 NVIDIA軟件可選服務支持數據中心集群管理
NVIDIA軟件可選服務支持數據中心集群管理

這項可選服務將幫助數據中心運營商監測整個 AI GPU 集群運行狀況,從而最大限度地延長正常運行時間。
隨著 AI 基礎設施的規模和復雜性不斷增加,數據中心運營商需要持續了解性能、溫度和功耗等因素。這些洞察使數據中心運營商能夠主動監測和調整大規模分布式系統中的數據中心配置,從而確保這些系統以最高效率和可靠性運行。
NVIDIA 正在開發用于可視化和監測 NVIDIA GPU 集群的軟件解決方案,為云合作伙伴和企業提供洞察儀表板,幫助他們提高整個計算基礎設施的 GPU 正常運行時間。
該服務由客戶選擇、自行安裝和控制,用于監測 GPU 使用情況、配置和錯誤。它將包含一個開源客戶端軟件智能體,這是 NVIDIA 持續支持開放、透明軟件的一部分,旨在幫助客戶最大限度的發揮其 GPU 系統的性能。
通過這項服務,數據中心運營商將能夠:
追蹤功耗峰值,在不超出能耗預算的前提下最大化單位功耗性能。
監測整個集群的利用率、內存帶寬和互連運行狀況。
及早發現熱點和氣流問題,以避免過熱降頻和組件過早老化。
確認軟件配置和設置一致,以確保結果可復現以及運行可靠。
發現錯誤和異常情況,及早發現故障部件。
這些功能可以幫助企業和云提供商可視化其 GPU 集群、解決系統瓶頸并優化生產力,從而提高投資回報。
此可選服務提供實時監測,讓每個 GPU 系統與外部云服務通信和共享 GPU 指標。NVIDIA GPU 沒有硬件跟蹤技術、終止開關和后門。
開源智能體為數據中心所有者提供洞察
該服務將配備客戶端軟件智能體,客戶可以安裝該智能體,將節點級 GPU 遙測數據流式傳輸到托管在NVIDIA NGC的門戶網站上。客戶可以在儀表板中可視化其 GPU 集群利用率,既可以全局查看,也可以按計算區域 (在同一物理或云位置注冊的節點組) 查看。
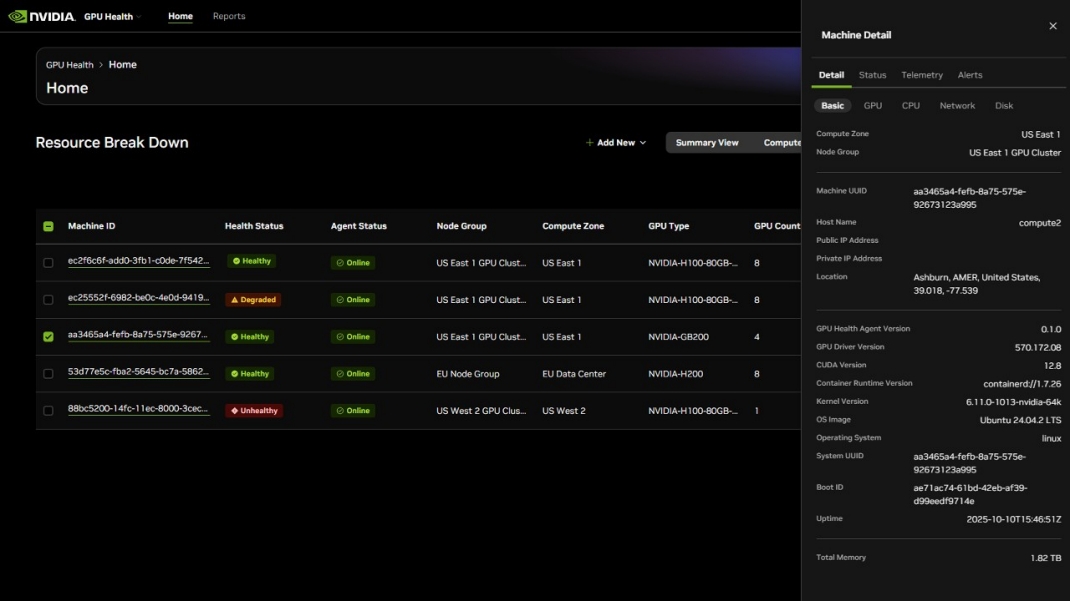
儀表盤可展示客戶全球 GPU 集群的整體狀態洞察。
該客戶端工具智能體也計劃開源,以提供透明度和可審計性。它將提供一個實際示例,展示客戶如何將 NVIDIA 工具整合到他們自己的 GPU 基礎設施監測解決方案中,無論是用于關鍵計算集群,還是整個 GPU 集群。
該軟件能夠幫助企業了解其 GPU 庫存情況,但無法修改 GPU 配置或底層運行機制。它提供的是只讀遙測數據,并由客戶自行管理及自定義。
該服務還支持客戶生成詳細介紹 GPU 集群信息的報告。
隨著 AI 應用的數量和復雜性不斷增加,現代 AI 基礎設施管理也在不斷發展以適應這一趨勢。AI 正在重塑各行各業以及各種應用,因此確保 AI 數據中心保持最佳狀態運行至關重要。這項軟件服務正是為此而生。
-
NVIDIA
+關注
關注
14文章
5628瀏覽量
109879 -
gpu
+關注
關注
28文章
5214瀏覽量
135625 -
數據中心
+關注
關注
18文章
5670瀏覽量
75078
原文標題:NVIDIA 軟件可選服務支持數據中心集群管理
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
提高數據中心效率:探索PDU的作用
KubePi:開源Kubernetes可視化管理面板,讓集群管理如此簡單

構建高可靠的數據中心零配置帶外管理體系

數據中心發展的三大驅動力
睿海光電以高效交付與廣泛兼容助力AI數據中心800G光模塊升級
加速AI未來,睿海光電800G OSFP光模塊重構數據中心互聯標準
PCIe協議分析儀在數據中心中有何作用?
中型數據中心應用平臺與差分晶體振蕩器參數對照中型數據中心應用平臺與差分晶體振蕩器參數對照
中型數據中心中的差分晶體振蕩器應用與匹配方案
利用NVIDIA技術構建從數據中心到邊緣的智慧醫院解決方案
施耐德電氣發布數據中心高密度AI集群部署解決方案



 工商網監
工商網監
評論