 從零復現,全面開源:360 Light-R1-14B/7B帶來端側AI平權時刻
從零復現,全面開源:360 Light-R1-14B/7B帶來端側AI平權時刻


性能領先、開源普惠、國產易獲取的三重勢能,造就了年初DeepSeek的技術平權狂熱,掀起AI普惠浪潮。
然而,當很多人想在端側部署DeepSeek模型時,卻遭遇了挑戰:部署滿血版大模型需數萬元硬件投入,退而求其次選擇蒸餾版14B版本,又會出現性能斷崖式下跌與響應延遲。
就在AI用戶陷入“高成本部署”與“低質量妥協”的兩難困境時,端側AI的破局時刻,悄悄被360打開了。
近期,360智腦團隊發布了最強14B推理模型:Light-R1-14B-DS,是業界首次在14B模型上復現強化學習效果。數學能力上,表現超過
DeepSeek-R1-Distill-Llama-70B和DeepSeek-R1-Distill-Qwen-32B。

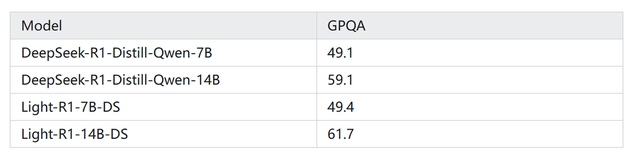
盡管只訓練了MATH數據,但在GPQA科學常識評測中,7B/14B雙版本均超越對標產品,展現出“小參數大智慧”的泛化能力。
此外,配合360的全面開源策略(模型/數據/代碼/技術報告全開放),這場端側AI平權運動,意味著14B模型能在手機端流暢運行,意味著企業無需天價算力即可部署專業級AI。
AI端側民主化的風暴眼,正在醞釀之中。

我們第一時間研讀了360放出的技術報告,發現端側AI的技術拐點已經出現。360開源的Light-R1-14B-DS創造了三項行業紀錄:
一是能力復現。Light-R1-14B-DS首次在數學能力上,用14B 模型復現了強化學習效果,通過多階段課程學習SFT和強化學習,Light-R1-14B-DS的表現超過
DeepSeek-R1-Distill-Llama-70B和DeepSeek-R1-Distill-Qwen-32B,是目前最優的14B模型,這驗證了RL強化學習策略的有效性,RL對端側模型訓練的收益很大,仍有進一步挖掘潛力。
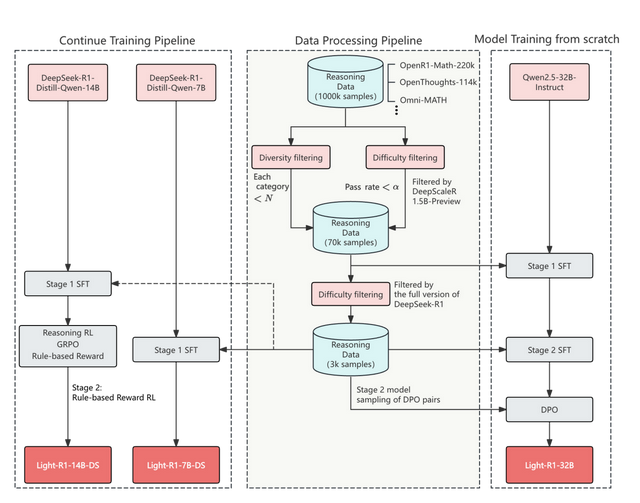
(Light-R1 訓練流程)
二是效率革命。Light-R1-14B-DS 經過長思維鏈強化學習后訓練,在AIME 24和25上分別取得了74.0和60.2的成績,數學部分表現超越DeepSeek的70B(72.6分)和32B(54.9分)蒸餾模型,取得了非常顯著的提升,這標志著推理能耗進一步降低。另一版本的Light-R1-7B-DS,無需量化即可端側部署。此次探索,在低成本復現 DeepSeek-R1方面邁出了重要一步。
三是泛化能力增強。Light-R1-14B-DS在科學常識評測GPQA上漲,打破了模型“災難性遺忘”的魔咒,具有較好的泛化性,開辟模型優化新路徑。
最強14B端側推理模型,撕開了DeepSeek 70B的性能封鎖線,端側AI迎來了規模化普及的拐點。不過,在AI與大眾之間,還差一個開源。

如果僅有技術突破,但沒有開源機制,那么端側推理模型再好,也無法被大眾輕松獲得、低成本用起來。
此次,360采取了全棧式的開源策略——模型權重、22萬條數學數據集、RL訓練代碼、技術報告等,都悉數公開。這種開源深度,遠遠超過了常規模型權重開放。
也就是說,中小團隊僅需極少算力,就能從數據清洗到強化學習全鏈路復現,完成端側AI的后訓練與部署。
端側AI的民主化,高度依賴于科技企業的開源策略,為什么說360此次開放端側推理模型很重要?
對企業來說,傳統端側AI部署,會面臨閉源模型高昂的授權費用(如OpenAI API調用成本)與硬件適配的邊際成本(需定制化芯片或服務器),成本難以承受。此前openai也發布過蒸餾版o1-mini,但高昂的訂閱費依然讓大量開發者望而卻步。此外,閉源模型存在不可解釋性風險,醫療、法律等行業因合規要求無法接受“輸入-輸出”不透明的AI決策。因此,Light-R1-14B-DS這樣低成本、全開源的國產端側推理模型,有望打消企業對AI的顧慮,輕松邁入智能化。
對個人來講,云端模型需要上傳數據,這會引發隱私泄露的顧慮。而在端側離線運行大模型,又對算力/內存有更高的要求,傳統端側AI需要旗艦級設備,買不起旗艦機,就用不到好AI,這形成了一種AI時代的“設備歧視”。
360開源最強14B端側模型,讓端側AI能力不再是少數機型的特權,也可以下沉到普惠機型上,為大眾所用。而用戶規模的擴大,也會推動AI應用及大模型產品的增長。
由此看到,360開源策略所帶來的技術民主化,可以激活AI的長尾需求,加速AI普惠的到來。

終端設備,是用好AI的載體。推理模型下沉到端側,應用空間也十分廣闊,打開了端側AI的無限想象空間。
預測一下,目前這兩個最強端側14B/7B推理模型,可能會首先落地在商業價值高的場景,然后一步步滲透進各行業。
首當其沖的,就是消費電子領域。智能手機、手表、平板、PC、眼鏡等終端設備,近兩年都在加速AI化。
但此前AI化有兩種方案:一是純端側,保證本地隱私安全,但內存要求高,功耗大;另一種是端云結合,部分任務上云處理。Light-R1-7B-DS無需量化即可部署于終端設備(如手機、IoT設備),標志著消費級硬件也能運行復雜AI任務。對比傳統需要32B以上參數的端側模型,其7B規模大幅降低內存占用和能耗。為AI終端帶來了更大的創新空間,比如在手機本地運行復雜數學輔導、法律文書解析等任務,解決隱私和延遲痛點。
360的技術突破與全棧開源,可以為消費電子領域的AI探索帶來非常有益的借鑒。
下一個就是重點行業、垂直領域。金融、政務、醫療、法律等數字化基礎較好的行業,積極擁抱AI,又希望在本地化運行專業級AI,避免敏感數據上傳云端,這就需要專有模型+后訓練,最強端側14B/7B推理模型可以大幅降低端側專有模型的訓練、推理等硬件門檻,加速行業智能化探索。
更進一步,傳統行業壁壘也將被端側普惠AI撕開。比如智慧城市治理,通過部署端側AI的邊緣智能計算,可以極大減少智能化的建設和升級運維成本;農業智能化,搭載14B模型的農業無人機,路線自動避障、精準識別地面等能力,都會隨著推理能力的增強而大幅提升。
通過端側AI的普惠路線圖,來進行推演,不難看到,360的技術突破與開源策略,一定會吸引大量行業開發者或個人開發者前來試用,與豐富的場景相結合,催生大量智能化的長尾應用。
也就是說,通過開源輕量級推理模型,360有望規避AI六小強在千億參數級的競爭。基于開源開放的技術公信力,構建開發者生態護城河。從這個角度看,360掀起的端側AI颶風,也將卷出一個大模型競爭的新格局。
端側推理模型的平權時刻已到,萬億級邊緣智能市場正蓄勢待發、乘風遠航。

審核編輯 黃宇
-
AI
+關注
關注
91文章
39755瀏覽量
301346 -
開源
+關注
關注
3文章
4203瀏覽量
46120
發布評論請先 登錄
太強了!AI PC搭載70B大模型,算力狂飆,內存開掛

端側大模型上車:從“語音助手”到“車內 AI 智能體”的躍遷革命
從云端到邊緣:聯發科MT8371/MT8391平臺實現7B大模型本地部署
基于合眾恒躍rk3576?開發板deepseek-r1-1.5b/7b 部署指南

此芯科技發布“合一”AI加速計劃,賦能邊緣與端側AI創新

Arm率先適配騰訊混元開源模型,助力端側AI創新開發
華為宣布開源盤古7B稠密和72B混合專家模型
華為正式開源盤古7B稠密和72B混合專家模型
帶增益的 RX 分集 FEM(B26、B8、B20、B1/4、B3 和 B7) skyworksinc

帶增益的 RX 分集 FEM(B3、B39、B1、B40、B41 和 B7) skyworksinc
在阿里云PAI上快速部署NVIDIA Cosmos Reason-1模型
【幸狐Omni3576邊緣計算套件試用體驗】CPU部署DeekSeek-R1模型(1B和7B)
首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手
具有載波聚合的 RX 分集 FEM(B26、B8、B20、B1/4、B3 和 B7) skyworksinc



 工商網監
工商網監
評論