 安霸大算力AI芯片接入DeepSeek R1
安霸大算力AI芯片接入DeepSeek R1

安霸(Ambarela)在人工智能領域持續發力,已成功在多款 AI 芯片,包括 N 系列大算力 AI 芯片上本地部署了 DeepSeek R1。
這一舉措意義重大,不僅使模型推理速度提升,而且滿足了客戶在開發端側設備上超低功耗、低延遲推理的需求。未來,針對機器人市場、消費類電子以及汽車市場,安霸將推出更加完整、成熟且快速響應的支持體系。這不僅能讓客戶更加便捷地運用大語言模型,還將助力行業客戶構建屬于自己的 AI 系統。借助大模型的先進技術,客戶能夠顯著提升產品的競爭力,在競爭激烈的 AI 賽道上始終保持領先地位,為各行業的智能化發展注入強大動力。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
AI芯片
+關注
關注
17文章
2126瀏覽量
36766 -
安霸
+關注
關注
3文章
55瀏覽量
13465 -
DeepSeek
+關注
關注
2文章
835瀏覽量
3255
原文標題:安霸大算力 AI 芯片本地部署 DeepSeek R1
文章出處:【微信號:AMBARELLA_AMBA,微信公眾號:Ambarella安霸半導體】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
云天勵飛如何助力中國AI芯片突圍
過去兩年,人工智能以驚人的速度席卷全球。從ChatGPT的橫空出世,到Sora等多模態模型的突破,再到中國DeepSeek R1的開源,AI技術正以前所未有的節奏重塑產業格局。算
邊緣計算AI硬件如何接入DeepSeek嗎?需要具備哪些條件?
成本極低,R1模型的訓練成本僅為560萬美元,遠低于美國科技巨頭數億美元乃至數十億美元的投入。這一顛覆式創新打破了“更強大的硬件、更高的算力才是推動人工智能發展的關鍵”

如何在NVIDIA Blackwell GPU上優化DeepSeek R1吞吐量
開源 DeepSeek R1 模型的創新架構包含多頭潛在注意力機制 (MLA) 和大型稀疏混合專家模型 (MoE),其顯著提升了大語言模型 (LLM) 的推理效率。
速看!EASY-EAI教你離線部署Deepseek R1大模型
1.Deepseek簡介DeepSeek-R1,是幻方量化旗下AI公司深度求索(DeepSeek)研發的推理模型。DeepSeek-R1采用

DeepSeek開源新版R1 媲美OpenAI o3
DeepSeek“悄悄”地又放了一個大招,DeepSeek開源了R1最新0528版本。盡管DeepSeek目前還沒有對該版本進行任何說明,但是根據著名代碼測試平臺Live CodeBe

DeepSeek R1模型本地部署與產品接入實操
針對VS680/SL1680系列大算力芯片,我們的研發團隊正在研究將蒸餾后的輕量級DeepSeek模型(DeepSeek-R1-Distil
科大訊飛深度解析DeepSeek-V3/R1推理系統成本
本篇分析來自科大訊飛技術團隊,深度解析了DeepSeek-V3 / R1 推理系統成本,旨在助力開發者實現高性價比的MoE集群部署方案。感謝訊飛研究院副院長&AI工程院常務副院長龍明康、AI
DeepSeek推動AI算力需求:800G光模塊的關鍵作用
隨著人工智能技術的飛速發展,AI算力需求正以前所未有的速度增長。DeepSeek等大模型的訓練與推理任務對算
發表于 03-25 12:00
科通技術推出DeepSeek+AI芯片全場景方案
2025年,隨著DeepSeek新版本的開源,AI技術掀起了全球普及的浪潮。在這股浪潮中,AI芯片作為關鍵算
存力接棒算力,慧榮科技以主控技術突破AI存儲極限
電子發燒友網報道(文/黃山明)在AI的高速增長下,尤其是以DeepSeek為代表的AI大模型推動存儲需求激增,算力增長倒逼存

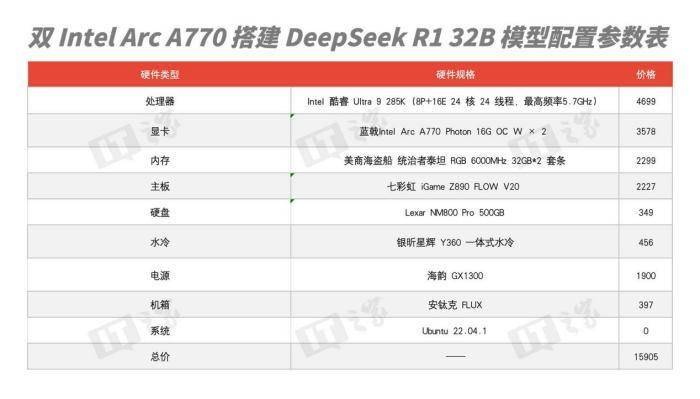
顯存也能疊疊樂,雙 Intel Arc A770 顯卡低成本部署 DeepSeek R1 32B 蒸餾模型體驗
今年春節后,DeepSeek R1 風暴般地席卷全國,小到手機 App,大到新能源汽車,似乎一夜間所有產品都接入了 DeepSeek R1。
DeepSeek-R1:別被它的光環迷了眼,這些能力局限你得知道!
作者:算力魔方創始人/英特爾創新大使劉力 最近,DeepSeek-R1 可是火遍了全網,號稱“超越人類專家”,數學競賽奪冠、代碼能力碾壓人類開發者……聽起來是不是很厲害?但別急著被這些
實戰案例 | 299元國產工業級AI核心板部署DeepSeek-R1
前言:在AIoT領域,搭載Ubuntu系統的眺望T527開發板,僅憑2GB內存便成功運行15億參數的DeepSeek-R1輕量級大模型!在邊緣端上演一場算力革命,這一突破性進展不僅刷新了邊緣A




 工商網監
工商網監
評論