完善資料讓更多小伙伴認識你,還能領(lǐng)取20積分哦,立即完善>
標(biāo)簽 > llm
在人工智能領(lǐng)域,LLM代表“大型語言模型”。在人工智能(AI)領(lǐng)域自然語言處理(NLP)是一個快速進展的領(lǐng)域。NLP中最重要是大語言模型(LLM)。大語言模型(英文:Large Language Model,縮寫LLM),也稱大型語言模型,是一種基于機器學(xué)習(xí)和自然語言處理技術(shù)的模型。
文章:344個 瀏覽:1337次 帖子:3個

DeepSeek R1 MTP在TensorRT-LLM中的實現(xiàn)與優(yōu)化
TensorRT-LLM 在 NVIDIA Blackwell GPU 上創(chuàng)下了 DeepSeek-R1 推理性能的世界紀(jì)錄,Multi-Token P...
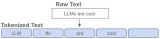
從原理到代碼理解語言模型訓(xùn)練和推理,通俗易懂,快速修煉LLM
要理解大語言模型(LLM),首先要理解它的本質(zhì),無論預(yù)訓(xùn)練、微調(diào)還是在推理階段,核心都是next token prediction,也就是以自回歸的方式...
近期,openEuler A-Tune SIG在openEuler 23.09版本引入llama.cpp&chatglm-cpp兩款應(yīng)用,以支持...
使用基于Transformers的API在CPU上實現(xiàn)LLM高效推理
英特爾 Extension for Transformers是英特爾推出的一個創(chuàng)新工具包,可基于英特爾 架構(gòu)平臺,尤其是第四代英特爾 至強 可擴展處理器...

隨著ChatGPT的快速發(fā)展,基于Transformer的大型語言模型(LLM)為人工通用智能(AGI)鋪平了一條革命性的道路,并已應(yīng)用于知識庫、人機界...
2023-11-27 標(biāo)簽:模型深度學(xué)習(xí)ChatGPT 4.1k 0
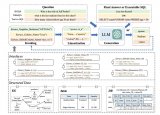
中國研究人員提出StructGPT,提高LLM對結(jié)構(gòu)化數(shù)據(jù)的零樣本推理能力
盡管結(jié)構(gòu)化數(shù)據(jù)的體量往往非常巨大,但不可能容納輸入提示中的所有數(shù)據(jù)記錄(例如,ChatGPT 的最大上下文長度為 4096)。將結(jié)構(gòu)化數(shù)據(jù)線性化為 LL...
2023-05-24 標(biāo)簽:數(shù)據(jù)管理自然語言處理知識圖譜 4.1k 0
LLM(線性混合模型)和LMM(線性混合效應(yīng)模型)之間的區(qū)別如下: 定義: LLM(線性混合模型)是一種統(tǒng)計模型,用于分析具有固定效應(yīng)和隨機效應(yīng)的線性數(shù)...
2024-07-09 標(biāo)簽:模型數(shù)據(jù)結(jié)構(gòu)LLM 4k 0

什么是向量數(shù)據(jù)庫?關(guān)系數(shù)據(jù)庫和向量數(shù)據(jù)庫之間的區(qū)別是什么?
向量數(shù)據(jù)庫是一種以向量嵌入(高維向量)方式存儲和管理非結(jié)構(gòu)化數(shù)據(jù)(如文本、圖像或音頻)的數(shù)據(jù)庫,以便于快速查找和檢索類似對象。
2023-08-16 標(biāo)簽:存儲器向量機機器學(xué)習(xí) 4k 0
由于本文以大語言模型 RLHF 的 PPO 算法為主,所以希望你在閱讀前先弄明白大語言模型 RLHF 的前兩步,即 SFT Model 和 Reward...
2023-12-11 標(biāo)簽:算法深度學(xué)習(xí)ChatGPT 4k 0

最新綜述!當(dāng)大型語言模型(LLM)遇上知識圖譜:兩大技術(shù)優(yōu)勢互補
LLM 是黑箱模型,缺乏可解釋性,因此備受批評。LLM 通過參數(shù)隱含地表示知識。因此,我們難以解釋和驗證 LLM 獲得的知識。此外,LLM 是通過概率模...

當(dāng)紅炸子雞LoRA,是當(dāng)代微調(diào)LLMs的正確姿勢?
大多數(shù)人對于 LLM 的“親密度”,可能最多就是拉個開源的 demo 跑下推理過程,得到個“意料之中”的結(jié)果,然后很諷刺地自 high 一把:WOW~ ...
大型語言模型(LLM)的自定義訓(xùn)練:包含代碼示例的詳細指南
近年來,像 GPT-4 這樣的大型語言模型 (LLM) 因其在自然語言理解和生成方面的驚人能力而受到廣泛關(guān)注。但是,要根據(jù)特定任務(wù)或領(lǐng)域定制LLM,定制...
2023-06-12 標(biāo)簽:GPUpython數(shù)據(jù)集 3.8k 0

? ? 在這篇文章中,我們將盡可能詳細地梳理一個完整的 LLM 訓(xùn)練流程。包括模型預(yù)訓(xùn)練(Pretrain)、Tokenizer 訓(xùn)練、指令微調(diào)(Ins...
2023-06-29 標(biāo)簽:數(shù)據(jù)編碼模型 3.7k 0
近日,Dify全面接入了Perf XCloud,借助Perf XCloud提供的大模型調(diào)用服務(wù),用戶可在Dify中構(gòu)建出更加經(jīng)濟、高效的LLM應(yīng)用。

? 最近幾年,GPT-3、PaLM和GPT-4等LLM刷爆了各種NLP任務(wù),特別是在zero-shot和few-shot方面表現(xiàn)出它們強大的性能。因此,...
2023-05-29 標(biāo)簽:模型數(shù)據(jù)集ChatGPT 3.5k 0

BERT和 GPT-3 等語言模型針對語言任務(wù)進行了預(yù)訓(xùn)練。微調(diào)使它們適應(yīng)特定領(lǐng)域,如營銷、醫(yī)療保健、金融。在本指南中,您將了解 LLM 架構(gòu)、微調(diào)過程...
2024-01-19 標(biāo)簽:神經(jīng)網(wǎng)絡(luò)nlpChatGPT 3.5k 0

我們正在參加全球電子成就獎的評選,歡迎大家?guī)臀覀兺镀薄x謝支持本文轉(zhuǎn)自:騰訊技術(shù)工程作者:royceshao大語言模型LLM的精妙之處在于很好地利用...
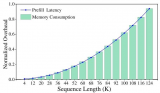
基于DBFP與DB-Attn的算法硬件協(xié)同優(yōu)化方案
本文討論了LLM推理過程對計算資源需求急劇攀升的背景下,現(xiàn)有量化和剪枝技術(shù)、新數(shù)據(jù)格式存在的不足,提出動態(tài)塊浮點數(shù)(DBFP)及其配套算法-硬件協(xié)同框架...
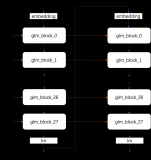
基于MNN在個人設(shè)備上流暢運行大語言模型該如何實現(xiàn)呢?
LLM(大語言模型)因其強大的語言理解能力贏得了眾多用戶的青睞,但LLM龐大規(guī)模的參數(shù)導(dǎo)致其部署條件苛刻;
2023-07-20 標(biāo)簽:轉(zhuǎn)換器存儲器C++語言 3.4k 0
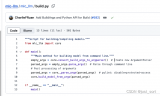
在 MLC-LLM 部署RWKV World系列模型實戰(zhàn)(3B模型Mac M2解碼可達26tokens/s) 中提到要使用mlc-llm部署模型首先需要...
2023-09-26 標(biāo)簽:編譯MLC深度學(xué)習(xí) 3.3k 0
 換一批
換一批
編輯推薦廠商產(chǎn)品技術(shù)軟件/工具OS/語言教程專題
| 電機控制 | DSP | 氮化鎵 | 功率放大器 | ChatGPT | 自動駕駛 | TI | 瑞薩電子 |
| BLDC | PLC | 碳化硅 | 二極管 | OpenAI | 元宇宙 | 安森美 | ADI |
| 無刷電機 | FOC | IGBT | 逆變器 | 文心一言 | 5G | 英飛凌 | 羅姆 |
| 直流電機 | PID | MOSFET | 傳感器 | 人工智能 | 物聯(lián)網(wǎng) | NXP | 賽靈思 |
| 步進電機 | SPWM | 充電樁 | IPM | 機器視覺 | 無人機 | 三菱電機 | ST |
| 伺服電機 | SVPWM | 光伏發(fā)電 | UPS | AR | 智能電網(wǎng) | 國民技術(shù) | Microchip |
| Arduino | BeagleBone | 樹莓派 | STM32 | MSP430 | EFM32 | ARM mbed | EDA |
| 示波器 | LPC | imx8 | PSoC | Altium Designer | Allegro | Mentor | Pads |
| OrCAD | Cadence | AutoCAD | 華秋DFM | Keil | MATLAB | MPLAB | Quartus |
| C++ | Java | Python | JavaScript | node.js | RISC-V | verilog | Tensorflow |
| Android | iOS | linux | RTOS | FreeRTOS | LiteOS | RT-THread | uCOS |
| DuerOS | Brillo | Windows11 | HarmonyOS |
關(guān)注我們的微信

下載發(fā)燒友APP

電子發(fā)燒友觀察

版權(quán)所有 ? 長沙勒克斯教育咨詢有限公司
湖南省長沙市開福區(qū)月湖街道匍園路20號聚恒科技園1棟2301-1房
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023036445號-105-1
工商網(wǎng)監(jiān)
湘ICP備2023036445號-105-1