 在Python中借助NVIDIA CUDA Tile簡化GPU編程
在Python中借助NVIDIA CUDA Tile簡化GPU編程

NVIDIA CUDA 13.1 版本新增了基于 Tile 的GPU 編程模式。它是自 CUDA 發明以來 GPU 編程最核心的更新之一。借助 GPU tile kernels,可以用比 SIMT 模型更高的層級來實現算法。至于如何將計算任務拆分到各個線程,完全由編譯器和運行時在底層自動處理。不僅如此,tile kernels 還能夠屏蔽 Tensor Core 等專用硬件的細節,寫出的代碼還能兼容未來的 GPU 架構。借助 NVIDIA cuTile Python,開發者可以直接用 Python 編寫 tile kernels。
什么是cuTile Python?
cuTile Python 是 CUDA Tile 編程模型在 Python 中的實現,基于 CUDA Tile IR 規范開發。它支持用 Python 編寫 tile kernels,以 tile-based 模型來定義 GPU kernels——既可以作為 SIMT 模型的替代,也能作為 SIMT 模型的補充。
SIMT 編程要求明確指定每個 GPU 執行線程的任務。理論上,每個線程都能獨立運行,執行和其他線程不同的代碼路徑。但實際應用中,要充分發揮 GPU 性能,通常會采用單線程對不同數據執行相同操作的算法設計思路。
SIMT 模型的優勢是靈活性高、可定制性強,但要達到頂級性能,往往需要大量手動調優。而 tile model 能夠幫助屏蔽部分硬件底層細節,而聚焦于更高層級的算法設計。至于 tile 算法如何拆分為線程、如何調度到 GPU 上執行,這些工作都由 NVIDIA CUDA 編譯器和運行時自動完成。
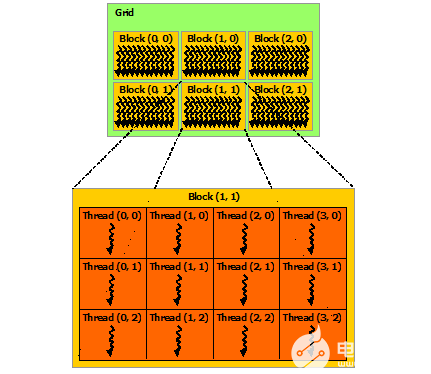
cuTile 是專為 NVIDIA GPU 設計的并行 kernels 編程模型,核心規則有四條:
數組是最核心的數據結構;
Tiles 是 kernels 操作的數組子集;
Kernels 是由多個 Block 并行執行的函數;
Block 是 GPU 計算資源的子集,tiles 的操作會在各個 block 之間并行開展。
cuTile 能自動處理塊級并行、異步執行、內存遷移等 GPU 編程的底層細節。它可以充分利用 NVIDIA 硬件的高級特性,比如 Tensor Cores、共享內存、Tensor 內存加速器,而且不需要手動編寫相關代碼。更重要的是,cuTile 能跨不同 NVIDIA GPU 架構遷移,不用重寫代碼,就能使用最新的硬件功能。
cuTile適合哪些人使用?
cuTile 面向的是需要編寫通用數據并行 GPU kernels 的開發者。目前我們重點針對 AI/ML 應用中常見的計算類型優化 cuTile,后續還會持續迭代——新增功能和性能特性,讓它能優化更多類型的工作負載。
你可能會疑惑:CUDA C++ 和 CUDA Python 一直很好用,為什么還要用 cuTile 寫 kernels?關于這一點,我們在另一篇介紹 CUDA tile model 的文章里有詳細說明。簡單來說,現在 GPU 硬件架構越來越復雜,我們提供這樣一層合理的抽象,就是為了能讓開發者更專注于算法本身,不用再花大量精力把算法手動適配到特定硬件上。
用 tile 模式寫代碼,既能利用 Tensor Cores 的性能,又能保證代碼兼容未來的 GPU 架構。就像 PTX 是 SIMT 模型的底層虛擬指令集架構(ISA),CUDA Tile IR 就是 tile-based 編程的虛擬指令集架構。它支持用更高層級表達算法,軟件和硬件會在底層自動把這種表達映射到 Tensor Cores,助力實現峰值性能。
cuTilePython代碼示例
cuTile Python 代碼長什么樣?如果你學過 CUDA C++,一定接觸過經典的向量加法 kernels。假設數據已經從主機端拷貝到設備端,CUDA SIMT 實現的向量加法 kernels 如下——它接收兩個向量,逐元素相加后生成第三個向量,是最基礎的 CUDA kernels 之一。
__global__ void vecAdd(float* A, float* B, float* C, int vectorLength)
{
/* calculate my thread index */
int workIndex = threadIdx.x + blockIdx.x*blockDim.x;
if(workIndex < vectorLength)
{
/* perform the vector addition */
C[workIndex] = A[workIndex] + B[workIndex];
}
}在這個 kernel 里,每個線程的任務都要明確指定。而且你啟動 kernel 時,還得手動選擇要啟動的 blocks 和線程數。
再看等效的 cuTile Python 實現:不用指定每個線程的操作,只需把數據拆成 tiles,定義好每個 tile 的數學運算就行,剩下的工作全由 cuTile 自動處理。
cuTile Python kernel 代碼如下:
import cuda.tile as ct
@ct.kernel
def vector_add(a, b, c, tile_size: ct.Constant[int]):
# Get the 1D pid
pid = ct.bid(0)
# Load input tiles
a_tile = ct.load(a, index=(pid,) , shape=(tile_size, ) )
b_tile = ct.load(b, index=(pid,) , shape=(tile_size, ) )
# Perform elementwise addition
result = a_tile + b_tile
# Store result
ct.store(c, index=(pid, ), tile=result)
ct.bid(0) 是用于獲取(本例中)第 0 維度塊 ID 的函數,例如,它的作用相當于 SIMT kernels 開發者使用 blockIdx.x 與 threadIdx.x。ct.load() 函數則用于從設備內存中加載指定索引和形狀的 tile 數據,數據加載到 tiles 后,即可用于計算,所有計算完成后,ct.store() 會將 tiled 數據寫回 GPU 設備內存。
完整實現代碼
接下來,我們將展示如何在 Python 中調用這個 vector_add kernels,并提供一份你可直接運行的完整 Python 腳本。以下是包含 kernels 定義與主函數的完整代碼。
"""
Example demonstrating simple vector addition.
Shows how to perform elementwise operations on vectors.
"""
from math import ceil
import cupy as cp
import numpy as np
import cuda.tile as ct
@ct.kernel
def vector_add(a, b, c, tile_size: ct.Constant[int]):
# Get the 1D pid
pid = ct.bid(0)
# Load input tiles
a_tile = ct.load(a, index=(pid,) , shape=(tile_size, ) )
b_tile = ct.load(b, index=(pid,) , shape=(tile_size, ) )
# Perform elementwise addition
result = a_tile + b_tile
# Store result
ct.store(c, index=(pid, ), tile=result)
def test():
# Create input data
vector_size = 2**12
tile_size = 2**4
grid = (ceil(vector_size / tile_size),1,1)
a = cp.random.uniform(-1, 1, vector_size)
b = cp.random.uniform(-1, 1, vector_size)
c = cp.zeros_like(a)
# Launch kernel
ct.launch(cp.cuda.get_current_stream(),
grid, # 1D grid of processors
vector_add,
(a, b, c, tile_size))
# Copy to host only to compare
a_np = cp.asnumpy(a)
b_np = cp.asnumpy(b)
c_np = cp.asnumpy(c)
# Verify results
expected = a_np + b_np
np.testing.assert_array_almost_equal(c_np, expected)
print("? vector_add_example passed!")
if __name__ == "__main__":
test()
如果已經安裝好 cuTile Python、CuPy 等必要軟件,運行代碼很簡單,直接執行以下命令即可:
$ python3 VectorAdd_quickstart.py
? vector_add_example passed!
恭喜!你已經成功運行了第一個 cuTile Python 程序。
開發者工具支持
[]()cuTile kernels 的性能分析可以用 NVIDIA Nsight Compute,操作方式和 SIMT kernels 完全一樣。
$ ncu -o VecAddProfile --set detailed python3 VectorAdd_quickstart.py
生成性能分析文件后,用 Nsight Compute 圖形界面打開,按以下步驟操作:
● 選中 vector_add kernel;
● 選擇“Details”標簽頁;
● 展開“Tile Statistics”報告板塊。
此時你會看到類似圖 1 的界面。

圖 1. Nsight Compute生成的性能分析報告,展示vector_add kernel的tile 統計信息
請注意,Tile Statistics 板塊包含了指定的 tile 數量、大小(由編譯器自動選擇),以及其他 tile 專屬信息。
源碼頁面同樣支持 cuTile kernels,還能查看源碼行級別的性能指標——這和 CUDA C kernels 的支持方式完全一致。
如何獲取 cuTile ?
運行 cuTile Python 程序,需要滿足以下環境要求:
GPU 計算能力需為 10.x 或 12.x(后續 CUDA 版本會支持更多 GPU 架構);
NVIDIA 驅動版本需為 R580 及以上(若要使用 tile 專屬開發者工具,需升級到 R590);
安裝 CUDA Toolkit 13.1 及以上版本;
Python 版本需為 3.10 及以上;
安裝 cuTile Python 包:執行 pip install cuda-tile 命令即可完成安裝。
關于作者
Jonathan Bentz 領導 NVIDIA 的 CUDA 技術營銷工程團隊,其團隊專注于創建和提供引人入勝的內容,并與 CUDA 開發者建立聯系。Jonathan 擁有愛荷華州立大學化學博士學位和計算機科學碩士學位。
Tony Scudiero 是 CUDA 平臺的技術營銷工程師。他致力于將 CUDA 帶給各種類型和能力的開發者。在 NVIDIA 任職期間,他曾使用過大型 HPC 系統和應用、實時聲學模擬 (VRWorks Audio) 和 Omniverse RTX 渲染器。
-
NVIDIA
+關注
關注
14文章
5639瀏覽量
109885 -
gpu
+關注
關注
28文章
5217瀏覽量
135632 -
編程
+關注
關注
90文章
3717瀏覽量
97249 -
python
+關注
關注
58文章
4879瀏覽量
90142
原文標題:在 Python 中借助 NVIDIA CUDA Tile 簡化 GPU 編程
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何在NVIDIA CUDA Tile中編寫高性能矩陣乘法

NVIDIA Tesla K40C K40M 高精密并行計算GPU
NVIDIA火熱招聘GPU高性能計算架構師
NVIDIA英偉達 GPU廠商 招聘軟件類職位(上海/深圳)
NVIDIA 招聘 軟件測試篇(深圳、上海)
NVIDIA-SMI:監控GPU的絕佳起點
用于vGPU的GPU調度程序
NVIDIA推出適用于Python的VPF,簡化開發GPU加速視頻編碼/解碼
如何使用Warp在Python環境中編寫CUDA內核
NVIDIA CUDA Tile的創新之處、工作原理以及使用方法




 工商網監
工商網監
評論