 電子發燒友App
電子發燒友App



sysbench 是一個非常經典的綜合性能測試工具,通常都用它來做數據庫的性能壓測,但也可以用來做CPU,IO的性能測試。而對于IO測試,不是很推薦sysbench,倒不是說它有錯誤,工具本身沒有任何問題,它的測試方法導致測試的數據會讓人有些困惑:性能數據到底是不是這樣呢,跟云廠商承諾的性能有關系嘛。一般我們都用FIO來進行性能測試,云廠商都推薦用FIO進行性能測試,通過FIO性能測試,都能輕易達到云廠商承諾的性能。
插曲:關于sysbench的版本,現在主要有0.4.12和1.0.版本。截止2006年sysbench好長時間沒有發展,2017年之前都是用舊版本0.4.12(所以網上一搜一大堆文章都是0.4.的教程),然后作者估計修了幾個bug,變成0.5版本,然后就跟過去做了告別,從2017重新開發了一個新版本sysbench 1.0.*,這里講述的性能測試都是用了最新版。
1. sysbench fileio測試
言歸正傳,sysbench怎么做IO的性能測試呢,sysbench fileio help,參數如下:
#/usr/local/sysbench_1/bin/sysbench?fileio?helpsysbench?1.0.9?(using?bundled?LuaJIT?2.1.0-beta2)
fileio?options:
??--file-num=N??????????????number?of?files?to?create?[128]
??--file-block-size=N???????block?size?to?use?in?all?IO?operations?[16384]
??--file-total-size=SIZE????total?size?of?files?to?create?[2G]
??--file-test-mode=STRING???test?mode?{seqwr,?seqrewr,?seqrd,?rndrd,?rndwr,?rndrw}
??--file-io-mode=STRING?????file?operations?mode?{sync,async,mmap}?[sync]
??--file-async-backlog=N????number?of?asynchronous?operatons?to?queue?per?thread?[128]
??--file-extra-flags=STRING?additional?flags?to?use?on?opening?files?{sync,dsync,direct}?[]
??--file-fsync-freq=N???????do?fsync()?after?this?number?of?requests?(0?-?don't?use?fsync())?[100]
??--file-fsync-all[=on|off]?do?fsync()?after?each?write?operation?[off]
??--file-fsync-end[=on|off]?do?fsync()?at?the?end?of?test?[on]
??--file-fsync-mode=STRING??which?method?to?use?for?synchronization?{fsync,?fdatasync}?[fsync]
??--file-merged-requests=N??merge?at?most?this?number?of?IO?requests?if?possible?(0?-?don't?merge)?[0]
??--file-rw-ratio=N?????????reads/writes?ratio?for?combined?test?[1.5]sysbench的性能測試都需要做prepare,run,cleanup這三步,準備數據,跑測試,刪除數據。那下面就開始實戰:
客戶用2C4G的vm,掛載120G的SSD云盤做了性能測試,測試命令如下:
cd?/mnt/vdb??#一定要到你測試的磁盤目錄下執行,否則可能測試系統盤了sysbench?fileio?--file-total-size=15G?--file-test-mode=rndrw?--time=300?--max-requests=0?prepare sysbench?fileio?--file-total-size=15G?--file-test-mode=rndrw?--time=300?--max-requests=0?run sysbench?fileio?--file-total-size=15G?--file-test-mode=rndrw?--time=300?--max-requests=0?cleanup
結果如下:
File?operations: ????reads/s:??????????????????????2183.76 ????writes/s:?????????????????????1455.84 ????fsyncs/s:?????????????????????4658.67Throughput:????read,?MiB/s:??????????????????34.12 ????written,?MiB/s:???????????????22.75General?statistics: ????total?time:??????????????????????????300.0030s ????total?number?of?events:??????????????2489528Latency?(ms): ?????????min:??????????????????????????????????0.00 ?????????avg:??????????????????????????????????0.12 ?????????max:????????????????????????????????204.04 ?????????95th?percentile:??????????????????????0.35 ?????????sum:?????????????????????????????298857.30Threads?fairness: ????events?(avg/stddev):???????????2489528.0000/0.00 ????execution?time?(avg/stddev):???298.8573/0.00
隨機讀寫性能好像不咋地,換算IOPS為(34.12+22.75)*1024/16.384=3554.375,與宣稱的5400IOPS有很大差距。眼尖的人肯定發現只有2個核,去遍歷128個文件,好像會降低效率,于是定制file-num去做了系列測試,測試結果如下:
| file-num | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
|---|---|---|---|---|---|---|---|---|
| read(MB/s) | 57.51 | 57.3 | 57.36 | 57.33 | 55.12 | 47.72 | 41.11 | 34.12 |
| write(MB/s) | 38.34 | 38.2 | 38.24 | 38.22 | 36.75 | 31.81 | 27.4 | 22.75 |
明顯可以看到,默認測試方法會導致性能下降,文件數設置為1達到最大性能。
那file-num=128與file-num=1的區別是測試文件從128個變成1個,但是總文件大小都是15G,都是隨機讀寫,按理性能應該是一致的,區別是會在多個文件之間切換讀寫,那么可能會導致中斷增加和上下文切換開銷增大。通過vmstat命令得到了驗證:
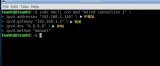
file-num=128的vmstat輸出是這樣的:
file-num=1的vmstat輸出是這樣的:
從上面兩個圖可以看出file-num=1的時候上下文切換只有8500左右比file-num=128的時候24800小多了,in(中斷)也少太多了。減少了中斷和上下文切換開銷,吞吐能力顯著提升了。
再做了一個實驗,同樣磁盤大小,改成掛載到8C的vm下,改成8線程進行測試,得到如下數據:
| file-num | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
|---|---|---|---|---|---|---|---|---|
| read(MB/s) | 253.08 | 209.86 | 193.38 | 159.73 | 117.98 | 86.78 | 67.39 | 51.98 |
| write(MB/s) | 168.72 | 139.9 | 128.92 | 106.49 | 78.66 | 57.85 | 44.93 | 34.65 |
可以得出同樣的結論,file-num=1可以得到最好的性能,理由如上。
2. 與fio測試的比較
單進程下,file-num=1換算到IOPS為(57.51+38.34)*1024/16.384=5990.625,這好像超過我們的IOPS設置限定了。通過fio是怎么測得這個IOPS的呢:
fio?-direct=1?-iodepth=128?-rw=randrw?-ioengine=libaio?-bs=4k?-size=1G?-numjobs=1?-runtime=1000?-group_reporting?-filename=iotest?-name=randrw_test
通過閱讀源代碼,發現很多不同:
一個是通過libaio,一個是通過pwrite/pread。libaio的性能是非常強勁的,詳情可以參考文章。
即使ioengine=psync,這個engine的讀寫方法是pread和pwrite,但是整個實現也是不一致的。fio測試的時候direct=1,就是每次都寫入磁盤,而sysbench默認file-fsync-freq=100,也就是完成100次操作才會有一個fsync操作,這種操作涉及系統緩存。
3. 深入一步
上節認為操作系統干擾以及io讀寫方式的差異,造成了測試數據的不一致。深入去研究了下源代碼,其實sysbench的作者是提倡用libaio,代碼里面大量地運用了宏定義,如:
/*?異步寫的截取代碼?*/#ifdef?HAVE_LIBAIO
??else?if?(file_io_mode?==?FILE_IO_MODE_ASYNC)
??{????/*?Use?asynchronous?write?*/
????io_prep_pwrite(&iocb,?fd,?buf,?count,?offset);????if?(file_submit_or_wait(&iocb,?FILE_OP_TYPE_WRITE,?count,?thread_id))??????return?0;????return?count;
??}#endif那怎么啟用這個宏呢,默認就是啟用這個宏的。
啟用這個宏后,執行sysbench fileio help,會發現有這一項:--file-async-backlog=N number of asynchronous operatons to queue per thread [128],說明HAVE_LIBAIO這個宏確實生效了。
既然sysbench默認有libaio后,那整個測試方法需要調整:
#?--file-extra-flags=direct?文件讀寫模式改成direct#?--file-io-mode=async?確保libaio起效#?--file-fsync-freq=0?不需要執行fsyncsysbench?fileio?--file-total-size=15G?--file-test-mode=rndrw?--time=300?--max-requests=0?--file-io-mode=async?--file-extra-flags=direct??--file-num=1?--file-rw-ratio=1?--file-fsync-freq=0?run
得到測試結果如下:
對于FIO命令也進行了調整,把bs調整成16k,其他不變,還是達到上限5400。測試結果如下:
可以看到sysbench測試的效果與fio的測試效果完全一致!
不過個人還是推薦FIO來做IO的性能測試。



























































 工商網監
工商網監
評論