") 使用NVIDIA NVLink Fusion技術(shù)提升AI推理性能
使用NVIDIA NVLink Fusion技術(shù)提升AI推理性能

AI 模型復(fù)雜性的指數(shù)級增長驅(qū)動參數(shù)規(guī)模從數(shù)百萬迅速擴展到數(shù)萬億,對計算資源提出了前所未有的需求,必須依賴大規(guī)模 GPU 集群才能滿足。混合專家(MoE)架構(gòu)的廣泛應(yīng)用以及測試時擴展(test-time scaling)在推理階段的引入,進一步加劇了計算負載。為實現(xiàn)高效的推理部署,AI 系統(tǒng)已發(fā)展出大規(guī)模并行化策略,包括張量并行、流水線并行和專家并行等技術(shù)。這些需求推動了支持內(nèi)存語義的縱向擴展(Scale-up)計算網(wǎng)絡(luò)向更大的 GPU 域演進,構(gòu)建統(tǒng)一的計算與內(nèi)存資源池,實現(xiàn)高效協(xié)同。
本文詳細闡述了NVIDIA NVLink Fusion如何借助高效可擴展的 NVIDIA NVLink scale-up 架構(gòu)技術(shù),滿足日益復(fù)雜的 AI 模型不斷增長的需求。
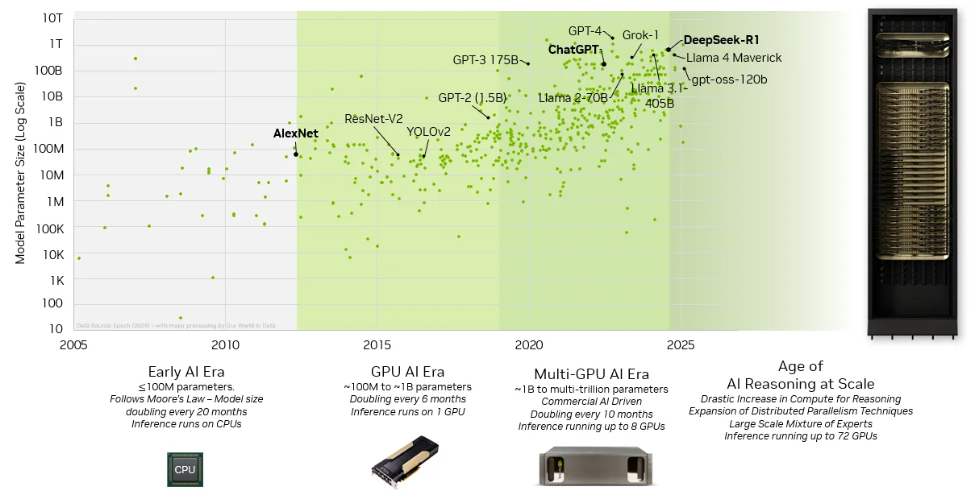
圖 1:模型規(guī)模與復(fù)雜性的提升推動了 scale-up 域的擴展
NVLink 如何持續(xù)演進以滿足不斷增長的 scale-up 需求
NVIDIA 于 2016 年首次推出 NVLink,旨在克服 PCIe 在高性能計算和人工智能工作負載中的局限性。該技術(shù)實現(xiàn)了更快的 GPU 間通信,并構(gòu)建了統(tǒng)一的內(nèi)存空間。
2018年,NVIDIA 推出了 NVLink Switch 技術(shù),實現(xiàn)了在 8 個 GPU 的網(wǎng)絡(luò)拓撲中每對 GPU 之間高達 300 GB/s 的 all-to-all 帶寬,為多 GPU 計算時代的 scale-up 網(wǎng)絡(luò)奠定了基礎(chǔ)。隨后,在第三代 NVLink Switch 中引入了 NVIDIA 可擴展分層聚合與歸約協(xié)議(SHARP)技術(shù),進一步提升了性能,有效優(yōu)化了帶寬性能并降低了集合操作的延遲。
隨著 2024 年第五代 NVLink 的發(fā)布,進一步增強的 NVLink Switch 支持 72 個 GPU 實現(xiàn)全互聯(lián)通信,通信速率達 1800 GB/s,聚合總帶寬高達 130 TB/s,較第一代產(chǎn)品提升了 800 倍。
盡管 NVIDIA 已大規(guī)模部署 NVLink 近十年,但仍在不斷突破技術(shù)極限,對未來三代的 NVLink 產(chǎn)品,會保持每年推出一代的節(jié)奏。這一迭代策略推動了持續(xù)的技術(shù)進步,有效滿足了 AI 模型在復(fù)雜性和計算需求方面的指數(shù)級增長。
NVLink 的性能取決于硬件和通信庫,尤其是 NVIDIA 集群通信庫(NCCL)。
NCCL 作為一個開源庫,專為加速單節(jié)點和多節(jié)點拓撲中 GPU 之間的通信而設(shè)計,能夠?qū)崿F(xiàn)接近理論帶寬的 GPU 到 GPU 通信性能。它無縫支持橫向和縱向擴展,具備自動拓撲感知與優(yōu)化能力。NCCL 已集成到所有主流深度學(xué)習(xí)框架中,歷經(jīng) 10 年的開發(fā)與 10 年的生產(chǎn)環(huán)境部署,技術(shù)成熟且廣泛應(yīng)用。

圖 2:NCCL 支持縱向擴展和橫向擴展,在所有主流框架中均受支持
最大化 AI 工廠收入
NVIDIA 在 NVLink 硬件和軟件庫方面積累了豐富的經(jīng)驗,配合大規(guī)模的計算域,能夠有效滿足當(dāng)前 AI 推理計算的需求。其中,72-GPU 機架架構(gòu)在多種應(yīng)用場景中實現(xiàn)了卓越的推理性能,發(fā)揮了關(guān)鍵作用。在評估大語言模型(LLM)推理性能時,前沿帕累托(Frontier Pareto)曲線清晰地展現(xiàn)了每瓦吞吐量與延遲之間的權(quán)衡關(guān)系。
AI 工廠的生產(chǎn)和收入目標(biāo)是最大化曲線下的面積。影響該曲線動態(tài)的因素眾多,包括原始算力、內(nèi)存容量與吞吐量,以及 scale-up 技術(shù),通過高速通信優(yōu)化實現(xiàn)張量并行、流水線并行和專家并行等技術(shù)。
在檢查各類 scale-up 配置的性能時,我們發(fā)現(xiàn)存在顯著差異,即使是使用相同的 NVLink 速度。
在 4 個 GPU 的 NVLink mesh 拓撲(無交換機)中,由于每對 GPU 之間只能分到有限帶寬,曲線會呈現(xiàn)下降趨勢。
采用 NVLink Switch 的 8 GPU 網(wǎng)絡(luò)拓撲能顯著提升性能,因為每對 GPU 之間均實現(xiàn)完全帶寬。
通過 NVLink Switch 擴展至 72 個 GPU 的域,可最大限度地提升性能和收益。
NVLink Fusion 實現(xiàn)對NVLink scale-up 技術(shù)的定制化使用
NVIDIA 推出了 NVLink Fusion,使超大規(guī)模數(shù)據(jù)中心能夠采用經(jīng)過生產(chǎn)驗證的 NVLink scale-up 技術(shù)。該技術(shù)可讓定制芯片(包括 CPU 和 XPU)與 NVIDIA 的 NVLink scale-up 網(wǎng)絡(luò)技術(shù)以及機架級擴展架構(gòu)相集成,從而實現(xiàn)半定制化的 AI 基礎(chǔ)設(shè)施部署。
NVLink scale-up 技術(shù)涵蓋 NVLink SERDES、NVLink chiplets、NVLink 交換機以及機架級擴展架構(gòu)的整體方案。高密度機架級擴展架構(gòu)包括 NVLink spine、銅纜系統(tǒng)、創(chuàng)新的機械結(jié)構(gòu)、先進的供電與液冷技術(shù),以及供應(yīng)鏈就緒的完整生態(tài)系統(tǒng)。
NVLink Fusion 為定制 CPU、定制 XPU 或兩者的組合配置提供了靈活的解決方案。作為模塊化開放計算項目(OCP)MGX 機架架構(gòu)的一部分,NVLink Fusion 可與任何網(wǎng)卡(NIC)、數(shù)據(jù)處理器(DPU)或橫向擴展交換機集成,使客戶能夠根據(jù)需求靈活構(gòu)建理想的系統(tǒng)。
對于自定義 XPU 配置,NVLink 通過通用芯粒互連(Universal Chiplet Interconnect Express, UCIe)IP 與接口實現(xiàn)集成。NVIDIA 提供支持 UCIe 的 NVLink 橋接芯片,既能實現(xiàn)極高性能,又便于集成,使客戶能夠像 NVIDIA 一樣充分利用 NVLink 的功能。UCIe 作為一項開放標(biāo)準(zhǔn),采用該接口進行 NVLink 集成可讓客戶為其 XPU 靈活選擇當(dāng)前或未來平臺的多種方案。
對于自定義 CPU 配置,建議集成 NVIDIA NVLink-C2C IP,以連接 NVIDIA GPU,從而實現(xiàn)最佳性能。采用定制 CPU 與 NVIDIA GPU 的系統(tǒng)可平滑訪問 CUDA 平臺的數(shù)百個 NVIDIA CUDA-X 庫,充分發(fā)揮加速計算的高性能優(yōu)勢。
由廣泛的生產(chǎn)就緒合作伙伴生態(tài)系統(tǒng)提供有力支持
NVLink Fusion 擁有一個強大的芯片生態(tài)系統(tǒng),涵蓋定制芯片、CPU 以及 IP 技術(shù)合作伙伴,不僅確保了廣泛的技術(shù)支持和快速的設(shè)計實現(xiàn),還持續(xù)推動著技術(shù)創(chuàng)新。
對于機架產(chǎn)品,用戶可受益于我們的系統(tǒng)合作伙伴網(wǎng)絡(luò)以及數(shù)據(jù)中心基礎(chǔ)設(shè)施組件供應(yīng)商。這些合作伙伴和供應(yīng)商已實現(xiàn) NVIDIA Blackwell NVL72 系統(tǒng)的大規(guī)模生產(chǎn)。通過整合生態(tài)系統(tǒng)與供應(yīng)鏈資源,用戶能夠加快產(chǎn)品上市速度,并顯著縮短機架級擴展系統(tǒng),以及 scale-up 網(wǎng)絡(luò)的生產(chǎn)部署時間。
提升 AI 推理性能
NVLink 代表了滿足 AI 推理時代計算需求的重大飛躍。NVLink Fusion 充分融合了 NVIDIA 在 NVLink scale-up 技術(shù)領(lǐng)域長達十年的深厚積累,結(jié)合 OCP MGX 機架架構(gòu)及生態(tài)系統(tǒng)開放的生產(chǎn)部署標(biāo)準(zhǔn),為超大規(guī)模數(shù)據(jù)中心提供了卓越的性能與全面的定制化選項。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5674瀏覽量
110026 -
AI
+關(guān)注
關(guān)注
91文章
40579瀏覽量
302221 -
模型
+關(guān)注
關(guān)注
1文章
3791瀏覽量
52217
原文標(biāo)題:借助 NVIDIA NVLink 和 NVLink Fusion 擴展 AI 推理性能和靈活性
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
英特爾FPGA 助力Microsoft Azure機器學(xué)習(xí)提供AI推理性能
NVIDIA擴大AI推理性能領(lǐng)先優(yōu)勢,首次在Arm服務(wù)器上取得佳績

NVIDIA打破AI推理性能記錄
進一步解讀英偉達 Blackwell 架構(gòu)、NVlink及GB200 超級芯片
NVIDIA 在首個AI推理基準(zhǔn)測試中大放異彩
求助,為什么將不同的權(quán)重應(yīng)用于模型會影響推理性能?
如何提高YOLOv4模型的推理性能?
英特爾FPGA為人工智能(AI)提供推理性能
NVIDIA A100 GPU推理性能237倍碾壓CPU
NVIDIA發(fā)布最新Orin芯片提升邊緣AI標(biāo)桿
Nvidia 通過開源庫提升 LLM 推理性能
開箱即用,AISBench測試展示英特爾至強處理器的卓越推理性能

使用NVIDIA推理平臺提高AI推理性能




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論