 如何在NVIDIA Blackwell GPU上優化DeepSeek R1吞吐量
如何在NVIDIA Blackwell GPU上優化DeepSeek R1吞吐量

前言
開源 DeepSeek R1 模型的創新架構包含多頭潛在注意力機制 (MLA) 和大型稀疏混合專家模型 (MoE),其顯著提升了大語言模型 (LLM) 的推理效率。但要充分發揮這種創新架構的潛力,軟硬件的協同優化也至關重要。本文將深入解析 NVIDIA 在基于 Blackwell GPU 的TensorRT-LLM框架內為 DeepSeek R1 吞吐量優化場景 (TPS / GPU) 開發的優化策略。文內將詳細闡述各項優化措施的設計思路。另一篇關于降低延遲的博客(見下)已詳細解釋了 TensorRT-LLM 如何通過提升 R1 性能實現最佳 TPS / USER。
這些優化措施顯著提升了 DeepSeek R1 在 Blackwell 上的吞吐量。其在 ISL / OSL 1K / 2K 數據集上的性能從 2 月的約 2000 TPS / GPU 提升至 4600 TPS / GPU。這些優化措施具有通用性,可適用于其他 ISL / OSL 配置。其大致分為三個方面:MLA 層、MoE 層和運行時。
精度策略
DeepSeek R1 吞吐量場景的混合精度策略與延遲優化場景的策略基本一致,具體差異如下:
使用 FP8 KV 緩存和 FP8 注意力機制,而非 BF16 精度。
使用 FP4 Allgather 提高通信帶寬利用率。
本文中使用的 Checkpoint 位于 nvidia / DeepSeek-R1-FP4,由 NVIDIA 模型優化器生成。常用數據集在該 FP4 Checkpoint 和 TensorRT-LLM 執行中準確率分數為:
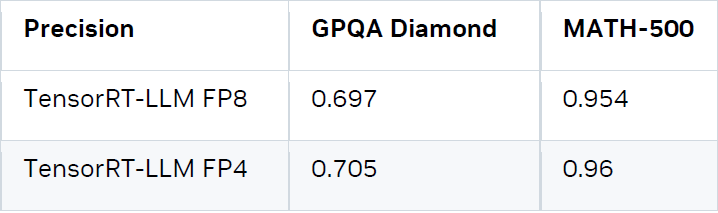
** 注意這些評估結果存在運行間波動,因此 FP4 數據的分數略高。我們認為 FP4 在這些數據集上的精度與 FP8 相當。
該 Checkpoint 中的 MoE 層已量化為 FP4。將 MoE 層權重量化為 FP4 具有以下優點:
充分利用 NVIDIA Blackwell GPU 第五代 Tensor Core 的 FLOPS(每秒浮點運算)
將 MoE 權重所需的顯存負載減少近一半。在該場景中,MoE 部分在 Decoding 階段仍受顯存限制,且 DeepSeek R1 模型中 97% 的權重來自 MoE 層。
減少模型權重的顯存占用,從而釋放更多 GPU 顯存用于 KV 緩存,進而增加最大并發數。DeepSeek R1 模型的原始 FP8 量化 Checkpoint 大小約為 640GB,而 NVIDIA 提供的 DeepSeek R1 FP4 量化模型僅為約 400GB。
我們在 GSM8K 數據集上對 FP8 KV 緩存和 FP8 注意力內核的精度進行了評估,未觀察到明顯的準確率下降。有關準確率數據,請參見 FP8 KV 緩存部分的表格。如果用戶在自己的數據集上觀察到準確率差異,仍可選擇使用 BF16 KV 緩存和注意力機制。
并行策略
DeepSeek R1 吞吐量場景的并行策略與延遲場景的策略有所不同。
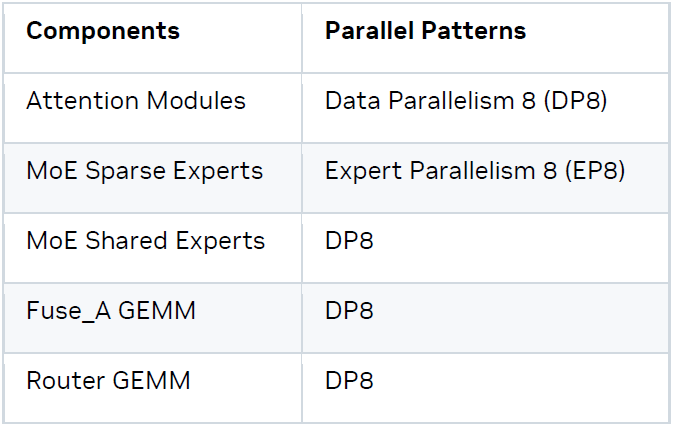
在接下來的部分,我們將解釋為何選擇數據并行 (DP) 和專家并行 (EP),而非張量并行 (TP)。
權重吸收與 MQA
MLA 的核心理念是通過對注意力鍵 (K) 和值 (V) 進行低秩聯合壓縮,減少推理過程中的 KV 緩存大小。基于 MLA 公式,向下投影的 KV Latent 被向上投影到多個頭并與向上投影的 Q 結合,形成常規的多頭注意力機制 (MHA)。由于矩陣乘法的性質,K 的向上投影權重矩陣 (W^UK) 可先與 Q 的向上投影權重矩陣 (W^Q) 相乘,再將結果與 Q 相乘。V 的向上投影權重矩陣 (W^UV) 與注意力輸出投影矩陣 W^O 也可在注意力輸出后相乘。DeepSeek-V2 技術報告將該技術稱為“吸收”。在權重被吸收后,MLA 等價于多查詢注意力 (MQA)。參見 DeepSeek-V2 技術論文獲取詳細公式和解釋,下圖所示的是 TensorRT-LLM 中權重吸收 MLA 的計算流程。
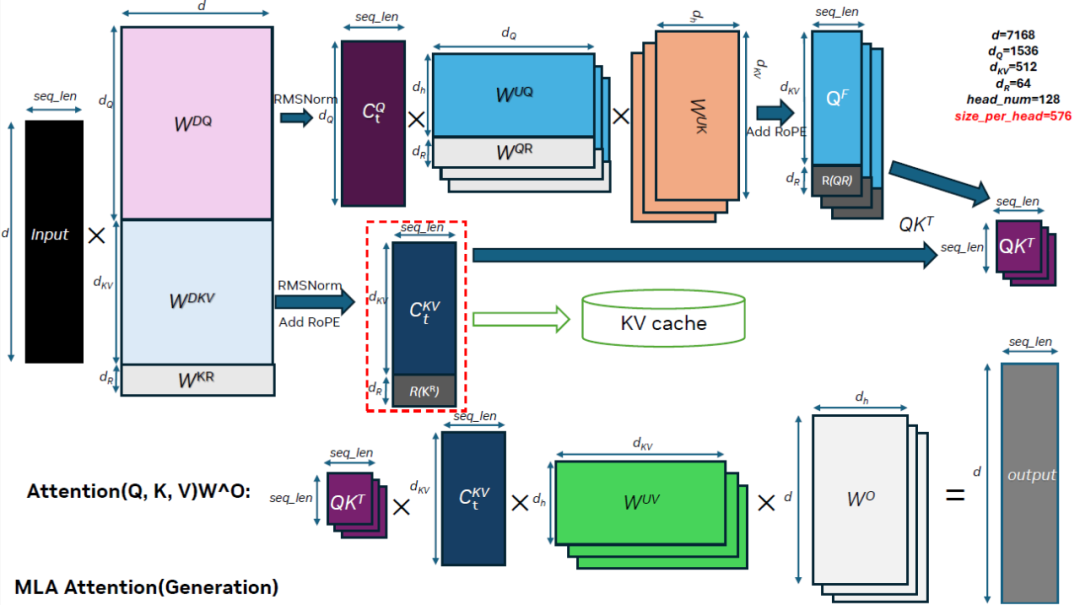
該圖片來源于 Github:Optimizing DeepSeek R1 Throughput on NVIDIA Blackwell GPUs: A Deep Dive for Developers一文,若您有任何疑問或需要使用該圖片,請聯系該文作者
在 Decoding 階段,權重吸收顯著減少向上投影 K 和 V 所需的數學 FLOPS,這是因為這些 KV 向上投影所需的 FLOPS 與 KV 緩存長度成線性關系,而 Decoding 階段的 Q 向量長度始終為 1。KV 緩存歷史越長,所需的 FLOPS 越多,且由于僅保存了投影的 KV Latent,每個 Decoding Token 都需要重復進行向上投影,這進一步增加了所需的 FLOPS。在 Prefill 階段,吸收權重的版本改變了 Q 和 KV 的維度,增加了注意力機制所需的 FLOPS。根據 Roofline 分析,在輸入長度為 256 或以上的情況下,非吸收版本更有利于 Prefill 階段。TensorRT-LLM MLA 實現為 Prefill 和 Decoding 階段分別選擇了不同的高度優化內核,詳見 MLA。
注意力模塊數據并行 (ADP)
選擇注意力數據并行 (ADP) 的核心原因是對 MQA(由不同 GPU 計算不同的注意力 Q 頭)采用張量并行 (TP) 會重復復制 KV 緩存顯存,從而限制系統能夠實現的并發性。重復因子等于 TP 組大小,因此 TP8 時為 8 倍。并發性低會影響高性能系統 (如 NVIDIA DGX B200) 的吞吐量。
對于使用 8 個 B200 GPU 的 DeepSeek R1 FP4 Checkpoint,每個 GPU 的權重和激活占用約 80GB 顯存,每個 GPU 的可用 KV 緩存將為 100GB。假設 ISL 為 1K,OSL 為 2K,每次請求將消耗約 200MB KV 緩存,使每個 GPU 的最大并發數為 500。單節點 8 GPU 系統的全局并發性為 4000。使用 ATP 時,全局并發性將降至 500。
硅片實驗表明,在保持所有其他因素不變的情況下,ADP 技術在最大吞吐量場景下可提速 400%。
MoE 專家并行 (EP)
DeepSeek R1 MoE 設計包含 256 個小型稀疏專家模型和 1 個共享專家模型,這些專家模型的 GEMM 問題規模如下。
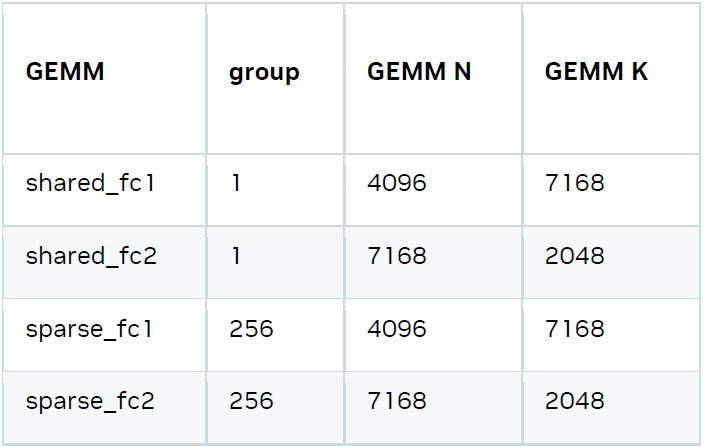
這些專家模型可采用張量并行 (TP) 或專家并行 (EP) 的方式實現。目前的消融實驗表明,由于 GEMM 問題規模更小,專家并行在 GEMM FLOPS 方面的表現更好。并且與 AllReduce 相比,專家并行可節省 GPU 通信帶寬,這是因為只需將 Token 發送至該 Token 對應的活躍專家所在的 GPU,而張量并行 (TP) 則需對所有 GPU 間的 Token 執行 AllReduce 操作。此外,為了將 DeepSeek R1 推理擴展到 GB200 NVL72 等系統并充分利用聚合顯存帶寬和 Tensor Core FLOPS,需要使用大型專家并行。我們正在積極推進該技術的實現。
硅片性能測試表明,在保持其他因素不變的情況下,專家并行 (EP) 可在 1K / 2K 最大吞吐量場景下將速度提升 142%。
MLA 層優化
除了上述提到的并行策略和精度策略外,我們在 MLA 模塊內的層 / 內核中進行了以下優化。
注意力內核優化
該優化措施使端到端速度較 2 月基線實現版本提升了 20%。其使用高吞吐量生成 MLA 內核,所涉及的技術包括使用 Blackwell GPU 的 Tensor Core 5th MMA 指令的 2CTA 組變體,通過 interleaved tile 將 MLA 與 softmax 重疊,并針對 DeepSeek R1 問題規模微調內核選擇啟發式算法。
FP8 KV 緩存
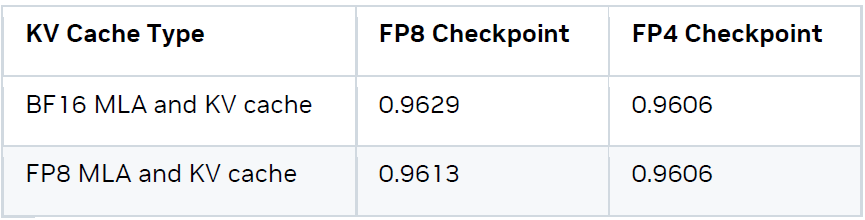
這項重要的優化措施能夠在并發性相同的情況下使端到端吞吐量提升 6%。FP8 KV 緩存的另一個優點是將 KV 緩存大小減半,從而支持更大的并發性,并使用比運行 BF16 數據類型更快的 FP8 注意力內核。我們建議用戶始終啟用 FP8 KV 緩存以提高性能。在上下文階段,KV 被量化為 FP8 并保存到 KV 緩存池中。在生成階段,Q 和 KV 均被量化為 FP8 并使用 FP8 多查詢注意力機制 (MQA)。在 GSM8k 數據集上的評估顯示,準確率無明顯下降。量化通常使用靜態的每張量 FP8,縮放因子默認設置為 1.0,但 KV 緩存縮放因子也可通過在目標數據集上校準生成。以下是不同組合在 GSM8K 數據集上的準確率指標。
手動 GEMM 策略調優
此優化措施針對 cuBLAS 中默認啟發式算法在模型中存在特定 GEMM 形狀時表現不佳的情況。我們開發了一個內部工具用于離線查找適合這些特定形狀的最佳算法,然后在運行時使用cublasLtMatmulAPI 應用此特定優化算法。當通用啟發式算法無法為所有特定場景找到最高效的內核時,這一系統優化十分必要。我們也正與 cuBLAS 團隊積極合作,進一步改進啟發式算法,以便始終能夠實現開箱即用 (OOTB) 的最佳性能。調優詳情參見 cublasScaledMM.cpp。
水平融合
這涉及融合 Q / KV 向下投影 GEMM 操作與 K 張量的 RoPE 維度。詳情參見 modeling_deepseekv3.py。水平融合可減少內核啟動開銷并增大 GEMM 問題規模,從而提高硬件利用率。這是常用的低延遲優化和吞吐量優化技術。
雙流優化
在 MLA 中有一些小操作可并行運行,例如 Q 范數和 KV 范數。這些操作無法充分使用 GPU 的計算能力和顯存帶寬,因此可通過在并行 CUDA 流中運行來提升速度。
MoE 層優化
已對 MoE 層采取以下優化措施。
在RouterGEMM 中使用混合 I/O 數據類型
通過避免類型轉換 (Casting) 操作并直接使用混合輸入和輸出數據類型(例如 BF16 輸入和 FP32 輸出)執行 GEMM,將端到端速度提升了 4%。這樣就無需將輸入顯式轉換為輸出類型,并節省了顯存帶寬。
Top-K 內核融合
該優化措施將端到端速度提升了 7.4%。在 DeepSeek R1 中,從 256 個專家模型中選出前 8 名,其選擇過程分為兩個階段:首先選擇若干個專家組,然后在這些組中選出前 8 個專家。DeepSeek R1 采用了一些額外技術來實現更好的專家負載平衡,包括在 topK 復雜度中添加偏置和縮放因子。所有這些操作在未融合時都會產生 18 個 PyTorch 操作,詳見 Deepseekv3RoutingImpl。融合這些 Top-K 計算所涉及的多個內核可顯著縮短整體計算時間。與使用 18 個原生 PyTorch 操作相比,融合可將操作數量減少到僅有 2 個內核。根據在 B200 平臺上的測量結果,融合這些內核可將目標設置下的內核時間從 252us 縮短至 15us。
FP4 AllGather 優化
該優化措施使端到端速度提升了 4%,將 BF16 AllGather 操作替換為了 FP4 版本。由于這種通信原語使用較低精度,因此網絡傳輸的數據量有所減少,而通信效率大幅提升。此外,由于原始的 BF16 張量在 AllGather 通信后會被轉換為 FP4 格式,此優化措施不會對準確性產生任何影響。在內核層面,從 BF16 切換到 FP4 AllGather 使性能提高了約 3 倍。
CUTLASS 組 GEMM 優化
該優化措施將端到端速度提升了 1.3%。若干 CUTLASS 方向的優化同時適用于低延遲和高吞吐場景。更新 CUTLASS 至最新版本即可將 MoE 組 GEMM 的內核性能提升 13% ,端到端 TPS / GPU 提升 1.3%。
多流優化
在雙流中運行共享和路由專家,結合 MLA 模塊中的其他多流優化措施將端到端速度提升了 5.3%。
運行時優化
這些優化措施旨在推理系統中的整體執行流程、調度和資源管理。它們在 DeepSeek R1 模型和其他 TensorRT-LLM 支持的模型之間共享。下面將介紹一些提升 B200 上 DeepSeek R1 性能的消融實驗。
CUDA Graph
CUDA Graph 將吞吐量場景中的端到端性能提升了 22%。
CUDA Graph 允許捕獲一連串 CUDA 操作并將其作為單個單元啟動,從而大幅減少內核啟動開銷。這對于具有大量小型內核的模型特別有益,尤其是在 PyTorch 流程上,因為 Python 主機代碼的執行速度通常慢于 C++。由于 CUDA Graph 凍結了內核啟動參數(這些參數通常與張量形狀相關),因此只能安全地用于靜態形狀,這意味著不同批次大小需要捕獲不同的 CUDA Graph。每個 Graph 都會產生一些顯存使用和捕獲時間的開銷,因此無法為所有可能的批次捕獲所有可能的 CUDA Graph。對于未捕獲的批次大小,將執行 PyTorch 的即時模式代碼。
TensorRT-LLM 中有一個名為“CUDA Graph 填充”(CUDA Graph padding) 的功能,它在 CUDA Graph 的數量和命中率之間取得了很好的平衡;該功能嘗試將批次填充到最近捕獲的 CUDA Graph。通常情況下建議啟用 CUDA Graph 填充功能以提高 CUDA Graph 命中率,但填充本身會因 Token 計算的浪費而帶來一些開銷。
用戶可通過設置cuda_graph_config: enable_padding: False來禁用 CUDA Graph 填充功能以查看性能優勢。參見 API:Pytorch 后端配置
https://github.com/NVIDIA/TensorRT-LLM/blob/main/tensorrt_llm/_torch/pyexecutor/config.py#L41
重疊調度器
該優化措施將端到端性能提升了 4%,故應默認啟用。此調度器管理不同操作(如計算和通信)的執行,從而在 GPU 和網絡上有效重疊操作。其原理是通過在等待數據傳輸時執行計算(或反之)來隱藏延遲,從而提高整體硬件利用率。在 TensorRT-LLM 中,重疊調度已默認在提交時啟用。如果存在特殊情況導致其無法正常工作,用戶仍可通過將 disable_overlap_scheduler 設置為 true 來禁用此功能。
顯存優化
該優化措施減少了 4GB 顯存占用。所使用的技術包括針對 Hopper 架構的分塊 MoE 以及修復 CUDA 上下文初始化的錯誤。這些方法降低了模型權重或中間張量的顯存占用,從而支持更大的批次大小或序列長度,避免了顯存不足 (OOM) 的錯誤。
如何復現
參見性能優化實踐:
https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/Best_perf_practice_on_DeepSeek-R1_in_TensorRT-LLM.md#b200-max-throughput
未來工作
大型專家并行 (EP)
上下文分塊
增加通信重疊
致謝
本文詳細介紹了如何在 Blackwell GPU 上顯著提升 DeepSeek R1 的吞吐量,這是我們工程團隊共同努力的成果。他們通過深入研究 MLA 層、MoE 層和運行時優化措施,將 TPS / GPU 提高了近 2.3 倍。我們衷心感謝參與這次集中優化工作的所有工程師,他們的集體智慧在進一步突破 TensorRT-LLM 吞吐量性能方面起到了至關重要的作用。相信分享這些大幅提高吞吐量的針對性策略,將有助于開發者群體在 NVIDIA 硬件上部署高負載的 LLM 推理任務。
作者
張國銘
NVIDIA 性能架構師,目前主要從事大模型推理架構和優化。
-
NVIDIA
+關注
關注
14文章
5675瀏覽量
110042 -
gpu
+關注
關注
28文章
5241瀏覽量
135939 -
開源
+關注
關注
3文章
4286瀏覽量
46356 -
模型
+關注
關注
1文章
3794瀏覽量
52221
原文標題:在 NVIDIA Blackwell GPU 上優化 DeepSeek R1 吞吐量:開發者深度解析
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
NVIDIA Blackwell GPU優化DeepSeek-R1性能 打破DeepSeek-R1在最小延遲場景中的性能紀錄

DeepSeek R1 MTP在TensorRT-LLM中的實現與優化

了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
dm36x的吞吐量性能信息和SOC架構詳細概述
DM6467的吞吐量性能信息和系統芯片(SoC)架構的詳細概述
debug 吞吐量的辦法
debug 吞吐量的辦法

英偉達發布DeepSeek R1于NIM平臺
云天勵飛上線DeepSeek R1系列模型

NVIDIA RTX PRO 4500 Blackwell GPU測試分析




 工商網監
工商網監
評論