 MLPerf V2.0推理結果放榜,NVIDIA表現搶眼
MLPerf V2.0推理結果放榜,NVIDIA表現搶眼

(文/程文智)不久前,AI性能基準評測平臺MLPerf公布了2022年首次推理(Inference v2.0)測試成績,NVIDIA的AI平臺表現依然搶眼。
據MLPerf官方介紹,它是由來自學術界、研究實驗室和相關行業的 AI 領導者組成的聯盟,旨在“構建公平和有用的基準測試”,在規定的條件下,針對硬件、軟件和服務的訓練和推理性能提供公平的評估。每年組織AI推理和AI訓練測試各兩次,以對迅速增長的AI計算需求與性能進行及時的跟蹤測評。MLPerf比賽通常分為固定任務(Closed)和開放優化(Open)兩類任務,開放優化能力著重考察參測廠商的AI技術創新力,固定任務則因更公平地考察參測廠商的硬件系統和軟件優化的能力,成為更具參考價值的AI性能基準測試。因此,目前MLPerf被看作是AI領域的風向標,誰能夠在這個測試中取得更多的領先,誰的AI能力就越突出。
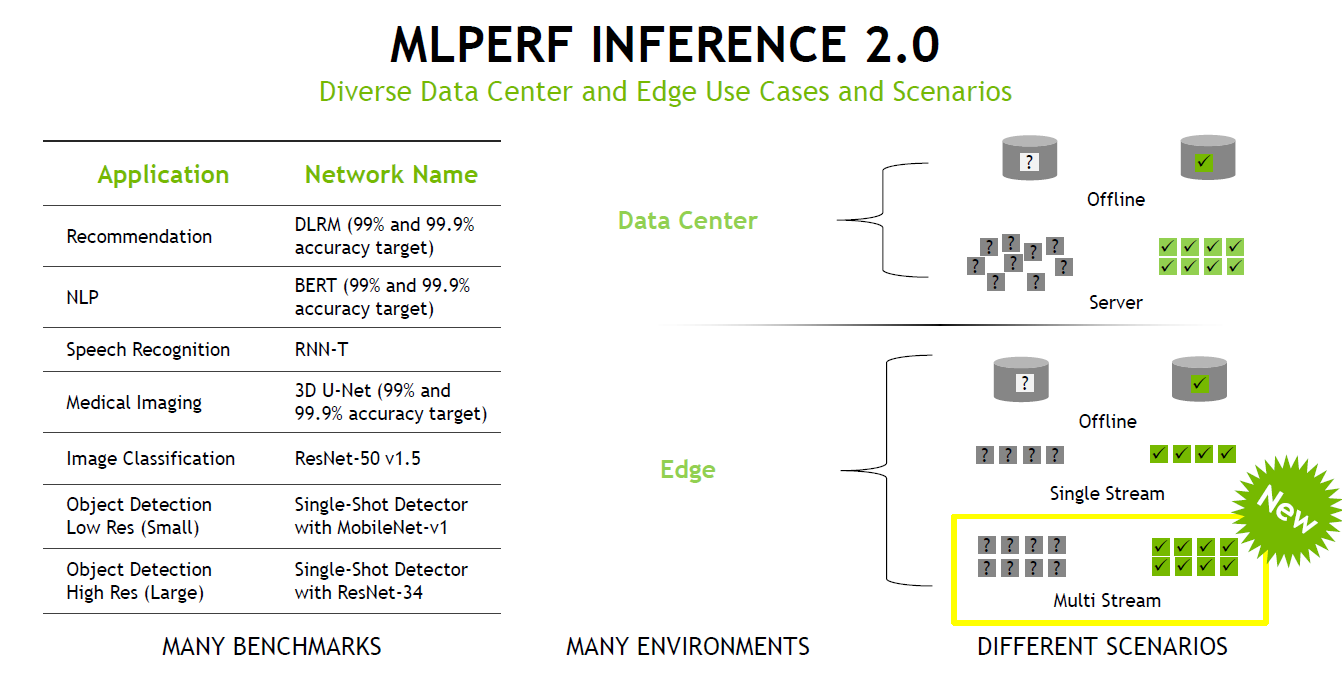
在最新一期的榜單中,浪潮、NVIDIA、英特爾、高通、阿里巴巴、戴爾、Deci.ai、Azure、富士通、技嘉、聯想、寧暢、美超微、華碩、浙江實驗室、及新華三等廠商參與了競賽。評測以最新MLPerf Inference V2.0為基準,涵蓋了圖像分類、目標檢測、醫療圖像分割、自然語言處理、語音轉文字和推薦系統6類AI應用場景,分為數據中心和邊緣兩類處理場景,每類場景都包含固定任務(Closed)和開放優化(Open)兩類性能競賽。其中,在最新的V2.0規范中,在邊緣運算環境導入多資料流(Multi Stream)測試項目,測量邊緣運算設備在多攝影機、多傳感器場景的性能表現,以得到更貼近真實使用情況的數據。
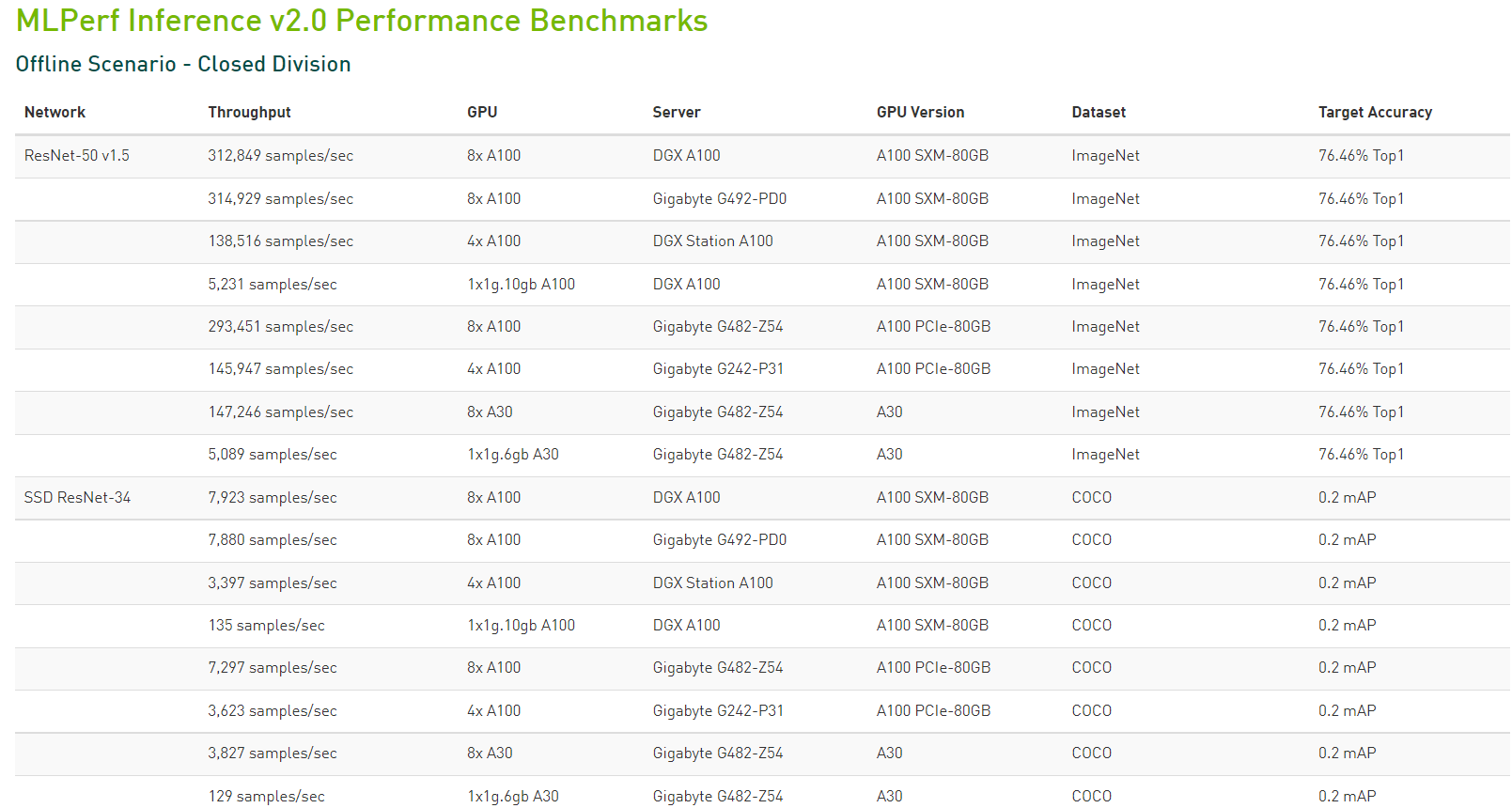
據統計,本輪測試一共展示了超過3900 次性能測試和 2200 次功耗測試,分別是上一輪的2倍和6倍。根據公開的數據顯示,本次測試中除了戴爾科技、富士通、技嘉、浪潮、聯想、寧暢和美超微等外,華碩和新華三本次測試中首次使用了NVIDIA AI平臺提交MLPerf結果。
Jetson AGX Orin提升邊緣AI性能,取得不俗成績
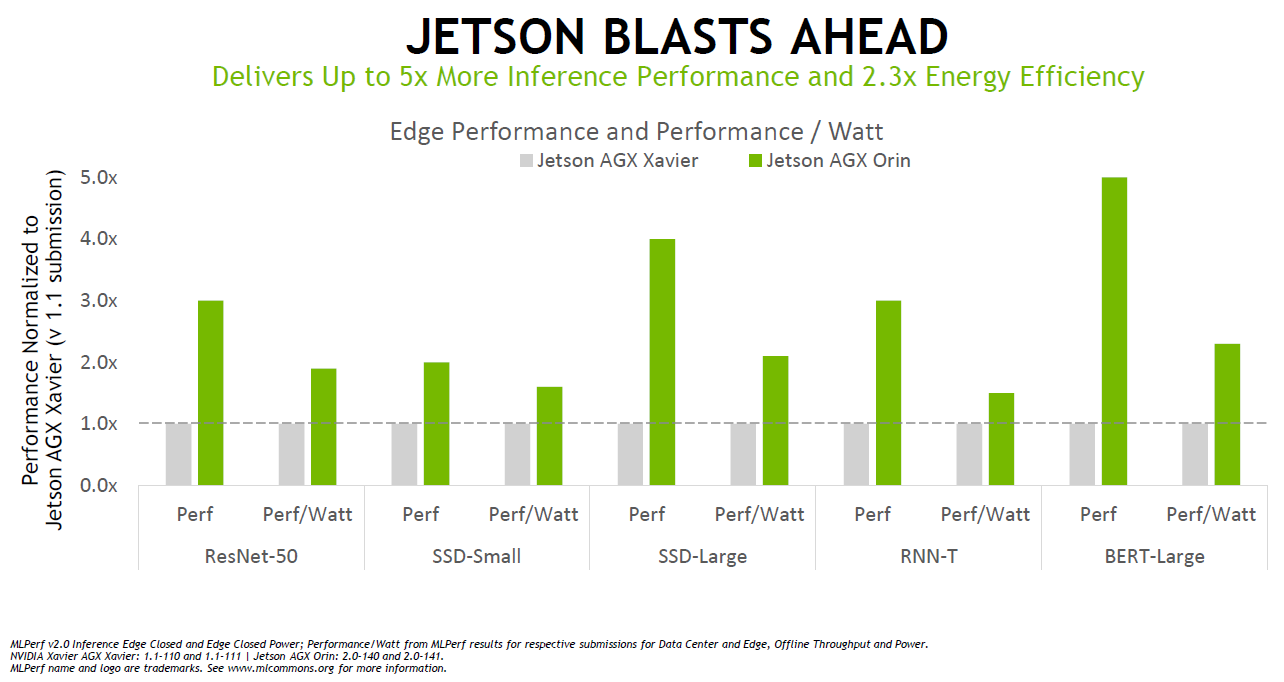
值得一提的是基于NVIDIA Ampere架構的低功耗系統級芯片NVIDIA Orin首次參加MLPerf基準測試,就取得了不俗的成績。在邊緣AI領域,NVIDIA Orin預生產版本在六項性能測試中的五項處于領先地位,其運行速度比上一代Jetson AGX Xavier快了5倍,能效平均提高了2倍。
根據NVIDIA官網的介紹,Jetson AGX Orin 系列有32GB和64GB兩個版本,該系列具有高達275TOPS的AI性能,由 Ampere GPU和深度學習加速器 (DLA) 提供支持。CPU配備了多達12個Arm Cortex A78AE內核。
Orin配備了其第三代Tensor Cores,可提高性能并支持稀疏矩陣。基于NVIDIA為 Xavier 所做的多處理器構建,它不僅具有 GPU 和CPU,還具有其他處理器,可以幫助從GPU和CPU卸載應用程序的某些部分。它包括一個專用于 AI 應用的深度學習加速器、一個用于計算機視覺應用和ISP的視覺加速器,以及一個視頻解碼和視頻編碼引擎。與 Xavier 相比,NVIDIA還為 Orin 帶來了 LPDDR5 以提高帶寬,傳輸速度可達204.8GB/s。 Orin 還具備豐富的IO連接,比如其具有多達22個PCIe4.0通道、4個千兆以太網、16個MIPI CSI通道,以及各種其他傳感器接口等。

根據測試,Jetson AGX Orin提供了8倍于Jetson AGX Xavier的性能,Jetson AGX Orin是能夠運行所有六項MLPerf基準測試的邊緣加速器。憑借JetPack SDK,Orin可以運行整個NVIDIA AI平臺,這個軟件堆棧已經在數據中心和云端得到了驗證,并且獲得了NVIDIA Jetson平臺100萬名開發者的支持。
在應用方面,目前,Orin主要關注三大領域,分別為:工業、自動駕駛和醫療。Orin現已加入到用于機器人和自動化系統的NVIDIA Jetson AGX Orin開發者套件。包括亞馬遜網絡服務、約翰迪爾、小松、美敦力和微軟Azure在內的6000多家客戶使用NVIDIA Jetson平臺進行AI推理或其他任務。
Orin也是NVIDIA Hyperion自動駕駛汽車平臺的關鍵組成部分。據NVIDIA介紹,Orin可處理在自動駕駛汽車和機器人中同時運行的大量應用和深度神經網絡,并且達到了ISO 26262 ASIL-D 等系統安全標準。而且,比亞迪近期已經宣布,他們將在其新一代自動駕駛電動汽車中使用內置Orin的DRIVE Hyperion架構。
Orin同樣也是NVIDIA Clara Holoscan醫療設備平臺的關鍵組成部分,且該平臺可供系統制造商和研究人員用來開發新一代AI儀器。
NVIDIA其他AI成果
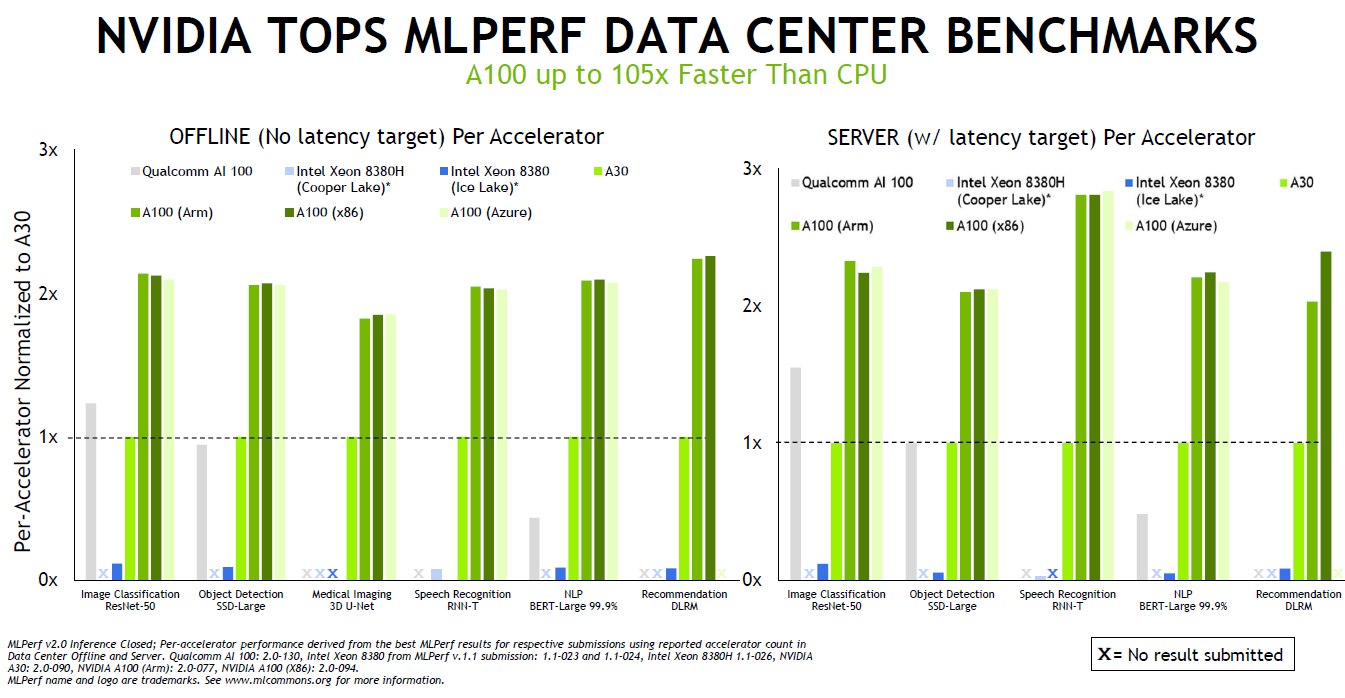
除了Orin之外,本輪MLPerf,驗證了NVIDIA的多項成果,包括多實例GPU(MIG)、TensorRT等。比如MIG可提升每個 NVIDIA A100 Tensor 核心 GPU 的性能和價值。MIG可將 A100 GPU 劃分為多達七個實例,每個實例均與各自的高帶寬顯存、緩存和計算核心完全隔離。管理員可以支持從大到小的各項工作負載,為每項工作提供規模適當的 GPU,而且服務質量 (QoS) 穩定可靠,從而優化利用率,讓每位用戶都能享用加速計算資源。

而根據實際測試結果,在使用7個實例時的性能為僅用一個實例的98%,這也意味著MIG可以充分利用GPU,避免了算力的浪費。
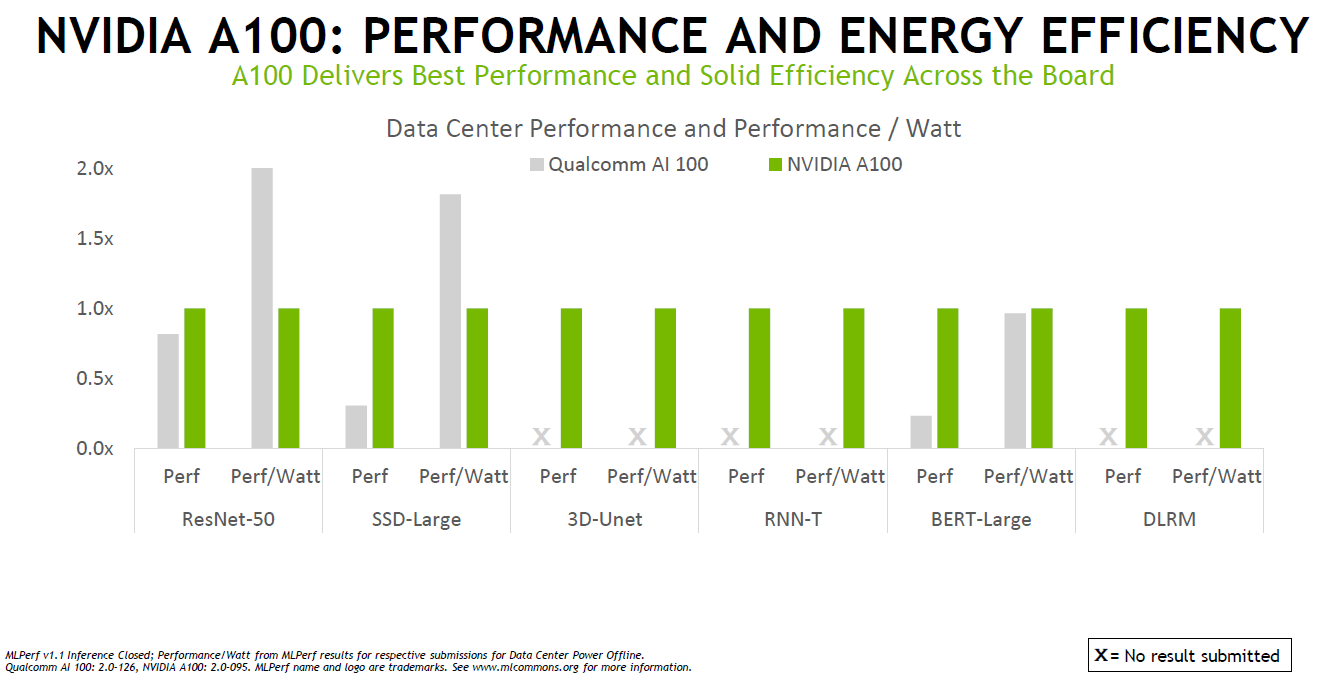
軟件是性能提升的關鍵驅動因素,NVIDIA在AI推理方面的軟件包括了用于優化 AI 模型的 NVIDIA TensorRT 和用于有效部署它們的 NVIDIA Triton開源推理服務軟件。NVIDIA AI 推理和云高級產品經理David Salvator在媒體發布會上介紹了NVIDIA的Triton開源推理服務軟件。
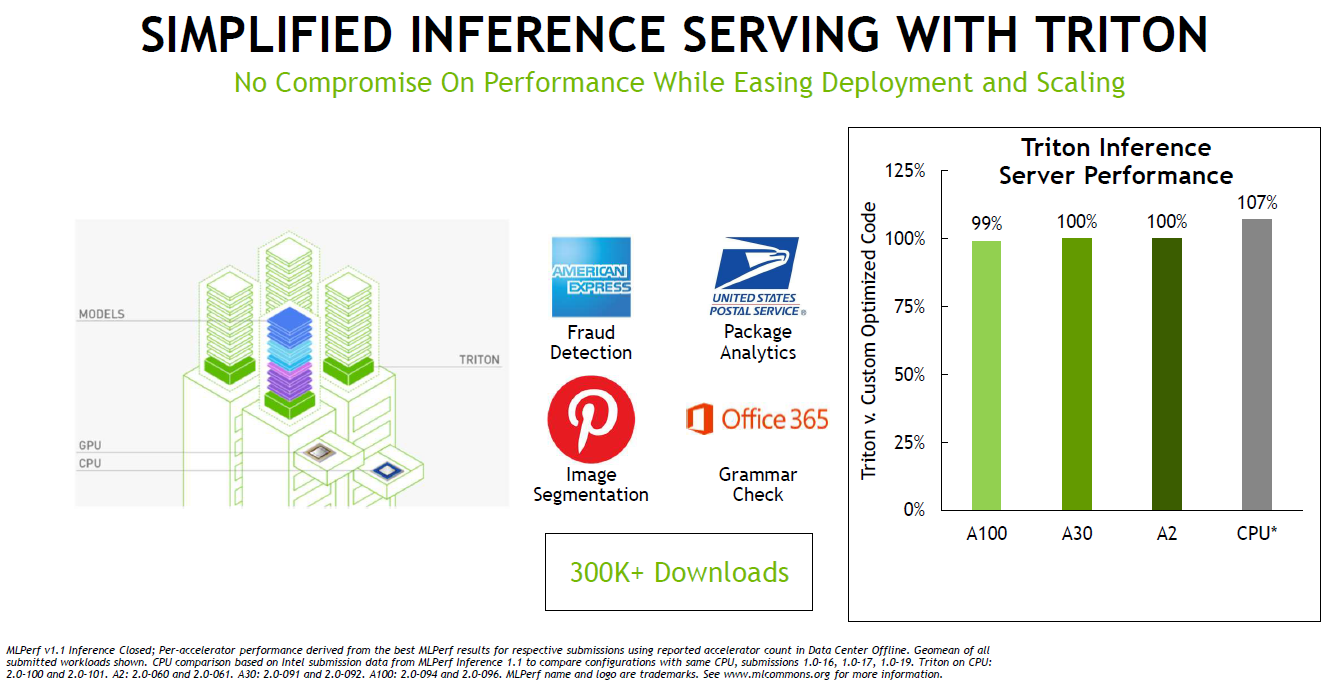
目前TensorRT廣泛的優化GPU內核庫已支持Jetson Orin,MLPerf中使用的插件已全部移植到Orin并添加到 TensorRT 8.4。Triton則Kubernetes緊密集成,可以管理GPU以及x86和Arm CPU上的AI推理工作,NVIDIA宣布,Triton現在可以只在CPU上運行,而無需GPU。
而也正是因為NVIDIA的跨平臺管理能力,使A100在Arm和x86-64平臺上的性能幾乎相同。并且,通過NVIDIA的軟件優化,AI性能在過去一年中就增長了高達50%。
結語
這幾年,NVIDIA在AI領域一路狂奔,不僅僅在數據中心方面優勢明顯,在汽車、邊緣計算方面也正推出優勢產品,另外在他們還在準備推出工業級的AI產品,進入傳統工業領域。AI正在不斷滲透到人們生活的各個方面。
-
NVIDIA
+關注
關注
14文章
5592瀏覽量
109722 -
AI
+關注
關注
91文章
39768瀏覽量
301370 -
人工智能
+關注
關注
1817文章
50094瀏覽量
265302 -
推理
+關注
關注
0文章
9瀏覽量
7421 -
MLPerf
+關注
關注
0文章
37瀏覽量
970
發布評論請先 登錄
智子科技發布數字營銷策略大模型智小虎V2.0


NVIDIA TensorRT LLM 1.0推理框架正式上線
華為推出人工智能氣象預報模型V2.0版本
使用env v2.0執行scons --dist產生缺失依賴報錯怎么解決?
NVIDIA Nemotron Nano 2推理模型發布

Robrain V2.0正式登場:落地人形機器人,引爆智能進化革命

請問是否可以將 Nu-Link2-Me V1.0 的固件升級到 V2.0?
登頂!華為OceanStor A系列存儲再登MLPerf全球性能之巔
智嵌云V2.0獲軟件著作權登記,賦能行業數字化升級




 工商網監
工商網監
評論