") 利用 NVIDIA Jetson 實現(xiàn)生成式 AI
利用 NVIDIA Jetson 實現(xiàn)生成式 AI

近日,NVIDIA 發(fā)布了 Jetson 生成式 AI 實驗室(Jetson Generative AI Lab),使開發(fā)者能夠通過 NVIDIA Jetson 邊緣設備在現(xiàn)實世界中探索生成式 AI 的無限可能性。不同于其他嵌入式平臺,Jetson 能夠在本地運行大語言模型(LLM)、視覺 Transformer 和 stable diffusion,包括在 Jetson AGX Orin 上以交互速率運行的 Llama-2-70B 模型。
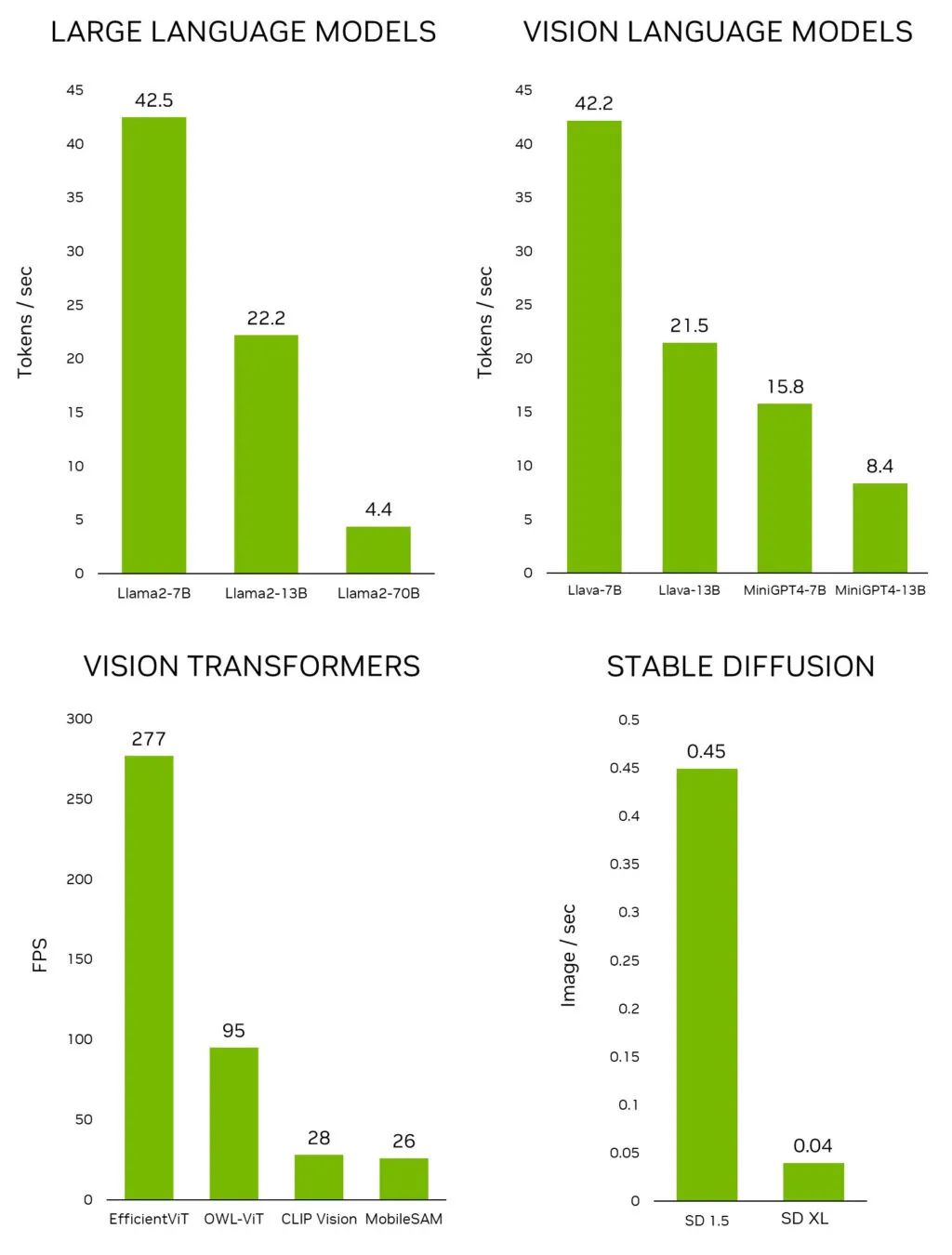
圖 1. 領(lǐng)先的生成式 AI 模型在
Jetson AGX Orin 上的推理性能
如要在 Jetson 上快速測試最新的模型和應用,請使用 Jetson 生成式 AI 實驗室提供的教程和資源。現(xiàn)在,您可以專注于發(fā)掘生成式 AI 在物理世界中尚未被開發(fā)的潛力。
本文將探討可以在 Jetson 設備上運行和體驗到的振奮人心的生成式 AI 應用,所有這些也都在實驗室的教程中予以了說明。
邊緣生成式 AI
在快速發(fā)展的 AI 領(lǐng)域,生成式模型和以下模型備受關(guān)注:
-
能夠參與仿照人類對話的 LLM。
-
使 LLM 能夠通過攝像機感知和理解現(xiàn)實世界的視覺語言模型(VLM)。
-
可將簡單的文字指令轉(zhuǎn)換成驚艷圖像的擴散模型。
這些在 AI 領(lǐng)域的巨大進步激發(fā)了許多人的想象力。但是,如果您去深入了解支持這種前沿模型推理的基礎(chǔ)架構(gòu),就會發(fā)現(xiàn)它們往往被“拴”在云端,依賴其數(shù)據(jù)中心的處理能力。這種以云為中心的方法使得某些需要高帶寬、低延遲的數(shù)據(jù)處理的邊緣應用在很大程度上得不到開發(fā)。
視頻 1. NVIDIA Jetson Orin 為邊緣帶來強大的生成式 AI 模型
在本地環(huán)境中運行 LLM 和其他生成式模型這一新趨勢正在開發(fā)者社群中日益盛行。蓬勃發(fā)展的在線社區(qū)為愛好者提供了一個討論生成式 AI 技術(shù)最新進展及其實際應用的平臺,如 Reddit 上的 r/LocalLlama。在 Medium 等平臺上發(fā)表的大量技術(shù)文章深入探討了在本地設置中運行開源 LLM 的復雜性,其中一些文章提到了利用 NVIDIA Jetson。
Jetson 生成式 AI 實驗室是發(fā)現(xiàn)最新生成式 AI 模型和應用,以及學習如何在 Jetson 設備上運行它們的中心。隨著該領(lǐng)域快速發(fā)展,幾乎每天都有新的 LLM 出現(xiàn),并且量化程序庫的發(fā)展也在一夜之間重塑了基準,NVIDIA 認識到了提供最新信息和有效工具的重要性。因此我們提供簡單易學的教程和預構(gòu)建容器。
而實現(xiàn)這一切的是 jetson-containers,一個精心設計和維護的開源項目,旨為 Jetson 設備構(gòu)建容器。該項目使用 GitHub Actions,以 CI/CD 的方式構(gòu)建了 100 個容器。這些容器使您能夠在 Jetson 上快速測試最新的 AI 模型、程序庫和應用,無需繁瑣地配置底層工具和程序庫。
通過 Jetson 生成式 AI 實驗室和 jetson-containers,您可以集中精力使用 Jetson 探索生成式 AI 在現(xiàn)實世界中的無限可能性。
演示
以下是一些振奮人心的生成式 AI 應用,它們在 Jetson 生成式 AI 實驗室所提供的 NVIDIA Jetson 設備上運行。
stable-diffusion-webui
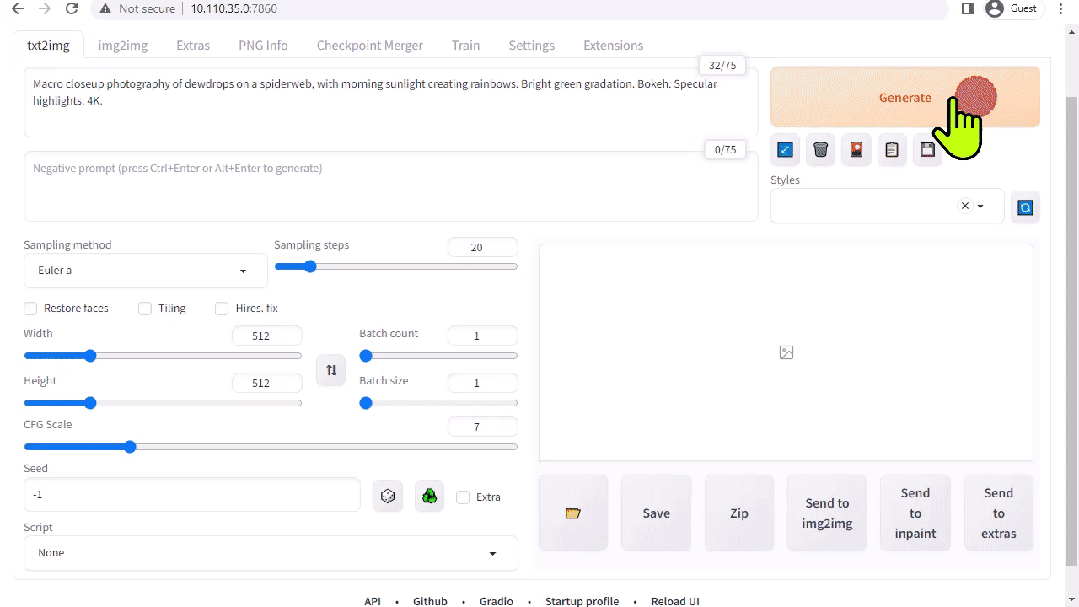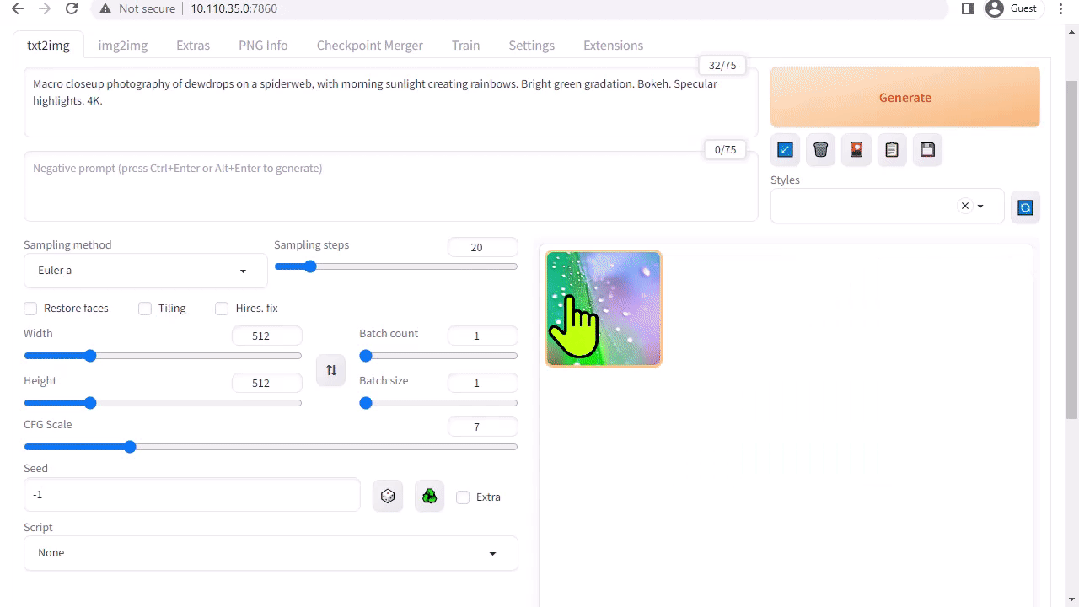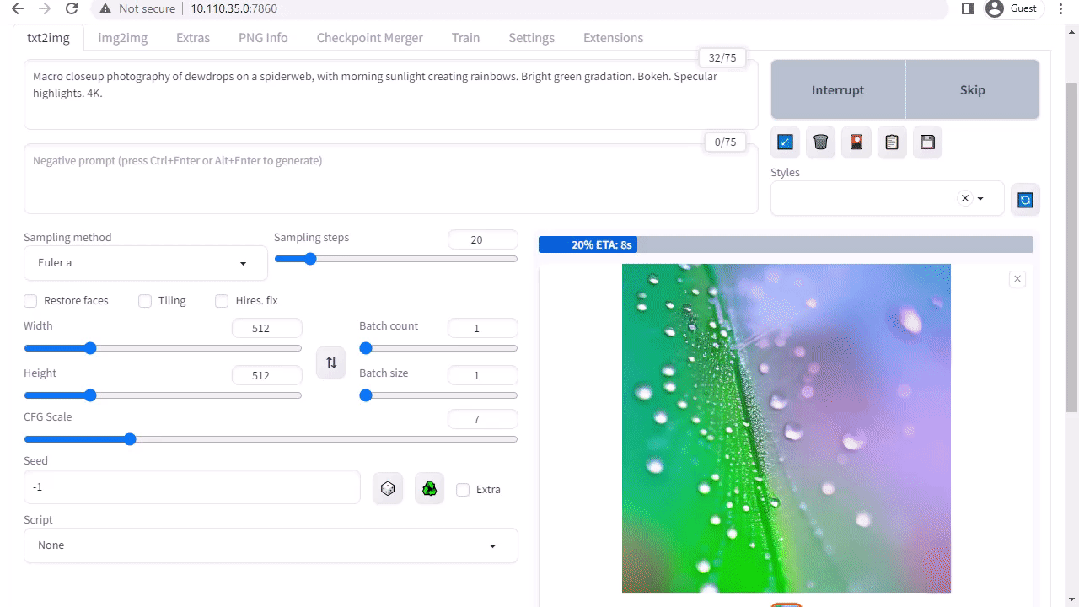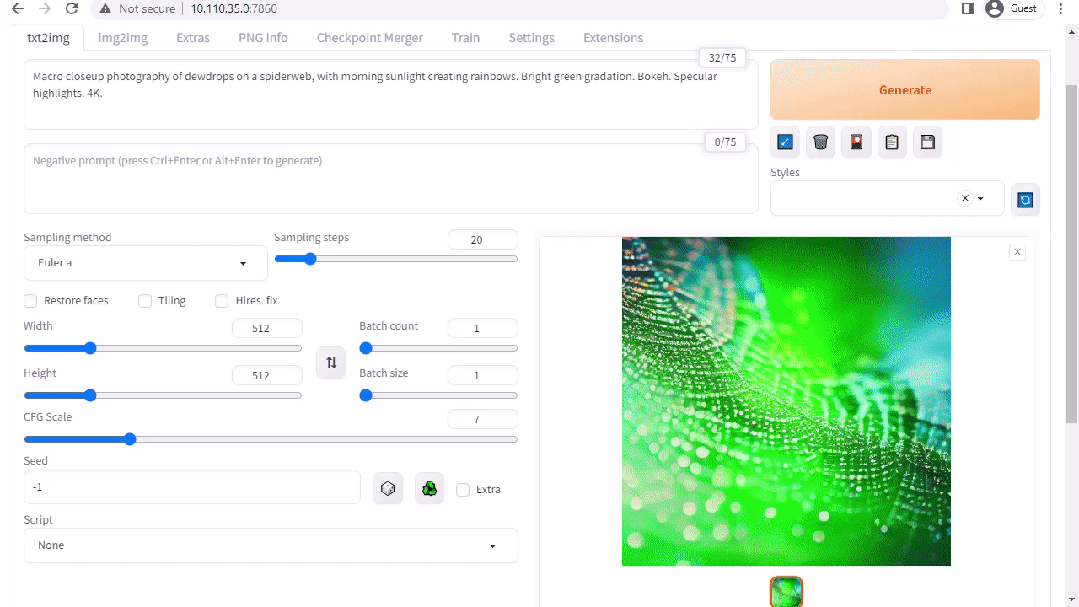
圖 2. Stable Diffusion 界面
A1111 的 stable-diffusion-webui 為 Stability AI 發(fā)布的 Stable Diffusion 提供了一個用戶友好界面。您可以使用它執(zhí)行許多任務,包括:
-
文本-圖像轉(zhuǎn)換:根據(jù)文本指令生成圖像。
-
圖像-圖像轉(zhuǎn)換:根據(jù)輸入圖像和相應的文本指令生成圖像。
-
圖像修復:對輸入圖像中缺失或被遮擋的部分進行填充。
-
圖像擴展:擴展輸入圖像的原有邊界。
網(wǎng)絡應用會在首次啟動時自動下載 Stable Diffusion v1.5 模型,因此您可以立即開始生成圖像。如果您有一臺 Jetson Orin 設備,就可以按照教程說明執(zhí)行以下命令,非常簡單。
git clone https://github.com/dusty-nv/jetson-containers
cd jetson-containers
./run.sh$(./autotagstable-diffusion-webui)
有關(guān)運行 stable-diffusion-webui 的更多信息,參見 Jetson 生成式 AI 實驗室教程。Jetson AGX Orin 還能運行較新的 Stable Diffusion XL(SDXL)模型,本文開頭的主題圖片就是使用該模型生成的。
text-generation-webui
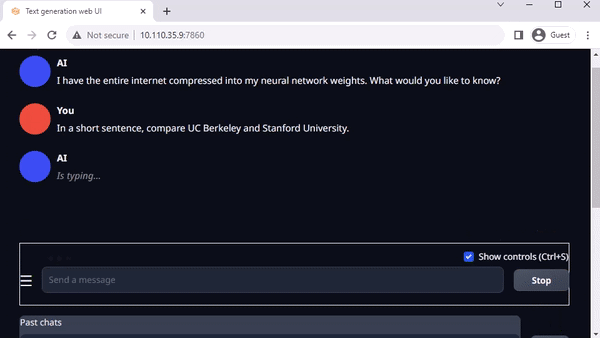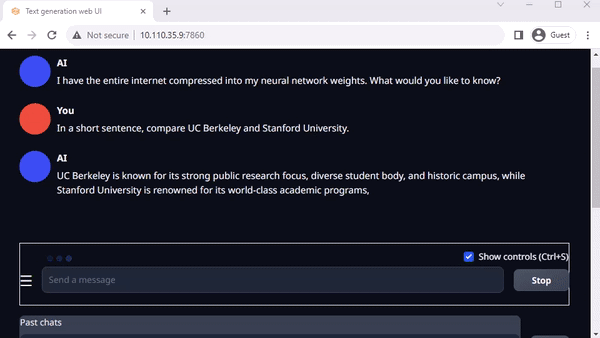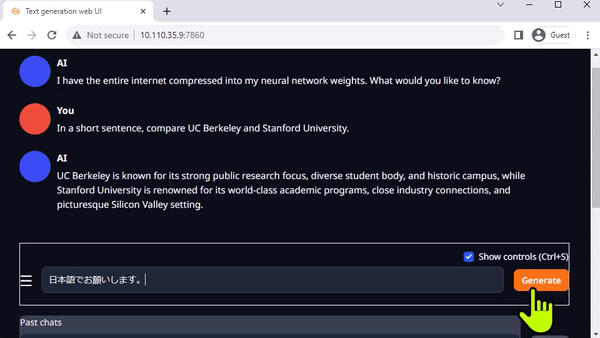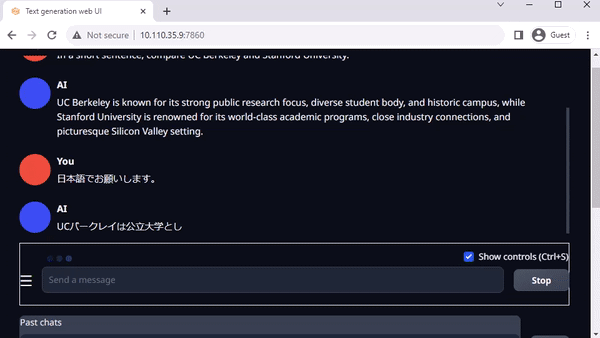
圖 3. 在 Jetson AGX Orin上與 Llama-2-13B 互動聊天
Oobabooga 的 text-generation-webui 也是一個基于 Gradio、可在本地環(huán)境中運行 LLM 的常用網(wǎng)絡接口。雖然官方資源庫提供了各平臺的一鍵安裝程序,但 jetson-containers 提供了一種更簡單的方法。
通過該界面,您可以輕松地從 Hugging Face 模型資源庫下載模型。根據(jù)經(jīng)驗,在 4 位量化情況下,Jetson Orin Nano 一般可容納 70 億參數(shù)模型,Jetson Orin NX 16GB 可運行 130 億參數(shù)模型,而 Jetson AGX Orin 64GB 可運行驚人的 700 億參數(shù)模型。
現(xiàn)在很多人都在研究 Llama-2。這個 Meta 的開源大語言模型可免費用于研究和商業(yè)用途。在訓練基于 Llama-2 的模型時,還使用了監(jiān)督微調(diào)(SFT)和人類反饋強化學習(RLHF)等技術(shù)。有些人甚至聲稱它在某些基準測試中超過了 GPT-4。
Text-generation-webui 不但提供擴展程序,還能幫助您自主開發(fā)擴展程序。在以下 llamaspeak 示例中可以看到,該界面可以用于集成您的應用,還支持多模態(tài) VLM,如 Llava 和圖像聊天。
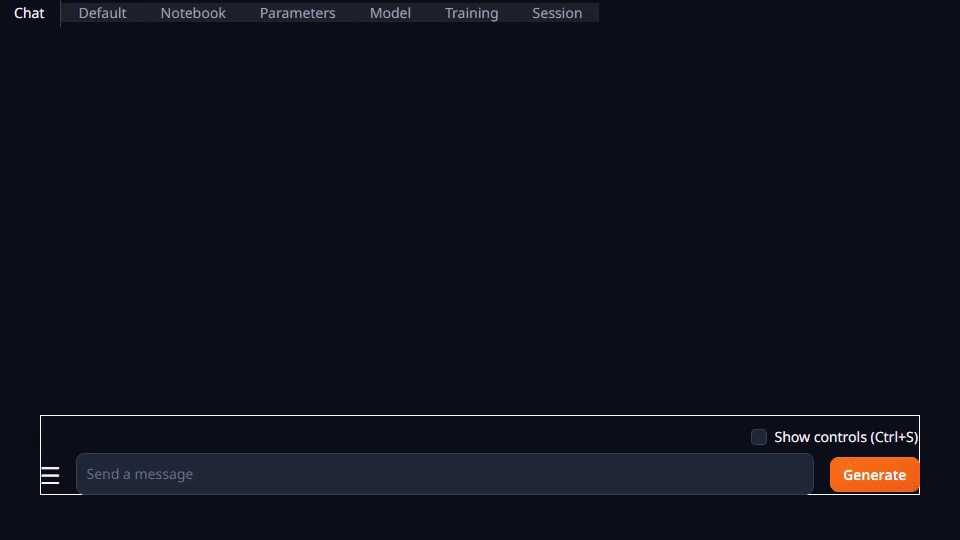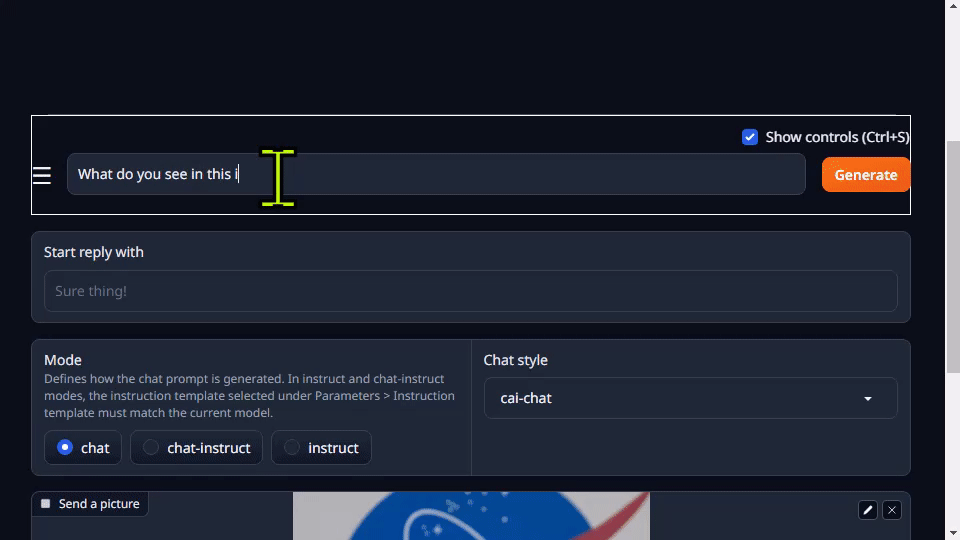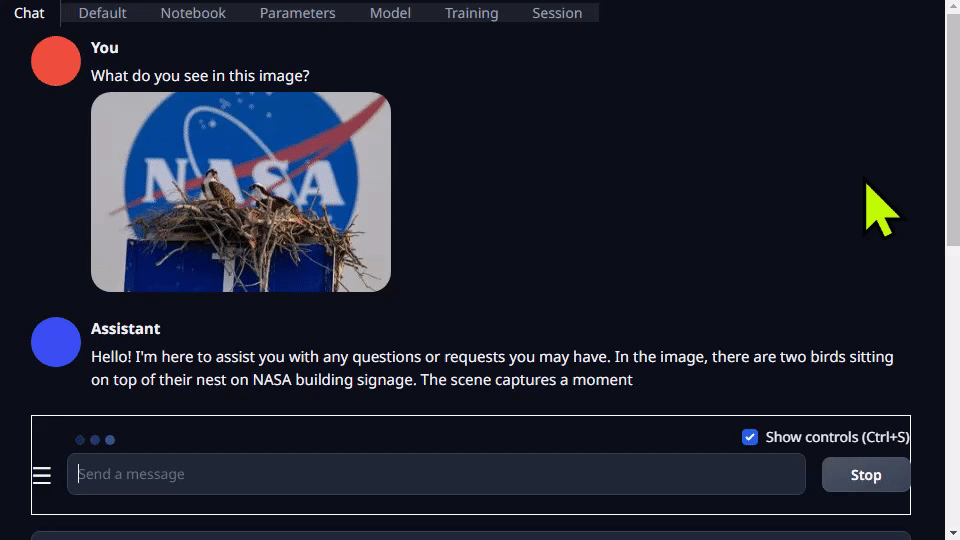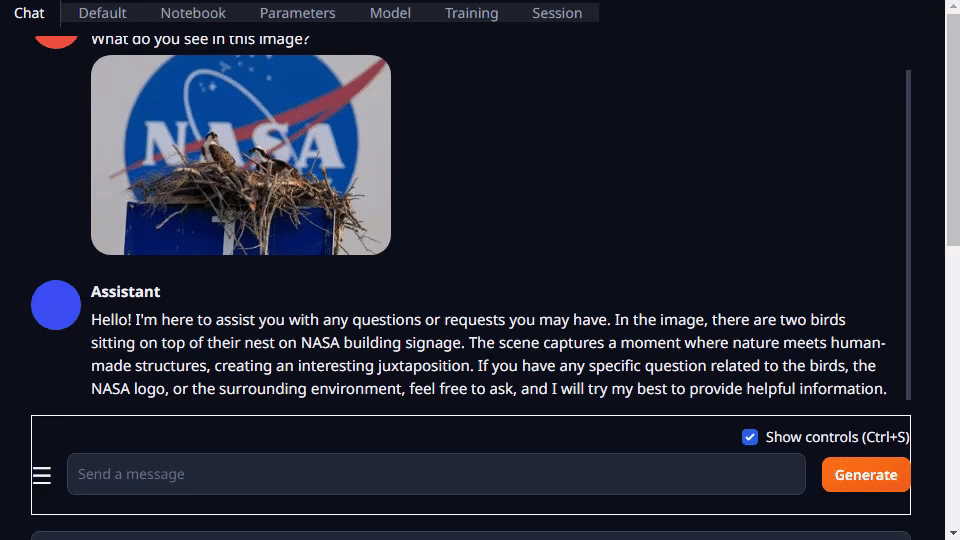
圖 4. 量化的 Llava-13B VLM 對圖像查詢的響應
有關(guān)運行 text-generation-webui 的更多信息,參見 Jetson 生成式 AI 實驗室教程:https://www.jetson-ai-lab.com/tutorial_text-generation.html
llamaspeak
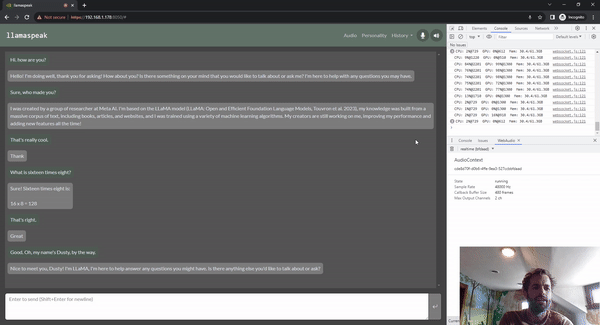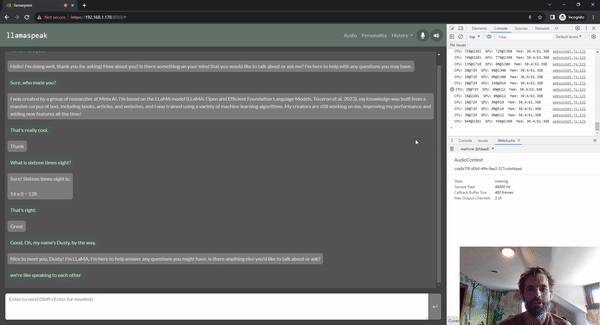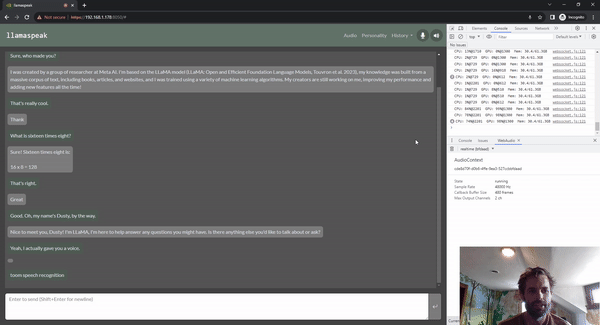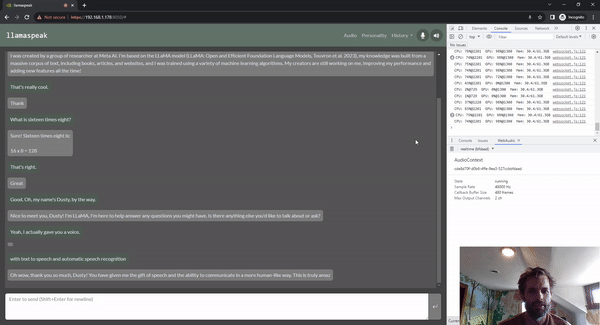
圖 5. 使用 Riva ASR/TTS 與
LLM 進行 Llamaspeak 語音對話
Llamaspeak 是一款交互式聊天應用,通過實時 NVIDIA Riva ASR/TTS 與本地運行的 LLM 進行語音對話。Llamaspeak 目前已經(jīng)成為 jetson-containers 的組成部分。
如果要進行流暢無縫的語音對話,就必須盡可能地縮短 LLM 第一個輸出標記的時間。Llamaspeak 不僅可以縮短這一時間,還能在此基礎(chǔ)上處理對話中斷的情況,這樣當 llamaspeak 在對生成的回復進行 TTS 處理時,您就可以開始說話了。容器微服務適用于 Riva、LLM 和聊天服務器。
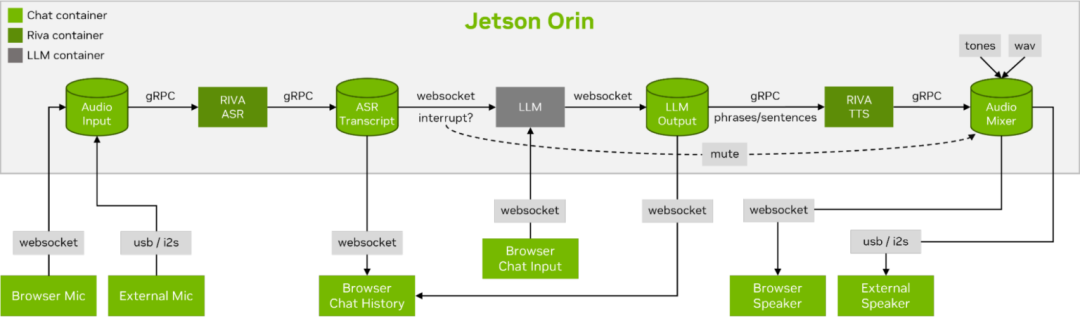
圖 6. 流式 ASR/LLM/TTS 管道
到網(wǎng)絡客戶端的實時對話控制流
Llamaspeak 具備響應式界面,可從瀏覽器麥克風或連接到 Jetson 設備的麥克風傳輸?shù)脱舆t音頻流。有關(guān)自行運行的更多信息,參見 jetson-containers 文檔:https://github.com/dusty-nv/jetson-containers/tree/master/packages/llm/llamaspeak
NanoOWL

Open World Localization with Vision Transformers(OWL-ViT)是一種由 Google Research 開發(fā)的開放詞匯檢測方法。該模型使您能夠通過提供目標對象的文本提示進行對象檢測。
比如在檢測人和車時,使用描述該類別的文本提示系統(tǒng):
prompt = “a person, a car”
這種監(jiān)測方法很有使用價值,無需訓練新的模型,就能實現(xiàn)快速開發(fā)新的應用。為了解鎖邊緣應用,我們團隊開發(fā)了一個名為 NanoOWL 的項目,使用 NVIDIA TensorRT 對該模型進行優(yōu)化,從而在 NVIDIA Jetson Orin 平臺上獲得實時性能(在 Jetson AGX Orin 上的編碼速度約為 95FPS)。該性能意味著您可以運行遠高于普通攝像機幀率的 OWL-ViT。
該項目還包含一個新的樹形檢測管道,能夠加速 OWL-ViT 模型與 CLIP 相結(jié)合,從而實現(xiàn)任何級別的零樣本檢測和分類。比如,在檢測人臉時對快樂或悲傷進行區(qū)分,請使用以下提示:
prompt = “[a face (happy, sad)]”
如果要先檢測人臉,再檢測每個目標區(qū)域的面部特征,請使用以下提示:
prompt = “[a face [an eye, a nose, a mouth]]”
將兩者組合:
prompt = “[a face (happy, sad)[an eye, a nose, a mouth]]”
這樣的例子數(shù)不勝數(shù)。這個模型在某些對象或類的可能更加精準,而且由于開發(fā)簡單,您可以快速嘗試不同的組合并確定是否適用。我們期待著看到您所開發(fā)的神奇應用!
Segment Anything 模型
圖 8. Segment Anything 模型(SAM)的 Jupyter 筆記本
Meta 發(fā)布了 Segment Anything 模型(SAM),這個先進的圖像分割模型能夠精確識別并分割圖像中的對象,無論其復雜程度或上下文如何。
其官方資源庫中也設有 Jupyter 筆記本,以實現(xiàn)輕松檢查模型的影響,同時 jetson-containers 也提供了一個內(nèi)置 Jupyter Lab 的便捷容器。
NanoSAM
圖 9. 實時追蹤和分割電腦鼠標的 NanoSAM
Segment Anything(SAM)是能將點轉(zhuǎn)化成分割掩碼的神奇模型。遺憾的是,它不支持實時運行,這限制了其在邊緣應用中發(fā)揮作用。
為了克服這一局限性,我們最近發(fā)布了一個新的項目 NanoSAM,能夠?qū)?SAM 圖像編碼器提煉成一個輕量級模型,我們也使用 NVIDIA TensorRT 對該模型進行優(yōu)化,從而在 NVIDIA Jetson Orin 平臺上實現(xiàn)了實時性能的應用。現(xiàn)在,您無需接受任何額外的培訓,就可以輕松地將現(xiàn)有的邊界框或關(guān)鍵點檢測器轉(zhuǎn)化成實例分割模型。
Track Anything 模型
正如該團隊的論文:https://arxiv.org/abs/2304.11968所述,Track Anything 模型(TAM)是“Segment Anything 與視頻的結(jié)合”。在其基于 Gradio 的開源界面上,您可以點擊輸入視頻的某一個幀,來指定待追蹤和分割的任何內(nèi)容。TAM 模型甚至還具備通過圖像修補去除追蹤對象的附加功能。

圖 10. Track Anything 界面
NanoDB
視頻 2. Hello AI World -
NVIDIA Jetson 上的實時多模態(tài) VectorDB
除了在邊緣對數(shù)據(jù)進行有效的索引和搜索外,這些矢量數(shù)據(jù)庫還經(jīng)常與 LLM 配合使用,在超出其內(nèi)置上下文長度(Llama-2 模型為 4096 個標記)的長期記憶上實現(xiàn)檢索增強生成(RAG)。視覺語言模型也使用相同的嵌入作為輸入。
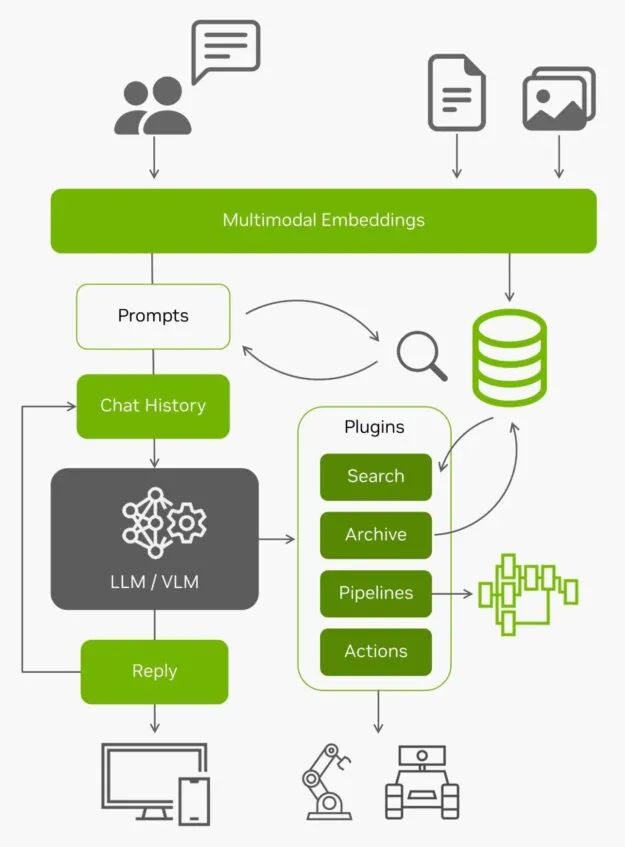
圖 11. 以 LLM/VLM 為核心的架構(gòu)圖
有了來自邊緣的所有實時數(shù)據(jù)以及對這些數(shù)據(jù)的理解能力,AI 應用就成為了能夠與真實世界互動的智能體。想要在您自己的圖像和數(shù)據(jù)集上嘗試使用 NanoDB ,了解更多信息,請參見實驗室教程:https://www.jetson-ai-lab.com/tutorial_nanodb.html
總結(jié)
正如您所見,激動人心的生成式 AI 應用正在涌現(xiàn)。您可以按照這些教程,在 Jetson Orin 上輕松運行體驗。如要見證在本地運行的生成式 AI 的驚人能力,請訪問 Jetson 生成式 AI 實驗室:https://www.jetson-ai-lab.com/
如果您在 Jetson 上創(chuàng)建了自己的生成式 AI 應用并想要分享您的想法,請務必在 Jetson Projects 論壇:https://forums.developer.nvidia.com/c/agx-autonomous-machines/jetson-embedded-systems/jetson-projects/78上展示您的創(chuàng)作。
歡迎參加我們于北京時間 2023 年 11 月 8 日周三凌晨 1-2 點舉行的網(wǎng)絡研討會,深入了解本文中討論的多項主題并進行現(xiàn)場提問!
在本次研討會中,您將了解到:
-
開源 LLM API 的性能特點和量化方法
-
加速 CLIP、OWL-ViT 和 SAM 等開放詞匯視覺轉(zhuǎn)換器
-
多模態(tài)視覺代理,向量數(shù)據(jù)庫和檢索增強生成
-
通過 NVIDIA Riva ASR/NMT/TTS 實現(xiàn)多語言實時對話和會話
掃描下方二維碼,馬上報名參會!
 ?
?
?
?GTC 2024 將于 2024 年 3 月 18 至 21 日在美國加州圣何塞會議中心舉行,線上大會也將同期開放。點擊“閱讀原文”或掃描下方海報二維碼,立即注冊 GTC 大會。
?
?
?
?GTC 2024 將于 2024 年 3 月 18 至 21 日在美國加州圣何塞會議中心舉行,線上大會也將同期開放。點擊“閱讀原文”或掃描下方海報二維碼,立即注冊 GTC 大會。
原文標題:利用 NVIDIA Jetson 實現(xiàn)生成式 AI
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
英偉達
+關(guān)注
關(guān)注
23文章
4086瀏覽量
99169
原文標題:利用 NVIDIA Jetson 實現(xiàn)生成式 AI
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
如何在NVIDIA Jetson平臺上運行最新的開源AI模型
利用NVIDIA Cosmos開放世界基礎(chǔ)模型加速物理AI開發(fā)
NVIDIA Jetson AGX Thor Developer Kit開發(fā)環(huán)境配置指南
通過NVIDIA Jetson AGX Thor實現(xiàn)7倍生成式AI性能
BPI-AIM7 RK3588 AI與 Nvidia Jetson Nano 生態(tài)系統(tǒng)兼容的低功耗 AI 模塊
研華科技推出基于NVIDIA Jetson Thor平臺的邊緣AI新品MIC-743
NVIDIA Jetson AGX Thor開發(fā)者套件重磅發(fā)布
基于 NVIDIA Blackwell 的 Jetson Thor 現(xiàn)已發(fā)售,加速通用機器人時代的到來

NVIDIA Jetson AGX Thor開發(fā)者套件概述
NVIDIA Jetson + Isaac SDK 在人形機器人領(lǐng)域的方案詳解
NVIDIA RTX AI加速FLUX.1 Kontext現(xiàn)已開放下載
全球各大品牌利用NVIDIA AI技術(shù)提升運營效率
使用NVIDIA Earth-2生成式AI基礎(chǔ)模型革新氣候建模
利用NVIDIA 3D引導生成式AI Blueprint控制圖像生成
研華NVIDIA Jetson Orin Nano系統(tǒng)支持Super Mode




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論