 地平線11篇論文強勢入選CVPR 2026
地平線11篇論文強勢入選CVPR 2026

近日,計算機視覺與模式識別領域國際頂會CVPR 2026 (IEEE/CVF Conference on Computer Vision and Pattern Recognition) 正式公布論文收錄結果。地平線憑借深厚的技術積淀與前瞻的科研布局,共有11篇論文成功入選,覆蓋端到端自動駕駛、3D重建、世界模型、具身智能等多個核心領域,充分彰顯地平線在前沿技術領域的頂尖研發水平。
CVPR如同連接學術與產業的 “黃金橋梁”,一端錨定前沿理論的創新高地,另一端銜接產業落地的實踐沃土,讓實驗室里的技術構想,通過這座橋梁轉化為賦能千行百業的實際價值。作為全球計算機視覺領域的頂級會議,CVPR每年吸引全球超萬份高質量論文投稿,僅有少數兼具創新性與實用性的研究成果能夠脫穎而出。
本文將分享地平線此次入選的11篇研發工作。
基于歸一化殘差軌跡建模的端到端自動駕駛新范式
? 論文題目:
ResAD: Normalized Residual Trajectory Modeling for End-to-End Autonomous Driving
?論文鏈接:
https://arxiv.org/abs/2510.08562
? 項目主頁:
https://duckyee728.github.io/ResAD
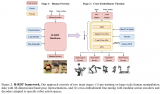
端到端自動駕駛 (E2EAD) 系統因軌跡數據固有的時空不平衡性,面臨模型易學習虛假關聯、優化過程過度關注遠距離不確定預測而犧牲即時安全的核心難題。針對上述問題,地平線提出ResAD,為E2EAD打造了全新的軌跡預測范式,核心創新點與技術突破體現在重構學習任務、優化目標加權、實現高效多模態規劃三大維度,大幅簡化了模型學習難度并提升規劃性能。

ResAD摒棄直接預測未來軌跡的傳統思路,先基于自車當前狀態通過恒速模型生成慣性參考軌跡這一穩健的物理先驗,將學習任務重構為預測實際軌跡相對該參考的殘差偏差,迫使模型聚焦于學習由交通規則、障礙物等場景上下文驅動的必要修正,而非從頭學習復雜的時空動力學,從根源上避免虛假關聯的學習。針對長時程預測的不確定性導致的優化失衡問題,提出逐點殘差歸一化 (PRNorm) 技術,對預測殘差進行分量級歸一化并重新加權優化目標,有效解決了遠距離航點的大幅誤差主導學習信號的問題,保障了近場安全關鍵微調的精準捕捉。同時,設計慣性參考擾動 (IRP) 策略,通過對自車初始速度添加隨機擾動生成多樣化的慣性參考,無需依賴靜態預定義軌跡詞匯表,即可生成符合場景上下文的多模態軌跡假設,結合自研的軌跡排序器實現最優軌跡篩選,突破了傳統多模態規劃效率低、軌跡可行性差的局限。
ResAD通過從任務本質重構E2EAD的軌跡預測邏輯,成功解決了原始軌跡數據的時空不平衡難題,為端到端自動駕駛構建了更魯棒、穩定且可擴展的技術基礎,相關代碼將開源以推動后續研究。
用測試時訓練補上全局上下文
邁向公里級三維重建
? 論文題目:
Scal3R: Scalable Test-Time Training for Feed-forward Large-Scale 3D Reconstruction
大規模長序列三維重建在自動駕駛、機器人建圖、數字孿生等場景中具有重要應用價值,但現有方法在“規模”與“精度”之間始終存在明顯矛盾:以VGGT為代表的feed-forward幾何模型雖然具備很強的局部重建能力,卻受限于注意力的二次復雜度,難以直接擴展到超長序列和公里級場景;FastVGGT通過token壓縮換取更高效率,卻不可避免地損失細粒度幾何信息和長程依賴;VGGT-Long則依賴chunk切分與后期對齊來處理長序列,但由于缺乏真正的全局上下文共享,模型對局部預測誤差高度敏感,容易在跨chunk重建中積累不一致,影響整體結構穩定性。針對這一核心瓶頸,本文提出Scal3R,將Test-Time Training引入大規模三維重建過程,在僅使用RGB輸入的條件下實現對長序列全局上下文的高 效建模,為公里級場景重建提供了一種兼顧精度、一致性與擴展性的全新方案。

Scal3R的核心創新集中在全局上下文表示與跨chunk上下文同步兩大層面。在全局上下文表示方面,作者提出Global Context Memory (GCM) 機制,將一組輕量神經子網絡作為可快速適配的“神經記憶單元”,掛接在VGGT的全局注意力層后,并通過自監督目標在測試階段在線更新,從而把長程場景信息壓縮進可持續演化的上下文表示中。與傳統固定長度 記憶或簡單緩存不同,這種設計顯著提升了模型對長程依賴的承載能力,讓局部重建能夠獲得更充分的全局先驗。在跨chunk聚合方面,進一步提出Global Context Synchronization (GCS) 機制,將不同chunk、不同設備上的上下文更新進行高效同步,使每個局部塊在推理時都能共享來自全序列的全局信息,緩解傳統chunk-by-chunk方案中常見的跨段 不一致、局部誤差放大以及全局結構松散等問題。借助這一設計,Scal3R不只是把長序列“切開來算”,而是真正讓全局上下文參與到局部幾何推理之中,從根本上增強了大場景重建的穩定性與一致性。
實驗結果表明,Scal3R在KITTI Odometry、Oxford Spires、Virtual KITTI、ETH3D等多個大規模基準上取得了領先的位姿估計和三維重建表現,尤其在長序列、復雜視角變化和大尺度場景下,相比現有feed-forward、streaming memory-based方法以及chunk對齊方案展現出更強的全局一致性與幾何魯棒性。同時,該方法在效率上也保持了較好的實用性:既避免了長上下文Transformer常見的顯存膨脹問題,也顯著快于依賴重型全局優化的傳統SfM流程。總體來看,Scal3R將test-time adaptation、長程上下文建模與大規模三維幾何推理有機結合,為“僅憑RGB實現高質量公里級場景重建”提供了一條很有代表性的技術路線,也為今后長序列三維感知系統的可擴展設計帶來了新的啟發。
突破純視覺流式三維重建瓶頸
LongStream賦能公里級流式重建
? 論文題目:
LongStream: Long-Sequence Streaming Autoregressive Visual Geometry
?論文鏈接:
https://arxiv.org/abs/2602.13172
? 項目主頁:
https://3dagentworld.github.io/longstream
長序列流式三維重建在自動駕駛、機器人與AR/VR等場景中具有重要價值,但現有流式自回歸模型在長序列中普遍快速失穩。其根源在于,主流方法采用首幀錨定的絕對位姿建模,訓練時只見短序列,推理時卻要處理遠超訓練范圍的長視頻流,因而產生明顯的train-short, test-long域偏差,推理時被迫進行越來越困難的長程外推,最終導致誤差累積、軌跡漂移與幾何崩潰。同時,這類模型還表現出與大語言模型類似的attention sink現象,注意力異常沉積于首幀token,而非對重建更關鍵的時空鄰近幀,從而違背了局部幾何約束;長期累積的KV cache也會帶來表征污染、記憶飽和與幾何漂移。多種因素疊加,使現有方法往往在數十米范圍內便迅速失效。

針對這一核心瓶頸,LongStream從流式幾何學習的建模范式出發進行了系統重構。該方法采用Gauge-Decoupled設計,擺脫首幀錨定的絕對位姿回歸方式,轉而預測當前幀相對于最近關鍵幀的位姿,將隨序列長度不斷惡化的長程外推問題轉化為難度基本恒定的局部估計問題,從根本上削弱了對固定全局坐標系和首幀錨點的依賴。在此基礎上,LongStream進一步識別出attention sink和長期KV-cache污染是長時退化的主要來源,并提出 緩存一致性訓練,通過在訓練階段顯式傳遞和裁剪緩存,使訓練時的可見上下文與真實流式推理保持一致,引導模型在滑動窗口條件下學習穩定的局部時序依賴,而非繼續依賴首幀“沉積”注意力。
同時,該方法結合周期性緩存刷新,定期邊緣化陳舊上下文,清理退化記憶,抑制長期飽和與幾何漂移。由于整個系統建立在關鍵幀相對坐標系之上,緩存可在關鍵幀處刷新而不破壞重建一致性,從而使模型獲得更接近“無限流”處理的能力。基于這一系列設計,LongStream實現了公里級、實時、穩定的流式三維重建,為長序列視覺幾何建模提供了更魯棒、更可擴展的技術方案。其對長序列失效原因的識別和分析為相關領域研究提供了重要借鑒,有望推動流式重建模型在自動駕駛、AR/VR等實際應用場景的技術落地。
推動事件相機邁向駕駛智能
構建全棧事件語言基準
? 論文題目:
EventDrive: Event Cameras for Vision–Language Driving Intelligence
事件相機具備微秒級時間分辨率、高動態范圍和抗運動模糊等優勢,在高速運動、強光炫光和低照度等場景中,相比傳統幀相機更能穩定捕捉動態變化。但現有研究大多集中在檢測、分割、跟蹤等低層感知任務,尚未系統回答一個關鍵問題:事件信號能否進一步服務于自動駕駛中的高層語義理解、行為預測與決策規劃。EventDrive圍繞這一問題展開,首次將事件流、RGB圖像與語言監督統一到自動駕駛全流程框架中,推動事件視覺從“感知增強”走向“智能驅動”。

為填補這一空白,EventDrive構建了首個面向自動駕駛全棧智能的事件-語言基準,將任務統一劃分為Perception、Understanding、Prediction和Planning四個層級,共覆蓋17個子任務,形成約47.6萬條 事件-幀-語言樣本,為評測事件相機在駕駛智能中的實際價值提供了系統平臺。相較以往主要關注caption或簡單問答的數據集,EventDrive首次把事件模態推進到自動駕駛“感知—理解—預測—規劃”的完整閉環中。
在模型層面,論文進一步提出EventDrive-VLM。該方法通過 多時間尺度事件體素化 與 動態時間域事件編碼 建模不同頻率和運動模式下的事件特征,并引入Event Q-Former提取與語言任務相關的運動表征,實現事件模態、圖像模態與語言推理空間之間的有效對齊。大量實驗表明,EventDrive-VLM在多類駕駛推理任務上取得了顯著提升,尤其在動態變化、運動狀態和時序推理相關任務中,事件信號展現出對傳統幀模態的重要補充價值。
EventDrive的提出,為事件相機融入自動駕駛高層智能系統提供了新的研究范式,也為未來構建更魯棒、更高時效的多模態駕駛系統奠定了基礎。
貫通“視覺-幾何-功能-人類感知”
駕駛世界模型閉環評估新范式
? 論文題目:
WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
?論文鏈接:
https://arxiv.org/abs/2512.10958
? 項目主頁:
https://worldbench.github.io/worldlens
當前駕駛場景生成式世界模型雖能合成高視覺真實感的4D環境,但普遍存在物理邏輯違規、幾何一致性缺失、功能可用性不足等問題,且行業缺乏統一的綜合評估標準,現有指標僅側重幀級視覺質量,難以衡量物理合理性、多視圖一致性及實際應用價值。針對這一核心痛點,本文提出WorldLens—— 首個覆蓋 “生成質量、重建一致性、動作跟隨性、下游任務適配、人類偏好” 五大維度的全光譜評估基準,配套構建WorldLens-26K大規模人類偏好數據集與WorldLens-Agent自動評估模型,形成 “基準-數據集-評估代理” 三位一體的完整評估生態,實現對駕駛世界模型 “視覺真實感、幾何一致性、物理plausibility、功能可靠性” 的全方位量化與解讀。

其核心創新性體現在三大維度:一是評估維度的全景化突破,首次將4D重建一致性、閉環動作跟隨性、下游感知任務適配性與人類主觀偏好納入統一框架,拆解為24個細粒度子維度,覆蓋從低階視覺特征到高階行為邏輯的全鏈路評估;二是評估體系的人機協同創新,通過26808條含文本理由的人類標注數據,建立客觀指標與人類感知的映射關系,進而訓練出WorldLens-Agent自動評估模型,該模型基于Qwen3-VL-8B微調,可實現零樣本場景下與人類判斷高度對齊的量化評分及可解釋性推理,解決人工評估效率低、主觀性強的痛點;三是評估指標的功能導向創新,引入閉環仿真(如Route Completion、ADS分數)、下游感知任務(3D檢測、占用預測)等功能性指標,突破傳統視覺評估的局限,實現對模型 “能用、好用” 的核心訴求的量化。
實驗驗證顯示,現有主流模型均無全能表現:DiST-4D在幾何重建與下游任務適配中表現最優,OpenDWM在視覺真實感上領先,而所有模型在閉環動作跟隨性上仍存在顯著短板(路線完成率普遍低于 15%)。WorldLens通過標準化評估流程與工具鏈,不僅揭示了當前模型在 “視覺真實” 與 “物理/功能真實” 間的核心矛盾,更提供了精準的缺陷診斷能力,為駕駛世界模型從 “看起來真實” 向 “行為真實、可用可靠” 的進化提供了關鍵技術支撐。
突破大規模3D重建效率瓶頸
實現千圖序列10×加速
? 論文題目:
LiteVGGT: Boosting Vanilla VGGT via Geometry-aware Cached Token Merging
?論文鏈接:
https://arxiv.org/abs/2512.04939
? 項目主頁:
https://garlicba.github.io/LiteVGGT
VGGT作為3D視覺基礎模型,在多視圖3D重建任務中表現卓越,但因其Transformer架構的全局注意力機制存在二次計算與內存復雜度,處理長序列圖像時易出現內存溢出 (OOM) 、推理耗時過長等問題,難以適配大規模場景應用。針對這一核心痛點,本文提出LiteVGGT,通過創新的幾何感知緩存token merging策略,在保持VGGT核心重建精度的前提下,實現了10倍推理加速與顯著內存節省,并支持千圖級圖像序列的高效單次推理3D重建。

LiteVGGT的核心貢獻體現在三個方面:首先,提出幾何感知token優先級劃分機制,通過識別對三維幾何結構最關鍵的視覺token,在減少計算量的同時保留重建所需的關鍵幾何信息;其次,設計跨層緩存融合索引策略,復用相鄰global attention層的token融合索引,在僅帶來輕微精度下降的情況下顯著降低推理時延;此外,結合多源數據精細化微調與FP8量化推理,進一步提升模型運行效率并降低顯存占用,構建完整的高效推理優化方案。
實驗結果表明,LiteVGGT在ScanNet-50、Tanks & Temples等多種室內外大規模場景數據集上表現出色:在處理1000張圖像序列時,相比原始VGGT實現10倍 推理加速,顯存占用顯著降低,同時點云重建精度和相機姿態估計性能均接近原模型。該方案無需修改VGGT核心架構,具有良好的兼容性與工程落地能力,可為自動駕駛、AR/VR等應用場景提供高效的大規模三維重建能力。
深度賦能+區域自適應
破解視覺3D占用預測兩大核心痛點
? 論文題目:
Dr.Occ: Depth- and Region-Guided 3D Occupancy from Surround-View Cameras for Autonomous Driving
?論文鏈接:
https://arxiv.org/abs/2603.01007
3D語義占用預測是自動駕駛感知的核心任務,但其視覺-based方法長期面臨兩大關鍵瓶頸:一是2D到3D視圖轉換中因低分辨率、高噪聲深度估計導致的幾何錯位,二是語義類別空間分布各向異性引發的嚴重類別不平衡。針對上述痛點,本文提出Dr.Occ—— 深度與區域雙引導的3D占用預測框架,通過創新的幾何增強與語義建模模塊實現協同優化,在Occ3D-nuScenes基準上較強基線BEVDet4D提升7.43% mIoU與3.09% IoU,且可無縫集成至SOTA方法COTR并額外提升1.0% mIoU,展現出極強的通用性與工程價值。

本項目核心創新在于兩大技術突破:其一,提出深度引導雙投影視圖Transformer (D2-VFormer) 。針對實驗發現的“直接融合深度圖易導致性能退化”這一挑戰,該模塊利用MoGe-2生成的高質量深度線索構建體素級掩碼 (Voxel-level Masks) ,引導模型精準聚焦非空區域。通過“前向投影下采樣-反向投影致密化-深度引導非空精煉”三階段流程,有效攻克了2D-to-3D轉換中的幾何錯位難題,實現了深度基準模型向3D占用任務的高效遷移。其二,提出區域引導專家Transformer (R-EFormer) 及其遞歸變體R2-EFormer。該方法基于3D空間語義分布的強位置偏好,將傳統混合專家 (MoE) 的通道激活機制升華為空間維度的選擇性專家建模。通過為不同空間區域自適應分配專屬專家,該架構有效捕捉了復雜的空間異構語義,并顯著提升了稀有類別的識別召回率,為3D占用任務提供了全新的空間特征融合范式。
機器人首次實現語義進展推理
零標簽在指令結構中定位任務進展
? 論文題目:
Progress-Think: Semantic Progress Reasoning for Vision-Language Navigation
?論文鏈接:
https://arxiv.org/abs/2511.17097
? 項目主頁:
https://horizonrobotics.github.io/robot_lab/progress-think
在視覺語言導航 (VLN) 中,機器人長期缺乏一種關鍵能力:它能持續前進,卻無法判斷自己的任務推進到了哪一步。導航在空間中不斷展開,畫面節節推進,但模型并不知道自己在自然語言指令里處于什么階段,因此容易漂移、兜圈,或做出難以解釋的決策。我們認為,引入語義進展推理,是破解長程導航不穩定性的關鍵路徑。
為了在沒有進展標注的情況下習得進展定位能力,我們設計了一個三階段的學習框架。第一階段,通過前綴對齊的自監督訓練,模型在視覺軌跡中自動推斷出與指令前綴的對應關系,使“當前觀察對應哪一語義段落”成為一種內生表征,而非依賴外部標注。第二階段,我們將進展表示作為上下文注入導航VLA策略,使決策在結合指令和觀測的同時,也能參考自身的任務進展,從而形成明確的語義方向感。第三階段,通過進展推理與導航VLA策略的聯合優化,使模型在推理時保持一致、穩健的進展定位能力,并形成從語義對齊到動作生成的完整閉環。

在三階段學習下,進展不再是一個回歸值或附加標簽,而演化為貫穿視覺理解、語義推理與行動決策的結構性信號。機器人由此首次具備真正的“進展定位”能力,能夠在執行中持續推理“我完成到哪了”,并據此更清晰地決策“下一步該做什么”。
Progress-Think讓機器人第一次具備語義層面的“進展坐標系”。我們首次揭示了視覺觀測序列與指令語義之間的結構性關聯,并將其提煉為可學習的進展信號,使模型無需額外標注即可學會思考:“我剛完成了什么”。通過自監督的進展對齊、進展引導決策以及進展–策略聯合微調,僅憑單目相機輸入,模型就能顯著減少偏航并提升穩定性。Progress-Think在R2R-CE等標準數據集上取得領先表現,并進一步推動具身推理朝更明確的任務導向發展。
從解耦到統一
以通用高斯范式突破3D重建與語義理解邊界
? 論文題目:
Uni3R: Unified 3D Reconstruction and Semantic Understanding via Generalizable Gaussian Splatting from Unposed Multi-View Images
?論文鏈接:
https://arxiv.org/abs/2508.03643
? 項目主頁:
https://horizonrobotics.github.io/robot_lab/uni3R
現有3D場景重建方案,普遍面臨任務表征解耦與多視圖擴展受限兩大局限。一方面,幾何重建與語義理解通常被獨立建模,且高度依賴耗時的逐場景優化,直接限制了系統的泛化能力;另一方面,現有框架多局限于雙視圖輸入,擴展至多視圖時需進行高計算成本的逐對特征匹配,常導致跨視圖幾何不一致。為解決上述計算冗余與表征割裂問題,本文提出了一種基于通用3D Gaussian Splatting的前饋式3D感知底座Uni3R。

Uni3R系統僅需無姿態的多視圖純視覺輸入,即可直接生成融合幾何結構、外觀表征與開放詞匯語義的3D隱式表示。架構設計上,模型采用跨視圖Transformer融合機制,通過交替執行幀內自注意力與幀間交叉注意力,在無相機姿態先驗的條件下,實現了對任意數量視圖信息的高效整合。針對純渲染監督易引發的幾何坍塌問題,框架引入無標注幾何先驗以約束高斯基元的空間分布,從而在零額外幾何標注的前提下,顯著提升了訓練穩定性與深度預測精度。依托該統一表征空間,Uni3R僅需單次前向傳播,即可并發執行高保真新視角合成、開放詞匯3D語義分割與深度預測三項核心任務。此外,實驗表明,多任務統一表征機制不僅大幅削減了底層計算冗余,更在幾何重建、視角渲染與語義理解之間確立了顯著的協同增益。
定量實驗表明,Uni3R徹底摒棄了逐場景優化與外部姿態估計依賴,單場景整體重建耗時僅約0.16秒。在ScanNet數據集上,其開放詞匯語義分割精度達到55.84 mIoU,新視圖合成質量達到25.53 PSNR;在RE10K數據集上,新視圖合成質量達25.07 PSNR。整體量化指標均優于PixelSplat與LSM等主流框架,為自動駕駛與機器人數字孿生提供了高效、可擴展的實時3D場景感知方案。
幾何一致視覺世界模型
突破機器人操作泛化邊界
? 論文題目:
RoboTransfer: Controllable Geometry-Consistent Video Diffusion for Manipulation Policy Transfer
?論文鏈接:
https://arxiv.org/abs/2505.23171
? 項目主頁:
https://horizonrobotics.github.io/robot_lab/robotransfer
在機器人操作領域,模仿學習是推動具身智能發展的關鍵路徑,但高度依賴大規模、高質量的真實演示數據,面臨高昂采集成本與效率瓶頸。仿真器雖提供了低成本數據生成方案,但顯著的“模擬到現實” (Sim2Real) 鴻溝,制約了仿真數據訓練策略的泛化能力與落地應用。
我們提出RoboTransfer——基于擴散模型的視頻生成框架,旨在合成高保真且符合物理規律的機器人操作演示數據。該框架創新性地融合深度-表面法向的幾何約束與多視角特征建模,確保生成視頻具備高度幾何一致性與真實感。通過拆分控制條件設計,實現對操作場景元素(如背景替換、物體外觀)的精細控制。結合物理仿真器重構空問布局與交互狀態,實現多樣化、可拓展的高保真數據合成。

RoboTransfer通過數據驅動的生成式AI技術,建立機器人操作數據合成新范式,提供高質量、可擴展的演示數據,助力具身智能突破通用性與泛化性邊界。實驗結果表明,RoboTransfer能夠生成具有高幾何一致性和視覺質量的多視角視頻序列。此外,使用RoboTransfer合成數據訓練的機器人視覺策略模型,在標準測試任務中表現出顯著提升的性能:在更換前景物體的場景下取得了33.3%的成功率相對提升,在更具挑戰性的場景下(同時更換前景背景)更是達到了251%的顯著提升。
打破3D重建與生成邊界
原位補全構建單圖3D場景生成新范式
? 論文題目:
3D-Fixer: Coarse-to-Fine In-place Completion for 3D Scenes from a Single Image
? 項目主頁:
https://zx-yin.github.io/3dfixer
? 代碼鏈接:
https://github.com/HorizonRobotics/3D-Fixer
基于單張圖像生成3D場景,是構建機器人與具身智能數字孿生環境的關鍵技術 。現有方案在處理復雜場景時,常面臨幾何重建不完整與姿態對齊易出錯的局限 ;此外,高質量場景級訓練數據的稀缺,也直接限制了現有模型的泛化能力 。為此,研究團隊提出了3D-Fixer技術框架,引入了“原位補全 (In-place Completion) ”范式 。該范式摒棄了傳統的顯式姿態對齊流程。其核心機制是利用3D基礎模型,提取場景中觀測到的殘缺幾何信息作為空間錨點,直接在原位進行3D生成與幾何補全。這一設計在維持全局布局一致性的同時,兼顧了空間定位的準確度與生成物體的完整度,從而有效規避了傳統迭代對齊與位姿優化過程中固有的誤差累積與結構錯位問題。

模型結構上,3D-Fixer通過引入 由粗到精 (Coarse-to-Fine) 的生成策略與遮擋魯棒特征對齊 (Occlusion-Robust Feature Alignment) 機制,將預訓練的物體生成先驗與真實場景中的幾何觀測信息進行深度融合,使模型能夠在存在遮擋的情況下仍然穩定推斷場景結構,并有效緩解遮擋區域邊界模糊的問題。與此同時,為解決高質量場景級訓練數據長期稀缺的瓶頸,團隊構建并開源了目前規模最大的組合式場景數據集ARSG-110K,其中包含超過11萬個程序化生成的復雜場景配置以及300萬張帶有高保真三維標注的圖像數據對。
實驗結果表明,3D-Fixer在保持前饋推理高效性的同時,實現了當前領先水平的幾何重建精度,為機器人與具身智能系統提供了一種高保真、具備良好泛化能力的三維場景生成新基準,并為構建大規模可交互數字孿生環境提供了重要技術支撐。
-
計算機
+關注
關注
19文章
7822瀏覽量
93331 -
自動駕駛
+關注
關注
794文章
14930瀏覽量
180628 -
地平線
+關注
關注
0文章
465瀏覽量
16434
原文標題:CVPR 2026重磅揭曉!地平線11篇論文強勢入選,前瞻技術實力引領行業創新
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
地平線正式開源HoloBrain VLA基座模型

地平線智駕安全基座榮獲SGS ISO 26262功能安全產品證書
地平線與行深智能達成戰略合作
地平線與元戎啟行達成戰略合作
知行科技亮相2025地平線技術生態大會
地平線五篇論文入選NeurIPS 2025與AAAI 2026

地平線HSD量產先鋒品鑒會圓滿落幕
Nullmax端到端軌跡規劃論文入選AAAI 2026
地平線與采埃孚推出城市領航coPILOT輔助駕駛系統

地平線與哈啰正式簽署戰略合作協議
地平線H-RDT模型斬獲CVPR 2025大賽冠軍



 工商網監
工商網監
評論