") 如何在NVIDIA Jetson AGX Thor上部署1200億參數(shù)大模型
如何在NVIDIA Jetson AGX Thor上部署1200億參數(shù)大模型

上一期介紹了如何在NVIDIAJetson AGX Thor上使用 Docker 部署 vLLM 推理服務,以及使用 Chatbox 作為前端調(diào)用 vLLM 運行的模型(上期文章鏈接)。本期我們將嘗試能否在 Jetson AGX Thor 上部署并成功運行高達 1,200 億參數(shù)量的 gpt-oss-120b 大模型。
gpt-oss-120b 是由 OpenAI 于今年發(fā)布的開放權重 AI 模型,采用了廣受歡迎的混合專家模型(MoE)架構和 SwigGLU 激活函數(shù)。其注意力層使用 RoPE 技術,上下文規(guī)模為 128k,交替使用完整上下文和長度為 128 個 Token 的滑動窗口。模型的精度為 FP4,可運行在 NVIDIA Blackwell 架構 GPU 上。
本期具體內(nèi)容包括:
vLLM 鏡像下載及容器構建
模型下載與運行
使用 Chatbox 作為前端調(diào)用 gpt-oss-120b
Jetson AGX Thor 模型運行資源占用及性能
一、vLLM 鏡像下載及容器構建
參考上期教程,拉取 vLLM 鏡像并構建容器。
1. 在命令行運行docker pull nvcr.io/nvidia/vllm:25.10-py3下載容器。

2. 下載完成后,運行容器,創(chuàng)建啟動命令。
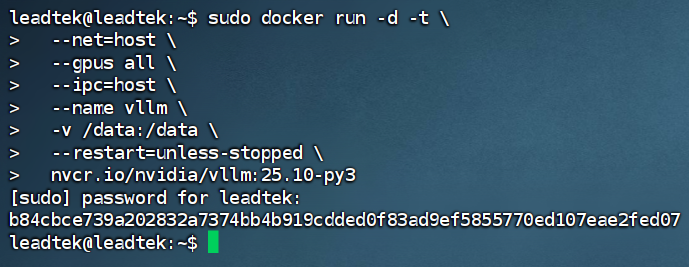
3. 容器創(chuàng)建成功后,使用docker exec -it vllm /bin/bash命令進入此容器。

二、模型下載與運行
1. 在線下載模型并運行
1.1 登錄 Hugging Face,下載 gpt-oss-120b 模型。
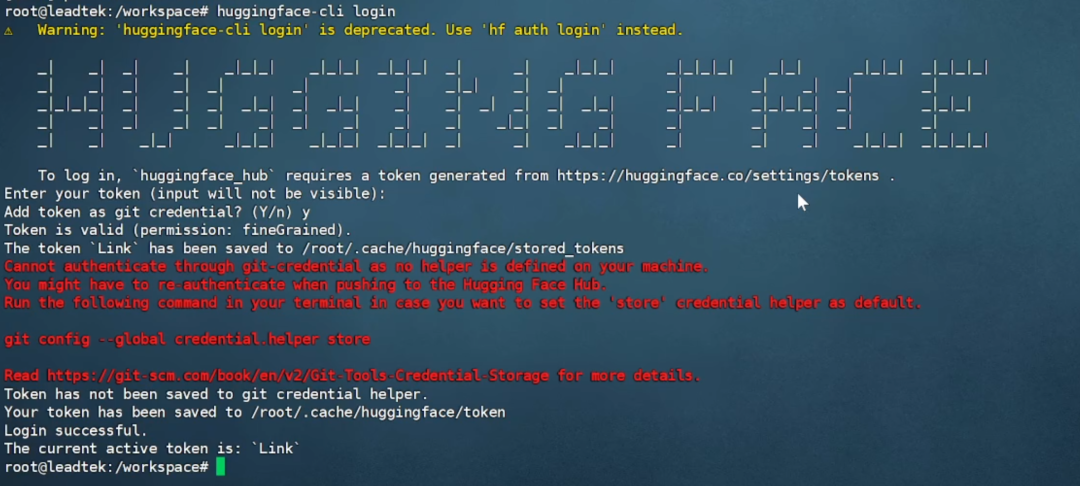
容器內(nèi)執(zhí)行huggingface-cli login,輸入 Hugging Face 的token,出現(xiàn)“Login successful”即表示登錄成功。
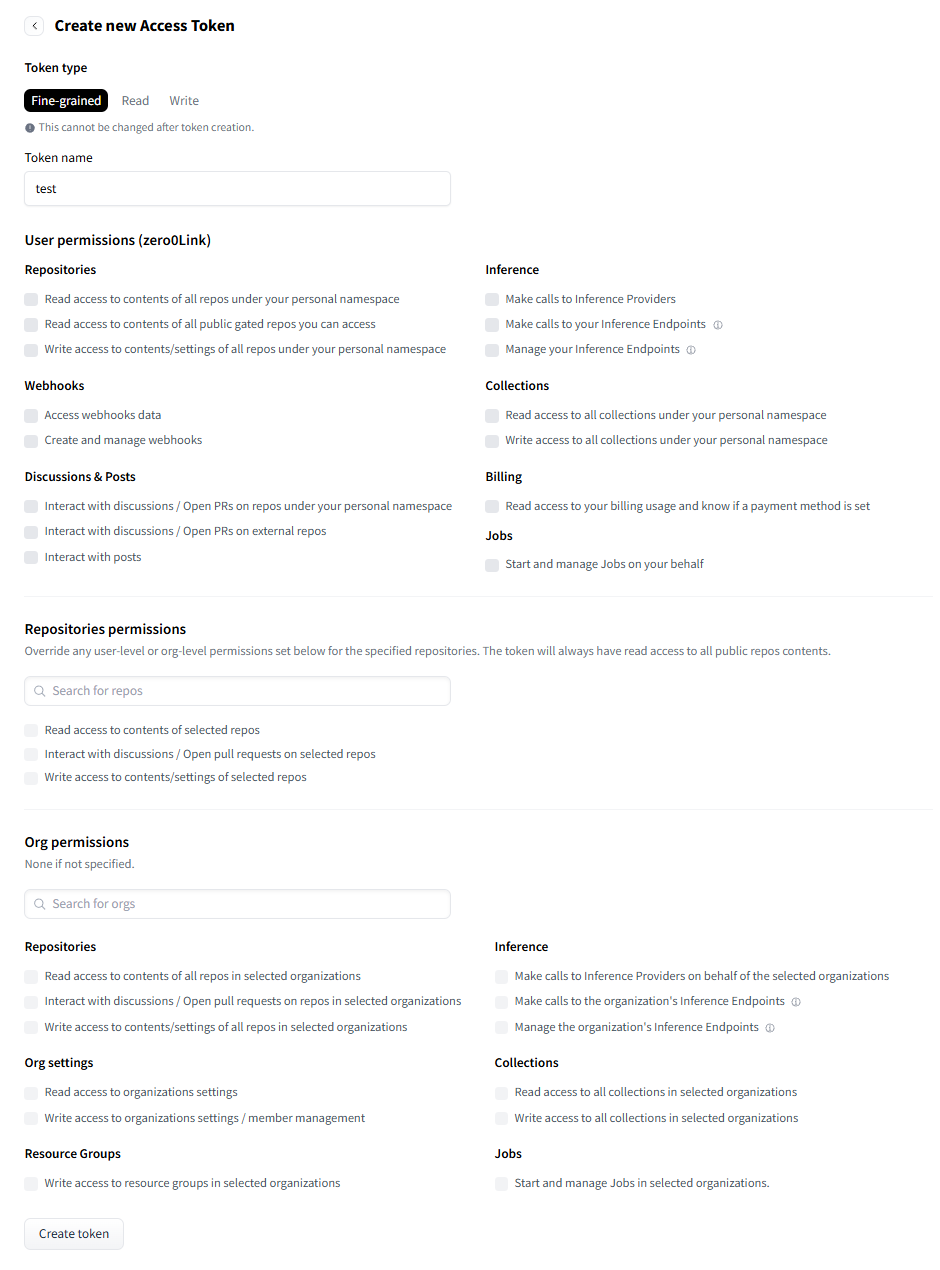
注:token 獲取方式為注冊并登錄 huggingface.co,點擊右上角用戶頭像 -Access Tokens,然后在新頁面點擊 Create new token,輸入 token name,最后在最下方點擊 Create token,復制并保存即可。
上下滑動查看圖片
1.2 容器內(nèi)運行vllm serve openai/gpt-oss-120b,從 Hugging Face 上在線下載模型并開始運行。
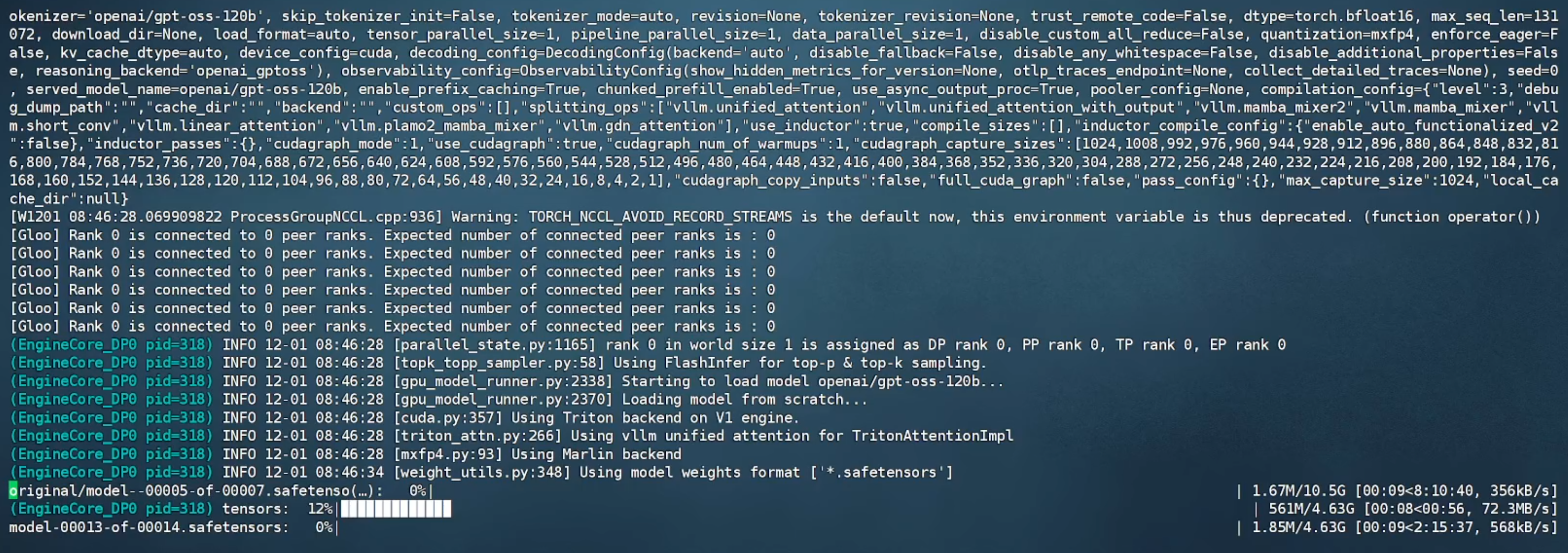
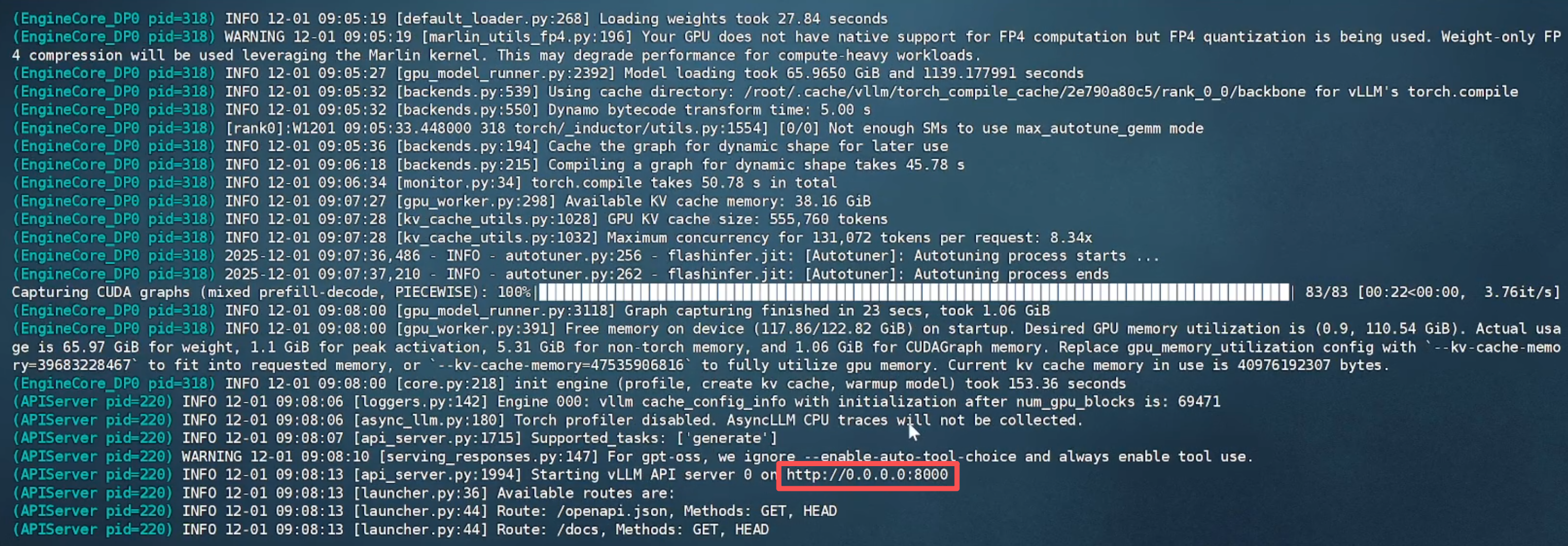
1.3 等待模型文件下載完成后(需科學上網(wǎng)),出現(xiàn) API 端口號即可進行調(diào)用。
2. 本地模型運行
上述方法會將模型文件下載至容器的默認目錄,再次運行時將直接調(diào)用已下載的文件。為避免容器刪除導致文件丟失,建議將模型文件復制到本地映射的目錄(如 /data)中進行保存。
以在當前路徑舉例,命令行執(zhí)行以下代碼,即可保存到本地指定目錄:
cp-r models--openai--gpt-oss-120b /data

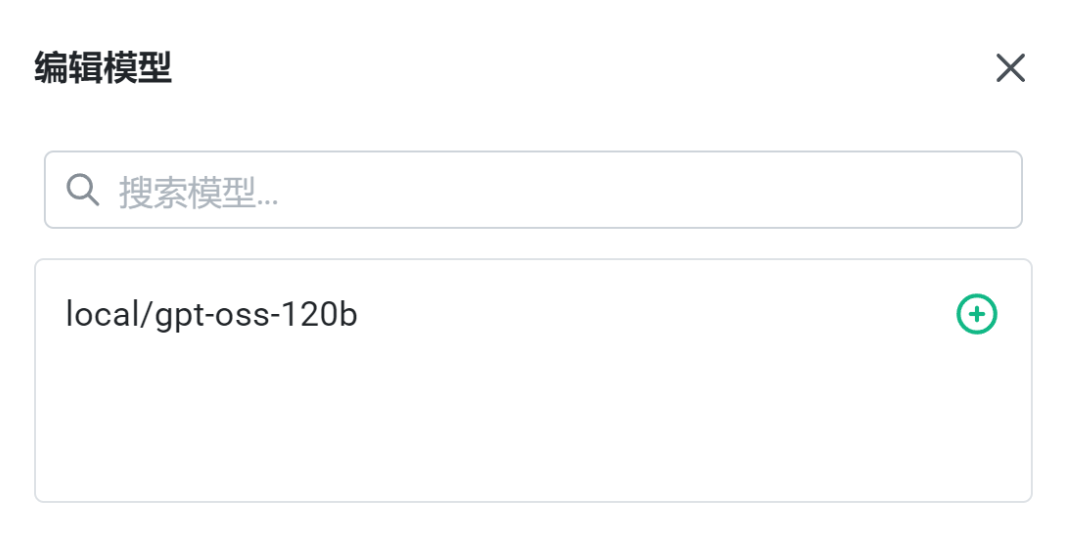
我們將本地模型文件命名為:local/gpt-oss-120b,容器內(nèi)命令行執(zhí)行以下命令,即可正常運行本地模型:
vllm serve /data/models--openai--gpt-oss-120b/snapshots/b5c939de8f754692c1647ca79f bf85e8c1e70f8a --served-model-name"local/gpt-oss-120b"
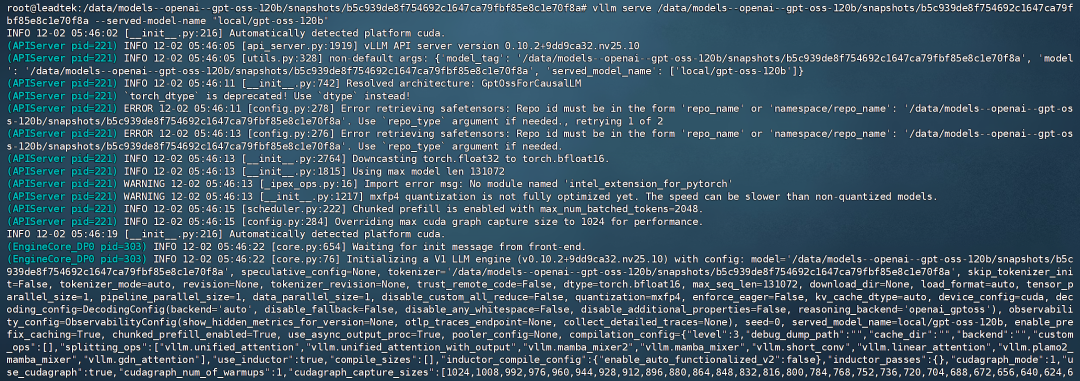
模型運行成功:
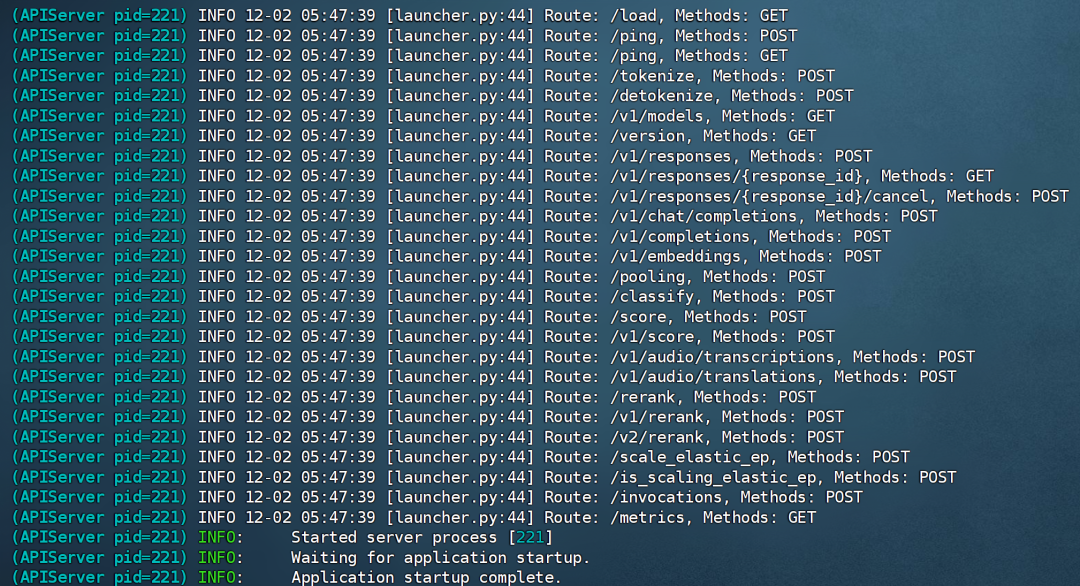
三、使用 Chatbox 作為前端調(diào)用 gpt-oss-120b
Chatbox AI 是一款 AI 客戶端應用和智能助手,支持眾多先進的 AI 模型和 API,可在 Windows、MacOS、Android、iOS、Linux 和網(wǎng)頁版上使用。在這里,可以選擇 Chatbox 作為前端調(diào)用 vLLM 運行的 gpt-oss-120b 模型,用于本地或在線與 AI 進行對話。
1.參考上期教程,局域網(wǎng)內(nèi)下載安裝 Chatbox Windows 版本,點擊“設置提供方” — “添加”,輸入模型名稱,再次點擊“添加”。

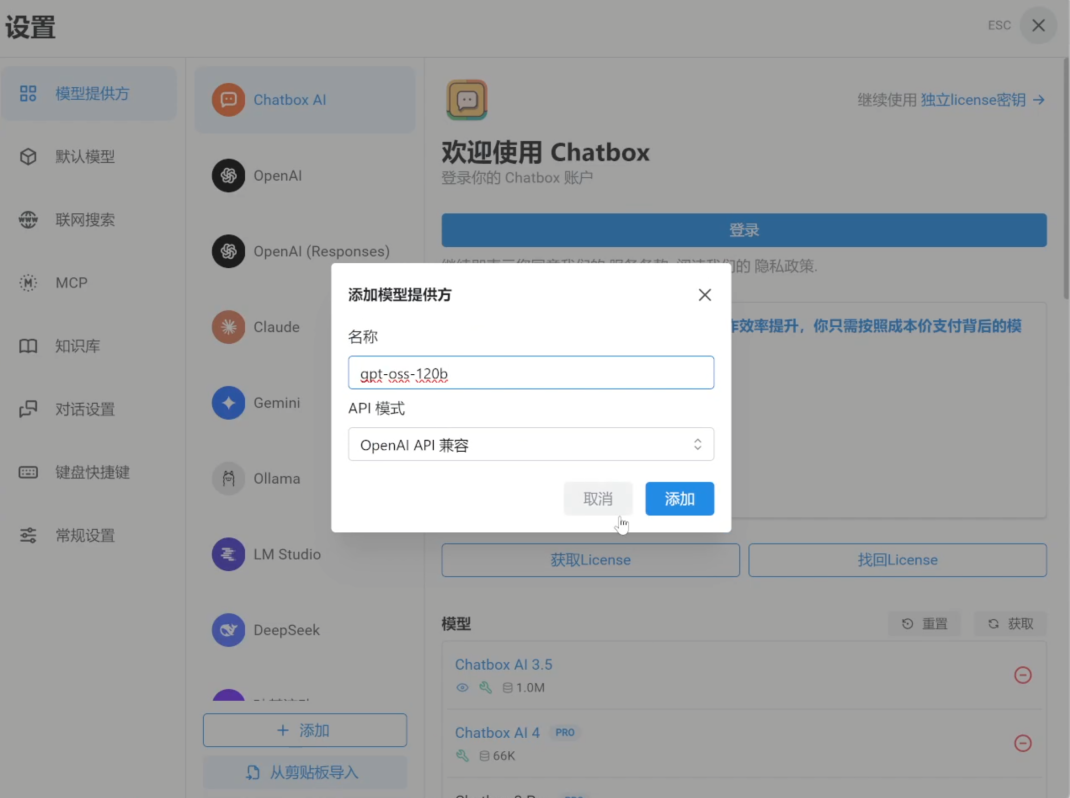
上下滑動查看圖片
2. API 主機可輸入 Jetson AGX Thor 主機 IP 以及 vLLM 服務端口號。
(例:http://192.168.23.107:8000)
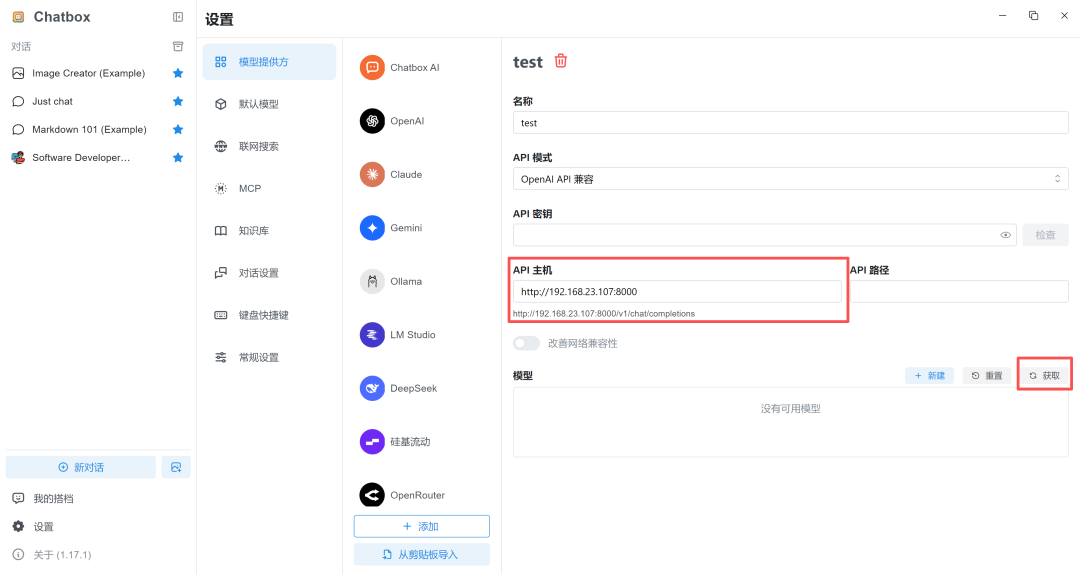
3. 選擇 vLLM 運行的模型,點擊“+”。
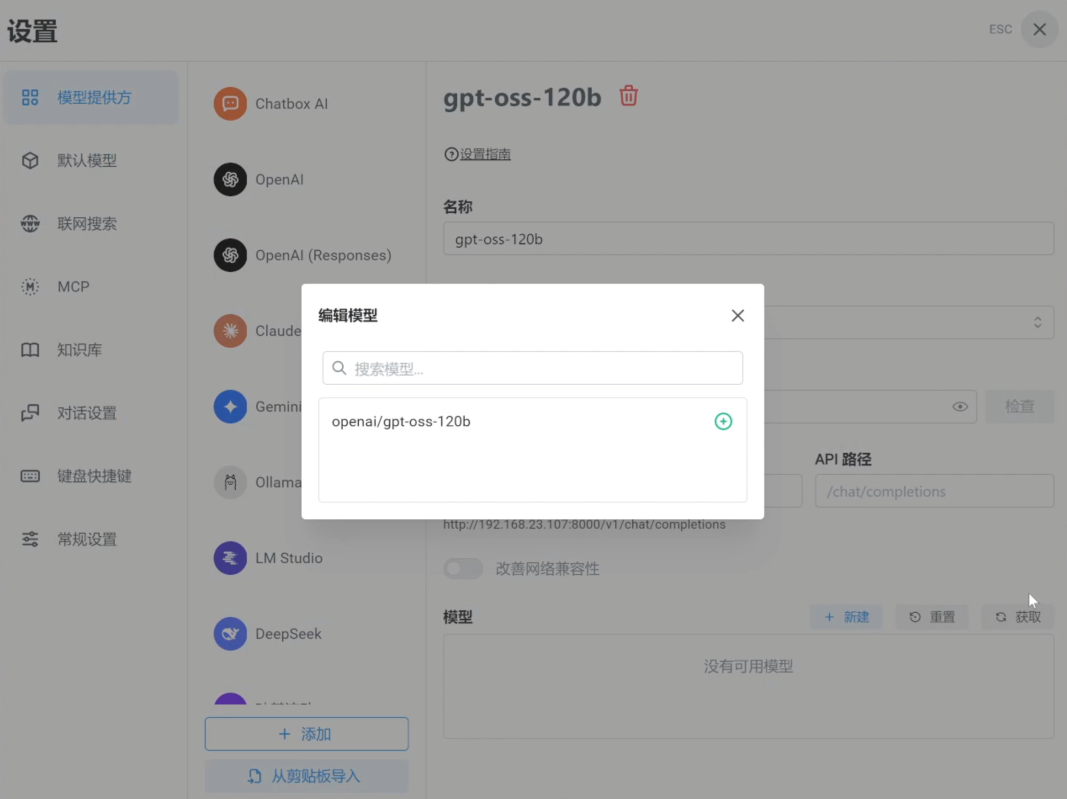
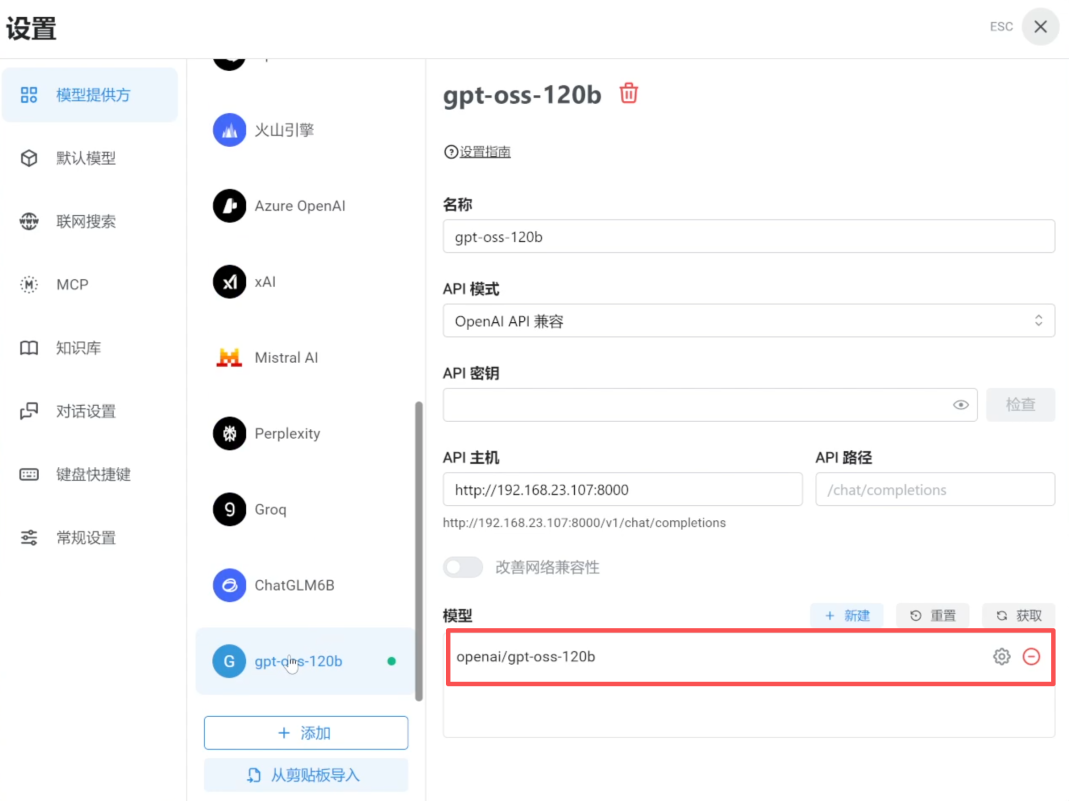
注:這里同樣可以添加前述步驟已保存或通過其他方式獲取的模型文件。
4. 點擊“新對話”,右下角選擇該模型即可開啟對話。
5. 運行示例
我們在此示例提問一個問題,運行結果如下:
以上視頻已作 3 倍加速處理
四、Jetson AGX Thor 模型運行資源占用及性能
接下來分析運行 gpt-oss-120b 時的資源使用情況。
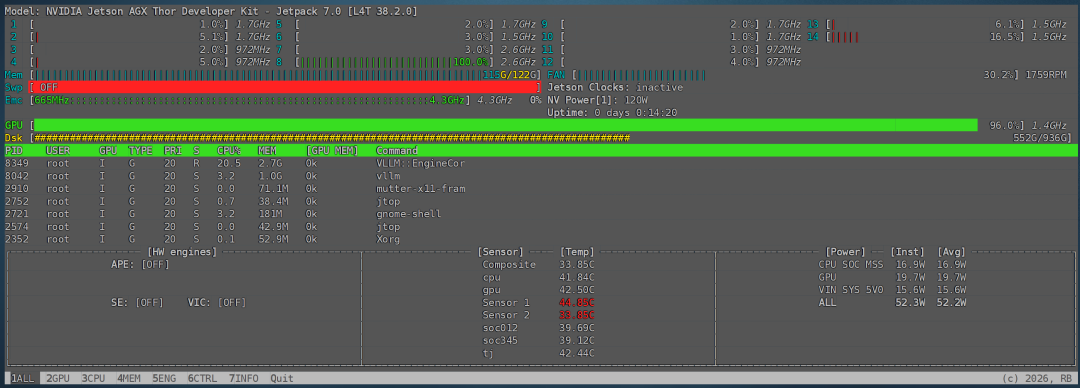
命令行執(zhí)行jtop命令,可見加載完模型后,內(nèi)存占用約為 115G。

當模型在進行推理任務時,部分 CPU 核心持續(xù)滿載,同時 GPU 使用率也維持在 95% 左右的高位。
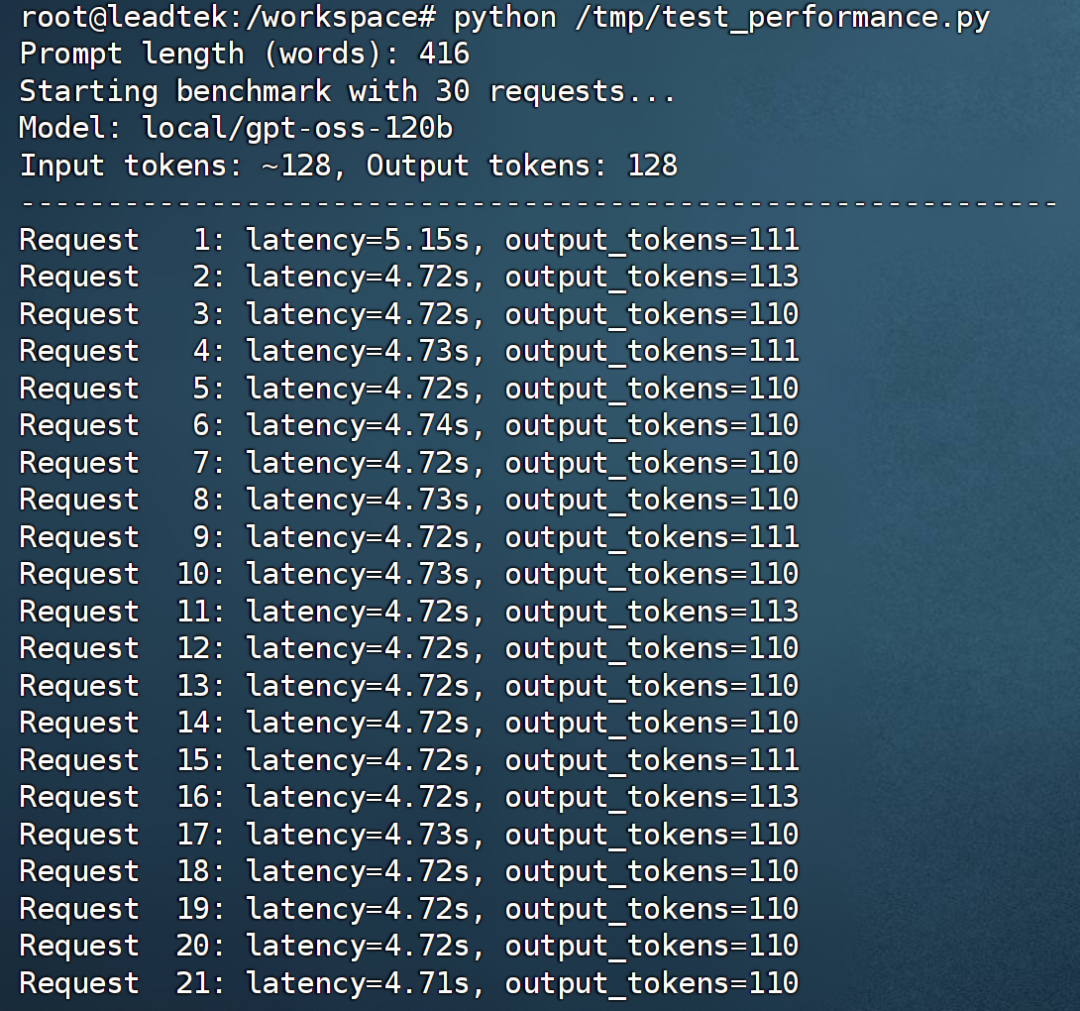
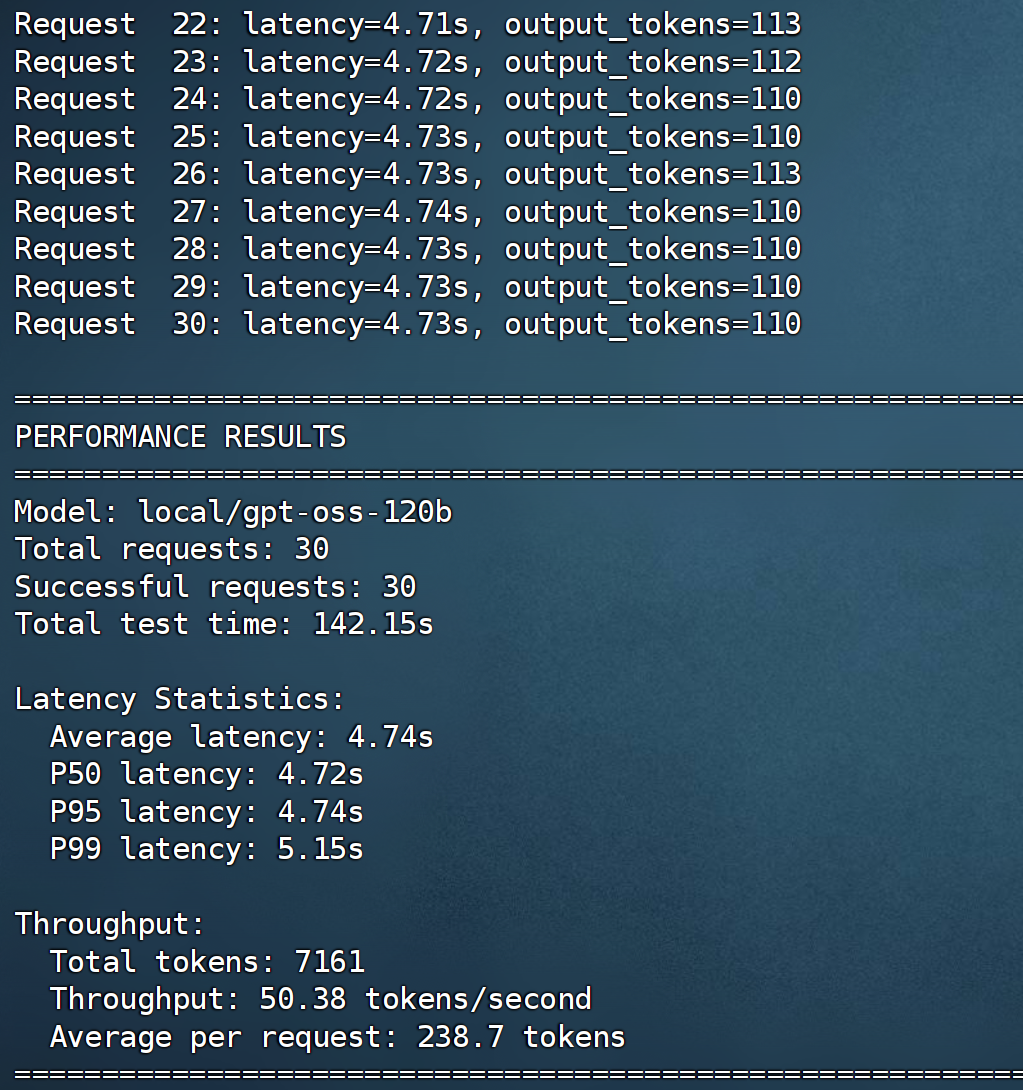
我們使用 AI 生成的腳本,測試了輸入 128 tokens、輸出 128 tokens 且并發(fā)數(shù)為 1 時的吞吐量。
容器內(nèi)執(zhí)行:
# 創(chuàng)建測試腳本 cat > /tmp/test_performance.py <
滑動查看完整代碼
命令行執(zhí)行:
python /tmp/test_performance.py
根據(jù)上圖的測試結果,在單用戶、輸入 / 輸出長度為 128 tokens、并發(fā)數(shù)為 1 的條件下,系統(tǒng)吞吐量達到了50.38 tokens / second。這意味著在 Jetson AGX Thor 上能夠流暢運行 1,200 億參數(shù)模型。
-
NVIDIA
+關注
關注
14文章
5661瀏覽量
109936 -
gpu
+關注
關注
28文章
5223瀏覽量
135772 -
AI
+關注
關注
91文章
40309瀏覽量
301885 -
大模型
+關注
關注
2文章
3691瀏覽量
5215
原文標題:邊緣 AI 實力驗證:NVIDIA Jetson AGX Thor 成功駕馭 1200 億參數(shù)大模型
文章出處:【微信號:Leadtek,微信公眾號:麗臺科技】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
NVIDIA Jetson AGX Thor Developer Kit開發(fā)環(huán)境配置指南
如何在NVIDIA Jetson AGX Thor上通過Docker高效部署vLLM推理服務

京東和美團已選用NVIDIA Jetson AGX Xavier 平臺
Arm方案 基于Arm架構的邊緣側設備(樹莓派或 NVIDIA Jetson Nano)上部署PyTorch模型
NVIDIA Jetson的相關資料分享
怎么做才能通過Jetson Xavier AGX構建android圖像呢?
NVIDIA Jetson AGX Orin提升邊緣AI標桿
NVIDIA 推出 Jetson AGX Orin 工業(yè)級模塊助力邊緣 AI
利用 NVIDIA Jetson 實現(xiàn)生成式 AI
NVIDIA Jetson AGX Thor開發(fā)者套件概述
基于 NVIDIA Blackwell 的 Jetson Thor 現(xiàn)已發(fā)售,加速通用機器人時代的到來

NVIDIA Jetson AGX Thor開發(fā)者套件重磅發(fā)布
通過NVIDIA Jetson AGX Thor實現(xiàn)7倍生成式AI性能
NVIDIA Jetson系列開發(fā)者套件助力打造面向未來的智能機器人
NVIDIA Jetson模型賦能AI在邊緣端落地




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論