 如何在NVIDIA Jetson Thor上提升機器人感知效率
如何在NVIDIA Jetson Thor上提升機器人感知效率

借助 NVIDIA 視覺編程接口庫(VPI),您可以更有效地利用 Jetson Thor 的計算性能。
構建自主機器人需要具備可靠且低延遲的視覺感知能力,以實現在動態環境中的深度估計、障礙物識別、定位與導航。這些功能對計算性能有較高要求。NVIDIA Jetson平臺雖為深度學習提供了強大的GPU支持,但隨著AI模型復雜性的提升以及對實時性能的更高需求,GPU可能面臨過載風險。若將所有感知任務完全依賴GPU執行,不僅容易造成性能瓶頸,還可能導致功耗上升和散熱壓力加劇,這在功耗受限且散熱條件有限的移動機器人應用中尤為突出。
為解決上述挑戰,NVIDIA Jetson平臺將高性能GPU與專用硬件加速器相結合。Jetson AGX Orin和Jetson Thor等平臺均配備專用硬件加速器,專為高效執行圖像處理和計算機視覺任務而設計,從而釋放GPU資源,使其能夠專注于處理更復雜的深度學習工作負載。NVIDIA視覺編程接口(VPI)進一步充分激活了不同類型硬件加速器的性能潛力。
在本博客中,我們將探討使用這些加速器的優勢,并詳細介紹開發者如何通過VPI充分發揮Jetson平臺的性能潛力。作為示例,我們將展示如何運用這些加速器開發一個用于立體視差的低延遲、低功耗的感知應用。首先,我們將構建單路立體攝像頭的工作流,隨后擴展至多流工作流,在Thor T5000上支持8路立體攝像頭同時以30 FPS運行,其性能相較Orin AGX 64 GB提升至10倍。
在開始開發之前,讓我們快速了解Jetson平臺提供的各類加速器,它們的優勢所在,能夠支持哪些應用場景,以及VPI如何為開發提供助力。
除了GPU之外,Jetson還配備了哪些其他加速器?
Jetson設備配備了強大的GPU,適用于深度學習任務,但隨著AI復雜性的提升,對GPU資源的高效管理變得愈發重要。Jetson為計算機視覺(CV)工作負載提供了專用的硬件加速引擎。這些引擎與GPU協同工作,在保持靈活性的同時,顯著提升了計算效率。通過VPI,開發者可以更便捷地訪問這些硬件資源,簡化實驗流程并實現高效的負載分配。
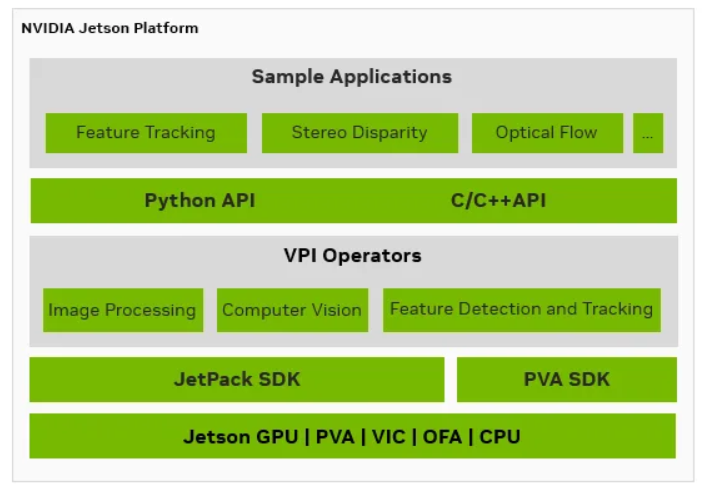
圖1:面向Jetson開發者的視覺編程接口(VPI)
下面我們逐一深入了解每個加速器,以及其用途與優勢。
可編程視覺加速器(PVA):
PVA是一款可編程的數字信號處理(DSP)引擎,配備超過1024位的單指令多數據(SIMD)單元,以及支持靈活直接內存訪問(DMA)的本地內存,專為視覺和圖像處理任務優化,具備出色的每瓦性能。它能夠與CPU、GPU及其他加速器異步運行,除NVIDIA Jetson Nano外,其他所有Jetson平臺均配備該加速器。
通過VPI,開發者可以調用現成的算法,如AprilTag檢測、物體追蹤,和立體視差估計。對于需要自定義算法的場景,Jetson開發者現在還可使用PVA SDK,該SDK提供了C/C++ API及相關工具,支持直接在PVA上開發視覺算法。
光流加速器(OFA):
OFA是一種固定功能的硬件加速器,用于基于立體攝像頭對的數據,計算光流和立體視差。OFA支持兩種工作模式:在視差模式下,通過處理立體攝像頭的左右校正圖像來生成視差圖;在光流模式下,則用于估算連續兩幀之間的二維運動矢量。
視頻和圖像合成器(VIC):
VIC是Jetson設備中的一種專用硬件加速器,具備固定功能,能夠高效節能地處理圖像縮放、重映射、扭曲、色彩空間轉換和降噪等基礎圖像處理任務。
哪些用例可以從這些加速器中獲益?
在某些場景下,開發者可能會考慮采用GPU以外的解決方案,以更好地滿足特定應用的需求。
GPU資源過載應用:為實現高效運行,開發者應優先將深度學習(DL)工作負載分配給GPU,同時利用VPI將計算機視覺任務卸載至PVA、OFA或VIC等專用加速器。例如,DeepStream的Multi+ Object Tracker在Orin AGX平臺上若僅依賴GPU,可處理12路視頻流;而通過引入PVA實現負載均衡后,支持的視頻流數量可提升至16路。
功耗敏感型應用:在哨兵模式(sentry mode)或持續監控等場景中,將主要計算任務轉移至低功耗加速器(如PVA、OFA、VIC),有助于顯著提升效率。
存在熱限制的工業應用:在高溫運行環境下,合理分配任務至各類加速器可有效降低GPU負載,減少因過熱導致的性能節流,從而在限定的熱預算內維持穩定的延遲與吞吐表現。
如何使用VPI解鎖所有加速器
VPI提供了一個統一且靈活的框架,使開發者能夠在Jetson模組、工作站或配備獨立GPU的PC等不同平臺上無縫訪問加速器。
現在,我們來看一個綜合運用上述內容的示例。
示例:立體視覺工作流
現代機器人系統通常采用被動立體視覺技術實現對周圍環境的三維感知。因此,計算立體視差圖成為構建復雜感知系統的關鍵環節。本文將介紹一個示例流程,幫助開發者生成立體視差圖及其對應的置信度圖。同時,我們將展示如何利用VPI提供的各類加速器,構建低延遲、高能效的處理工作流。
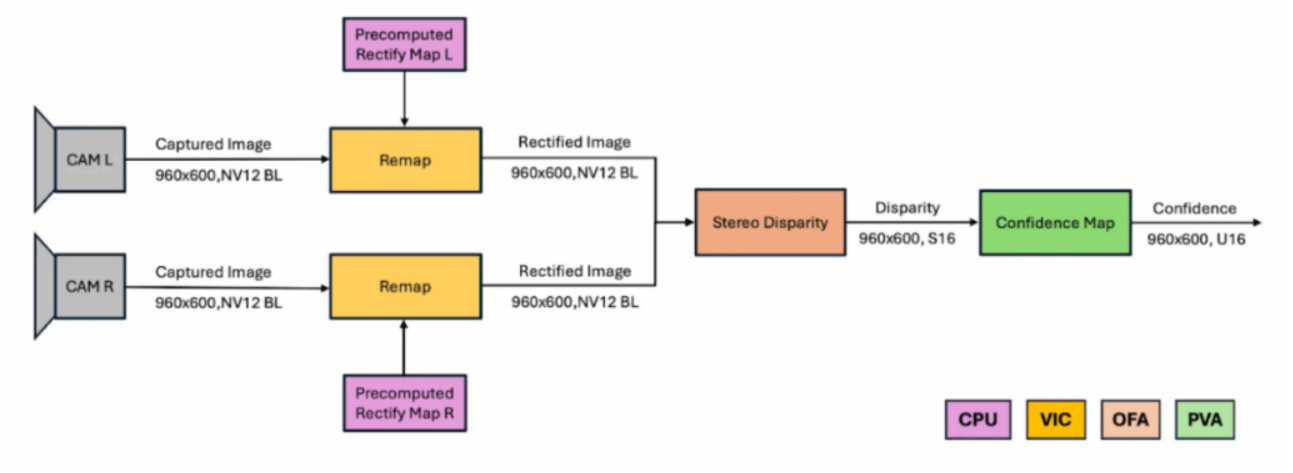
圖2:在Jetson多加速器上部署的立體視覺流程示意圖。PVA+:可編程視覺陣列;VIC:視頻與圖像合成器;OFA:光流加速器。
在CPU上進行預處理:預處理步驟可以在CPU上運行,因為它只發生一次。該步驟計算一個校正映射(rectification map),用于糾正立體相機幀中的鏡頭畸變。
在VIC上進行重映射:這一步驟使用預計算的校正映射對相機幀去畸變并對齊,確保兩條光軸水平且平行。VPI支持多項式與魚眼畸變模型,并允許開發者定義自定義warp映射。更多細節可參考Remap文檔。
在OFA上計算立體視差:校正后的圖像對作為半全局匹配(SGM)算法的輸入。在實際應用中,SGM可能會產生噪聲或錯誤的視差值。通過生成置信度圖,可以剔除低置信度的視差估計,從而提升結果質量。有關SGM算法及其支持參數的更多信息,請參閱立體視差文檔。
在PVA上生成置信度圖:VPI提供三種置信度圖模式:絕對值(Absolute)、相對值(Relative)和推理(Inference)。絕對值和相對值模式需要兩個OFA通道(左/右視差)并結合PVA的交叉檢查機制;而推理模式僅需一個OFA通道,并在PVA上運行一個輕量級CNN(包含兩個卷積層和兩個非線性激活層)。跳過置信度計算雖然速度較快,但會產生噪聲視差圖;相比之下,采用相對值或推理模式可顯著提升視差結果的精度與可靠性。
VPI的統一內存架構避免了跨引擎的不必要數據復制,其異步流與事件機制使開發者能夠提前規劃任務負載和同步點。由硬件管理的調度支持跨引擎并行執行,既釋放了CPU資源,又通過高效的流式流程設計避免了延遲。
使用VPI構建高性能立體視差工作流
開始使用Python API
本教程介紹如何使用VPI Python API實現基礎的立體視差工作流,且無需進行圖像重映射。
需要提前準備:
NVIDIA Jetson設備(例如Jetson AGX Thor)
通過NVIDIA SDK Manager或apt安裝VPI
Python庫:vpi、numpy、Pillow、opencv-python
在本教程中,我們將:
加載左右立體圖像
轉換圖像格式以適配處理需求
同步數據流,確保信息準備就緒
執行立體匹配算法以計算視差
對輸出結果進行后處理并保存
設置和初始化
第一步是導入所需的庫并創建VPIStream對象。VPIStream充當命令隊列,可用于提交任務以實現異步執行。為了演示并行處理,我們將使用兩個流。
import vpi import numpy as np from PIL import Image from argparse import ArgumentParser # Create two streams for parallel processing streamLeft = vpi.Stream() streamRight = vpi.Stream()
streamLeft用于處理左側圖像,streamRight用于處理右側圖像。
加載和轉換圖像
VPI的Python API可直接使用NumPy數組。我們首先通過Pillow加載圖像,然后利用VPI的asimage函數將其封裝為VPI圖像對象。接著,將圖像轉換為適用于立體匹配算法的格式。在本例中,圖像將從RGBA8格式轉換為Y8_ER_BL格式(即8位灰度、塊線性布局)。
# Load images and wrap them in VPI images left_img = np.asarray(Image.open(args.left)) right_img = np.asarray(Image.open(args.right)) left = vpi.asimage(left_img) right = vpi.asimage(right_img) # Convert images to Y8_ER_BL format in parallel on different backends left = left.convert(vpi.Format.Y8_ER_BL, scale=1, stream=streamLeft, backend=vpi.Backend.VIC) right = right.convert(vpi.Format.Y8_ER_BL, scale=1, stream=streamRight, backend=vpi.Backend.CUDA)
左側圖像通過streamLeft提交至VIC后端進行處理,右側圖像則通過streamRight提交給NVIDIA CUDA后端。這種設計使得兩項操作能夠在不同的硬件單元上并行執行,充分體現了VPI的核心優勢。
同步并執行立體差異
在執行立體差異計算之前,必須確保兩張圖像均已準備就緒。我們調用streamLeft.sync()來阻塞主線程,直至左側圖像的轉換完成。隨后,便可向streamRight提交vpi.stereodisp操作。
# Synchronize streamLeft to ensure the left image is ready streamLeft.sync() # Submit the stereo disparity operation on streamRight disparityS16 = vpi.stereodisp(left, right, backend=vpi.Backend.OFA|vpi.Backend.PVA|vpi.Backend.VIC, stream=streamRight)
立體差異算法在VPI后端(OFA、PVA、VIC)的組合上運行,以充分利用專用硬件,最終生成一張S16格式的差異圖,用于表示兩幅圖像中對應像素之間的水平偏移。
后處理和可視化
對原始差異圖進行后處理以實現可視化時,將Q10.5定點格式表示的差異值縮放到0-255范圍內并保存。
# Post-process the disparity map
# Convert Q10.5 to U8 and scale for visualization
disparityU8 = disparityS16.convert(vpi.Format.U8, scale=255.0/(32*128), stream=streamRight, backend=vpi.Backend.CUDA)
# make accessible in cpu
disparityU8 = disparityU8.cpu()
#save with pillow
d_pil = Image.fromarray(disparityU8)
d_pil.save('./disparity.png')
最后一步是將原始數據轉換為人類可讀的圖像,其中灰度值代表深度信息。
使用C++ API的多流差異工作流
先進的機器人技術依賴于高吞吐量,而VPI通過并行多流傳輸實現了這一需求。憑借簡潔的API與硬件加速器的高效結合,VPI使開發者能夠構建快速且可靠的視覺處理流程——與波士頓動力(Boston Dynamics)新一代機器人系統的處理流程相似。
VPI采用VPIStream對象,這些對象作為先進先出(FIFO)的命令隊列,可異步地向后端提交任務,從而實現不同硬件單元上的并行運算執行(異步流)。
對于任務關鍵、追求極致性能的應用,VPI的C++ API是理想之選。
以下代碼片段源自C++基準測試,用于演示多流立體視差工作流的構建與執行過程。該示例通過SimpleMultiStreamBenchmarkC++應用實現:首先預生成合成的NV12_BL格式圖像,以消除運行時生成數據帶來的開銷;隨后并行處理多個數據流,并測量每秒幀數(FPS)以評估吞吐性能。此外,該工具支持保存輸入圖像以及差異圖和置信度圖,便于調試分析。通過預生成數據的方式,本示例可有效模擬高速實時工作負載場景。
資源配置、對象聲明與初始化
我們首先聲明并初始化VPI中執行該流水線所需的全部對象,包括創建流、輸入/輸出圖像以及立體視覺處理所需的有效載荷。由于立體算法的輸入圖像格式為NV12_BL,因此我們將其與Y8_Er圖像類型一同設置為中間格式轉換的格式。
int totalIterations = itersPerStream * numStreams; std::vectorleftInputs(numStreams), rightInputs(numStreams), confidences(numStreams), leftTmps(numStreams), rightTmps(numStreams); std::vector leftOuts(numStreams), rightOuts(numStreams), disparities(numStreams); std::vector stereoPayloads(numStreams); std::vector streamsLeft(numStreams), streamsRight(numStreams); std::vector events(numStreams); int width = cvImageLeft.cols; int height = cvImageLeft.rows; int vic_pva_ofa = VPI_BACKEND_VIC | VPI_BACKEND_OFA | VPI_BACKEND_PVA; VPIStereoDisparityEstimatorCreationParams stereoPayloadParams; VPIStereoDisparityEstimatorParams stereoParams; CHECK_STATUS(vpiInitStereoDisparityEstimatorCreationParams(&stereoPayloadParams)); CHECK_STATUS(vpiInitStereoDisparityEstimatorParams(&stereoParams)); stereoPayloadParams.maxDisparity = 128; stereoParams.maxDisparity= 128; stereoParams.confidenceType = VPI_STEREO_CONFIDENCE_RELATIVE; for (int i = 0; i < numStreams; i++) { CHECK_STATUS(vpiImageCreateWrapperOpenCVMat(cvImageLeft, 0, &leftInputs[i])); CHECK_STATUS(vpiImageCreateWrapperOpenCVMat(cvImageRight, 0, &rightInputs[i])); CHECK_STATUS(vpiStreamCreate(0, &streamsLeft[i])); CHECK_STATUS(vpiStreamCreate(0, &streamsRight[i])); CHECK_STATUS(vpiImageCreate(width, height, VPI_IMAGE_FORMAT_Y8_ER, 0, &leftTmps[i])); CHECK_STATUS(vpiImageCreate(width, height, VPI_IMAGE_FORMAT_NV12_BL, 0, &leftOuts[i])); CHECK_STATUS(vpiImageCreate(width, height, VPI_IMAGE_FORMAT_Y8_ER, 0, &rightTmps[i])); CHECK_STATUS(vpiImageCreate(width, height, VPI_IMAGE_FORMAT_NV12_BL, 0, &rightOuts[i])); CHECK_STATUS(vpiCreateStereoDisparityEstimator(vic_pva_ofa, width, height, VPI_IMAGE_FORMAT_NV12_BL, &stereoPayloadParams, &stereoPayloads[i])); CHECK_STATUS(vpiEventCreate(0, &events[i])); } int outCount = saveOutput ? (numStreams * itersPerStream) : numStreams; disparities.resize(outCount); confidences.resize(outCount); for (int i = 0; i < outCount; i++) { CHECK_STATUS(vpiImageCreate(width, height, VPI_IMAGE_FORMAT_S16, 0, &disparities[i])); CHECK_STATUS(vpiImageCreate(width, height, VPI_IMAGE_FORMAT_U16, 0, &confidences[i])); }
轉換圖像格式
我們使用VPI的C API為每個流提交圖像轉換操作,將來自攝像頭的NV12_BL輸入模擬幀進行格式轉換。
for (int i = 0; i < numStreams; i++)
{
CHECK_STATUS(vpiSubmitConvertImageFormat(streamsLeft[i], VPI_BACKEND_CPU, leftInputs[i], leftTmps[i], NULL));
CHECK_STATUS(vpiSubmitConvertImageFormat(streamsLeft[i], VPI_BACKEND_VIC, leftTmps[i], leftOuts[i], NULL));
CHECK_STATUS(vpiEventRecord(events[i], streamsLeft[i]));
CHECK_STATUS(vpiSubmitConvertImageFormat(streamsRight[i], VPI_BACKEND_CPU, rightInputs[i], rightTmps[i], NULL));
CHECK_STATUS(vpiSubmitConvertImageFormat(streamsRight[i], VPI_BACKEND_VIC, rightTmps[i], rightOuts[i], NULL));
CHECK_STATUS(vpiStreamWaitEvent(streamsRight[i], events[i]));
}
for (int i = 0; i < numStreams; i++)
{
CHECK_STATUS(vpiStreamSync(streamsLeft[i]));
CHECK_STATUS(vpiStreamSync(streamsRight[i]));
}
我們將操作分別提交到兩個獨立流的不同硬件上,具體類型由輸入/輸出圖像的類型推斷得出。此次,我們還將在左側流完成轉換操作后記錄一個VPIEvent。VPIEvent是一種VPI對象,能夠在流錄制過程中等待另一個流完成所有操作。通過這種方式,我們可以讓右側流等待左側流的轉換操作完成,而無需阻塞調用線程(即主線程),從而實現多個左側流與右側流的并行執行。
同步并執行立體差異
我們通過VPI的C API提交立體匹配計算任務,并使用std::chrono對其性能進行基準測試。
auto benchmarkStart = std::chrono::high_resolution_clock::now();
for (int iter = 0; iter < itersPerStream; iter++)
{
for (int i = 0; i < numStreams; i++)
{
int dispIdx = saveOutput ? (i * itersPerStream + iter) : i;
CHECK_STATUS(vpiSubmitStereoDisparityEstimator(streamsRight[i], vic_pva_ofa, stereoPayloads[i], leftOuts[i],
rightOuts[i], disparities[dispIdx], confidences[dispIdx],
&stereoParams));
}
}
// ====================
// End Benchmarking
for (int i = 0; i < numStreams; i++)
{
CHECK_STATUS(vpiStreamSync(streamsRight[i]));
}
auto benchmarkEnd = std::chrono::high_resolution_clock::now();
我們繼續使用confidenceMap提交計算任務,并生成結果差異圖。同時,停止基準測試計時器,記錄轉換和生成差異所耗的時間。在向所有流提交任務后,顯式同步各個流,以確保調用線程在提交過程中不會被阻塞。
后處理和清理
我們利用VPI的C API與OpenCV的互操作性對差異圖進行后處理,并在每次迭代循環中將其保存。可根據需要選擇保留輸出數據以供檢查,循環結束后再清理相關對象。
// ====================
// Save Outputs
if (saveOutput)
{
for (int i = 0; i < numStreams * itersPerStream; i++)
{
VPIImageData dispData, confData;
cv::Mat cvDisparity, cvDisparityColor, cvConfidence, cvMask;
CHECK_STATUS(
vpiImageLockData(disparities[i], VPI_LOCK_READ, VPI_IMAGE_BUFFER_HOST_PITCH_LINEAR, &dispData));
vpiImageDataExportOpenCVMat(dispData, &cvDisparity);
cvDisparity.convertTo(cvDisparity, CV_8UC1, 255.0 / (32 * stereoParams.maxDisparity), 0);
applyColorMap(cvDisparity, cvDisparityColor, cv::COLORMAP_JET);
CHECK_STATUS(vpiImageUnlock(disparities[i]));
std::ostringstream fpStream;
fpStream << "stream_" << i / itersPerStream << "_iter_" << i % itersPerStream << "_disparity.png";
imwrite(fpStream.str(), cvDisparityColor);
// Confidence output (U16 -> scale to 8-bit and save)
CHECK_STATUS(
vpiImageLockData(confidences[i], VPI_LOCK_READ, VPI_IMAGE_BUFFER_HOST_PITCH_LINEAR, &confData));
vpiImageDataExportOpenCVMat(confData, &cvConfidence);
cvConfidence.convertTo(cvConfidence, CV_8UC1, 255.0 / 65535.0, 0);
CHECK_STATUS(vpiImageUnlock(confidences[i]));
std::ostringstream fpStreamConf;
fpStreamConf << "stream_" << i / itersPerStream << "_iter_" << i % itersPerStream << "_confidence.png";
imwrite(fpStreamConf.str(), cvConfidence);
}
}
// ====================
// Clean Up VPI Objects
for (int i = 0; i < numStreams; i++)
{
CHECK_STATUS(vpiStreamSync(streamsLeft[i]));
CHECK_STATUS(vpiStreamSync(streamsRight[i]));
vpiStreamDestroy(streamsLeft[i]);
vpiStreamDestroy(streamsRight[i]);
vpiImageDestroy(rightInputs[i]);
vpiImageDestroy(leftInputs[i]);
vpiImageDestroy(leftTmps[i]);
vpiImageDestroy(leftOuts[i]);
vpiImageDestroy(rightTmps[i]);
vpiImageDestroy(rightOuts[i]);
vpiPayloadDestroy(stereoPayloads[i]);
vpiEventDestroy(events[i]);
}
// Destroy all disparity and confidence images
for (int i = 0; i < (int)disparities.size(); i++)
{
vpiImageDestroy(disparities[i]);
}
for (int i = 0; i < (int)confidences.size(); i++)
{
vpiImageDestroy(confidences[i]);
}
收集基準測試結果
我們現在能夠收集并展示基準測試的結果。
double totalTimeSeconds = totalTime / 1000000.0; double avgTimePerFrame = totalTimeSeconds / totalIterations; double throughputFPS= totalIterations / totalTimeSeconds; std::cout << "\n" << std::string(70, '=') << std::endl; std::cout << "SIMPLE MULTI-STREAM RESULTS" << std::endl; std::cout << std::string(70, '=') << std::endl; std::cout << "Input: RGB8 -> Y8_BL_ER" << std::endl; std::cout << "Total time: " << totalTimeSeconds << " seconds" << std::endl; std::cout << "Avg time per frame: " << (avgTimePerFrame * 1000) << " ms" << std::endl; std::cout << "THROUGHPUT: " << throughputFPS << " FPS" << std::endl; std::cout << std::string(70, '=') << std::endl; std::cout << "THROUGHPUT: " << throughputFPS << " FPS" << std::endl; std::cout << std::string(70, '=') << std::endl;
查看結果
在圖像分辨率為960 × 600、最大視差為128的條件下,該方案在Thor T5000上以30 FPS的幀率運行立體視差估計,同時支持8個并行數據流(包括置信度圖),且無需占用GPU資源。在MAX_N功耗模式下,其性能相比Orin AGX 64 GB提升至10倍。具體性能數據如表1所示。
| 立體視差全工作流(相對模式,分辨率:960 × 600,最大差異:128)的幀率(FPS)加速比隨流數量變化情況:Orin AGX(64 GB)、Jetson Thor、T5000分別達到122、122.5、212、111.9、54.6、58.9、78.3、299.7。 | |||
| 幀率(FPS) | 加速比 | ||
| 流數量 | Orin AGX(64 GB) | Jetson Thor T5000 | |
| 1 | 22 | 122 | 5.5 |
| 2 | 12 | 111 | 9.5 |
| 4 | 6 | 58 | 9.7 |
| 8 | 3 | 29 | 9.7 |
表1:Orin AGX與Thor T5000在RELATIVE模式下,立體視差處理流程的對比
波士頓動力如何使用VPI
作為Jetson平臺的深度用戶,波士頓動力借助視覺編程接口(VPI)來加速其感知系統的處理流程。
VPI支持無縫訪問Jetson的專用硬件加速器,提供一系列優化的視覺算法(如AprilTags和SGM立體匹配),以及ORB、Harris Corner、Pyramidal LK等特征檢測器,和由OFA加速的光流計算。這些技術構成了波士頓動力感知系統的核心,可通過負載均衡同時支撐原型驗證與系統優化。通過采用VPI,工程師能夠快速適配硬件更新,顯著縮短從開發到實現價值的周期。
要點總結
Jetson Thor平臺以及VPI等庫在硬件功能上的進步,使開發者能夠為邊緣端機器人設計出高效且低延遲的解決方案。
通過充分發揮Jetson平臺上各款可用加速器的獨特優勢,像波士頓動力這樣的機器人公司能夠實現高效且可擴展的復雜視覺處理,從而推動智能自主機器人在多種現實應用場景中的落地與發展。
關于作者
Chintan Intwala 是 NVIDIA 核心計算機視覺產品管理團隊的成員,專注于構建 AI 賦能的云技術,為各行各業的大型計算機視覺開發者提供支持。在加入 NVIDIA 之前,Chintan 曾在 Adobe 工作,專注于構建 AI/ML 和 AR/Camera 產品及功能。他擁有麻省理工學院斯隆分校 (MIT Sloan) 的 MBA 學位,并已獲得超過 25 項美國專利。
Jonas Toelke 是 NVIDIA 核心計算機視覺團隊的一員,領導的團隊專注于構建經過優化的計算機視覺產品,為各行各業的 TegraSoC 提供支持。加入 NVIDIA 之前,Jonas 曾就職于 Halliburton,專注于構建 AI/ ML 應用以解決石油物理問題。他擁有慕尼黑理工大學工程學博士學位,并已獲得 20 項專利。
Colin Tracey 是 NVIDIA 的高級系統軟件工程師。他在 Jetson 和 DRIVE 平臺的嵌入式計算機視覺庫和 SDK 上工作。
Arjun Verma 是 NVIDIA 的系統軟件工程師,也是 NVIDIA 嵌入式設備計算機視覺產品的核心開發者。Arjun 最近剛從佐治亞理工學院獲得機器學習碩士學位。
-
機器人
+關注
關注
213文章
31217瀏覽量
222996 -
接口
+關注
關注
33文章
9553瀏覽量
157335 -
加速器
+關注
關注
2文章
839瀏覽量
40165 -
NVIDIA
+關注
關注
14文章
5662瀏覽量
109952 -
gpu
+關注
關注
28文章
5227瀏覽量
135799
原文標題:在 NVIDIA Jetson Thor 上提升機器人感知效率
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
NVIDIA Jetson AGX Thor Developer Kit開發環境配置指南
如何在NVIDIA Jetson AGX Thor上通過Docker高效部署vLLM推理服務

如何在NVIDIA Jetson AGX Thor上部署1200億參數大模型

NVIDIA Jetson的相關資料分享
基于 NVIDIA Jetson 使用硬件在環設計機器人
NVIDIA Jetson還能讓AI驅動維修機器人?
使用NVIDIA Jetson打造機器人導盲犬
NVIDIA Jetson + Isaac SDK 在人形機器人領域的方案詳解
NVIDIA Jetson + Isaac SDK 人形機器人方案全面解析
基于 NVIDIA Blackwell 的 Jetson Thor 現已發售,加速通用機器人時代的到來




 工商網監
工商網監
評論