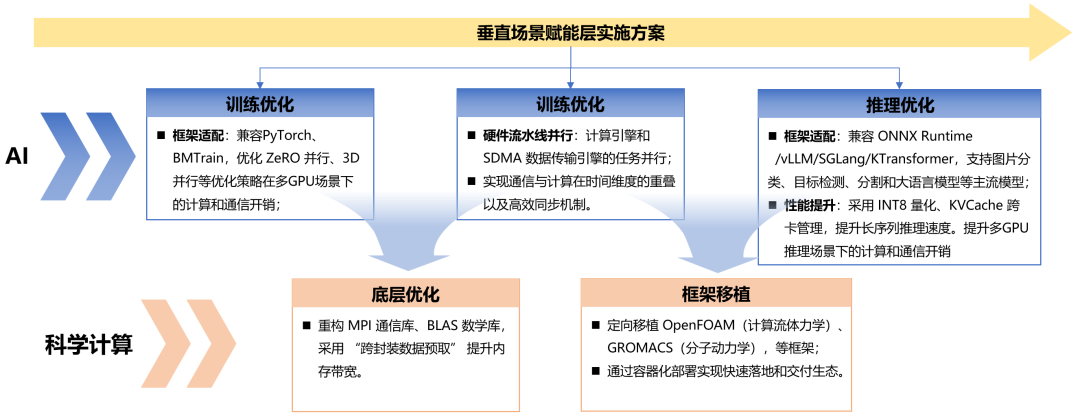
圖4 MACA套件中垂直場景賦能層——算力與行業需求的融合
2大模型訓推一體化:大模型算力支撐底座和效能突破
沐曦MACA-3.3.0.X版本構建起覆蓋大模型訓練與推理全流程的一體化算力支撐底座,通過軟硬件深度協同、核心算子優化、分布式架構升級,破解大模型超大規模參數訓練的通信瓶頸、高算力需求、長周期部署等核心痛點,實現訓推效能的跨越式突破。
2.1訓推一體化算力底座核心架構
2.1.1. 硬件算力基座支撐
依托沐曦自研GPGPU的高算力密度、高內存帶寬與高速互連優勢,底座提供從單卡到萬卡級集群的彈性算力供給。單卡原生支持多精度混合計算,內存容量與帶寬適配千億參數模型的存儲需求;跨節點通過MetaXLink自研高速互連技術,構建低時延、高帶寬的分布式通信網絡,為大規模集群訓推奠定硬件基礎。
2.1.2. 全棧軟件協同賦能
以MACA異構計算軟件棧為核心,構建起端到端協同體系,實現軟硬件能力的深度耦合與效能最大化。該體系全面兼容 PyTorch、PaddlePaddle、TensorFlow、JAX、Megatron-LM、DeepSpeed、XTuner等主流大模型訓練框架,全面兼容vLLM、SGLang、LMDeploy等大模型推理框架,圖5展示了MACA套件在大模型推理場景下的優化技術匯總。總體特征是無需大幅修改代碼即可支持現有模型,降低開發者使用門檻;依托MetaXLink自研高速互連技術與MCCL高性能通信庫,構建低時延、高帶寬的分布式通信架構,有效破解分布式訓練中的通信瓶頸;集成拓撲感知MCCL分布式通信庫,能夠動態識別集群拓撲結構并適配最優通信策略,為多機多卡訓推提供高效數據協同支撐;同時內置自研編譯器優化模塊,通過算子自動融合、循環展開等編譯級智能優化,充分挖掘硬件底層算力潛力,實現計算資源的高效利用,為大模型訓推全流程提供穩定、高效的軟件底層支撐。
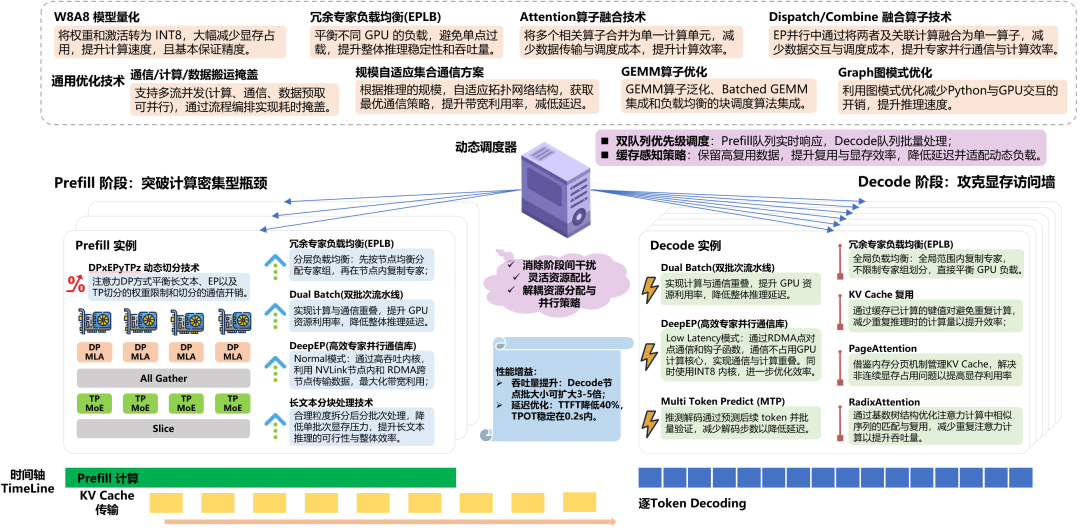
圖5 MACA套件大模型推理優化技術匯總
2.1.3. 訓推無縫切換能力
MACA軟件棧底座打破訓練與推理的場景壁壘,支持模型訓練后的輕量化轉換與直接部署,無需二次適配。通過統一的模型格式與接口規范,實現 “訓練-微調-推理-部署” 全流程鏈路打通,大幅降低大模型從研發到落地的周期成本。
2.2核心效能優化技術突破
2.2.1. 關鍵算子深度調優
針對大模型訓推核心算子開展硬件親和性優化:
FlashAttention算子:優化數據布局與訪存流水線設計,融合計算與數據搬運操作,適配大模型長上下文生成需求。按GPU片上高速緩存大小拆分Q/K/V數據塊,讓計算全程在高速緩存內完成,不用反復讀寫外部HBM高速內存。同時整合矩陣相乘、Softmax歸一化等多步操作,中間結果不落地,大幅減少HBM數據傳輸開銷。支持FP16/BF16多精度與超長序列,長序列場景吞吐量提升,內存帶寬占用降低,模型精度完全不受影響,高效緩解訪存瓶頸。
分布式集合通信庫:作為分布式訓推的 “數據協同中樞”,負責多機多卡間高效數據同步與交換,是大規模集群發揮算力的核心支撐。針對AllReduce、All2All、AllGather等高頻算子開展全維度優化:AllReduce(聚合核心)采用算法自適應策略,根據數據量動態切換Ring/Tree/Recursive Doubling算法,結合節點內預聚合+跨節點拓撲感知路由,減少20%跨節點通信延遲;All2All(MoE專家并行關鍵)通過動態分組通信、流量均衡調度優化,避免專家數據交換時的網絡擁堵,如圖6所示在EP144的實踐中,使用了優化后的All2All通信庫,專家并行效率提升15%,;AllGather(數據匯聚)采用分塊流水線傳輸+異構網絡適配,提升數據分片聚合速率。同時疊加通信壓縮(梯度量化/稀疏化)、預通信調度等技術,千卡集群線性度穩定在95%以上,保障大模型分布式訓推的高吞吐與低延遲。
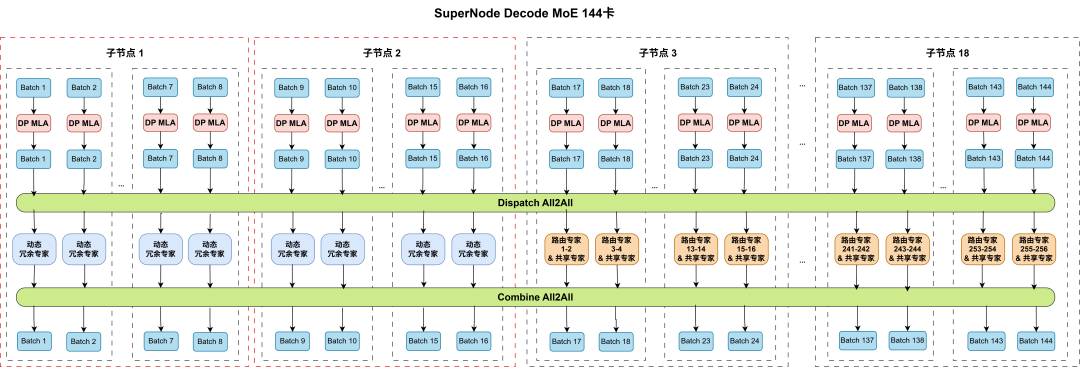
圖6 分布式集合通信庫在大EP并行中的使用
通信-計算重疊優化:通信-計算重疊優化是突破GPU訓推性能瓶頸的核心技術,旨在解決數據通信與計算任務串行執行導致的資源閑置問題。核心通過異步通信機制實現:依托MACA自研MCCL集合通信庫的非阻塞接口,將數據傳輸任務與GPU計算任務解耦;結合任務調度引擎預加載遠程數據、拆分通信粒度,利用GPU空閑周期并行處理數據傳輸;部分架構通過硬件級專有通信單元卸載,進一步降低CPU干預開銷。圖7所示,在大模型分布式訓練場景的實踐中,通過計算和通信并行可顯著縮短端到端延遲,提升GPU利用率15%-30%,在分布式訓練、大模型推理等場景中,有效緩解跨節點/跨卡通信瓶頸,支撐更大批量數據處理與更復雜模型的高效運行。
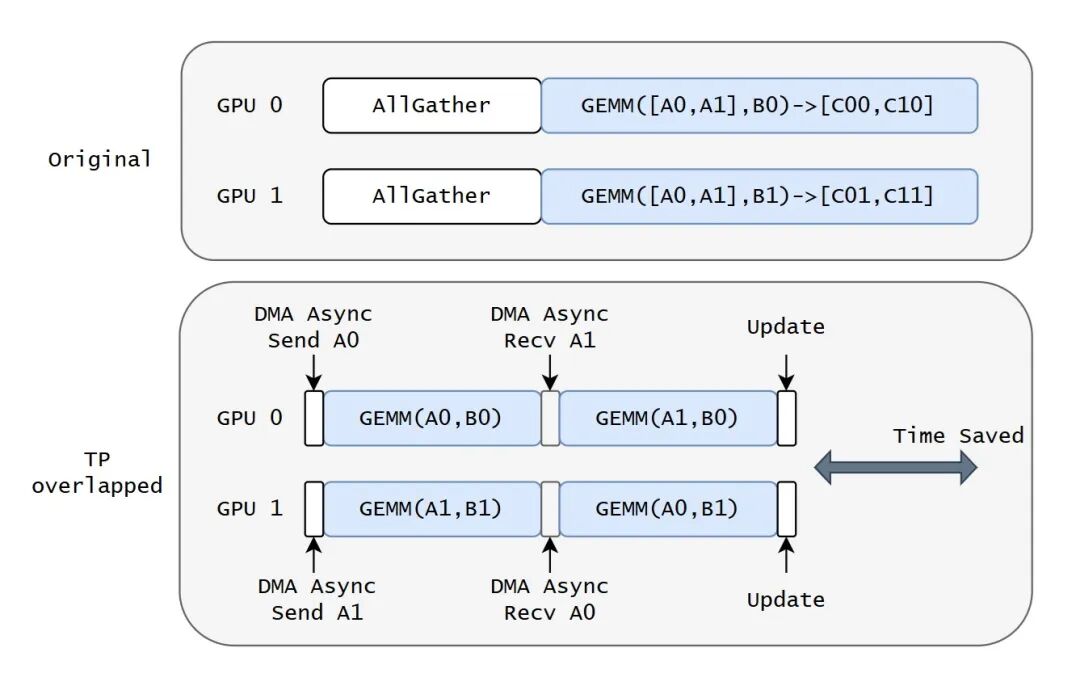
圖7 大模型分布式訓練場景的計算和通信并行
2.2.2. 編譯與部署優化
編譯級效能提升:深度支持torch.compile動態圖編譯優化,通過算子自動融合、循環展開、指令調度優化等手段,最大化硬件算力利用率,模型訓練迭代速度提升;
推理引擎輕量化適配:針對大模型推理場景打造專用輕量化引擎,優化算子調度與批處理策略,覆蓋長短序列差異化需求,短序列推理延遲降低,長序列推理吞吐量提升;
企業級部署適配:兼容容器化部署與云原生調度架構,支持集群快速擴容與彈性伸縮,簡化環境配置與運維流程,適配企業級大規模落地需求,降低部署與運維成本。
2.3效能突破核心表現
1訓練效能
針對大規模大模型訓練場景,顯著縮短訓練周期,在大規模集群分布式訓練中展現優異線性度,可支持長周期無故障穩定運行,保障訓練任務高效推進;
2推理效能
對主流大模型推理性能進行深度優化,顯著降低推理延遲、大幅提升吞吐量,在長上下文推理場景下仍保持高效穩定的運行表現,適配復雜業務需求;
3兼容性
全面兼容當前主流大模型生態體系,覆蓋全系列主流模型,無需進行代碼修改即可直接開展訓練與推理工作,降低模型優化與適配成本;
4擴展性
具備從小規模調試到大規模訓推的全場景平滑擴展能力,可靈活適配不同規模企業的技術研發與生產部署需求,提供高效、可擴展的算力支撐方案。
2.3.1 大模型訓練性能數據
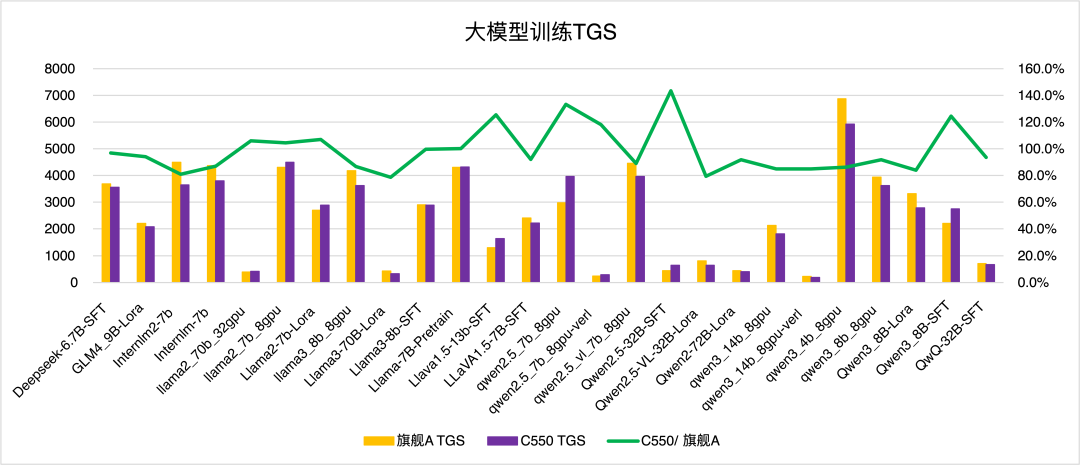
圖8 不同大模型訓練任務的 TGS 對比
圖8展示了 DeepSeek、GLM、InternLM、Llama、Qwen 等多系列大模型,在不同參數規模(如 7B、13B)及任務類型(SFT、Pretrain)下的訓練 TGS 數據,包含 “旗艦 A TGS”(黃色柱)、“C550 TGS”(紫色柱)及兩者效率比值(綠色折線)。
2.3.2 大模型推理性能數據
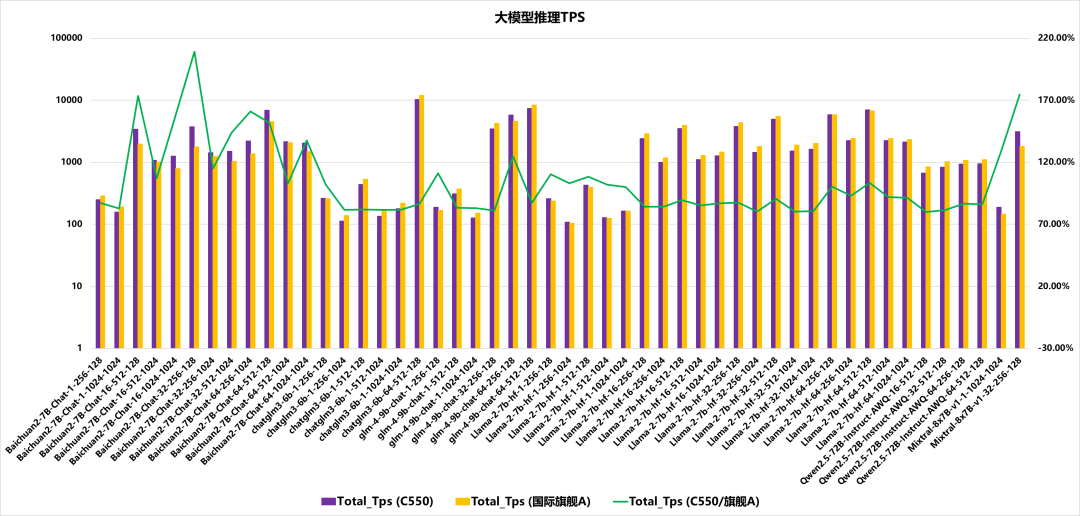
圖9 不同大模型推理任務的 Total TPS 對比
圖9呈現大模型推理階段的 Total_Tps 指標對比,橫軸為組合型 Model-Name(格式:模型名 - 并發數 - Input size-Output size),涵蓋 Baichuan2、chatglm3、glm4、Llama2、Owen2.5、Mixtral 等模型及不同并發、輸入輸出尺寸的配置。縱軸左側為 Total_Tps 數值,右側為 Total_Tps (C550 / 國際旗艦 A) 的比值;紫色柱代表 Total_Tps (C550),黃色柱代表 Total_Tps (國際旗艦 A),綠色折線表征兩者的比值,展示了不同模型及配置下的 TPS 表現與相對比值波動。
3搜廣推業務全場景:多技術棧協同的
全鏈路訓推適配升級
搜廣推(搜索、廣告、推薦)是互聯網核心流量變現與用戶體驗優化場景,其核心訴求是在海量數據中精準匹配用戶需求,并支持高并發、低延遲的實時決策。隨著數據規模爆發式增長和模型復雜度提升,GPU憑借大規模并行計算能力、高內存帶寬、專用計算核心,成為搜廣推場景的核心算力支撐。本版本技術報告重點討論TensorFlow/JAX與XLA技術的深度融合,暫不展示TorchRec體系。
3.1訓練適配:TensorFlow/JAX + XLA 深度協同,打造高效訓練新范式
3.1.1. 技術棧支持:全鏈路覆蓋與深度融合
全面完成 TensorFlow、JAX 雙框架與 XLA 技術棧的深度協同適配,打通從數據輸入、模型構建、編譯優化到分布式執行的全鏈路流程。其中,TensorFlow 依托成熟的模型開發體系、工業級分布式訓練框架及搜廣推場景生態優勢,提供低門檻的開發體驗;JAX 則憑借函數式編程特性、原生 XLA 深度集成能力及靈活的自動微分機制,適配高性能、定制化的訓練需求;XLA 編譯器作為統一優化層,通過算子融合、內存智能調度、靜態編譯優化等核心能力,解決傳統訓練中內核調用頻繁、內存開銷大的痛點。三者形成 “TensorFlow 生態便捷性+JAX高性能靈活性+XLA編譯高效性” 的三重優勢,覆蓋搜廣推場景模型訓練全流程,無論是基于TensorFlow的工業化落地,還是基于JAX的極致性能調優,均無需額外適配即可實現高效接入。
3.1.2. 核心優化:多卡訓練與精度優化雙輪驅動
單機多卡高效適配:以TensorFlow單機多卡訓練框架為核心,完成其數據并行模式與 XLA的深度協同適配,打通TensorFlow多卡調度接口與XLA跨設備編譯鏈路;同時針對JAX的分布式特性,適配其分布式接口與XLA跨設備編譯邏輯,解決JAX多卡場景下數據分片、設備通信的效率瓶頸。借助XLA對TensorFlow靜態計算圖、JAX函數式計算圖的統一優化能力,解決單機場景下多卡間數據同步、算子調度協調等關鍵問題,實現大規模批次樣本的高效并行訓練;依托TensorFlow成熟的多卡資源管理能力、JAX輕量化的分布式調度特性與XLA的編譯優化聯動,讓單機多卡資源利用率提升。
混合精度計算原生兼容:深度適配TensorFlow混合精度訓練接口,基于其對 FP16/BF16/TF32/FP32數據類型的原生支持,結合XLA編譯器的精度自適應優化邏輯;同時充分利用 JAX原生對BF16/FP16的輕量化支持,針對JAX函數式計算圖的精度傳播特性,優化XLA的精度適配規則。XLA可統一解析TensorFlow、JAX計算圖中各模塊的精度需求,自動識別模型核心計算模塊與精度敏感模塊,對 TensorFlow 場景側重 “生態兼容下的精度平衡”,對JAX場景側重 “極致性能下的精度可控”,實現高精度與高性能的動態平衡。相較于傳統CPU訓練方案,依托TensorFlow/JAX與XLA的協同優化,訓練周期縮短,有效支撐大規模稀疏特征與復雜模型的長時間穩定訓練。
編譯優化深度迭代:針對TensorFlow定義的搜廣推高維稀疏算子及特征處理流程,優化XLA的編譯適配邏輯;同時針對JAX生態下的稀疏計算需求,定制XLA對JAX稀疏算子的編譯規則,解決JAX稀疏特征處理中編譯開銷高、算子碎片化的問題。XLA基于TensorFlow靜態計算圖、JAX函數式計算圖的結構特點,精準識別 “特征查找-交叉-激活” 等關鍵子圖,通過子圖聚類、算子自動融合等技術,將多步TensorFlow操作或JAX函數調用融合為單一編譯單元,減少數據在TensorFlow/JAX算子與XLA編譯單元間的搬運開銷,讓核心計算模塊訓練效率提升。
3.1.3. 適配模型:覆蓋核心場景與復雜架構
深度兼容搜廣推領域全量核心模型,無論是基于TensorFlow開發的傳統機器學習模型(LR、GBDT)、深度學習基礎模型(DeepFM、Wide&Deep、DCN、NFM)、復雜序列模型(DIN、DIEN),還是基于JAX(結合Flax/Haiku高層神經網絡庫)實現的同類型模型,均無需大幅修改代碼即可接入適配體系。針對 Transformer 類模型的注意力機制、DeepFM 的特征交互模塊等復雜計算單元,分別定制XLA編譯優化規則:對TensorFlow版本側重 “生態兼容下的算子穩定性優化”,對JAX版本側重 “函數式計算圖的編譯效率優化”,既保障TensorFlow模型工業化訓練的穩定性,也提升JAX模型在GPU集群下的計算效率,全面覆蓋CTR/CVR預估、推薦排序、搜索召回等核心訓練場景。
3.1.4. 效果展示:TensorFlow/JAX + XLA 的深度融合
下圖10為部分搜廣推模型在XLA技術的深度融合下的,與國際旗艦產品A的對比效果。橫坐標為選取的各種主要模型,柱狀圖的主縱軸表示訓練單個step的平均耗時,折線圖的次縱軸表示國際旗艦產品A與沐曦GPU產品的比值。
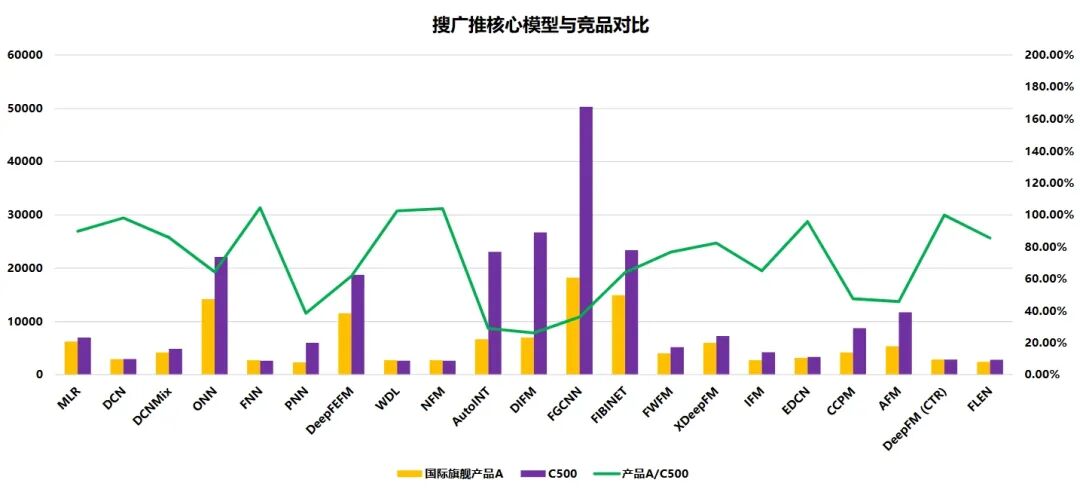
圖10 搜廣推模型使能XLA與國際旗艦產品A的
對比效果
3.2推理適配:TVM + XLA協同,構建低延遲推理體系
3.2.1. 技術棧支持:編譯與部署一體化支撐
完成TVM + XLA推理技術棧全流程適配,構建 “模型轉換-圖優化-圖切分-圖編譯-算子編譯優化-部署落地” 的一體化支撐體系。TVM提供跨硬件平臺的模型優化與部署能力,支持TensorFlow等多框架模型的統一轉換;XLA則作為核心編譯引擎,承接模型的算子優化、子圖編譯等關鍵環節,兩者協同實現 “模型無需改造即可編譯,編譯結果可直接部署” 的高效流程,適配GPU、CPU等加速器等多硬件環境,降低跨平臺部署成本。
3.2.2. 核心優化:多維度技術降低推理開銷
算子融合與編譯優化:通過XLA的算子融合能力與TVM的圖優化策略,實現推理計算圖的深度優化,將Concat、Transpose、Reduce、Split、Elementwise等串行算子融合為復合算子,減少內核調用次數,推理計算效率提升。
W8A8低比特量化落地:針對搜廣推推理場景對延遲的嚴苛要求,實現W8A8低比特量化技術的全流程支持,在XLA編譯器的量化感知編譯與TVM的量化部署工具協同下,模型體積壓縮,推理延遲大幅度優化,同時精度損失可控,滿足業務指標要求。
動態批處理智能適配:結合搜廣推業務流量波動特點,支持動態批處理技術,通過TV的批處理調度模塊與XLA的動態shape編譯能力,自動適配不同流量場景下的請求批次大小,在高并發場景下吞吐量提升,低并發場景下延遲降低。
3.2.3. 適配場景:全面覆蓋核心業務全流程
全面覆蓋搜廣推業務核心推理場景,實現全場景高效支撐:
搜索場景:適配召回(向量召回、協同過濾召回)、粗排、精排全鏈路推理,通過低延遲優化保障搜索結果毫秒級返回,提升用戶檢索體驗;推薦場景:支撐個性化推薦的精排、重排環節,動態批處理技術適配流量峰值波動,確保推薦列表實時更新與高效推送;廣告場景:覆蓋 CTR/CVR 預估、廣告排序、出價決策等核心環節,低比特量化與算子融合技術保障廣告投放的實時性與精準性,提升廣告轉化效率。
3.2.4. 效果展示:TensorFlow/JAX + XLA 的深度融合
在搜廣推場景中,TVM與XLA技術形成 “雙輪驅動” 的推理生態,實現了高效且適配的技術效果:mcTVM 針對搜廣推需求,支持稀疏算子、兼容 PyTorch/ONNX 等主流框架,提供端到端編譯部署工具鏈,其適配的數十個搜廣推開源模型(如 EasyRec/DeepCTR),平均推理性能超越國際旗艦 GPU 產品A(121.04%)、產品B(131.64%),上百個模型可開箱即用。mcXLA則兼容TensorFlow/JAX 框架,支持動態shape與JIT編譯,能無縫對接TF Serving快速部署,同樣適配上百個搜廣推模型。二者結合既兼顧通用性編程,又充分優化硬件性能,最終讓沐曦GPU具備支撐千億級流量的搜廣推全棧推理能力,精準適配這一 AI 落地最成熟的商業場景,高效釋放硬件潛力。
圖11為部分搜廣推模型在XLA編譯技術與TVM編譯框架深度融合方案下,與國際旗艦產品A和B的性能對比效果。
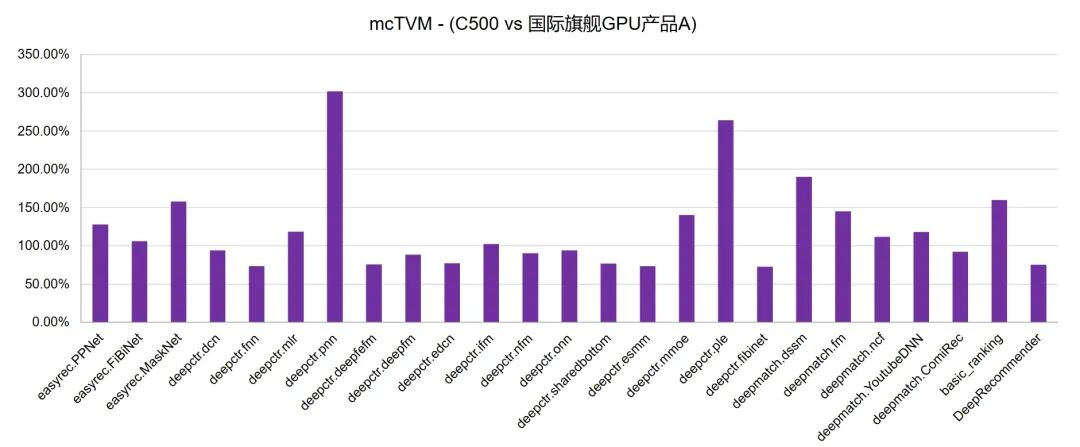
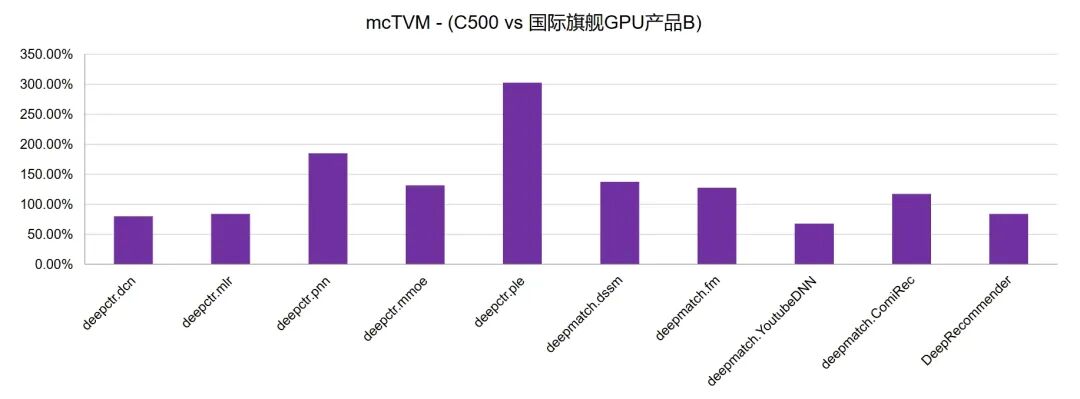
圖11 MACA套件中主流搜推廣開源模型
與國際旗艦A和B的推理性能對比
圖12呈現推薦系統和向量檢索的性能對比測試結果,涉及三類核心指標:it/s(每秒迭代次數,數值越高代表模型運算速度越快)、s/Nits(完成指定迭代量的耗時,數值越低代表效率越高)、QPS(每秒查詢數,數值越高代表向量檢索吞吐量越強)。測試對象覆蓋多目標排序 rechub 等推薦模型、Deep Image/SIFT 系列向量檢索模型,對比 C500(紫柱)與國際旗艦 B(黃柱)的性能表現,綠色曲線為 C500 相對國際旗艦 B 的性能占比。
數據層面:推薦模型中,多目標排序 rechub 的 it/s 指標 C500(約 32)優于國際旗艦 B(約 18);HugeCTR DIN 的 s/8000its 指標中國際旗艦 B 耗時更短。向量檢索模型中,Deep Image-ivflat 的 QPS(C500 約 607、國際旗艦 B 約 205)C500 領先顯著,僅 SIFT-ivfpq 的 QPS 中國際旗艦 B 略高。多數場景下 C500 性能占比超 100%,Deep Image-ivflat 占比近 300%,體現其在多數測試場景的性能優勢。
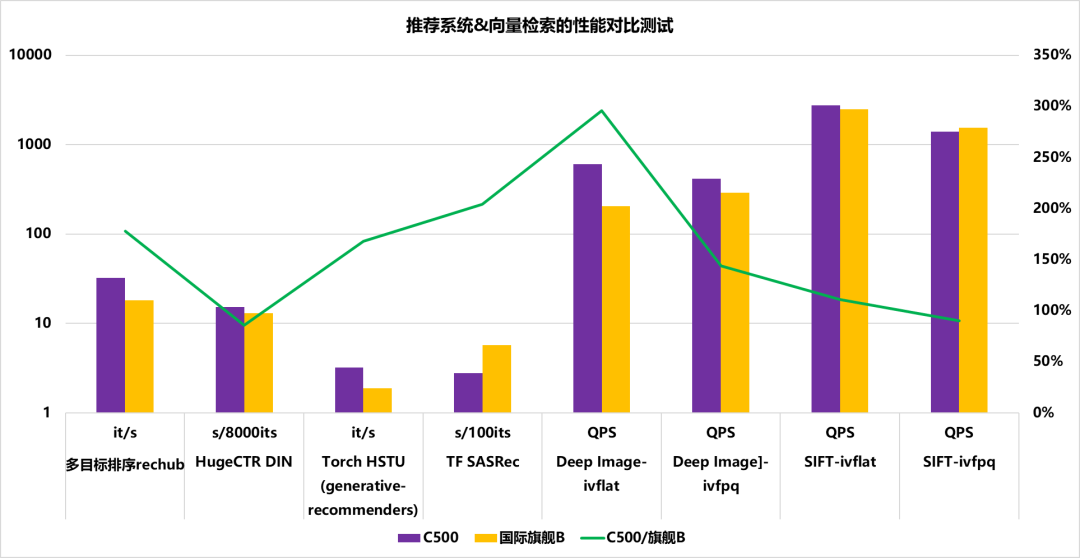
圖12 推薦系統和向量檢索與國際旗艦B的XLA
推理性能對比
4傳統小模型支持:泛場景的低成本與高效落地賦能
針對產業級AI應用中傳統小模型的部署需求,MACA套件構建了一套支持多技術領域、低成本、高算力利用率的技術體系,聚焦計算機視覺、自然語言處理及傳統機器學習等核心場景,通過兼容主流模型格式、優化底層計算邏輯及簡化流程,實現小模型的高效落地與性能提升,為相關技術應用提供標準化技術支撐。方案全面覆蓋傳統小模型的核心應用場景,無需額外構建專屬適配框架,其中計算機視覺場景支持圖像分類、目標檢測等基礎任務,適配各種圖像輸入格式,可滿足工業質檢、智能監控、物流分揀等典型場景的輕量化推理需求,兼容主流輕量化視覺模型結構;自然語言處理場景適配文本分類、識別等高頻任務,支持多語言文本及不同長度文本的處理需求,可應用于輿情分析、智能客服意圖識別、金融信息抽取、法律文書處理等場景,兼容輕量化NLP模型的推理邏輯;傳統機器學習場景則全面兼容線性回歸、聚類分析、決策樹、隨機森林等經典機器學習算法,適配結構化數據建模需求,可應用于預測、評估、分類、聚類等場景。
MACA套件具備多模型格式兼容、底層計算優化及優異性能表現等核心技術特性,支持 ONNX、TensorFlow Lite、PyTorch 等主流模型格式,搭配格式轉換工具鏈,可實現模型的直接導入與運行,降低跨框架適配的技術成本;依托 MACA 基礎計算庫,對 BLAS(矩陣運算)、FFT(頻域處理)、Sparse(稀疏數據計算)三大核心模塊進行針對性優化,實現GPU硬件的算力精準調度,減少算力冗余消耗,提升計算資源利用率,可滿足實時推理與高并發處理需求。
與國際旗艦產品A相比,部分典型模型的性能測試對比數據如圖13所示:
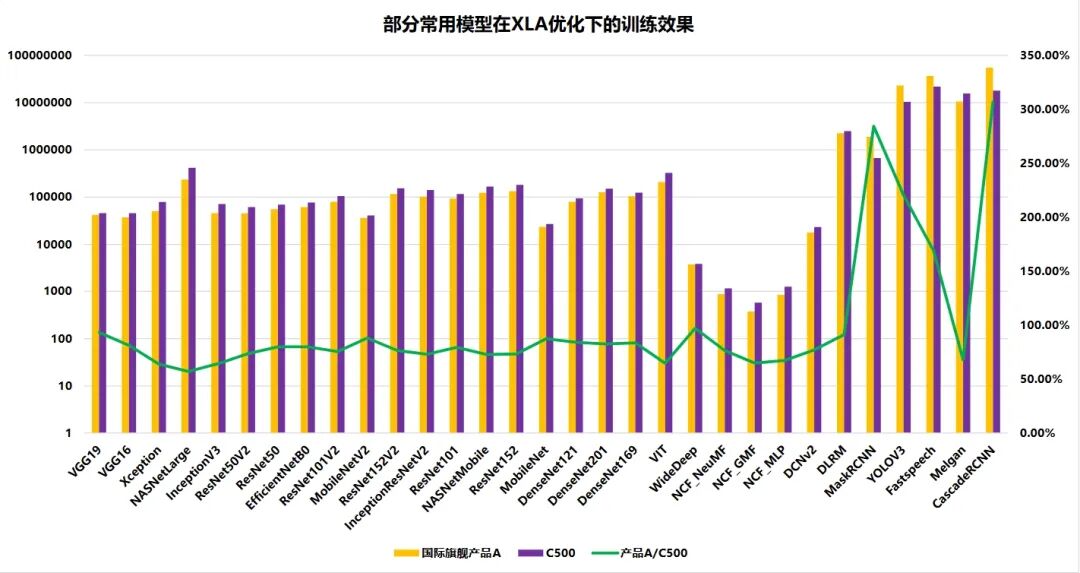
圖13 MACA套件中TensorFlow+XLA的訓練效果
圖13針對 XLA 優化場景下的常用模型訓練效果展開對比,橫軸覆蓋 VGG19、Xception、NASNetLarge 等多類典型模型,縱軸左側為訓練相關每個迭代步的平均耗時(由于不同模型的運行時間差異比較大,為了便于顯示使用了對數縱軸坐標系),右側為 “國際旗艦產品 A” 與 “C550” 的指標比值。圖中以橙色柱形表示 “國際旗艦產品 A” 的指標值,灰色柱形表示 “C550” 的指標值,黃色折線表征兩者的比值。該圖呈現了多類模型在 XLA 優化下的訓練指標差異,比值折線在多數模型區間呈小幅波動,僅在 DRM、YOLOV3 等少數模型處出現顯著抬升。
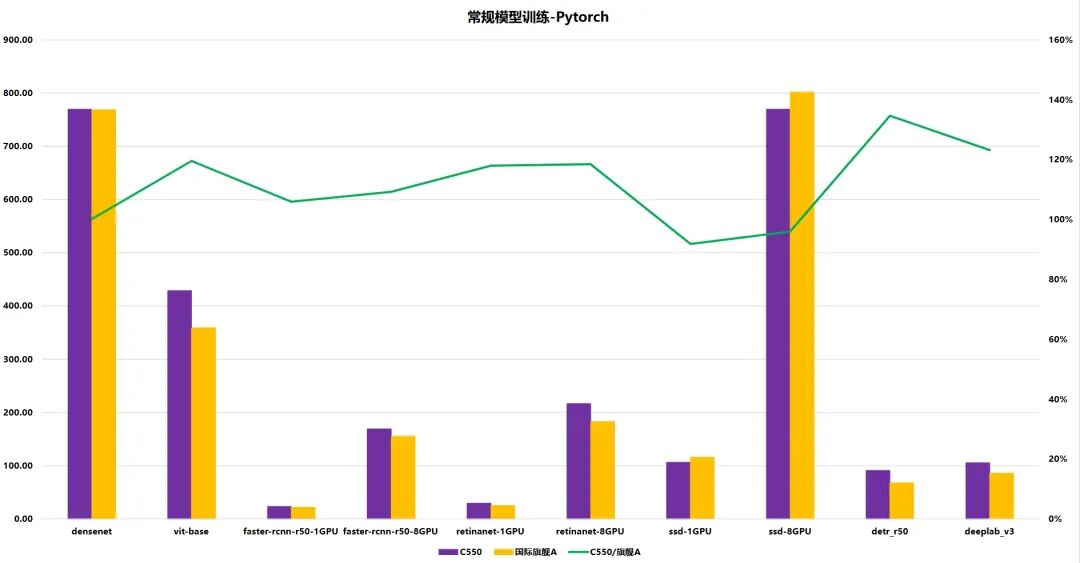
圖14 MACA套件中常規小模型PyTorch框架
的訓練效果
圖14展示 Pytorch 框架下常規模型的訓練指標對比,橫軸包含 densenet、vit-base 及不同 GPU 配置的模型(如 faster-rcnn-f50-1GPU/8GPU),縱軸左側為訓練階段的吞吐量指標,右側為 “C550” 相對 “國際旗艦產品 A” 的比值。可視化元素包括紫色柱形(C550)、黃色柱形(國際旗艦產品 A)、綠色折線(C550 / 旗艦 A)。圖中覆蓋了單 / 多 GPU 配置下的模型訓練指標,折線反映了不同模型及硬件配置下 C550 相對旗艦產品的指標比值變化。
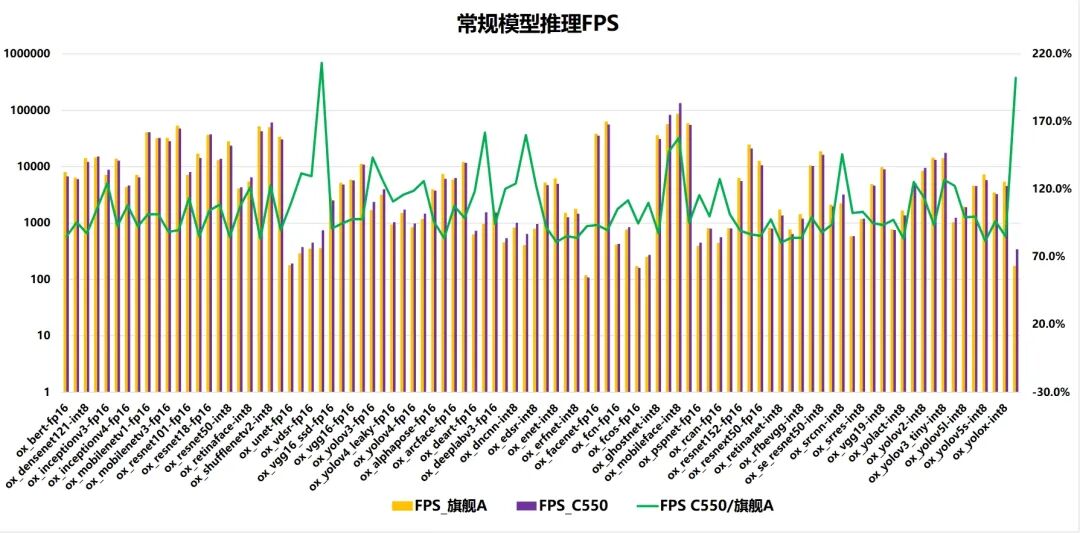
圖15 常規模型推理階段的 FPS
圖15聚焦常規模型推理階段的 FPS(每秒幀率)指標對比,橫軸為含精度配置的多類模型(如 ox_bert-fp16、ox_densenet121-int8),縱軸左側為 FPS 數值(區間 0 至 160000),右側為 “C550 / 旗艦 A” 的比值。圖中黃色柱形代表 “FPS_旗艦 A”,紫色柱形代表 “FPS_C550”,綠色折線代表兩者的比值。該圖涵蓋了 fp16、int8 等精度下的多模型推理 FPS,折線呈現 C550 相對旗艦產品的 FPS 比值在不同模型及精度配置間的波動特征。
5AI4S核心場景:沐曦股份推動
第五范式科研革新的實踐進展
AI4S(AI4Science)是繼實驗、理論、計算模擬、數據驅動后的第五代科學研究范式,2024年諾貝爾物理/化學獎對AI在基礎科學中貢獻的表彰,標志其已成為科學創新的核心工具。依托自研GPGPU及MACA生態套件,沐曦股份目前對AI4S多領域核心場景均已實現覆蓋,同時深化了與主流AI框架的生態協同,可推動科研與產業的智能化轉型,如圖16所示。
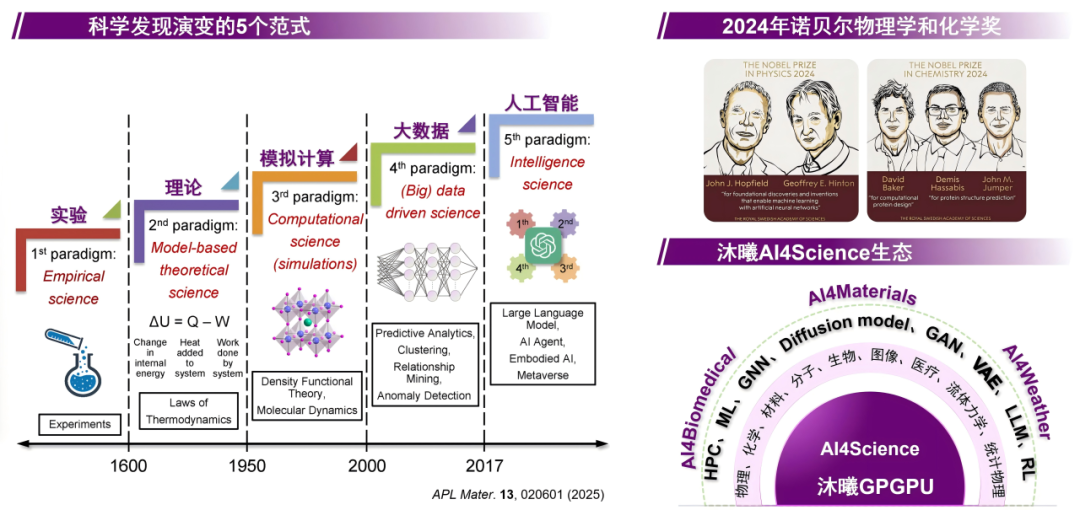
圖16 MACA套件推動第五范式科研革新的實踐進展
5.1主流AI框架的生態適配
1Paddle 框架支持
PaddleScience是基于PaddlePaddle開發的科學計算套件,憑借深度學習能力與自動(高階)微分機制,可解決物理、化學、氣象等領域問題,支持物理機理驅動、數據驅動、數理融合三種求解方式,并提供基礎API與詳盡文檔供二次開發。目前PaddleScience已完成與沐曦 AI 芯片的適配,雙方展開深度合作,覆蓋智能仿真、高性能計算、科學建模等方向,成功驗證50+科學計算模型全量訓練的精度與性能,充分展現國產AI硬件在科學計算場景的潛力。后續沐曦將與飛槳繼續在高性能科學計算、智能模擬等方向聯合攻關,推動AI for Science從實驗室走向產業落地。
2JAX框架支持
針對JAX在科學計算中 “高效自動微分+大規模并行計算” 的特性,沐曦平臺已實現對JAX生態的兼容適配,借助其技術能力,可助力物理建模、數據驅動型科學研究的高效開展,進一步豐富了AI4S的技術工具鏈。
5.2AI4Materials:破解材料研發低效痛點
針對傳統 “試錯式” 材料研發的高成本、長周期問題,AI4Materials 構建 “第一性原理 + ML勢能+分子動力學+GNN +大模型” 的一體化生態。目前,沐曦平臺已兼容VASP、DeepMD-kit、LAMMPS等工具鏈,融合多物理場耦合與原子尺度生成模型,實現國產化材料模擬平臺自主可控,推動產學研融合以提升新型功能材料的研發速度。
5.3技術科學場景:流體仿真的國產化工具賦能
在技術科學的流體仿真與求解器耦合方向,沐曦平臺適配了PaddleScience旗下的paddleCFD組件,可支持圓柱繞流、顱內動脈瘤、空氣激波等典型流體問題的仿真計算,結合 CFD-GCN、NSF-Nets等模型,進一步提升了流體仿真的效率與精度,為汽車控制臂、心臟仿真等工業級場景提供了國產化工具支持。
5.4AI4Weather:支撐高精度氣象風險管控
極端天氣對多行業沖擊顯著,AI4Weather以秒級響應的AI模型,彌補傳統數值天氣預報的高成本短板。沐曦平臺適配WRF數值模式及FourCastNet 等AI大模型,可支撐高精度極端天氣預警,助力行業風險管理與決策優化。
5.5AI4Biomedical:重塑生物醫藥創新格局
在藥物研發領域,沐曦AI4Drug discovery 平臺覆蓋分子表征、蛋白結構預測等全流程,集成 AlphaFold3、DiffDock等工具,同時融入PaddlePaddle生態下的paddleHelix工具;該工具可支持分子生成、蛋白配體相互作用預測等關鍵環節,完善了藥物研發的全流程國產化工具鏈,有效縮短研發周期、降低成本;在醫學影像領域,沐曦提供圖像重建、分割等工具集,支撐虛擬增強影像、冠脈血流模擬等臨床科研方案。
AI4S 通過繼承前四范式的優勢,實現科研效率與精度的跨越式提升。沐曦的實踐證明:基于自主可控的算力底座,結合Paddle、JAX等框架適配及paddleCFD、paddleHelix 等專用組件,可為多領域提供軟硬件協同賦能,推動科學研究的范式變革。
6版本迭代前瞻:軟硬件生態的前瞻布局
與能力升級預告
后續將推出曦云C600 GPU Beta版,聚焦硬件性能升級并對標國際高端GPU水準;軟件層面將同步強化前沿技術適配、多模態模型全流程兼容、行業專用框架適配及邊緣部署優化等核心能力,相關版本的正式發布時間后續補充。
3總結
沐曦MACA-3.3.0.X版本依托全自研GPGPU架構與MACA 異構計算軟件棧,構建了 “1+6+X” 戰略生態體系:沐曦 “1+6+X” 戰略是其算力生態商業化落地的核心布局,構建了 “算力底座-行業賦能” 的閉環體系。
“1” 為數字算力底座:以沐曦GPU為依托,通過自主 GPGPU 硬件與全棧軟件棧,支撐國家人工智能公共算力平臺、互聯網、運營商、智算中心等主體,提供自主可控的穩定算力基礎。
“6” 是6大核心行業賦能:聚焦金融、醫療健康、能源、教科研、交通、大文娛領域,針對各行業場景需求輸出行業定制化算力方案,實現場景級效能提升。
“X” 為泛行業拓展:基于標準化算力能力快速適配其他行業需求,擴大生態覆蓋邊界。
本次版本發布進一步驗證了沐曦軟硬件生態的 “高性能、高兼容、高可用” 核心特性,不僅實現了與國際旗艦產品的性能對標,更通過降低學習成本、全場景深度適配,為國產算力替代提供了成熟、可靠的解決方案,助力產業數字化轉型與技術自主創新。
關于沐曦股份
沐曦股份致力于自主研發全棧高性能GPU芯片及計算平臺,為智算、通用計算、云渲染等前沿領域提供高能效、高通用性的算力支撐,助力數字經濟發展。
-
gpu
+關注
關注
28文章
5226瀏覽量
135787 -
算力
+關注
關注
2文章
1576瀏覽量
16799 -
沐曦
+關注
關注
1文章
83瀏覽量
1849
原文標題:沐曦股份MXMACA-3.3.0.X簡要技術報告
文章出處:【微信號:沐曦MetaX,微信公眾號:沐曦MetaX】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
澎峰科技計算軟件棧與沐曦GPU完成適配和互認證
澎峰科技與沐曦完成聯合測試,實現全面兼容
瀚海量子與沐曦股份達成戰略合作 量子計算軟件領軍者+高性能GPU芯片領軍者
DLInfer聯手沐曦股份實現數據生成場景的實際落地

沐曦股份攜手紅帽共同發布MXAIE解決方案

沐曦股份曦云C系列GPU Day 0適配智譜GLM-4.6V多模態大模型

沐曦股份與江南大學建立聯合研究中心
沐曦股份正式推出曦索X系列全新GPU品牌與產品線
曦云C系列GPU Day 0 適配智譜全新一代大模型GLM-5

沐曦曦云C500/C550 GPU產品深度適配MiniMax M2.5模型
沐曦股份曦云C系列GPU深度適配通義千問Qwen3.5模型





 工商網監
工商網監
評論