為了應對在未來復雜的戰場環境下,由于通信受限等原因導致的集中式決策模式難以實施的情況,提出了一個基于多智能體深度強化學習方法的分布式作戰體系任務分配算法,該算法為各作戰單元均設計一個獨立的策略網絡
2023-05-18 16:46:43 6319
6319 
智能電網集成優化控制技術是實現各環節協調運行的關鍵,智能代理技術為解決這一問題提供了良好的方法。在介紹國內外智能代理研究現狀和發展趨勢的基礎上,介紹了基于Agent的智能電網集成優化控制技術總體架構,基于Agent的動態分解與協調技術,并以微電網為例,對微電網中基于Agent的即插即用技術進行了分析。
2016-01-12 14:38:432927 什么是深度強化學習? 眾所周知,人類擅長解決各種挑戰性的問題,從低級的運動控制(如:步行、跑步、打網球)到高級的認知任務。
2023-07-01 10:29:502122 
來源:易百納技術社區 隨著人工智能技術的不斷進步,深度學習成為計算機視覺領域的重要技術。微表情識別作為人類情感分析的一種重要手段,受到了越來越多的關注。本文將介紹基于深度學習的微表情識別技術,并提
2023-08-14 17:27:053847 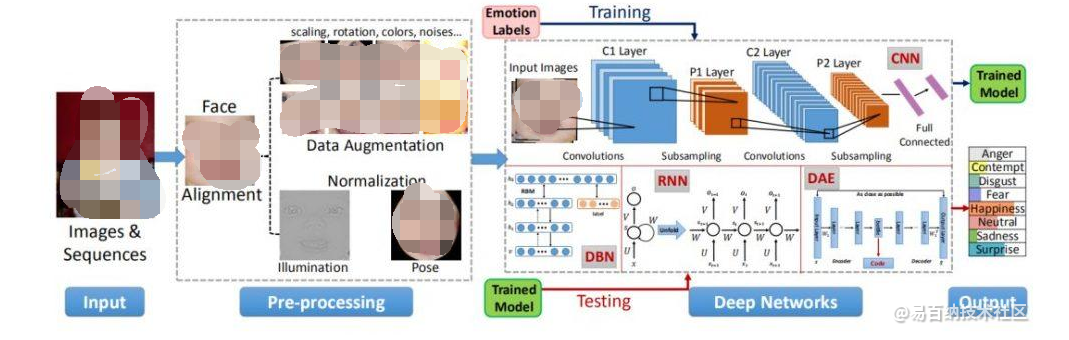
介紹一種一體化儀表優化交換式測量示例
2021-05-11 07:01:37
本文介紹一種基于FIFO結構的優化端點設計方案。
2021-05-31 06:31:35
多智能體系統深度強化學習:挑戰、解決方案和應用的回顧摘要介紹背景:強化學習前提貝爾曼方程RL方法深度強化學習:單智能體深度Q網絡DQN變體深度強化學習:多智能體挑戰與解決方案MADRL應用結論和研究
2021-07-12 08:44:43
做是小型的電力系統,具備完整的發輸配電功能,可實現用側可再生能源的安全消納,同時微網本身還是一個典型的分布式發電功能系統,可通過能源之間的調度,提高終端能源的利用率。也是智能電網發展的趨勢。在實際生活
2018-09-19 14:09:52
微電網儲能優化研究有何意義?微電網有哪些性能?如何去選取一種微電網優化算法?什么是粒子群算法?
2021-07-06 06:34:20
) 基于多代理技術的微電網控制。該方法將計算機領域的多代理技術應用到微電網,代理的自治性、自發性等特點能夠很好地適應和滿足微電網分散控制的要求。微電網作為分布式發電優化集成的一種方式,已經成為世界各國
2018-09-20 11:27:45
等方面。微電網作為分布式發電優化集成的一種方式,已經成為世界各國研究的重點,微電網將在未來占有重要的地位。微電網雖然具有很多優點,但在大規模應用之前,還有許多問題需要解決。所以中國微電網技術的發展還將
2018-11-20 08:43:30
深度策略梯度-DDPG,PPO等第一天9:00-12:0014:00-17:00一、強化學習概述1.強化學習介紹 2.強化學習與其它機器學習的不同3.強化學習發展歷史4.強化學習典型應用5.強化學習
2022-04-21 14:57:39
一:深度學習DeepLearning實戰時間地點:1 月 15日— 1 月18 日二:深度強化學習核心技術實戰時間地點: 1 月 27 日— 1 月30 日(第一天報到 授課三天;提前環境部署 電腦
2021-01-09 17:01:54
利用ML構建無線環境地圖及其在無線通信中的應用?使用深度學習的收發機設計和信道解碼基于ML的混合學習方法,用于信道估計、建模、預測和壓縮 使用自動編碼器等ML技術的端到端通信?無線電資源管理深度強化學習
2021-07-01 10:49:03
一:深度學習DeepLearning實戰時間地點:1 月 15日— 1 月18 日二:深度強化學習核心技術實戰時間地點: 1 月 27 日— 1 月30 日(第一天報到 授課三天;提前環境部署 電腦
2021-01-10 13:42:26
的工具和方法,對推動微電網技術的發展具有重要意義。1、微電網的實時仿真是指在仿真過程中,系統的運行和響應能夠以接近實時的速度進行模擬和評估的一種技術。它可以提供更高的仿真精度和準確度,使研究人員和工程師
2023-09-26 10:22:11
,Deep Learning—遷移學習5,Deep Learning—深度強化學習6,深度學習的常用模型或者方法深度學習交流大群: 372526178 (資料共享,加群備注楊春嬌邀請)
2018-09-05 10:22:34
相對成熟的技術和較好的性價比,鋰離子電池和鉛炭(酸)電池是目前儲能系統的首選技術路線。 近日,研究機構EVTank發布《微電網領域儲能行業深度分析報告(2016)》,研究報告認為隨著能源互聯網
2016-01-20 17:12:18
的清潔能源的推廣應用,智能光伏微電網的出現有效滿足這一現實需求。在本文內,南京研旭新能源科技有限公司將會就光伏微電網的技術應用來做詳細的介紹。 光伏微電網的特點:光伏微電網指的是,采用光伏發電作為白天
2018-10-18 11:07:27
,自適應處理技術; 實時分析——數據到信息的提升,優化運行方式。 二、智能微電網兩種運行模式 并網模式:正常情況下,智能微電網與常規配電網并網運行。 孤島模式:當檢測到電網故障或電能質量不滿足
2016-01-07 14:13:12
強化學習的另一種策略(二)
2019-04-03 12:10:44
、監控和調節不同的資源。智能電網在發展中國家的能源支持中也發揮著至關重要的作用,因為它們可以通過實現從一次性方法向電氣化的過渡,為人口稀少的地區提供電力。定制技術和增強的數據收集有助于提高生活水平
2023-04-06 16:34:25
。二、新能源實時仿真技術新能源實時仿真技術作為一種高效、低成本的研發手段,已經成為新能源技術發展的重要支撐。新能源實時仿真解決方案可以幫助設計者更好地了解新能源產品和系統的性能和特性,提高開發效率,并
2024-10-18 09:37:33
技術等眾多發展趨勢為一體的未來電網發展重要方式。智能電網相較傳統電網的優點在于可以針對網絡中的各供電節點進行實時的電力調節,對于現在大力提倡并推廣的分布式能源來說無疑是個好消息。規模化分布式能源電力
2015-07-16 11:17:07
將詳細介紹微電網多端口能量路由器的重要性和相關技術一特、點微。電網多端口能量路由器的概述微電網多端口能量路由器是一種新型的電力電子設備,它通過先進的功率電子變換技
2023-10-18 22:31:53
請訂閱2016年《程序員》 盡管監督式和非監督式學習的深度模型已經廣泛被技術社區所采用,深度強化學習仍舊顯得有些神秘。這篇文章將試圖揭秘
2017-10-09 18:28:43 0
0 與監督機器學習不同,在強化學習中,研究人員通過讓一個代理與環境交互來訓練模型。當代理的行為產生期望的結果時,它得到正反饋。例如,代理人獲得一個點數或贏得一場比賽的獎勵。簡單地說,研究人員加強了代理人的良好行為。
2018-07-13 09:33:0025158 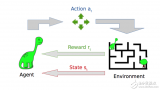
深度強化學習DRL自提出以來, 已在理論和應用方面均取得了顯著的成果。尤其是谷歌DeepMind團隊基于深度強化學習DRL研發的AlphaGo,將深度強化學習DRL成推上新的熱點和高度,成為人工智能歷史上一個新的里程碑。因此,深度強化學習DRL非常值得研究。
2018-06-29 18:36:0028671 薩頓在專訪中(再次)科普了強化學習、深度強化學習,并談到了這項技術的潛力,以及接下來的發展方向:預測學習
2017-12-27 09:07:1511877 本文提出了一種LCS和LS-SVM相結合的多機器人強化學習方法,LS-SVM獲得的最優學習策略作為LCS的初始規則集。LCS通過與環境的交互,能更快發現指導多機器人強化學習的規則,為強化學習系統
2018-01-09 14:43:490 傳統上,強化學習在人工智能領域占據著一個合適的地位。但強化學習在過去幾年已開始在很多人工智能計劃中發揮更大的作用。
2018-03-03 14:16:564677 SAC-X是一種通用的強化學習方法,未來可以應用于機器人以外的更廣泛領域
2018-03-19 14:45:482248 Q-learning和SARSA是兩種最常見的不理解環境強化學習算法,這兩者的探索原理不同,但是開發原理是相似的。Q-learning是一種離線學習算法,智能體需要從另一項方案中學習到行為a*的價值
2018-04-15 10:32:2214964 強化學習是智能系統從環境到行為映射的學習,以使獎勵信號(強化信號)函數值最大,強化學習不同于連接主義學習中的監督學習,主要表現在教師信號上,強化學習中由環境提供的強化信號是對產生動作的好壞作一種評價
2018-05-30 06:53:001741 為了達到人類學習的速率,斯坦福的研究人員們提出了一種基于目標的策略強化學習方法——SOORL,把重點放在對策略的探索和模型選擇上。
2018-06-06 11:18:235925 
可再生能源的間歇性和負荷的隨機性對微電網能源管理系統(EMS)產生了巨大的挑戰。在隨機環境下的能源優化調度問題在微電網的研究中具有重要意義。以微電網中光伏發電系統的功率預測為基礎,將光伏預測誤差當做隨機變量,建立了一種基于期望模型的能源隨機優化調度模型。
2018-06-14 08:00:009 自動駕駛汽車首先是人工智能問題,而強化學習是機器學習的一個重要分支,是多學科多領域交叉的一個產物。今天人工智能頭條給大家介紹強化學習在自動駕駛的一個應用案例,無需3D地圖也無需規則,讓汽車從零開始在二十分鐘內學會自動駕駛。
2018-07-10 09:00:295636 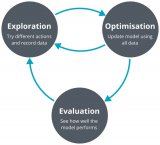
強化學習是人工智能基本的子領域之一,在強化學習的框架中,智能體通過與環境互動,來學習采取何種動作能使其在給定環境中的長期獎勵最大化,就像在上述的棋盤游戲寓言中,你通過與棋盤的互動來學習。
2018-07-15 10:56:3718470 
結合 DL 與 RL 的深度強化學習(Deep Reinforcement Learning, DRL)迅速成為人工智能界的焦點。
2018-08-09 10:12:436869 深度強化學習的理論、自動駕駛技術的現狀以及問題、深度強化學習在自動駕駛技術當中的應用及基于深度強化學習的禮讓自動駕駛研究。
2018-08-18 10:19:575830 強化學習作為一種常用的訓練智能體的方法,能夠完成很多復雜的任務。在強化學習中,智能體的策略是通過將獎勵函數最大化訓練的。獎勵在智能體之外,各個環境中的獎勵各不相同。深度學習的成功大多是有密集并且有效的獎勵函數,例如電子游戲中不斷增加的“分數”。
2018-08-18 11:38:574166 強化學習是一種非常重要 AI 技術,它能使用獎勵(或懲罰)來驅動智能體(agents)朝著特定目標前進,比如它訓練的 AI 系統 AlphaGo 擊敗了頂尖圍棋選手,它也是 DeepMind 的深度
2018-09-03 14:06:303344 之前接觸的強化學習算法都是單個智能體的強化學習算法,但是也有很多重要的應用場景牽涉到多個智能體之間的交互。
2018-11-02 16:18:1522830 針對提高視覺圖像特征與優化控制之間契合度的問題,本文提出一種基于深度強化學習的機械臂視覺抓取控制優化方法,可以自主地從與環境交互產生的視覺圖像中不斷學習特征提取,直接地將提取的特征應用于機械臂抓取
2018-12-19 15:23:5922 OpenAI 近期發布了一個新的訓練環境 CoinRun,它提供了一個度量智能體將其學習經驗活學活用到新情況的能力指標,而且還可以解決一項長期存在于強化學習中的疑難問題——即使是廣受贊譽的強化算法在訓練過程中也總是沒有運用監督學習的技術。
2019-01-01 09:22:003047 
一種人工智能系統,即通過深度強化學習來學習走路,簡單來說,就是教“一個四足機器人來穿越熟悉和不熟悉的地形”。
2019-01-03 09:50:133635 針對深度強化學習中卷積神經網絡(CNN)層數過深導致的梯度消失問題,提出一種將密集連接卷積網絡應用于強化學習的方法。首先,利用密集連接卷積網絡中的跨層連接結構進行圖像特征的有效提取;然后,在密集連接
2019-01-23 10:41:513 在一些情況下,我們會用策略函數(policy, 總得分,也就是搭建的網絡在測試集上的精度(accuracy),通過強化學習(Reinforcement Learning)這種通用黑盒算法來優化。然而,因為強化學習本身具有數據利用率低的特點,這個優化的過程往往需要大量的計算資源。
2019-01-28 09:54:225819 Google AI 與 DeepMind 合作推出深度規劃網絡 (PlaNet),這是一個純粹基于模型的智能體,能從圖像輸入中學習世界模型,完成多項規劃任務,數據效率平均提升50倍,強化學習又一突破。
2019-02-17 09:30:283943 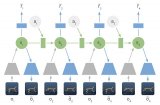
近日,Reddit一位網友根據近期OpenAI Five、AlphaStar的表現,提出“深度強化學習是否已經到達盡頭”的問題。
2019-05-10 16:34:592987 近年來,深度強化學習(Deep reinforcement learning)方法在人工智能方面取得了矚目的成就,從 Atari 游戲、到圍棋、再到無限制撲克等領域,AI 的表現都大大超越了專業選手,這一進展引起了眾多認知科學家的關注。
2019-05-30 17:29:353207 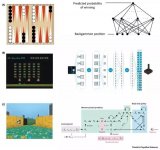
近年來,深度強化學習(Deep reinforcement learning)方法在人工智能方面取得了矚目的成就
2019-06-03 14:36:053355 近幾年來,強化學習在任務導向型對話系統中得到了廣泛的應用,對話系統通常被統計建模成為一個 馬爾科夫決策過程(Markov Decision Process)模型,通過隨機優化的方法來學習對話策略。
2019-08-06 14:16:292402 近日,中國科學院沈陽自動化研究所智能微電網課題組在智能電網優化調度領域取得進展,相關研究成果日前發表于《電氣和電子工程師協會智能電網匯刊》。
2019-10-17 11:12:261344 深度學習DL是機器學習中一種基于對數據進行表征學習的方法。深度學習DL有監督和非監督之分,都已經得到廣泛的研究和應用。
2020-01-30 09:53:006369 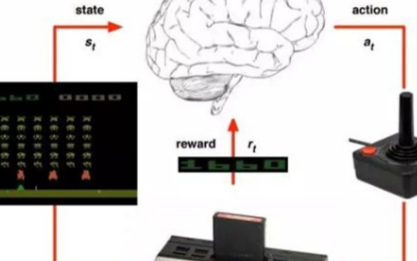
強化學習非常適合實現自主決策,相比之下監督學習與無監督學習技術則無法獨立完成此項工作。
2019-12-10 14:34:571667 深度學習DL是機器學習中一種基于對數據進行表征學習的方法。深度學習DL有監督和非監督之分,都已經得到廣泛的研究和應用。
2020-01-24 10:46:005623 惰性是人類的天性,然而惰性能讓人類無需過于復雜的練習就能學習某項技能,對于人工智能而言,是否可有基于惰性的快速學習的方法?本文提出一種懶惰強化學習(Lazy reinforcement learning, LRL) 算法。
2020-01-16 17:40:001238 本文檔的主要內容詳細介紹的是深度強化學習的筆記資料免費下載。
2020-03-10 08:00:000 )的研究人員聯合發表了一篇論文,詳細介紹了他們構建的一個通過 AI 技術自學走路的機器人。該機器人結合了深度學習和強化學習兩種不同類型的 AI 技術,具備直接放置于真實環境中進行訓練的條件。
2020-03-17 15:15:301764 深度學習DL是機器學習中一種基于對數據進行表征學習的方法。深度學習DL有監督和非監督之分,都已經得到廣泛的研究和應用。強化學習RL是通過對未知環境一邊探索一邊建立環境模型以及學習得到一個最優策略。強化學習是機器學習中一種快速、高效且不可替代的學習算法。
2020-05-16 09:20:403978 深度學習DL是機器學習中一種基于對數據進行表征學習的方法。深度學習DL有監督和非監督之分,都已經得到廣泛的研究和應用。強化學習RL是通過對未知環境一邊探索一邊建立環境模型以及學習得到一個最優策略。強化學習是機器學習中一種快速、高效且不可替代的學習算法。
2020-06-13 11:39:407089 與1月份的最后一次重大公告一樣,該公司還展示了一種用于深度學習的新方法的技術,在這種情況下,該公司提供了一種用于消除AI模型偏差的新技術。該軟件可以執行諸如調整現有程序之類的操作,從而可以更公平,準確地對照片中的黑人是否在微笑進行分類。
2020-07-22 10:26:505588 訓練最新 AI 系統需要驚人的計算資源,這意味著囊中羞澀的學術界實驗室很難趕上富有的科技公司。但一種新的方法可以讓科學家在單臺計算機上訓練先機的 AI。2018 年 OpenAI 報告每 3.4 個月訓練最強大 AI 所需的處理能力會翻一番,其中深度強化學習對處理尤為苛刻。
2020-07-29 09:45:38913 深度學習是一個廣闊的領域,它圍繞著一種形態由數百萬甚至數十億個變量決定并不斷變化的算法——神經網絡。似乎每隔一天就有大量的新方法和新技術被提出來。不過,總的來說,現代深度學習可以分為三種基本的學習范式。每一種都有自己的學習方法和理念,提升了機器學習的能力,擴大了其范圍。
2020-10-23 14:59:2113711 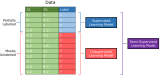
強化學習屬于機器學習中的一個子集,它使代理能夠理解在特定環境中執行特定操作的相應結果。目前,相當一部分機器人就在使用強化學習掌握種種新能力。
2020-11-06 15:33:492130 深度強化學習是深度學習與強化學習相結合的產物,它集成了深度學習在視覺等感知問題上強大的理解能力,以及強化學習的決策能力,實現了...
2020-12-10 18:32:501078 RLax(發音為“ relax”)是建立在JAX之上的庫,它公開了用于實施強化學習智能體的有用構建塊。。報道:深度強化學習實驗室作者:DeepRL ...
2020-12-10 18:43:231334 本文主要介紹深度強化學習在任務型對話上的應用,兩者的結合點主要是將深度強化學習應用于任務型對話的策略學習上來源:騰訊技術工程微信號
2020-12-10 19:02:451546 針對現有多目標追蹤方法通常存在學習速度慢、追蹤效率低及協同追蹤策略設計困難等問題,提岀一種改進的多目標追蹤方法。基于追蹤智能體和目標智能體數量及其環境信息建立任務分配模型,運用匈牙利算法根據距離效益
2021-03-17 11:08:1520 針對地下能量場聚焦模型中能量聚焦點無法有效識別的冋題,在深度學習的基礎上,提出一種地下淺層震源定位方法。利用逆時振幅疊加的方法將傳感器陣列獲取的震動數據逆時重建為三維能量場圖像樣本序列,并將其作為
2021-03-22 15:58:4510 強化學習( Reinforcement learning,RL)作為機器學習領域中與監督學習、無監督學習并列的第三種學習范式,通過與環境進行交互來學習,最終將累積收益最大化。常用的強化學習算法分為
2021-04-08 11:41:5811 強化學習。無模型強仳學習方法的訓練過程需要大量樣本,當采樣預算不足,無法收集大量樣本時,很難達到預期效果。然而,模型化強化學習可以充分利用環境模型,降低真實樣本需求量,在一定程度上提高樣本效率。將以模型化強化學習為核心,介紹
2021-04-12 11:01:529 變化。針對這一問題,提出了一種考慮可再生能源和負荷時變特性的綜合能源系統動態經濟調度方法。首先對綜合能源系統動態經濟調度問題進行數學描述,然后將該調度決策問題表述為強化學習框架,定義了系統的觀測狀態、調度
2021-04-14 09:36:130 利用深度強化學習技術實現路口信號控制是智能交通領域的硏究熱點。現有硏究大多利用強化學習來全面刻畫交通狀態以及設計有效強化學習算法以解決信號配時問題,但這些研究往往忽略了信號燈狀態對動作選擇的影響以及
2021-04-23 15:30:5321 目前壯語智能信息處理研究處于起步階段,缺乏自動詞性標注方法。針對壯語標注語料匱乏、人工標注費時費力而機器標注性能較差的現狀,提出一種基于強化學習的壯語詞性標注方法。依據壯語的文法特點和中文賓州樹庫
2021-05-14 11:29:3514 壓邊為改善板料拉深制造的成品質量,釆用深度強化學習的方法進行拉深過程旳壓邊力優化控制。提岀一種基于深度強化學習與有限元仿真集成的壓邊力控制模型,結合深度神經網絡的感知能力與強化學習的決策能力,進行
2021-05-27 10:32:390 針對微電網多目標優化計算量較大的問題,提出了一種考慮需求響應的微電網分布式神經動力學優化算法。首先考慮平均效率函數、微電網的排放、需求響應引起的不滿意度以及總利潤函數等因素建立多目標優化模型。其次
2021-05-31 14:21:344 一種新型的多智能體深度強化學習算法
2021-06-23 10:42:4736 基于深度強化學習的無人機控制律設計方法
2021-06-23 14:59:1046 基于深度強化學習的區域化視覺導航方法 人工智能技術與咨詢? 本文來自《 上海交通大學學報 》,作者李鵬等 關注微信公眾號:人工智能技術與咨詢。了解更多咨詢! ? 在環境中高效導航是智能
2021-11-19 11:03:571294 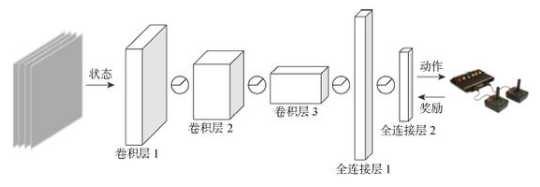
突破.由于融合了深度學習強大的表征能力和強化學習有效的策略搜索能力,深度強化學習已經成為實現人工智能頗有前景的學習范式.然而,深度強化學習在多Agent 系統的研究與應用中,仍存在諸多困難和挑戰,以StarCraft II 為代表的部分觀測環境下的多Agent學習仍然很難達到理想效果.本文簡要介紹了深度Q
2022-01-18 10:08:012300 
定標記訓練數據的情況下獲得正確的輸出 無監督學習(UL):關注在沒有預先存在的標簽的情況下發現數據中的模式 強化學習(RL) : 關注智能體在環境中如何采取行動以最大化累積獎勵 通俗地說,強化學習類似于嬰兒學習和發現世界,如果有獎勵(正強化),嬰兒可能會執行一個行
2022-12-20 14:00:021683 電子發燒友網站提供《ESP32上的深度強化學習.zip》資料免費下載
2022-12-27 10:31:451 一套泛化能力強的決策規劃機制是智能駕駛目前面臨的難點之一。強化學習是一種從經驗中總結的學習方式,并從長遠的角度出發,尋找解決問題的最優方案。近些年來,強化學習在人工智能領域取得了重大突破,因而成為了解決智能駕駛決策規劃問題的一種新的思路。
2023-02-08 14:05:162894 強化學習(RL)是人工智能的一個子領域,專注于決策過程。與其他形式的機器學習相比,強化學習模型通過與環境交互并以獎勵或懲罰的形式接收反饋來學習。
2023-06-09 09:23:23930 大模型時代,模型壓縮和加速顯得尤為重要。傳統監督學習可通過稀疏神經網絡實現模型壓縮和加速,那么同樣需要大量計算開銷的強化學習任務可以基于稀疏網絡進行訓練嗎?本文提出了一種強化學習專用稀疏訓練框架
2023-06-11 21:40:021325 
機械臂抓取擺放及堆疊物體是智能工廠流水線上常見的工序,可以有效的提升生產效率,本文針對機械臂的抓取擺放、抓取堆疊等常見任務,結合深度強化學習及視覺反饋,采用AprilTag視覺標簽、后視經驗回放機制
2023-06-12 11:25:224327 
來源:DeepHubIMBA強化學習的基礎知識和概念簡介(無模型、在線學習、離線強化學習等)機器學習(ML)分為三個分支:監督學習、無監督學習和強化學習。監督學習(SL):關注在給定標記訓練數據
2023-01-05 14:54:051715 
摘要:基于強化學習的目標檢測算法在檢測過程中通常采用預定義搜索行為,其產生的候選區域形狀和尺寸變化單一,導致目標檢測精確度較低。為此,在基于深度強化學習的視覺目標檢測算法基礎上,提出聯合回歸與深度
2023-07-19 14:35:020 訊維模擬矩陣在深度強化學習智能控制系統中的應用主要是通過構建一個包含多種環境信息和動作空間的模擬矩陣,來模擬和預測深度強化學習智能控制系統在不同環境下的表現和效果,從而優化控制策略和提高系統的性能
2023-09-04 14:26:361156 
強化學習是機器學習的方式之一,它與監督學習、無監督學習并列,是三種機器學習訓練方法之一。 在圍棋上擊敗世界第一李世石的 AlphaGo、在《星際爭霸2》中以 10:1 擊敗了人類頂級職業玩家
2023-10-30 11:36:405376 
更快更好地學習。我們的想法是找到最優數量的特征和最有意義的特征。在本文中,我們將介紹并實現一種新的通過強化學習策略的特征選擇。我們先討論強化學習,尤其是馬爾可夫決策
2024-06-05 08:27:46974 深度學習模型在訓練過程中,往往會遇到各種問題和挑戰,如過擬合、欠擬合、梯度消失或爆炸等。因此,對深度學習模型進行優化與調試是確保其性能優越的關鍵步驟。本文將從數據預處理、模型設計、超參數調整、正則化、模型集成以及調試與驗證等方面,詳細介紹深度學習的模型優化與調試方法。
2024-07-01 11:41:132534 強化學習(Reinforcement Learning, RL)是一種機器學習方法,它通過與環境的交互來學習如何做出決策,以最大化累積獎勵。PyTorch 是一個流行的開源機器學習庫,它提供了靈活
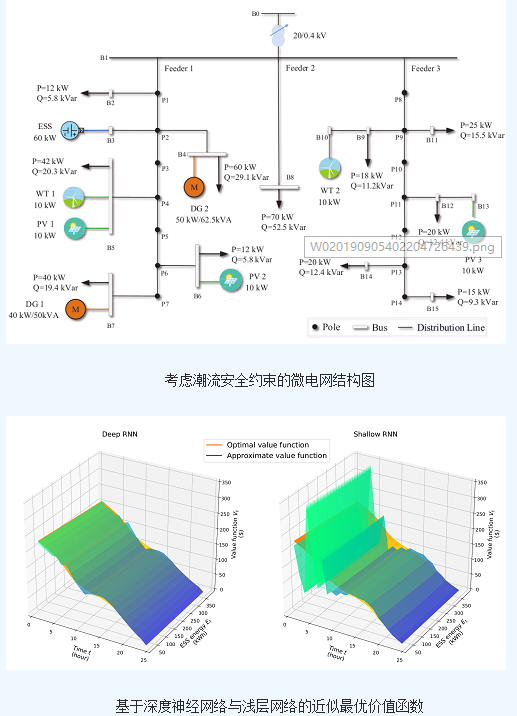
2024-11-05 17:34:281520 電網運行效率、優化能源分配、增強系統穩定性等方面的積極影響,為微電網能量管理領域的發展提供參考。 引言 隨著能源需求的增長和對可持續能源的追求,微電網作為一種高效、靈活的能源系統得到了廣泛關注。微電網通常包含分布式電源、儲能裝置、負荷以
2025-05-30 15:09:121202 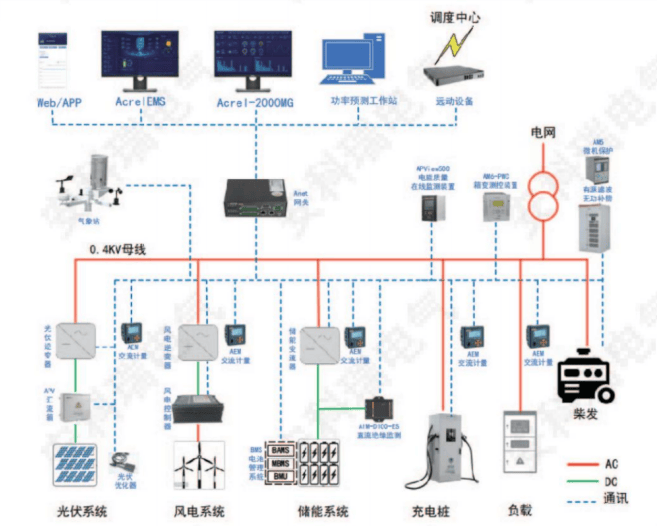
微電網能源管理物聯網平臺具備多種功能,旨在實現能源的高效利用、優化調度和智能化管理,以下是其主要功能: 實時監測與數據采集 :通過物聯網技術,平臺能夠實時采集微電網內各種能源設備(如光伏、風機、儲能
2025-06-21 18:00:251023 [首發于智駕最前沿微信公眾號]在談及自動駕駛時,有些方案中會提到“強化學習(Reinforcement Learning,簡稱RL)”,強化學習是一類讓機器通過試錯來學會做決策的技術。簡單理解
2025-10-23 09:00:37483 
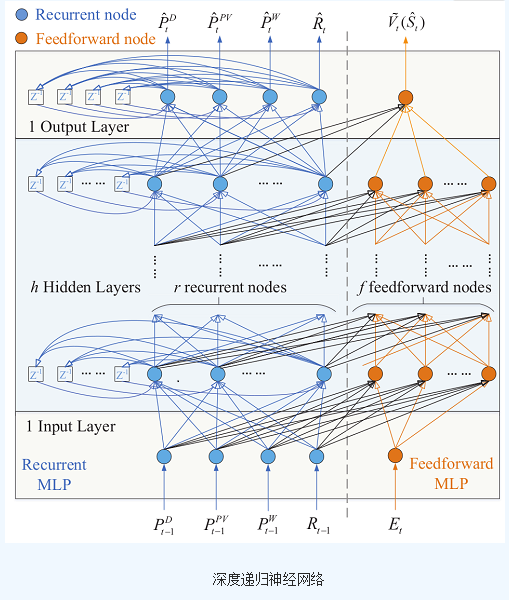
該系統核心是管理能源的方法。團隊采用調度框架,將多目標分布魯棒優化(DRO)與實時強化學習(RL)輔助機制結合。能源管理系統(EMS)是運行“大腦”,分布式響應系統(DRO)生成基準調度策略,強化學習(RL)模塊實時調整控制信號,讓系統適應環境。該研究強調,數學模型解決了多能源多時間尺度協調問題。
2025-11-27 17:05:18465
 電子發燒友App
電子發燒友App








 工商網監
工商網監
評論