") NVIDIA從云到邊緣加速OpenAI gpt-oss模型部署,實現(xiàn)150萬TPS推理
NVIDIA從云到邊緣加速OpenAI gpt-oss模型部署,實現(xiàn)150萬TPS推理

自 2016 年推出 NVIDIA DGX 以來,NVIDIA 與 OpenAI 便開始共同推動 AI 技術(shù)的邊界。此次 OpenAI gpt-oss-20b 和 gpt-oss-120b 模型的發(fā)布持續(xù)深化了雙方的 AI 創(chuàng)新合作。NVIDIA 在 NVIDIA Blackwell 架構(gòu)上優(yōu)化了這兩款全新的開放權(quán)重模型并實現(xiàn)了推理性能加速,在 NVIDIA 系統(tǒng)上至高達到每秒 150 萬個 Token (TPS)。
這兩個 gpt-oss 模型是具有鏈?zhǔn)剿季S和工具調(diào)用能力的文本推理大語言模型 (LLM),采用了廣受歡迎的混合專家模型 (MoE) 架構(gòu)和 SwigGLU 激活函數(shù)。其注意力層使用 RoPE 技術(shù),上下文規(guī)模為 128k,交替使用完整上下文和長度為 128 個 Token 的滑動窗口。兩個模型的精度為 FP4,可運行在單個 80GB 數(shù)據(jù)中心 GPU 上,并由 Blackwell 架構(gòu)提供原生支持。

這兩個模型在 NVIDIA Hopper 架構(gòu) Tensor Core GPU 上訓(xùn)練而成,gpt-oss-120b 模型訓(xùn)練耗時超過 210 萬小時,而 gpt-oss-20b 模型訓(xùn)練耗時約為前者的十分之一。除了NVIDIA TensorRT-LLM外,NVIDIA 還與 Hugging Face Transformers、Ollama、vLLM 等多個頂級開源框架合作,提供優(yōu)化內(nèi)核和模型增強。本文將介紹 NVIDIA 如何將 gpt-oss 集成到軟件平臺以滿足開發(fā)者需求。

表 1. OpenAI gpt-oss-20b 和 gpt-oss-120b 模型規(guī)格,包括總參數(shù)量、活躍參數(shù)量、專家模型數(shù)和輸入上下文長度
NVIDIA 還與 OpenAI 和社區(qū)一同對性能進行優(yōu)化,增加了以下功能:
Blackwell 上用于注意力預(yù)填充 (prefill)、注意力解碼 (decode) 和 MoE 低延遲的 TensorRT-LLM Gen 內(nèi)核。
Blackwell 上的 CUTLASS MoE 內(nèi)核。
Hopper 上用于專用注意力機制的 XQA 內(nèi)核。
通過適用于 LLM 的 FlashInfer 內(nèi)核服務(wù)庫提供優(yōu)化的注意力與 MoE 路由內(nèi)核。
支持 MoE 的 OpenAI Triton 內(nèi)核,適用于 TensorRT-LLM 和 vLLM。
使用 vLLM 進行部署
NVIDIA 與 vLLM 合作,在共同驗證準(zhǔn)確性的同時,分析并提升了 Hopper 和 Blackwell 架構(gòu)的性能。數(shù)據(jù)中心開發(fā)者可通過 FlashInfer LLM 內(nèi)核服務(wù)庫使用經(jīng) NVIDIA 優(yōu)化的內(nèi)核。
vLLM 建議使用 uv 進行 Python 依賴項管理。用戶可以使用 vLLM 啟動一個與 OpenAI API 兼容的 Web 服務(wù)器。以下命令將自動下載模型并啟動服務(wù)器。更多詳細(xì)信息參見文檔和 vLLM Cookbook 指南。
uv run--with vllm vllm serve openai/gpt-oss-20b
使用 TensorRT-LLM 進行部署
上述優(yōu)化已包含在 NVIDIA / TensorRT-LLM GitHub 庫中,開發(fā)者可根據(jù)庫中的部署指南啟動其高性能服務(wù)器,并按照指南從 Hugging Face 下載模型 checkpoint。NVIDIA 與 Transformers 庫合作,提升了新模型的開發(fā)者體驗。指南還提供 Docker 容器以及低延遲和最大吞吐量場景下性能配置的指導(dǎo)。
在 NVIDIA 系統(tǒng)上實現(xiàn)
每秒 100 萬個 Token 以上的性能
NVIDIA 工程師與 OpenAI 密切合作,確保了新發(fā)布的 gpt-oss-120b 和 gpt-oss-20b 模型在 NVIDIA Blackwell 和 NVIDIA Hopper 平臺上實現(xiàn)第零天 (Day 0) 性能提升。
根據(jù)早期性能測量結(jié)果,規(guī)模更大、計算需求更高的 gpt-oss-120b 模型,在 NVIDIA 系統(tǒng)上可實現(xiàn)每秒 150 萬個 Token 的性能或服務(wù)約 5 萬名并發(fā)用戶。Blackwell 搭載了許多能夠提高推理性能的架構(gòu)技術(shù),包括使用了 FP4 Tensor Core 的第二代 Transformer Engine,以及高帶寬的第五代 NVIDIA NVLink 和 NVIDIA NVLink Switch,使得 72 顆 Blackwell GPU 可視作一個大型 GPU 運行。
NVIDIA 平臺的性能、靈活性和創(chuàng)新速度使得該生態(tài)系統(tǒng)能夠在 Day 0 便以高吞吐量和低單位 Token 成本運行最新模型。
通過 NVIDIA Launchable 試用經(jīng)過優(yōu)化的模型
還可以使用 Open AI Cookbook 上 JupyterLab Notebook 中的 Python API 部署 TensorRT-LLM,并將其作為NVIDIA Launchable在構(gòu)建平臺中使用。用戶可以在預(yù)配置環(huán)境中一鍵部署經(jīng)過優(yōu)化的模型,并在多個云平臺進行測試。
使用 NVIDIA Dynamo 進行部署
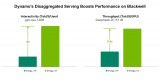
NVIDIA Dynamo是一個幫助開發(fā)者為大規(guī)模應(yīng)用部署 OpenAI gpt-oss 等模型的開源推理服務(wù)平臺。它與主流的推理后端集成,并提供 LLM 感知路由、彈性自動擴展和分離服務(wù)等功能。在應(yīng)用輸入序列長度 (ISL) 長的情況下,Dynamo 的分離服務(wù)可顯著提升性能。在 32K ISL 場景中,Dynamo 在系統(tǒng)吞吐量和 GPU 預(yù)算相同的情況下,交互性能較合并服務(wù)提升了 4 倍。如需使用 Dynamo 進行部署,可參考該指南:
https://github.com/ai-dynamo/dynamo/blob/main/components/backends/trtllm/gpt-oss.md
在 NVIDIA GeForce RTX AI PC 本地運行
開發(fā)者可在本地運行 AI ,以實現(xiàn)更快的迭代、更低的延遲和更可靠的數(shù)據(jù)隱私保護。兩個模型均具有原生 MXFP4 精度,可在 NVIDIA RTX PRO GPU 驅(qū)動的專業(yè)工作站上運行,其中 gpt-oss-20b 可部署在任何具有不低于 16GB 顯存的 GeForce RTX AI PC 上。開發(fā)者可通過 Ollama、Llama.cpp 或 Microsoft AI Foundry Local,使用其常用的應(yīng)用和 SDK 體驗這兩個模型。如需使用,請訪問 RTX AI Garage。

圖 1. 使用 Ollama 安裝和運行模型的步驟
通過 NVIDIA NIM 簡化企業(yè)部署
企業(yè)開發(fā)者可通過 NVIDIA API 目錄中的NVIDIA NIM預(yù)覽 API 和 Web Playground 環(huán)境試用 gpt-oss 模型。這兩個模型已被打包成 NVIDIA NIM,可靈活、輕松地部署在任何 GPU 加速的基礎(chǔ)設(shè)施上,同時保證數(shù)據(jù)隱私和提供企業(yè)級安全。
下載和部署預(yù)打包、可移植式且經(jīng)過優(yōu)化的 NIM:
下載 gpt-oss-120b
鏈接:https://www.nvidia.cn/ai/
文檔:https://docs.api.nvidia.com/nim/reference/openai-gpt-oss-120b
下載 gpt-oss-20b
鏈接:https://www.nvidia.cn/ai/
文檔:https://docs.api.nvidia.com/nim/reference/openai-gpt-oss-20b
隨著兩個 gpt-oss 模型被全面集成到 NVIDIA 開發(fā)者生態(tài)系統(tǒng)中,開發(fā)者可選擇最有效的解決方案。可在 NVIDIA API 目錄用戶界面或通過 OpenAI Cookbook 中的 NVIDIA 開發(fā)者指南開始使用。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5665瀏覽量
109979 -
OpenAI
+關(guān)注
關(guān)注
9文章
1247瀏覽量
10216
原文標(biāo)題:NVIDIA 從云到邊緣加速 OpenAI gpt-oss 模型部署,實現(xiàn) 150 萬 TPS 推理
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
NVIDIA Jetson模型賦能AI在邊緣端落地

從模型到產(chǎn)品:Qwen2.5-VL在BM1684X邊緣計算部署全攻略

如何在NVIDIA Jetson AGX Thor上部署1200億參數(shù)大模型

GPT-5.1發(fā)布 OpenAI開始拼情商
NVIDIA TensorRT LLM 1.0推理框架正式上線
NVIDIA Nemotron Nano 2推理模型發(fā)布

Dynamo 0.4在NVIDIA Blackwell上通過PD分離將性能提升4倍
澎峰科技完成OpenAI最新開源推理模型適配
訊飛星辰MaaS平臺率先上線OpenAI最新開源模型
OpenAI與NVIDIA共同開發(fā)全新開放模型
亞馬遜云科技現(xiàn)已上線OpenAI開放權(quán)重模型
OpenAI發(fā)布2款開源模型
如何在魔搭社區(qū)使用TensorRT-LLM加速優(yōu)化Qwen3系列模型推理部署
邊緣計算中的機器學(xué)習(xí):基于 Linux 系統(tǒng)的實時推理模型部署與工業(yè)集成!




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論