Machine Learning SDK 相集成以供預覽。客戶可以使用 Azure 大規(guī)模部署的英特爾? FPGA(現(xiàn)場可編程邏輯門陣列)技術,為其模型提供行業(yè)領先的人工智能 (AI) 推理性能。
2018-05-16 17:25:03 6901
6901 最新MLPerf基準測試表明,NVIDIA已將其在AI推理性能和能效方面的高標準擴展到Arm以及x86計算機。
2021-09-23 14:18:062953 
不久前,AI性能基準評測平臺MLPerf公布了2022年首次推理(Inference v2.0)測試成績,NVIDIA的AI平臺表現(xiàn)依然搶眼。
2022-04-15 22:12:004143 
NVIDIA Turing GPU和Xavier 芯片系統(tǒng)在首個獨立AI推理基準測試 ——MLPerf Inference 0.5中取得第一名。
2019-11-08 16:53:295804 5月的行業(yè)基準測試組織,致力于機器學習硬件、軟件和服務的訓練和推理性能測試,囊括行業(yè)中幾乎所有知名企業(yè)和機構,比如Intel、NVIDIA、Google、微軟、阿里巴巴等。 DGX Su
2020-07-31 08:03:006622 的BERT、GNMT 和Jasper 等AI模型開源優(yōu)化幫助開發(fā)者實現(xiàn)頂尖推理性能。NVIDIA的客戶和合作伙伴中包括有會話式AI領域的一流公司,比如Kensho、微軟、Nuance、Optum等。最后要
2019-11-08 19:44:51
類型在運行兩種常見的 FP32 ML 模型時的 ML 推理性能。我們將在以后的博客中介紹量化推理 (INT8) 的性能。工作負載[MLCommons]在其[MLPerf 推理基準套件]中提供了代表性
2022-08-31 15:03:46
三星打破上網(wǎng)本既有模式 性能尺寸接近傳統(tǒng)筆記本CNET科技資訊網(wǎng)7月1日國際報道 Nvidia證實,三星將推出一款采用其Ion芯片組的上網(wǎng)本,打破這類產品既有的模式。 Nvidia筆記本電腦產品部門
2009-07-01 21:47:27
網(wǎng)絡智能診斷平臺。通過對私有化網(wǎng)絡數(shù)據(jù)的定向訓練,信而泰打造了高性能、高可靠性的網(wǎng)絡診斷模型,顯著提升了AI輔助診斷的精準度與實用性。該方案實現(xiàn)了網(wǎng)絡全流量深度解析能力與AI智能推理分析能力的有機融合
2025-07-16 15:29:20
的是要知道它提供的選項來提高推理性能。作為開發(fā)人員,您會尋找可以壓縮的每一毫秒,尤其是在需要實現(xiàn)實時推理時。讓我們看一下Arm NN中可用的優(yōu)化選項之一,并通過一些實際示例評估它可能產生
2022-04-11 17:33:06
基于SRAM的方法可加速AI推理
2020-12-30 07:28:28
使用 PyTorch 對具有非方形圖像的 YOLOv4 模型進行了訓練。
將 權重轉換為 ONNX 文件,然后轉換為中間表示 (IR)。
無法確定如何獲得更好的推理性能。
2023-08-15 06:58:00
的參考。評估TI處理器模型性能的方式有兩種:TDA4VM入門套件評估模塊(EVM)或TI Edge AI Cloud,后者是一項免費在線服務,可支持遠程訪問TDA4VM EVM,以評估深度學習推理性能。借助
2022-11-03 06:53:28
生成兩個 IR文件(相同的 .xml 文件,但不同的 .bin 文件)
具有不同重量的類似模型,以不同的 fps (27fps 和 6fps) 運行
更多樣化的權重是否會影響 Myriad X 上的推理性能?
2023-08-15 07:00:25
1 簡介AI任務管理與統(tǒng)一的推理能力提供了接口的統(tǒng)一標準系統(tǒng)上CPU提供了AI任務調度管理的能力,對AI的能力進行了開放的推理和推理,同時,提供了一個不同的生命周期框架層級的應用程序。推理接口
2022-03-25 11:15:36
。
**英偉達Blackwell架構在數(shù)據(jù)中心方面的應用有哪些?**
1. **AI **大模型訓練
Blackwell 架構的 GPU 針對當前火爆的 AI 大模型進行了優(yōu)化,能夠顯著提升訓練和推理性能
2024-05-13 17:16:22
基于最小集覆蓋理論的擁塞鏈路推理算法,僅對共享瓶頸鏈路進行推理,當擁塞路徑存在多條鏈路擁塞時,算法的推理性能急劇下降.針對該問題,提出一種基于貝葉斯最大后驗(Bayesian maxlmum
2017-12-27 10:35:00 0
0 針對CLINK算法在路由改變時擁塞鏈路推理性能下降的問題,建立一種變結構離散動態(tài)貝葉斯網(wǎng)模型,通過引入馬爾可夫性及時齊性假設簡化該模型,并基于簡化模型提出一種IP網(wǎng)絡擁塞鏈路推理算法(VSDDB
2018-01-16 18:46:260 Azure Machine Learning SDK 相集成以供預覽。客戶可以使用 Azure 大規(guī)模部署的英特爾 FPGA(現(xiàn)場可編程邏輯門陣列)技術,為其模型提供行業(yè)領先的人工智能 (AI) 推理性能。 “作為一家整體技術提供商,我們通過與 Microsoft 密切合作為人工智能提供支持。
2018-05-20 00:10:003371 Xavier主要用于邊緣計算的深度神經網(wǎng)絡推理,其支持Caffe、Tensorflow、PyTorch等多種深度學習框架導出的模型。為進一步提高計算效率,還可以使用TensorRT對訓練好的模型利用
2019-04-17 16:55:4020004 
Nvidia用于開發(fā)和運行可理解和響應請求的對話式AI的GPU強化平臺,已經達成了一些重要的里程碑,并打破了一些記錄。
2019-08-15 14:26:252693 MLPerf Inference 0.5是業(yè)內首個獨立AI推理基準套件,其測試結果證明了NVIDIA Turing數(shù)據(jù)中心GPU以及 NVIDIA Xavier 邊緣計算芯片系統(tǒng)的性能。
2019-11-29 14:45:023401 2019年12月18日— — NVIDIA于今日發(fā)布一款突破性的推理軟件。借助于該軟件,全球各地的開發(fā)者都可以實現(xiàn)會話式AI應用,大幅減少推理延遲。而此前,巨大的推理延遲一直都是實現(xiàn)真正交互式互動的一大阻礙。
2019-12-19 10:06:511571 DeepCube專注于深度學習技術的研發(fā),這些技術可改善AI系統(tǒng)的實際部署。該公司的眾多專利創(chuàng)新包括更快,更準確地訓練深度學習模型的方法,以及在智能邊緣設備上大大提高的推理性能的方法。
2020-09-10 14:40:372449 你已經建立了你的深度學習推理模型并將它們部署到 NVIDIA Triton Inference Serve 最大化模型性能。 你如何進一步加快你的模型的運行速度? 進入 NVIDIA模型分析器 ,一
2020-10-21 19:01:031143 美國東部時間10月21日,全球備受矚目的權威AI基準測試MLPerf公布今年的推理測試榜單,浪潮AI服務器NF5488A5一舉創(chuàng)造18項性能紀錄,在數(shù)據(jù)中心AI推理性能上遙遙領先其他廠商產品
2020-10-23 16:59:442310 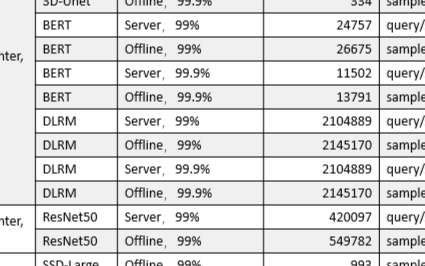
)的12個提交者增加了近一倍。 結果顯示,今年5月NVIDIA(Nvidia)發(fā)布的安培(Ampere)架構A100 Tensor Core GPU,在云端推理的基準測試性能是最先進Intel CPU
2020-10-23 17:40:025131 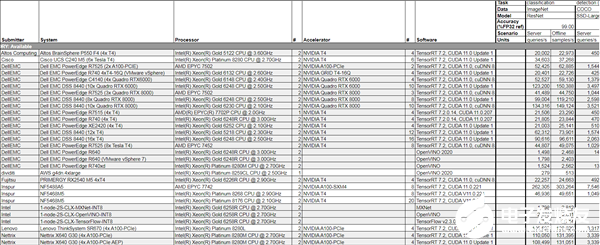
美國東部時間10月21日,全球倍受矚目的權威AI基準測試MLPerf公布今年的推理測試榜單,浪潮AI服務器NF5488A5一舉創(chuàng)造18項性能記錄,在數(shù)據(jù)中心AI推理性能上遙遙領先其他廠商產品。
2020-10-26 16:30:442328 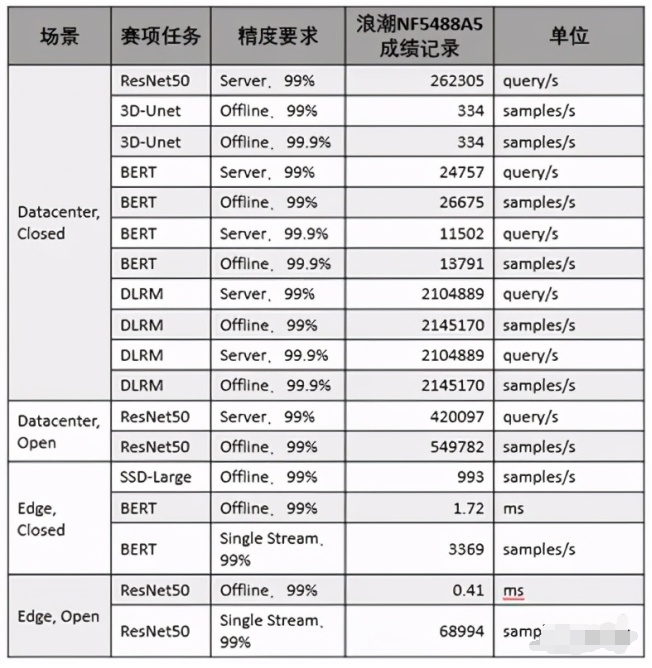
近日,在GTC China元腦生態(tài)技術論壇上,中科極限元、趨動科技、睿沿科技等元腦生態(tài)伙伴分享了多個場景下浪潮AI服務器NF5488A5的實測數(shù)據(jù),結果表明浪潮NF5488A5大幅提升了智能語音、圖像識別等AI模型的訓練和推理性能,促進了產業(yè)AI解決方案的開發(fā)與應用。
2020-12-24 15:25:013373 
一個支持邊緣實時推理的姿態(tài)估計模型,其推理性能比OpenPose模型快9倍。
2021-06-25 11:55:521852 基于8張NVIDIA A100 GPU和開放規(guī)則,以離線場景下每秒處理107.8萬張圖片的成績,打破MLPerf 1.0推理性能測試紀錄。 阿里云自研震旦異構計算加速平臺,適配GPU、ASIC等多種異構
2021-08-13 10:17:294431 ,其中的模型數(shù)量達數(shù)千個,日均調用服務達到千億級別。無量推薦系統(tǒng),在模型訓練和推理都能夠進行海量Embedding和DNN模型的GPU計算,是目前業(yè)界領先的體系結構設計。 傳統(tǒng)推薦系統(tǒng)面臨挑戰(zhàn) 傳統(tǒng)推薦系統(tǒng)具有以下特點: 訓練是基于參數(shù)
2021-08-23 17:09:035288 軟件的新功能,該軟件為所有AI模型和框架提供跨平臺推理;同時也包含對NVIDIA TensorRT的更新,該軟件優(yōu)化AI模型并為NVIDIA GPU上的高性能推理提供運行時優(yōu)化。 NVIDIA還推出了NVIDIA A2 Tensor Core GPU,這是一款用于邊
2021-11-12 14:42:532690 在首次參加行業(yè) MLPerf 基準測試時,基于 NVIDIA Ampere 架構的低功耗系統(tǒng)級芯片 NVIDIA Orin 就創(chuàng)造了新的AI推理性能紀錄,并在邊緣提升每個加速器的性能。
2022-04-08 10:14:445583 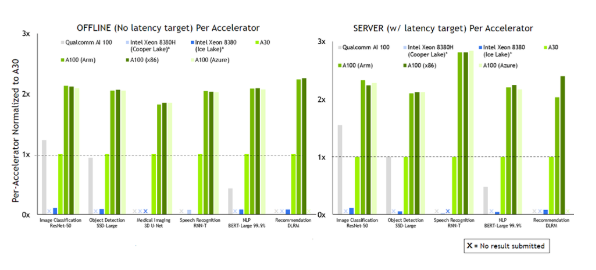
現(xiàn)在,您和開發(fā)人員社區(qū)的其他成員都可以使用這些成果,主要是以開源軟件的形式。此外, TensorRT 和 Triton 推理服務器可從?NVIDIA NGC?免費獲得,以及預訓練模型、深度學習框架
2022-04-08 16:31:311759 
“在使用 NVIDIA TensorRT和NVIDIA T4 GPU對平臺賦能后,“極星”推理平臺的算法推理效率得到了進一步的提升,更好地支持速接入各類算法、數(shù)據(jù)及智能設備,實現(xiàn)AI自閉環(huán)能力,并通過應用服務和標準化接口,幫助終端客戶低成本實現(xiàn)AI與業(yè)務的結合,快速構建智能應用。
2022-04-13 14:49:191588 NVIDIA Triton 有助于在每個數(shù)據(jù)中心、云和嵌入式設備中實現(xiàn)標準化的可擴展生產 AI 。它支持多個框架,在 GPU 和 DLA 等多個計算引擎上運行模型,處理不同類型的推理查詢。通過與 NVIDIA JetPack 的集成, NVIDIA Triton 可用于嵌入式應用。
2022-04-18 15:40:023480 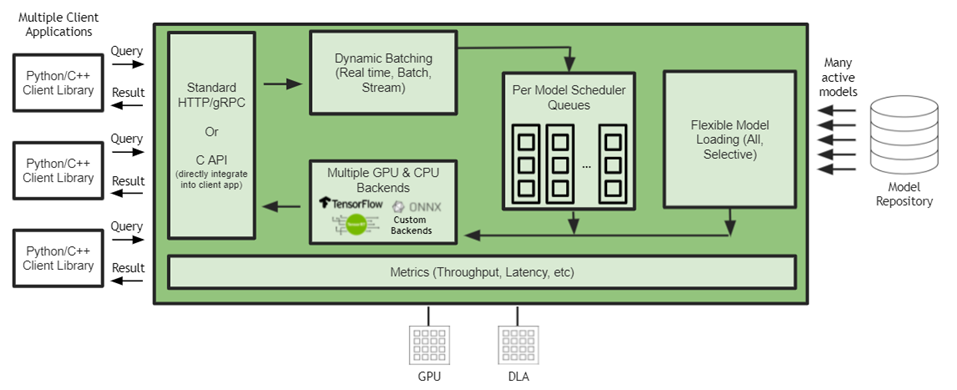
NVIDIA DRIVE Orin 現(xiàn)已投產,可在深度神經網(wǎng)絡推理性能方面實現(xiàn)重大飛躍。6 月 9 日,NVIDIA 將舉辦一場網(wǎng)絡會議,介紹 DNN 架構設計以及 NVIDIA TensorRT 的范圍,旨在為生產提供經過優(yōu)化的推理引擎。
2022-05-21 10:24:051974 最新的 AI 推理基準顯然具有重要意義,因為它是目前可用的最接近真實世界 AI 推理性能的衡量標準。但隨著它的成熟和吸引更多的提交,它也將成為成功部署技術堆棧的晴雨表和新實施的試驗場。
2022-07-08 15:37:552384 
綜上所述,這個新版本的 OpenVINO 工具包提供了許多好處,不僅優(yōu)化了用戶部署應用程序的體驗,還增強了性能參數(shù)。它使用戶能夠開發(fā)具有易于部署、更多深度學習模型、更多設備可移植性和更高推理性能且代碼更改更少的應用程序。
2022-07-12 10:08:571716 Kit 不僅大大提升了 GPU 集群上多機多卡分布式訓練的效率,對于 GPU 上的模型推理也通過集成 NVIDIA TensorRT 帶來了顯著加速。雙方團隊就 GPU 推理加速這一話題將進行持續(xù)深入的合作,推出定制化的優(yōu)化方案,為業(yè)界客戶帶來顯著的性能收益。
2022-08-31 09:24:072284 騰訊云 TI 平臺 TI-ONE 利用 NVIDIA Triton 推理服務器構造高性能推理服務部署平臺,使用戶能夠非常便捷地部署包括 TNN 模型在內的多種深度學習框架下獲得的 AI 模型,并且顯著提升推理服務的吞吐、提升 GPU 利用率。
2022-09-05 15:33:013067 螞蟻鏈 AIoT 團隊與 NVIDIA 合作,將量化感知訓練(QAT)技術應用于深度學習模型性能優(yōu)化中,并通過 NVIDIA TensorRT 高性能推理 SDK 進行高效率部署, 通過 INT8 推理, 吞吐量提升了 3 倍, 助力螞蟻鏈版權 AI 平臺中的模型推理服務大幅降本增效。
2022-09-09 09:53:521845 每個 AI 應用程序都需要強大的推理引擎。無論您是部署圖像識別服務、智能虛擬助理還是欺詐檢測應用程序,可靠的推理服務器都能提供快速、準確和可擴展的預測,具有低延遲(對單個查詢的響應時間較短)和高吞吐量(在給定時間間隔內處理大量查詢)。然而,檢查所有這些方框可能很難實現(xiàn),而且成本高昂。
2022-10-11 09:49:221955 
推理識別是人工智能最重要的落地應用,其他與深度學習相關的數(shù)據(jù)收集、標注、模型訓練等工作,都是為了得到更好的最終推理性能與效果。
2022-10-26 09:43:573382 為了解決AI部署落地難題,我們發(fā)起了FastDeploy項目。FastDeploy針對產業(yè)落地場景中的重要AI模型,將模型API標準化,提供下載即可運行的Demo示例。相比傳統(tǒng)推理引擎,做到端到端的推理性能優(yōu)化。
2022-11-08 14:28:123586 為了解決AI部署落地難題,我們發(fā)起了FastDeploy項目。FastDeploy針對產業(yè)落地場景中的重要AI模型,將模型API標準化,提供下載即可運行的Demo示例。相比傳統(tǒng)推理引擎,做到端到端的推理性能優(yōu)化。FastDeploy還支持在線(服務化部署)和離線部署形態(tài),滿足不同開發(fā)者的部署需求。
2022-11-10 10:18:322388 MLPerf是一套衡量機器學習系統(tǒng)性能的權威標準,將在標準目標下訓練或推理機器學習模型的時間,作為一套系統(tǒng)性能的測量標準。MLPerf推理任務包括圖像識別(ResNet50)、醫(yī)學影像分割
2022-11-10 14:43:402661 模型,并提供開箱即用的云邊端部署體驗,實現(xiàn) AI 模型端到端的推理性能優(yōu)化。 歡迎廣大開發(fā)者使用 NVIDIA 與飛槳聯(lián)合深度適配的 NGC 飛槳容器,在 NVIDIA GPU 上進
2022-12-13 19:50:052193 、NVIDIA 的技術專家將帶來 AI Infra 、 推理引擎 相關的專題分享,包括目前各企業(yè)面臨的模型推理挑戰(zhàn)、Triton 的應用及落地的具體方案等,現(xiàn)身說法,干貨十足。此外,還有來自蔚來
2023-02-15 16:10:05981 日 – NVIDIA于今日推出四款推理平臺。這些平臺針對各種快速興起的生成式AI應用進行了優(yōu)化,能夠幫助開發(fā)人員快速構建用于提供新服務和洞察的AI驅動的專業(yè)應用。 ? 這些平臺將NVIDIA的全棧推理
2023-03-22 14:48:39533 
AI推理性能對比 / Ampere 從性能對比上,我們可以看出AmpereOne在AI推理負載上的領先,比如在生成式AI和推薦算法上,AmpereOne的單機架性能是AMD EYPC 9654 Genoa的兩倍或以上,但兩者卻有著近乎相同的系統(tǒng)功耗,AmpereOne的優(yōu)勢在此展現(xiàn)得一覽無余。
2023-06-13 15:03:512172 
1792個CUDA和56個Tensor內核,使其算力能夠達到200TOPS。這使得BOXER-8640AI能夠同時在多個視頻流中利用顛覆性的轉換推理性能。研揚專業(yè)設計
2023-03-15 14:26:201435 
使用集成模型在 NVIDIA Triton 推理服務器上為 ML 模型管道提供服務
2023-07-05 16:30:342037 
達沃斯論壇|英特爾王銳:AI驅動工業(yè)元宇宙,釋放數(shù)實融合無窮潛力 英特爾研究院發(fā)布全新AI擴散模型,可根據(jù)文本提示生成360度全景圖 英特爾內部代工模式的最新進展 原文標題:英特爾? AMX 加速AI推理性能,助阿里電商推薦系統(tǒng)成功應對峰值負載
2023-07-08 14:15:03855 
能千行百業(yè) 人民網(wǎng)攜手英特爾啟動“數(shù)智加速度”計劃 WAIC 2023:英特爾以技術之力推動邊緣人工智能發(fā)展,打造數(shù)字化未來“芯”時代 英特爾 AMX 加速AI推理性能,助阿里電商推薦系統(tǒng)成功應對峰值負載壓力 原文標題:英特爾? AMX 助力百度ERNIE-T
2023-07-14 20:10:05736 
中,網(wǎng)絡軟、硬件對于端到端推理性能的影響。 在網(wǎng)絡評測中,有兩類節(jié)點:前端節(jié)點生成查詢,這些查詢通過業(yè)界標準的網(wǎng)絡(如以太網(wǎng)或 InfiniBand 網(wǎng)絡)發(fā)送到加速節(jié)點,由加速器節(jié)點進行處理和執(zhí)行推理。 圖 1:單節(jié)點封閉測試環(huán)境與多節(jié)點網(wǎng)絡測試環(huán)境 圖 1 顯示了在單個節(jié)點上運行的封閉測試環(huán)
2023-07-19 19:10:031854 
英特爾產品在全新MLCommons AI推理性能測試中盡顯優(yōu)勢 今日,MLCommons公布針對 60 億參數(shù)大語言模型及計算機視覺與自然語言處理模型GPT-J的 MLPerf推理v3.1 性能基準
2023-09-12 17:54:321117 
從云端到網(wǎng)絡邊緣,NVIDIA GH200、H100 和 L4 GPU 以及 Jetson Orin 模組在運行生產級 AI 時均展現(xiàn)出卓越性能。 NVIDIA GH200 Grace Hopper
2023-09-12 20:40:04900 從云端到網(wǎng)絡邊緣,NVIDIA GH200、H100和L4 GPU以及Jetson Orin模組在運行生產級 AI 時均展現(xiàn)出卓越性能。 ? ? ? NVIDIA GH200 Grace
2023-09-13 09:45:401159 
近日,MLCommons公布針對60億參數(shù)大語言模型及計算機視覺與自然語言處理模型GPT-J的MLPerf推理v3.1性能基準測試結果,其中包括英特爾所提交的基于Habana Gaudi 2加速器
2023-09-15 19:35:051060 
加利福尼亞州圣克拉拉——Nvidia通過一個名為TensorRT LLM的新開源軟件庫,將其H100、A100和L4 GPU的大型語言模型(LLM)推理性能提高了一倍。 正如對相同硬件一輪又一輪改進
2023-10-23 16:10:191426 由 CSDN 舉辦的 NVIDIA AI Inference Day - 大模型推理線上研討會,將幫助您了解 NVIDIA 開源大型語言模型(LLM)推理加速庫 TensorRT-LLM ?及其功能
2023-10-26 09:05:02684 NVIDIA 于 2023 年 10 月 19 日公開發(fā)布 TensorRT-LLM ,可在 NVIDIA GPU 上加速和優(yōu)化最新的大語言模型(Large Language Models)的推理性能
2023-10-27 20:05:021917 
交互速率運行的 Llama-2-70B 模型。 圖 1. 領先的生成式 AI 模型在? Jetson AGX Orin 上的推理性能 如要在 Jetson 上快速測試最新的模型和應用,請使用 Jetson 生成式 AI 實驗室提供的教程和資源。
2023-11-07 21:25:012182 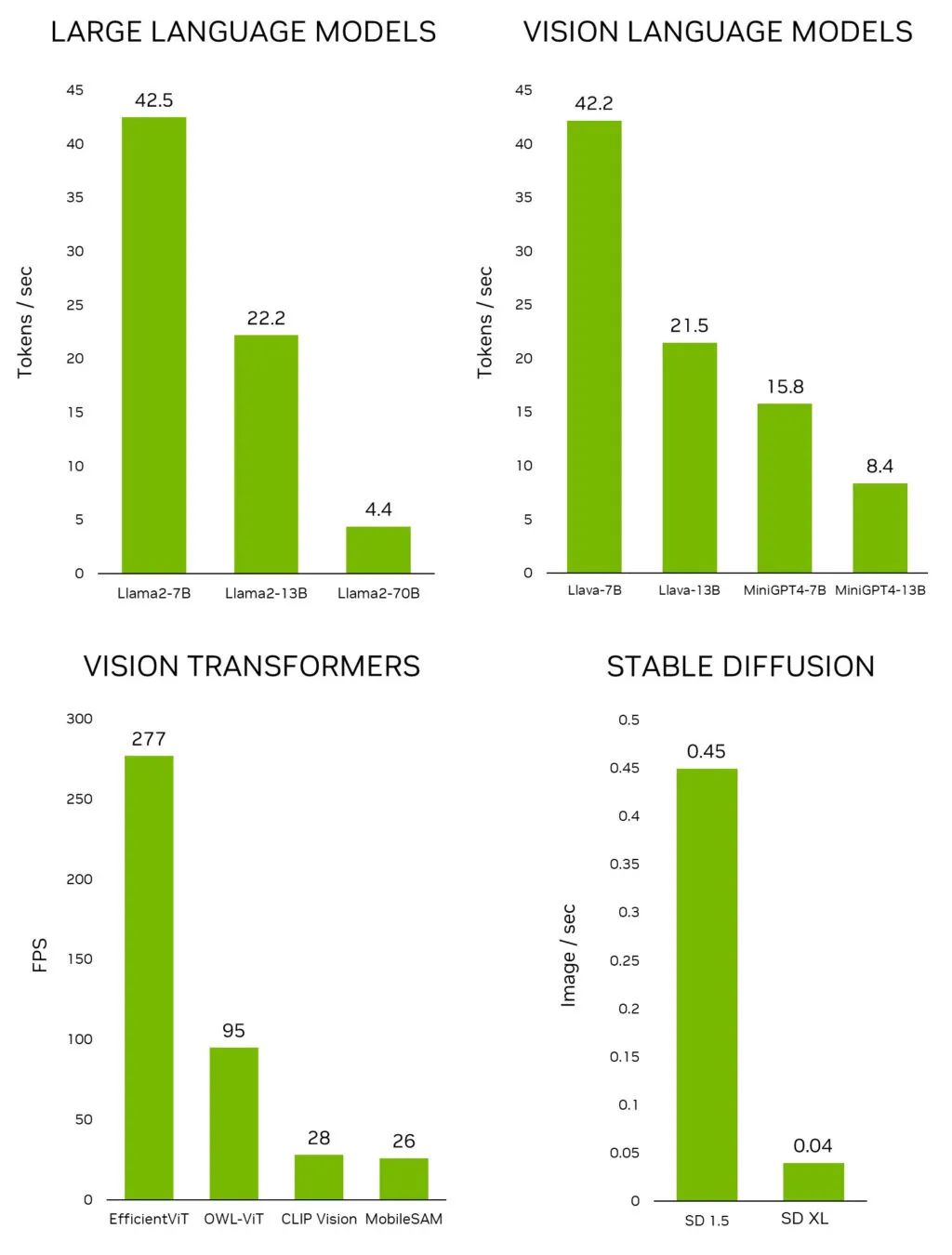
Gridspace 機器學習主管Wonkyum Lee表示:“我們的速度基準測試表明,在 Google Cloud TPU v5e 上訓練和運行時,AI 模型的速度提高了 5 倍。我們還看到推理
2023-11-24 10:27:301610 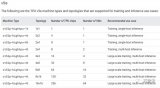
作者: 英特爾公司 沈海豪、羅嶼、孟恒宇、董波、林俊 編者按: 只需不到9行代碼, 就能在CPU上實現(xiàn)出色的LLM推理性能。 英特爾 ?Extension for Transformer 創(chuàng)新
2023-12-01 20:40:032133 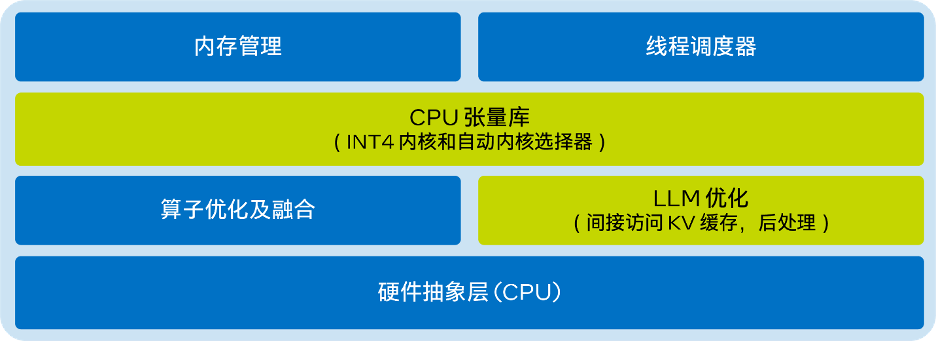
此外,至強可擴展處理器被譽為行業(yè)首屈一指的內置AI加速器數(shù)據(jù)中心處理器,全新第五代產品更能優(yōu)化參數(shù)量高達200億的大型語言模型,使其推理性能提升42%。眼下,它還是唯一歷次刷新MLPerf訓練及推理基準測試表現(xiàn)記錄并持續(xù)進步的CPU。
2023-12-15 11:02:551450 那么,什么是Torch TensorRT呢?Torch是我們大家聚在一起的原因,它是一個端到端的機器學習框架。而TensorRT則是NVIDIA的高性能深度學習推理軟件工具包。Torch TensorRT就是這兩者的結合。
2024-01-09 16:41:512996 
AI技術應用已經深入到各行各業(yè),特別是云服務提供商將AI能力集成到云服務中,能夠更好地滿足用戶對性能、效率和體驗的需求。
2024-01-13 10:46:111783 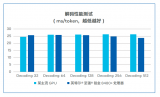
這家云計算巨頭的計算機視覺和數(shù)據(jù)科學服務使用 NVIDIA Triton 推理服務器來加速 AI 預測。
2024-02-29 14:04:401458 具有10TOPS/W能效的新一代AI加速器無需冷卻風扇即可提供高達80TOPS的AI推理性能
2024-03-01 10:41:381387 
Grace Blackwell Superchip、B200和B100 Tensor Core GPU等尖端產品,專為優(yōu)化AI訓練和推理性能而設計。
2024-03-25 10:27:441419 UL去年發(fā)布的首個Windows版Procyon AI推理基準測試,以計算機視覺工作負載評估AI推理性能。新推出的圖像生成測試將提供統(tǒng)一、精確且易于理解的工作負載,用以保證各支持硬件間公平、可比的性能表現(xiàn)。
2024-03-25 16:16:271773 當前,業(yè)界在將傳統(tǒng)優(yōu)化技術引入 LLM 推理的同時,同時也在探索從大模型自回歸解碼特點出發(fā),通過調整推理過程和引入新的模型結構來進一步提升推理性能。
2024-04-10 11:48:471564 
本實踐中,唯品會 AI 平臺與 NVIDIA 團隊合作,結合 NVIDIA TensorRT 和 NVIDIA Merlin HierarchicalKV(HKV)將推理的稠密網(wǎng)絡和熱 Embedding 全置于 GPU 上進行加速,吞吐相比 CPU 推理服務提升高于 3 倍。
2024-04-20 09:39:182014 英偉達近日宣布推出一項革命性的AI模型推理服務——NVIDIA NIM。這項服務將極大地簡化AI模型部署過程,為全球的2800萬英偉達開發(fā)者提供前所未有的便利。
2024-06-04 09:15:061278 NVIDIA 宣布推出全新 NVIDIA AI Foundry 服務和 NVIDIA NIM 推理微服務,與同樣剛推出的 Llama 3.1 系列開源模型一起,為全球企業(yè)的生成式 AI 提供強力支持。
2024-07-25 09:48:211350 “魔搭社區(qū)是中國最具影響力的模型開源社區(qū),致力給開發(fā)者提供模型即服務的體驗。魔搭社區(qū)利用NVIDIA TensorRT-LLM,大大提高了大語言模型的推理性能,方便了模型應用部署,提高了大模型產業(yè)應用效率,更大規(guī)模地釋放大模型的應用價值。”
2024-08-23 15:48:561661 。 中國電子技術標準化研究院賽西實驗室依據(jù)國家標準《人工智能服務器系統(tǒng)性能測試規(guī)范》(征求意見稿)相關要求,使用AISBench?2.0測試工具,完成了第五代英特爾至強可擴展處理器的AI大模型推理性能和精度測試。測試中,第五代英特爾至強在ChatGLM V2-6B(60億參
2024-09-06 15:33:521331 
麗蟾科技通過 Leaper 資源管理平臺集成 NVIDIA AI Enterprise,為企業(yè)和科研機構提供了一套高效、靈活的 AI 訓練與推理加速解決方案。無論是在復雜的 AI 開發(fā)任務中,還是在高并發(fā)推理場景下,都能夠確保項目的順利進行,并顯著提升業(yè)務效率與創(chuàng)新能力。
2024-10-27 10:03:251765 
Batching、Paged KV Caching、量化技術 (FP8、INT4 AWQ、INT8 SmoothQuant 等) 以及更多功能,確保您的 NVIDIA GPU 能發(fā)揮出卓越的推理性能。
2024-12-17 17:47:101694 生成式 AI 領域正在迅速發(fā)展,每天都有新的大語言模型(LLM)、視覺語言模型(VLM)和視覺語言動作模型(VLA)出現(xiàn)。為了在這一充滿變革的時代保持領先,開發(fā)者需要一個足夠強大的平臺將云端的最新模型無縫部署到邊緣,從而獲得基于 CUDA 的優(yōu)化推理性能和開放式機器學習(ML)框架。
2024-12-23 12:54:162079 
NVIDIA推理平臺提高了 AI 推理性能,為零售、電信等行業(yè)節(jié)省了數(shù)百萬美元。
2025-02-08 09:59:031512 
14B開源颶風,360掀起端側推理性能革命
2025-03-16 10:47:38957 
由 NVIDIA 后訓練的全新 Llama Nemotron 推理模型,為代理式 AI 提供業(yè)務就緒型基礎 埃森哲、Amdocs、Atlassian、Box、Cadence、CrowdStrike
2025-03-19 09:31:53352 
——Oracle 和 NVIDIA 今日宣布,NVIDIA 加速計算和推理軟件與 Oracle 的 AI 基礎設施以及生成式 AI 服務首次實現(xiàn)集成,以幫助全球企業(yè)組織加速創(chuàng)建代理式 AI 應用。 ? 此次
2025-03-19 15:24:36504 
NVIDIA Dynamo 提高了推理性能,同時降低了擴展測試時計算 (Scaling Test-Time Compute) 的成本;在 NVIDIA Blackwell 上的推理優(yōu)化將
2025-03-20 15:03:551120 英偉達GTC25亮點:NVIDIA Blackwell Ultra 開啟 AI 推理新時代
2025-03-20 15:35:401300 Oracle 數(shù)據(jù)庫與 NVIDIA AI 相集成,使企業(yè)能夠更輕松、快捷地采用代理式 AI Oracle 和 NVIDIA 宣布,NVIDIA 加速計算和推理軟件與 Oracle 的 AI
2025-03-21 12:01:551268 
創(chuàng)新技術——UCM推理記憶數(shù)據(jù)管理器,旨在推動AI推理體驗升級,提升推理性價比,加速AI商業(yè)正循環(huán)。同時,華為攜手中國銀聯(lián)率先在金融典型場景開展UCM技術試點應用,并聯(lián)合發(fā)布智慧金融AI推理加速方案應用成果。
2025-08-15 09:45:051090 的發(fā)布持續(xù)深化了雙方的 AI 創(chuàng)新合作。NVIDIA 在 NVIDIA Blackwell 架構上優(yōu)化了這兩款全新的開放權重模型并實現(xiàn)了推理性能加速,在 NVIDIA 系統(tǒng)上至高達到每秒 150 萬個
2025-08-15 20:34:402078 
本文詳細闡述了 NVIDIA NVLink Fusion 如何借助高效可擴展的 NVIDIA NVLink scale-up 架構技術,滿足日益復雜的 AI 模型不斷增長的需求。
2025-09-23 14:45:25739 
NVIDIA 的數(shù)據(jù)工廠團隊為 NVIDIA Cosmos Reason 等 AI 模型奠定了基礎,該模型近日在 Hugging Face 的物理推理模型排行榜中位列榜首。
2025-09-23 15:19:231043 在第三屆 NVIDIA DPU 中國黑客松競賽中,我們見證了開發(fā)者與 NVIDIA 網(wǎng)絡技術的深度碰撞。在 23 支參賽隊伍中,有 5 支隊伍脫穎而出,展現(xiàn)了在 AI 網(wǎng)絡、存儲和安全等領域的創(chuàng)新突破。
2025-09-23 15:25:31841 TensorRT LLM 作為 NVIDIA 為大規(guī)模 LLM 推理打造的推理框架,核心目標是突破 NVIDIA 平臺上的推理性能瓶頸。為實現(xiàn)這一目標,其構建了多維度的核心實現(xiàn)路徑:一方面,針對需
2025-10-21 11:04:24923 Jetson Thor 平臺還支持多種主流量化格式,包括 NVIDIA Blackwell GPU 架構的新 NVFP4 格式,有助于進一步優(yōu)化推理性能。該平臺同時支持推測解碼等新技術,為在邊緣端加速生成式 AI 工作負載提供了新的途徑。
2025-10-29 16:53:181249
 電子發(fā)燒友App
電子發(fā)燒友App








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論