、伙伴及開發者提供更好的服務。昇騰AI云服務單集群提供2000P Flops算力,千卡訓練30天長穩率達到90%,為業界提供穩定可靠的AI算力,讓大模型觸手可及。
2023-07-07 17:39:56 2946
2946 
的支持。蓬勃發展的大模型應用所帶來的特殊性需求,正推動芯片設計行業邁向新紀元。眾多頂級的半導體廠商紛紛為大模型應用而專門構建 AI 芯片,其高算力、高帶寬、動輒千億的晶體管數量成為大芯片的標配。 芯片設計復雜度,邁向新高峰 在人工
2023-08-15 11:02:111990 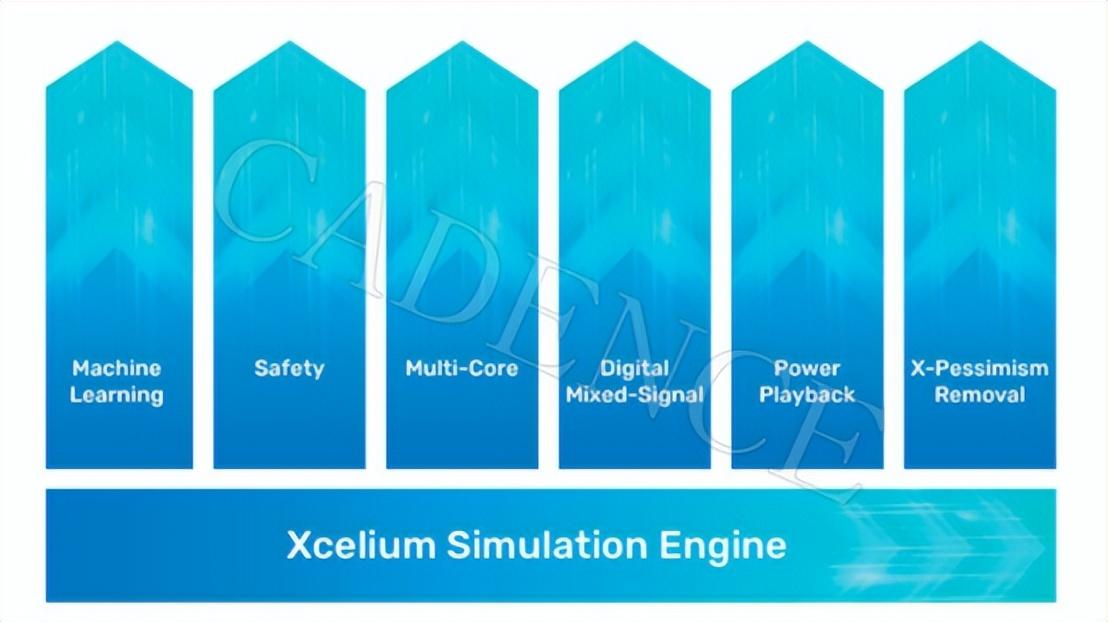
GPUStack 是一個用于運行 AI 模型的開源 GPU 集群管理器。它具有廣泛的硬件兼容性,支持多種品牌的 GPU,并能在 Apple MacBook、Windows PC 和 Linux 服務器上運行
2025-06-06 11:45:312292 
NVIDIA與Arm、Ampere、Cray、富士通、HPE、Marvell攜手構建GPU加速服務器,以滿足從超大規模云到邊緣、從模擬到AI、從高性能存儲到百萬兆級超級計算等多樣化需求。
2019-11-20 09:38:421911 NVIDIA NeMo Megatron 框架; 可定制的大規模語言模型 Megatron 530B;多GPU、多節點 Triton推理服務器助力基于語言的AI開發和部署,推動行業和科學發展。
2021-11-10 14:22:521160 電子發燒友網報道(文/李彎彎)近一年多時間,隨著大模型的發展,GPU在AI領域的重要性再次凸顯。雖然相比英偉達等國際大廠,國產GPU起步較晚、聲勢較小。不過近幾年,國內不少GPU廠商成長非常快,并且
2024-04-01 09:28:266086 
? 電子發燒友網報道(文/李彎彎)萬卡集群是指由一萬張及以上的加速卡(包括GPU、TPU及其他專用AI加速芯片)組成的高性能計算系統,主要用于加速人工智能模型的訓練和推理過程。這種集群的構建旨在
2024-06-02 06:18:006683 
STM32可以跑AI,這個AI模型怎么搞,知識盲區
2025-10-14 07:14:27
摘要: 3月28日,在2018云棲大會·深圳峰會上,阿里云宣布與英偉達GPU 云 合作 (NGC),開發者可以在云市場下載NVIDIA GPU 云鏡像和運行NGC 容器,來使用阿里云上的NVIDIA
2018-04-04 14:39:24
AI算法中比較常用的模型都有什么
2022-08-27 09:19:06
GPU編程--OpenCL四大模型
2019-04-29 07:40:44
ai芯片和gpu的區別▌車載芯片的發展趨勢(CPU-GPU-FPGA-ASIC)過去汽車電子芯片以與傳感器一一對應的電子控制單元(ECU)為主,主要分布與發動機等核心部件上。...
2021-07-27 07:29:46
集群通信網絡是什么?數字集群移動通信網絡是如何運行的?
2021-05-26 06:27:08
限制算力提升的瓶頸。800G光模塊通過更高的傳輸速率,能夠支持大規模GPU集群間的數據傳輸,保證各節點之間的快速互聯和低延遲通信,從而提升整個系統的計算效率與吞吐量。對于DeepSeek等超大模型
2025-03-25 12:00:18
上漲,因為事實表明,它們的 GPU 在訓練和運行 深度學習模型 方面效果明顯。實際上,英偉達也已經對自己的業務進行了轉型,之前它是一家純粹做 GPU 和游戲的公司,現在除了作為一家云 GPU 服務
2024-03-21 15:19:45
服務器,而隨著人們對服務器工作負載模式的新需求,越來越多的智能場景需要小型服務器來部署。方案簡介集群服務器解決方案,以多塊核心板的組合方式,提供標準的軟硬件接口,支持分布式AI運算,可用于機器學習
2019-08-16 15:09:56
Imagination全新BXS GPU助力德州儀器汽車處理器系列產品實現先進圖形處理功能
2020-12-16 07:04:43
Mali GPU 支持tensorflow或者caffe等深度學習模型嗎? 好像caffe2go和tensorflow lit可以部署到ARM,但不知道是否支持在GPU運行?我希望把訓練
2022-09-16 14:13:01
的模型在微控制器上平穩運行。這使我們能夠保持競爭力,并為客戶提供最佳解決方案。“多虧了 STM32Cube.AI 開發人員云,我們可以在很短的時間內確認我們創建具有嵌入式AI的產品的方法的有效性。通過
2023-02-02 09:52:43
使用cube-AI分析模型時報錯,該模型是pytorch的cnn轉化成onnx
```
Neural Network Tools for STM32AI v1.7.0 (STM.ai v8.0.0-19389)
INTERNAL ERROR: list index out of range
```
2024-05-27 07:15:58
模型收斂的情況下,最大集群規模只支持10塊GPU。這意味著在進行數據運算時,即時使用更多的GPU,計算效果也只相當于10塊GPU的能力,這樣訓練的時間將更加的漫長。 而華為云的深度學習
2018-08-02 20:44:09
Vitis AI 的所有工具和庫,而不需要在本地安裝任何依賴。CPU版本的Vitis AI docker 可以在沒有 GPU 的機器上運行,但是模型優化的速度會比 GPU 版本慢一些。
實際上,我會選擇通過
2023-10-14 15:34:26
算法的引擎GPU、GPU硬件架構剖析、GPU服務器的設計與實現、GPU集群的網絡設計與實現、GPU板卡級算力調度技術、基于云平臺的GPU集群的管理與運營等等:
翻閱部分章節,從GPU板卡到GPU服務器
2024-10-08 10:40:35
,本周將會推出針對異構計算GPU實例GN5年付5折的優惠活動,希望能夠打造良好的AI生態環境,幫助更多的人工智能企業以及項目順利上云。隨著深度學習對人工智能的巨大推動,深度學習所構建的多層神經網絡模型
2017-12-26 11:22:09
如何基于云原生技術為機器學習應用設計與實現更好的開發和運行平臺;第12章講解基于云平臺的GPU集群的管理與運營,涉及云運維平臺、云運營平臺和云審計平臺;第13章基于一個服務機器學習的GPU計算平臺落地
2024-08-16 18:33:51
問題最近在Ubuntu上使用Nvidia GPU訓練模型的時候,沒有問題,過一會再訓練出現非常卡頓,使用nvidia-smi查看發現,顯示GPU的風扇和電源報錯:解決方案自動風扇控制在nvidia
2022-01-03 08:24:09
在即將開展的“中國移動全球合作伙伴大會”上,華為將發布一款面向運營商電信領域的一站式AI開發平臺——SoftCOM AI平臺,幫助電信領域開發者解決AI開發在數據準備、模型訓練、模型發布以及部署驗證
2021-02-25 06:53:41
在 CPU 和 GPU 上運行OpenVINO? 2023.0 Benchmark_app推斷的 ONNX 模型。
在 CPU 上推理成功,但在 GPU 上失敗。
2025-03-06 08:02:41
用于快速模型的模型調試器是用于可擴展集群軟件開發的完全可重定目標的調試器。它旨在滿足SoC軟件開發人員的需求。
Model Debugger具有易于使用的GUI前端,并支持:
?源代碼級調試
2023-08-10 06:33:37
用于快速模型的模型調試器是用于可擴展集群軟件開發的完全可重定目標的調試器。它旨在滿足SoC軟件開發人員的需求。
Model Debugger具有易于使用的GUI前端,并支持:
?源代碼級調試
2023-08-09 07:57:45
18%。
智算中心建設:與國內AI獨角獸合作,提供支持液冷散熱的800G模塊集群,助力其大模型訓練效率提升30%。
邊緣計算網絡:在北美某5G運營商邊緣節點中,基于DML方案的SR8模塊實現90%空間
2025-08-13 19:05:00
引領AI時代網絡變革:睿海光電的核心競爭力
在AI時代,數據中心正經歷從傳統架構向AI工廠與AI云的轉型。AI工廠依賴超大規模GPU集群驅動大模型訓練,要求網絡具備超高帶寬與超低延遲;AI云則為多
2025-08-13 19:01:20
將AI推向邊緣的影響通過在邊緣運行ML模型可以使哪些具體的AI項目更容易運行?
2021-02-23 06:21:10
Mali T604 GPU的結構是由哪些部分組成的?Mali T604 GPU的編程特性有哪些?Mali GPU的并行化計算模型是怎樣構建的?基于Mali-T604 GPU的快速浮點矩陣乘法并行化該如何去實現?
2021-04-19 08:06:26
芯片的擴展,以滿足大規模AI模型的訓練和推理需求。
DGX SuperPOD配備智能控制平面,能夠監控數千個數據點,確保系統連續運行、數據完整性,并自動重新配置集群以避免停機。每個DGX GB200
2024-05-13 17:16:22
用于快速模型的模型調試器是用于可擴展集群軟件開發的完全可重定目標的調試器。它旨在滿足SoC軟件開發人員的需求。
Model Debugger具有易于使用的GUI前端,并支持:
?源代碼級調試
2023-08-08 06:28:56
數據中心依賴數千甚至上萬個GPU集群進行高性能計算,對帶寬、延遲和數據交換效率提出極高要求。
AI云:以生成式AI為核心的云平臺,為多租戶環境提供推理服務。這類數據中心要求網絡具備高帶寬、穩定性
2025-03-25 17:35:05
。 對于世界杯這種超大觀看量級、超強影響力的重要體育賽事,阿里云一直致力研究的AI技術一定不會缺席。本屆世界杯互聯網直播的順利進行,離不開各大云計算廠商的支持。在這其中,阿里云是當之無愧的“C位“,除了
2018-07-12 15:12:13
拷貝多份占用存儲空間,也給網絡管理和數據管理帶來了復雜性;并且由于數據無法共享,無法支持整個GPU集群同時運行任務,降低了整個IT系統的使用效率。為了便于數據管理和共享,傳統文件存儲在AI系統中得到一定
2018-08-23 17:39:35
群擴容和縮容。同云桌面/GPU服務器的結合 一般在仿真工作流里面,完成大量的仿真計算后會進入到渲染階段,所以一般會經過GPU服務器集群的Pipeline,最后通過云桌面展示給客戶的客戶。于是E-HPC
2018-05-18 22:19:53
作業在上汽仿真計算云平臺上完成,模擬了整車、發動機數百種工況。由于阿里云超級計算集群帶來的性能提升,相對本地集群節約了計算求解時間,用戶作業排隊時間也明顯縮短,工程師可以在工作時間段做更多的模型調整
2018-05-31 15:30:30
摘要: kubernetes集群讓您能夠方便的部署管理運維容器化的應用。但是實際情況中經常遇到的一些問題,就是單個集群通常無法跨單個云廠商的多個Region,更不用說支持跨跨域不同的云廠商。這樣會給
2018-03-12 17:10:52
摘要: 近日,阿里云重磅推出視頻點播新功能——視頻AI ,基于深度學習、計算機視覺技術和海量數據,為廣大用戶提供多場景的視頻AI服務。近日,阿里云重磅推出視頻點播新功能——視頻AI,基于深度學習
2018-01-23 15:19:23
針對機器故障下的煉鋼-連鑄重調度問題,建立基于動態約束滿足的重調度模型。對所建立的模型,提出基于粗重調度和斷澆修復的兩階段算法,源于實際生產數據的仿真實驗表明
2010-01-27 15:36:12 9
9 研究如何使用Jini 來實現集群網格計算環境,給出系統模型JCGE(a Jini-based cluster grid environment),設計一個在此模型上進行并行計算的通用算法,并在集群主機上對此模型及算法進行測試,
2011-05-14 11:05:4517 針對轉爐出鋼延遲的煉鋼連鑄重調度問題,以開工時間、加工時間以及加工機器的差異度和同一爐次相鄰設備間的等待時間的差異化最小為目標建立了動態約束滿足模型,提出了基于約束滿足和斷澆修復的重調度算法。算法
2018-02-27 16:28:540 數據。???????? 通過使用阿里云提供的云監控插件,可以一鍵安裝就實現GPU指標的采集和上報,同時展示維度上可以與目前的ECS一樣獲得更多維度的展示,比如Dashborad監控大盤,可以監控集群級別的GPU指標
2018-07-23 17:43:06475 華辰重機選用NVIDIA虛擬GPU解決方案,構建了高效、集約、安全的數控機虛擬化終端設計平臺,保證了近百億知識資產的數據。
2018-07-28 10:54:004162 「破局」AI規模化落地,英特爾至強的七重助力
2019-08-23 09:46:242970 “強悍的織女模型在京東探索研究院建設的全國首個基于 DGX SuperPOD 架構的超大規模計算集群 “天琴α” 上完成訓練,該集群具有全球領先的大規模分布式并行訓練技術,其近似線性加速比的數據、模型、流水線并行技術持續助力織女模型的高效訓練。”
2022-04-13 15:13:111493 經過百度內部 NLP 研究團隊的驗證,在這個網絡環境下的超大規模集群上提交千億模型訓練作業時,同等機器規模下整體訓練效率是普通 GPU 集群的 3.87 倍。
2022-05-20 15:00:271694 騰訊云計算加速套件 TACO Kit 包含 TACO Train 和 TACO Infer 兩個 AI 組件。基于 GPU 異構計算平臺針對業界 AI 訓練和推理任務進行了全方位的加速優化。TACO
2022-08-31 09:24:072284 10月18日, 上海億鑄智能科技有限公司與蘇州高新區獅山商務創新區進行簽約,將總部正式落戶蘇州。億鑄科技基于ReRAM (RRAM) 的存算一體大算力AI芯片技術,將為高新區集成電路產業注入新動能,助力蘇州集成電路設計產業蓬勃發展。
2022-10-19 10:29:042129 Adobe將開發下一代創意流程生成式AI模型;Getty Images、Morningstar、Quantiphi、Shutterstock公司正使用NVIDIA AI Foundations云服務
2023-03-22 13:45:40608 
L4 Tensor Core GPU 的云服務商。此外,L4 GPU 將在 Vertex AI 上提供優化支持,該平臺現在支持構建、調整和部署大型生成式AI模型。 開發人員
2023-03-23 06:55:021217 據悉,SDXL 0.9是在所有開源圖像模型中參數數量位居前茅,并且可以在消費級GPU上運行,還具備一個35億參數的基礎模型和一個66億參數的附加模型。
2023-06-26 09:41:491314 6 月 27 日上午1000,電子工程專輯【EE直播間】最新一期即將開播! 本期直播將圍繞“GPU助力數據中心高性能計算和AI大模型的開發”為主題,由 AspenCore 產業分析師為大家介紹
2023-06-26 11:20:021108 
大家好,歡迎收看總第84期“河套IT WALK”。 在這個日新月異的科技世界,無論是云端的智能,還是物聯網的連接,都在持續推動我們的生活進入新的紀元。今天的科技新聞側重AI發展,云計算升級,以及
2023-06-30 21:25:011280 
7月7日,華為云正式發布盤古大模型3.0,建立業界首個萬卡AI集群,欲打造世界AI另一極!盤古大模型3.0的發布引發中國科技圈熱議,業內人士認為,這展現出了華為“遇強則強、置之死地而后生”的頑強一面,既是華為對于技術追求的一種執念,更是在中美AI科技戰升級背景下的未雨綢繆。
2023-07-07 16:08:573051 據了解,星脈網絡具備業界最高的 3.2T 通信帶寬,可提升 40% 的 GPU 利用率、節省 30%~60% 的模型訓練成本,進而能為 AI 大模型帶來 10 倍通信性能提升。基于騰訊云新一代算力集群,可支持 10 萬卡的超大計算規模。
2023-07-14 14:46:333192 
首臺GPU千億參數大模型訓推一體機由數字寧夏倡議發起技術攻關,基于沐曦最新發布的曦云C500旗艦GPU芯片提供的算力支持、智譜華章的AI大模型以及優刻得靈活的算力部署方案,共同打造國內模型能力、算力支持及解決方案領先的國有自主知識產權的AI大模型訓練推理一體機
2023-08-21 14:41:2010390 適配。測試結果顯示,曦云C500在智譜AI的升級版大模型上充分兼容、高效穩定運行。 沐曦旗艦產品曦云C500基于自主研發的高性能GPU IP,特別適合千億參數AI大模型的訓練和推理;基于全自研 GPU 指令集打造的MXMACA軟件棧,全面兼容主流GPU生態,實現用戶零成本遷移;
2023-08-23 10:38:479276 日前,華為全聯接大會 2023 在上海召開。華為云 CTO 張宇昕在大會上發布了基于 Serverless 技術的大模型應用開發框架,框架以面向 AI 領域全新升級的 FunctionGraph
2023-10-25 21:30:441070 
大家好,歡迎收看河套IT WALK第124期。 今天,阿里云發布了具有720億參數的大型語言模型Qwen-72B,這一創新將助力多語言AI的發展,掀開了AI技術在全球溝通和數據處理方面的新篇章。谷歌
2023-12-01 20:15:011408 
中國電信規劃建設首個國產超大規模算力液冷集群 人工智能技術的快速發展催生了巨大的算力需求;中國電信規劃在上海規劃建設可支持萬億參數大模型訓練的智算集群中心。其中會搭載液冷技術,單池新建國產算力達10000卡,也是首個支持單池萬卡的國產超大規模算力液冷集群。
2024-02-22 18:48:331823 英特爾豐富的AI產品——面向數據中心的至強處理器,邊緣處理器及AI PC等產品為開發者提供最新的優化,助力其運行Meta新一代大語言模型Meta Llama 3
2024-04-28 11:16:421197 摩爾線程聯合無問芯穹宣布,雙方已在本周正式完成基于國產全功能GPU千卡集群的3B規模大模型實訓。
2024-05-27 10:44:021148 
英特爾助力京東云用CPU加速AI推理,以大模型構建數智化供應鏈
2024-05-27 11:50:101046 
近日,國內知名的GPU制造商摩爾線程與全學科教育AI大模型“師者AI”聯合宣布,雙方已成功完成了一項重要的大模型訓練測試。此次測試依托摩爾線程夸娥(KUAE)千卡智算集群,充分展現了其在處理復雜計算任務方面的卓越能力。
2024-06-14 16:31:311233 近日,摩爾線程與智譜AI在人工智能領域開展了一輪深入的合作,共同對GPU大模型進行了適配及性能測試。此次測試不僅涵蓋了大模型的推理能力,還涉及了基于摩爾線程夸娥(KUAE)千卡智算集群的大模型預訓練,旨在全面評估摩爾線程GPU在大模型應用中的性能表現。
2024-06-14 16:40:362024 協議,雙方將攜手步入全新的合作階段,共同探索并開發面向超萬億參數大模型和超大規模集群的高性能系統軟件方案,標志著雙方在推動AI技術邊界、加速產業智能化進程上邁出了堅實的一步。
2024-07-05 14:50:501581 特斯拉CEO埃隆·馬斯克引領的科技巨浪再添新章,其傾力打造的超級AI訓練集群Colossus已正式投入運營。該集群自7月初步建成以來,已展現出驚人的10萬張H100 GPU算力。而今
2024-09-04 16:13:22808 速度比原70B大模型提升2.2倍,具備更準確和更高效的運算效率;能夠大幅降低運行成本。 ? ? ? 通過NAS技術微調;大幅降低了內存消耗、計算復雜性;Llama-3.1-Nemotron-51B AI
2024-09-26 17:30:061275 Supermicro, Inc.,作為人工智能(AI)、云端、存儲和5G/Edge領域的整體IT解決方案提供商,近日宣布推出面向人工智能數據中心的液冷超級集群。該集群由英偉達GB200 NVL72和英偉達HGX B200系統提供支持,開創了高能效超大規模計算的新紀元。
2024-10-22 17:37:431330 GPU憑借其強大的并行處理能力和高效的內存系統,已成為AI模型訓練不可或缺的重要工具。
2024-10-24 09:39:261943 NVIDIA近日宣布,其位于田納西州孟菲斯市的xAI Colossus超級計算機集群規模已壯大至10萬顆NVIDIA Hopper GPU。這一里程碑式的成就,再次彰顯了NVIDIA在AI計算領域
2024-10-30 10:29:51993 眾所周知,在大型模型訓練中,通常采用每臺服務器配備多個GPU的集群架構。在上一篇文章《高性能GPU服務器AI網絡架構(上篇)》中,我們對GPU網絡中的核心術語與概念進行了詳盡介紹。本文將進一步深入探討常見的GPU系統架構。
2024-11-05 16:20:342133 
并從計算節點成本優化、集群網絡與拓撲的選擇等方面論述如何構建及優化GPU云網絡。
2024-11-06 16:03:101681 
訓練AI大模型需要選擇具有強大計算能力、足夠顯存、高效帶寬、良好散熱和能效比以及良好兼容性和擴展性的GPU。在選擇時,需要根據具體需求進行權衡和選擇。
2024-12-03 10:10:081128 在AI模型的訓練過程中,大量的計算工作集中在矩陣乘法、向量加法和激活函數等運算上。這些運算正是GPU所擅長的。接下來,AI部落小編帶您了解GPU是如何訓練AI大模型的。
2024-12-19 17:54:161577 LG集團旗下AI智庫利用亞馬遜云科技進行癌癥早期風險識別 Amazon SageMaker助力LG AI Research將基因測試時間從兩周縮短至不到一分鐘,加快患者診斷速度 北京2024年12月
2024-12-16 15:13:47664 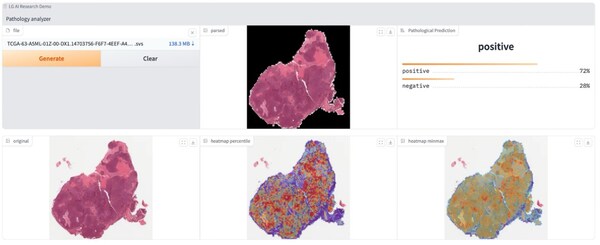
GPU加速云服務器是將GPU硬件與云計算服務相結合,通過云服務提供商的平臺,用戶可以根據需求靈活租用帶有GPU資源的虛擬機實例。那么,GPU加速云服務器怎么用的呢?下面,AI部落小編為您分享。
2024-12-26 11:58:12938 近日,有消息稱小米正在緊鑼密鼓地搭建自己的GPU萬卡集群,旨在加大對AI大模型的投入力度。據悉,小米的大模型團隊在成立之初就已經擁有了6500張GPU資源,而現在他們正在進一步擴大這一規模。 針對
2024-12-28 14:25:48847 1月2日,消費級AR領先品牌雷鳥創新RayNeo與阿里云舉行戰略簽約儀式,雙方宣布在AI眼鏡領域達成獨家戰略合作,通義系列大模型將為雷鳥創新的AI眼鏡提供獨家定制的技術支持。 ? 據悉,這是國內首個
2025-01-03 13:45:07565 
科技云報到:從大模型到云端,“AI+云計算”還能講出什么新故事
2025-01-07 13:27:34657 NVIDIA 今日發布能在 NVIDIA RTX AI PC 本地運行的基礎模型,為數字人、內容創作、生產力和開發提供強大助力。
2025-01-08 11:01:52975 中國信通院栗蔚:云計算與AI加速融合,如何開啟智算時代新紀元?
2025-01-17 18:48:361451 
鯤云科技全新一代的可重構數據流 AI 芯片 CAISA 430 成功適配 DeepSeek R1 蒸餾模型推理,這一創新舉措為大模型應用的高效部署帶來了全新的解決方案,標志著可重構數據流 AI 技術與大模型融合發展的又一重要里程碑,也展示了鯤云科技的可重構數據流技術的技術通用性和生態友好。
2025-02-07 09:57:432529 
、數據處理、模型調優到應用集成與部署等方面,助力企業加速生成式AI應用落地。此外,聚云科技還基于亞馬遜云科技打造RAGPro企業知識庫、AI-Space、DecisionAI和數字人等生成式AI解決方案,為游戲、電商、金融、教育、汽車、制造等行業企業提供技術支持,從提高業務效率、實現決
2025-02-14 13:41:00360 Bedrock等技術,從應用范圍、模型選擇、數據處理、模型調優到應用集成與部署等方面,助力企業加速生成式AI應用落地。此外,聚云科技還基于亞馬遜云科技打造RAGPro企業知識庫、AI-Space、DecisionAI和數字人等生成式AI解決方案,為游戲、電商、金融、教育、汽車、制造等行業企業提供技
2025-02-14 16:07:02735 “科通技術”)推出的“DeepSeek+AI芯片”全場景方案,在云AI領域取得重大突破。除了GPU的算力總量,云AI的一大挑戰來源于GPU集群的數據互聯效率。某大型互聯網集團為解決云AI系統中千卡級GPU集群的高性能需求,面臨服務器與加速卡間數據交換帶寬和延遲的嚴
2025-03-17 11:14:41768 RAKsmart高性能服務器集群憑借其創新的硬件架構與全棧優化能力,成為支撐大語言模型開發的核心算力引擎。下面,AI部落小編帶您了解RAKsmart如何為AI開發者提供從模型訓練到落地的全鏈路支持。
2025-04-15 09:40:37584 集合通信庫(如NCCL、HCCL)的運行細節用戶完全無感知,形成“黑盒”狀態。EPS通過實時解析集合通信庫的底層運行狀態,將隱蔽的通信路徑、GPU與網卡狀態等信息可視化,并提供智能路由推薦,幫助用戶快速優化集群性能。
2025-05-22 10:13:22796 
優勢,打造超低延時、超穩定、簡單易用的API接口服務,降低大模型應用成本和開發門檻,助力企業和個人用戶快速開啟AI創新之旅。專注邊緣推理,構建“云邊端”算力協同新范
2025-07-02 17:26:191028 
9月5日,在2025重慶世界智能產業博覽會上,中科曙光發布了國內首個基于AI計算開放架構設計的產品——曙光AI超集群系統。該系統以GPU為核心,實現了“算、存、網、電、冷、管、軟”一體化緊耦合
2025-09-06 09:11:281268 這項可選服務將幫助數據中心運營商監測整個 AI GPU 集群運行狀況,從而最大限度地延長正常運行時間。
2025-12-13 09:37:36825 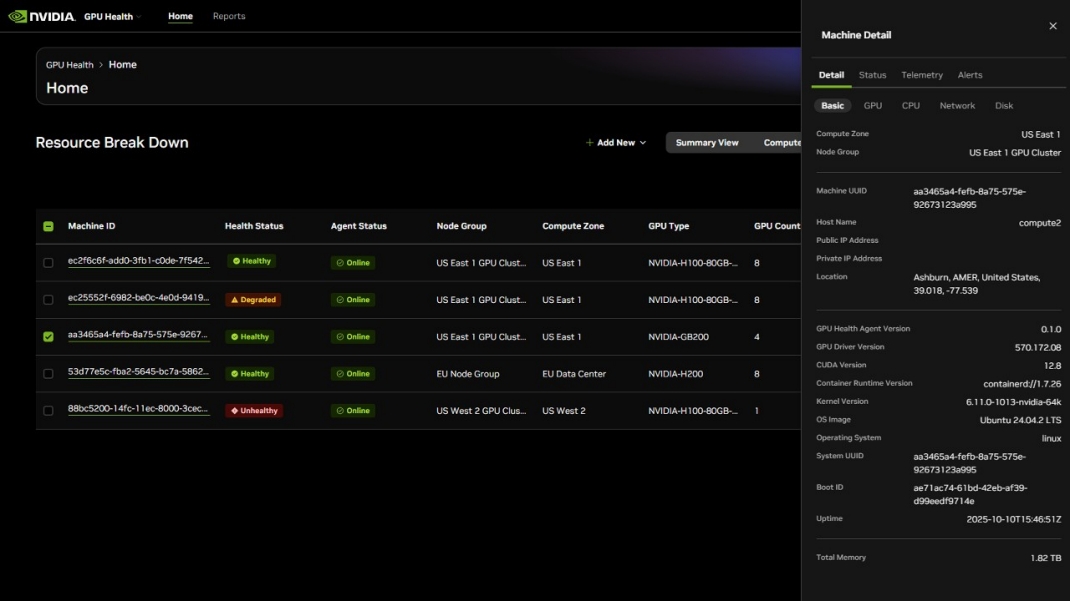
12月8日智譜AI發布并開源 GLM-4.6V 系列多模態大模型,沐曦股份曦云C系列GPU完成Day 0適配。
2025-12-17 14:28:41381 
近日,中國信息通信研究院(以下簡稱“中國信通院”)成功召開2025AI云產業發展大會。中國通信標準化協會理事長聞庫、中國信通院副院長王志勤出席會議并致辭。中國工程院院士鄭緯民作主旨報告。會議期間,發布了超大規模智算集群創新應用實踐成果,燧原科技國產萬卡推理集群經多輪評審確定,最終成功入選。
2025-12-29 09:59:12209 
電子發燒友網報道(文/黃山明)近日,有媒體報道,小米正在著手搭建自家的GPU萬卡集群,將對AI大模型加大投入。該計劃已進行數月,據悉小米大模型團隊在成立之初便已擁有6500張GPU資源,小米創始人兼
2024-12-29 00:02:003679 
 電子發燒友App
電子發燒友App








 工商網監
工商網監
評論