") DeepSeek R1 MTP在TensorRT-LLM中的實(shí)現(xiàn)與優(yōu)化
DeepSeek R1 MTP在TensorRT-LLM中的實(shí)現(xiàn)與優(yōu)化

TensorRT-LLM 在 NVIDIA Blackwell GPU 上創(chuàng)下了 DeepSeek-R1 推理性能的世界紀(jì)錄,Multi-Token Prediction (MTP) 實(shí)現(xiàn)了大幅提速。我們?cè)谥暗牟┛蚚1]中介紹了 DeepSeek-R1 模型實(shí)現(xiàn)超低推理延遲的關(guān)鍵優(yōu)化措施。本文將深入探討 TensorRT-LLM 中的 MTP 實(shí)現(xiàn)與優(yōu)化。
MTP 在推理中的應(yīng)用
受先前研究工作的啟發(fā),MTP 用于輔助 DeepSeek-V3 的訓(xùn)練,在主模型末尾添加額外的 MTP 模塊,并使用這些模塊預(yù)測(cè)更多 token。這可以將 MTP 的預(yù)測(cè)范圍擴(kuò)展到每個(gè)位置的多個(gè)候選 token,從而提高模型準(zhǔn)確性。這些 MTP 模塊還可用于推理過程中的投機(jī)采樣,以此進(jìn)一步降低生成延遲。本章將介紹適用于 LLM 推理的 MTP 投機(jī)采樣算法。
背景
投機(jī)采樣是一種提高 LLM 推理速度和成本效益的主流技術(shù),其基本原理是生成多個(gè)候選 token,與處理單個(gè) token 相比能更加高效地利用 GPU,特別是在計(jì)算需求較低的解碼階段。投機(jī)采樣技術(shù)通常將此過程分為低成本的 draft 階段和并行驗(yàn)證階段。Draft 階段使用小模型或主模型的一部分層預(yù)測(cè)候選 token。驗(yàn)證階段則使用主模型確定接受多少個(gè)候選 token,這比每次迭代生成一個(gè) token 高效得多。

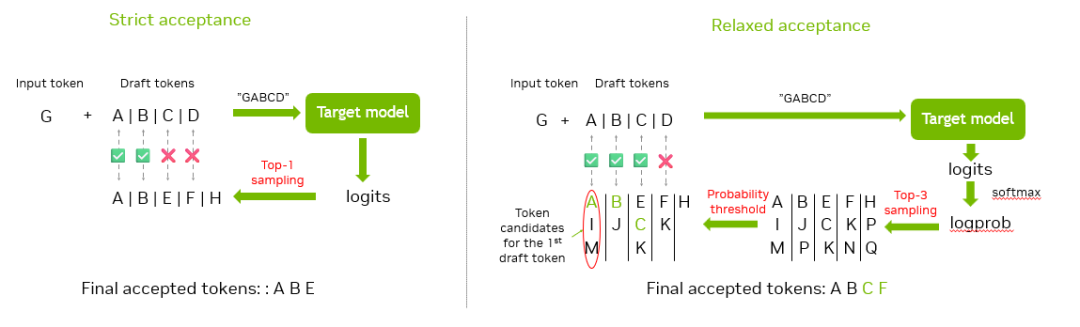
圖 1. 驗(yàn)證示例
圖 1 是一個(gè)有關(guān)如何驗(yàn)證并接受這些候選 token 的示例。假設(shè)共有 5 個(gè)候選 token “ABCDE”,我們將它們拼接到輸入 token “G”,并向主模型輸入總共 6 個(gè) token。采樣后,我們可以得到 6 個(gè)不同的預(yù)期 token,然后將預(yù)期 token 與候選 token 進(jìn)行比較,并接受最長(zhǎng)的前綴匹配 token。此示例中匹配的 token 是 “ABC”。由于 “H” 由主模型預(yù)測(cè),且對(duì)應(yīng)的輸入 token “C” 已被接受,因此 “H” 也將被接受。這樣一來,我們可以在單次迭代中接受四個(gè) token。MTP 也使用此方法驗(yàn)證并接受候選 token。在 MTP 的 draft 階段有兩種 MTP 方法:MTP Vanilla 和 MTP Eagle。它們適用于不同的推理場(chǎng)景。
MTP Vanilla
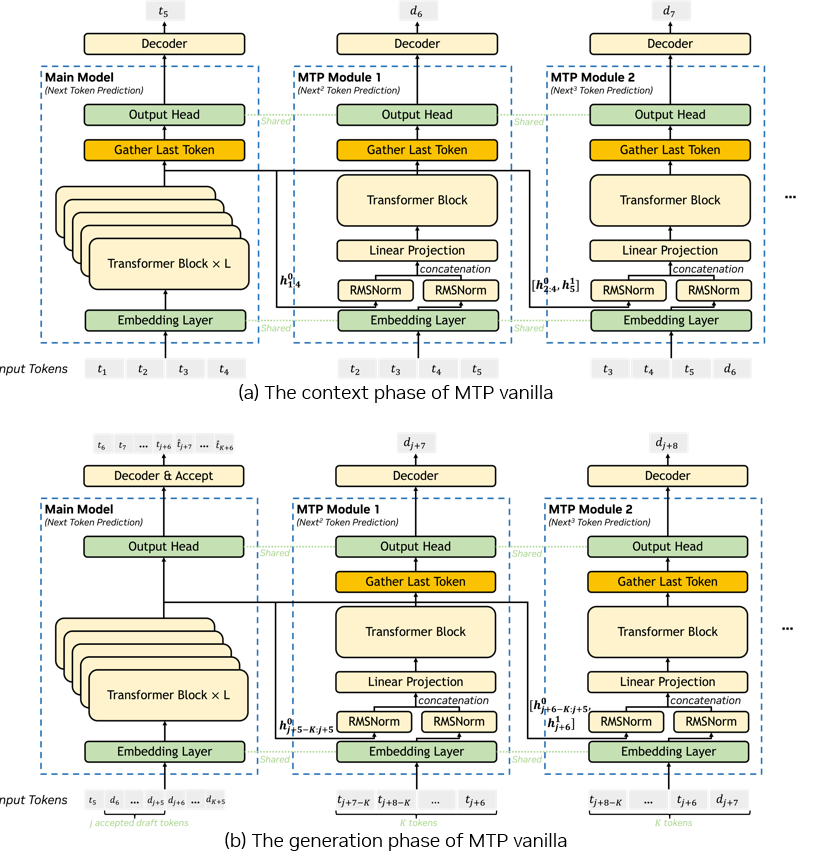
圖2. MTP Vanilla,其中ti為輸入token,di為預(yù)測(cè)的候選token,K為MTP模塊數(shù)量,hin為第n個(gè)MTP模塊的隱藏狀態(tài)。需注意h0表示主模型的隱藏狀態(tài)。
(注:圖改編自DeepSeek V3技術(shù)報(bào)告https://arxiv.org/pdf/2412.19437)
MTP Vanilla 方法與 MTP 訓(xùn)練更為相似,該方法按序調(diào)用不同 MTP 模塊來預(yù)測(cè)多個(gè)候選 token,支持包含多個(gè)不同 MTP 模塊權(quán)重的模型 checkpoint,且每個(gè) MTP 模塊均擁有獨(dú)立的 KV 緩存。
圖2是MTP Vanilla的推理流程。在預(yù)填充階段,假設(shè)總共有四個(gè)輸入token,我們將在主模型前向傳播后獲得輸出tokent5和隱藏狀態(tài)。輸出token將附加到輸入token上,然后移除第一個(gè)token,得到t2到t5作為第一個(gè)MTP模塊的輸入token。主模型的隱藏狀態(tài)將直接作為第一個(gè)MTP模塊的輸入,用于預(yù)測(cè)第一個(gè)候選token。對(duì)于接下來的幾個(gè)MTP模塊,我們將新生成的候選token與對(duì)應(yīng)最后一個(gè)輸入token的隱藏狀態(tài)附加到輸入token和隱藏狀態(tài)中。然后,我們將移除第一個(gè)token以準(zhǔn)備下一個(gè)MTP模塊的輸入。通過這種方式,我們可以盡可能多地保留主模型中的信息,有助于MTP模塊做出更準(zhǔn)確的預(yù)測(cè)。
在生成階段會(huì)有一點(diǎn)差異。預(yù)測(cè)的tokent5和候選token將作為主模型的輸入。在主模型前向傳播后,我們將進(jìn)行驗(yàn)證以獲取被接受的token。此示例假設(shè)j個(gè)候選tokend6~$d_{j+5}$被接受,然后準(zhǔn)備MTP模塊的輸入與預(yù)填充階段不同,我們將此前所有接收token中的最后K個(gè)token及其對(duì)應(yīng)的隱藏狀態(tài)作為第一個(gè)MTP模塊的輸入,該示例中最后一個(gè)被接受的token是t_{j+6},則輸入為t_{j+7-K}~t_{j+6},然后我們可以獲得第一次MTP模塊前向傳播后的第一個(gè)候選token。對(duì)于后續(xù)的MTP模塊,我們可通過與預(yù)填充階段中的MTP模塊類似的方式準(zhǔn)備它們的輸入,所有這些MTP模塊都具有相同的輸入序列長(zhǎng)度。在預(yù)測(cè)完所有新的候選token后,由于驗(yàn)證階段很多token沒有被接收,需要將這些被舍棄的候選token的鍵/值從模型的KV緩存中清除,以確保后續(xù)計(jì)算的正確性。
MTP Eagle
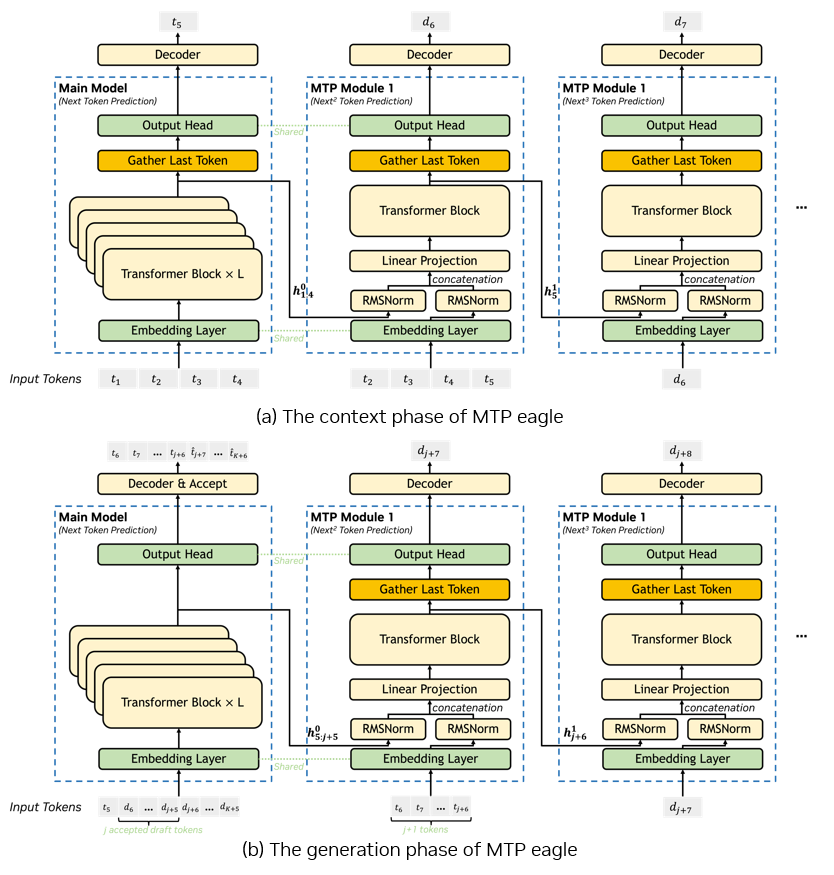
圖 3. 使用與圖 2 相同標(biāo)記的 MTP Eagle
(注:圖改編自 DeepSeek V3 技術(shù)報(bào)告 https://arxiv.org/pdf/2412.19437)
MTP Eagle 可以被視為 Eagle 投機(jī)采樣方法的變體,但目前僅支持鏈?zhǔn)浇獯a。該方法復(fù)用同一個(gè) MTP 模塊并重復(fù)多次來預(yù)測(cè)候選 token,因此 MTP Eagle 用于支持僅包含 1 個(gè) MTP 模塊的模型 checkpoint,官方 DeepSeek-V3 和 DeepSeek-R1 的checkpoint 中僅包含 1 個(gè) MTP 模塊,適用于 MTP Eagle。其與 MTP Vanilla 的另一個(gè)差異在于 KV 緩存,MTP Eagle 方法中的 MTP 模塊在預(yù)測(cè)多個(gè)候選 Token 時(shí)復(fù)用相同的 KV 緩存。
圖 3 是一個(gè) MTP Eagle 示例。在預(yù)填充階段,第一個(gè) MTP 模塊的輸入與 MTP Vanilla 相同,但是在后續(xù) MTP 模塊前向傳播過程中有些不同,首先 MTP Eagle 使用相同的 MTP 模塊預(yù)測(cè)候選 token 并復(fù)用相同的 KV 緩存,其次我們只需輸入 1 個(gè) token 的 token ID 和其隱藏狀態(tài),該 token 是前一個(gè) MTP 模塊預(yù)測(cè)得到的候選 token。通過這種方式,我們只使用 1 個(gè) MTP 模塊就可以預(yù)測(cè)總共 K 個(gè)候選 token。
生成階段的驗(yàn)證過程與 MTP Vanilla 類似。在獲得接受的 token 后,我們將所有被接收的 token 及其對(duì)應(yīng)的隱藏狀態(tài)作為第一個(gè) MTP 模塊前向傳播的輸入,與需要存儲(chǔ)過去 token 和隱藏狀態(tài)的 MTP Vanilla 不同,這種方法實(shí)現(xiàn)起來要簡(jiǎn)單得多。后續(xù) MTP 模塊前向傳播采用與預(yù)填充階段相同的方法來準(zhǔn)備輸入。在預(yù)測(cè)所有候選 token 后,與 MTP Vanilla 類似,需要清除模型 KV 緩存中所有被舍棄 token 的鍵 / 值。
TensorRT-LLM 中的 MTP 實(shí)現(xiàn)方式
基本實(shí)現(xiàn)方式
TensorRT-LLM 提供了兩條不同的 MTP 實(shí)現(xiàn)路徑,一條對(duì)應(yīng) MTP Vanilla,另一條對(duì)應(yīng) MTP Eagle。MTP Eagle 是 DeepSeek-V3 和 DeepSeek-R1 模型的默認(rèn)路徑。
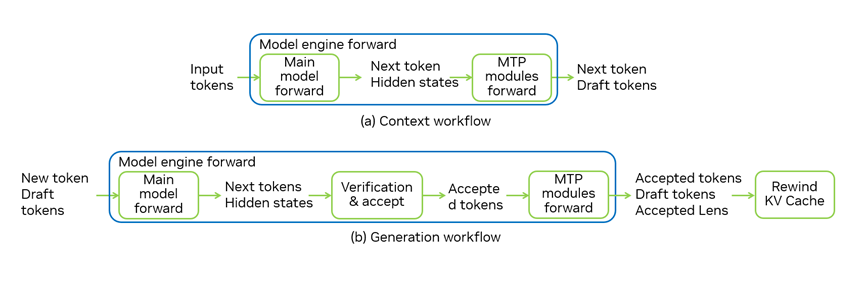
圖 4. TensorRT-LLM 中的 MTP 工作流
圖 4 是 TensorRT-LLM 中的完整 MTP 工作流。兩條路徑共用同一運(yùn)行時(shí)工作流,差別則在于 MTP 模塊的前向傳播。在預(yù)填充階段,輸入中不包含候選 token,TensorRT-LLM 模型引擎從請(qǐng)求中獲取輸入 ID,并將其輸入到模型引擎進(jìn)行前向傳播以獲取下一個(gè) token 和隱藏狀態(tài)。隨后準(zhǔn)備 MTP 模塊輸入,MTP 模塊通過前向傳播來預(yù)測(cè)候選 token。
生成工作流更為復(fù)雜,需要同時(shí)進(jìn)行驗(yàn)證和預(yù)測(cè)候選 token,預(yù)測(cè)的新 token 和候選 token 為主模型的輸入。在主模型前向傳播后,我們可以從輸出的 logits 中采樣并獲取新的 token,然后將它們與輸入的候選 token 進(jìn)行比較,以獲取最終接受的 token 來完成對(duì)候選 token 的驗(yàn)證。我們將使用接受的 token 和隱藏狀態(tài)啟動(dòng)一個(gè)新的 draft 階段,該階段使用 MTP 層預(yù)測(cè)下一輪迭代的新候選 token。最后,我們需要回滾 KV 緩存以清除與被拒絕 token 對(duì)應(yīng)的鍵值對(duì)。
除了回滾 KV 緩存外,所有這些過程均在模型引擎前向傳播中完成。這樣我們可以使用一個(gè)模型引擎支持 MTP 推理,并且 MTP 更容易與其他功能兼容,如 CUDA graph 和重疊調(diào)度器等。啟用 CUDA graph 后,驗(yàn)證和 draft 階段均可在同一個(gè) graph 中運(yùn)行,大幅降低了 CPU 開銷。
MTP 模塊
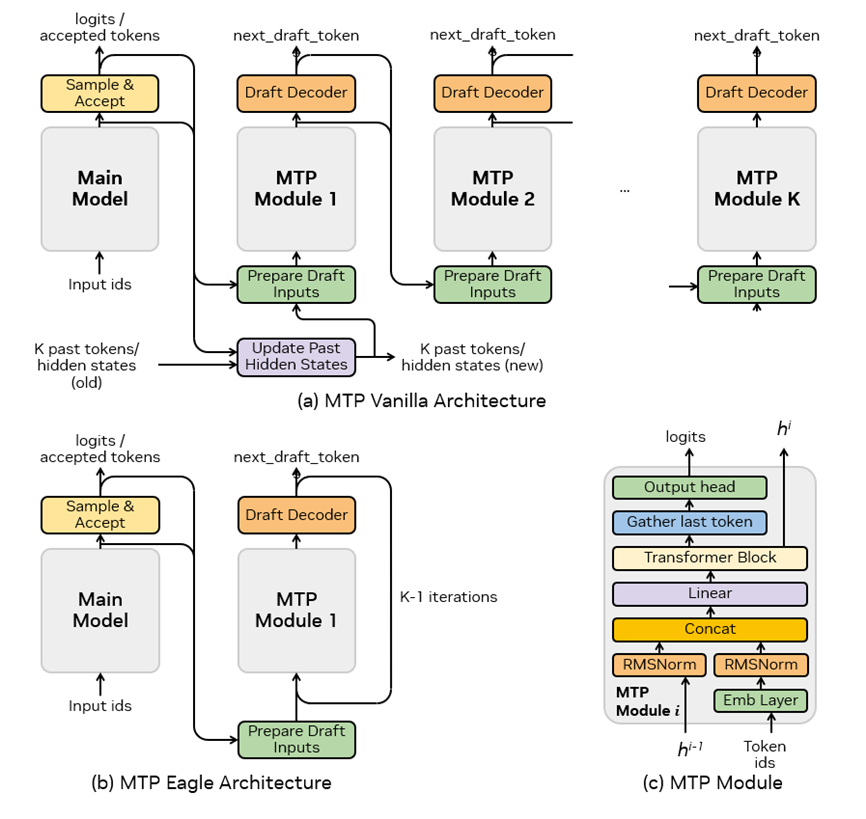
圖 5. MTP 模型架構(gòu)
圖 5 介紹了 MTP Vanilla、MTP Eagle 的基本模型架構(gòu)以及基本 MTP 模塊設(shè)計(jì)。由于 MTP Vanilla 需要 K 個(gè)輸入 token,若接受的 token 數(shù)量少于輸入 token 數(shù)量(即 j
MTP 模塊遵循了 DeepSeek-V3 中的設(shè)計(jì),其中嵌入層和輸出頭與主模型共享,這可以減少 GPU 顯存消耗。
支持 MTP 的注意力機(jī)制
注意力機(jī)制也是支持 MTP 推理的重要組成部分,變化主要體現(xiàn)在生成階段的注意力內(nèi)核上。在普通請(qǐng)求情況下,生成階段僅有一個(gè)輸入 token,但在 MTP 情況下,將有 K+1 個(gè)輸入 token。由于 MTP 按順序預(yù)測(cè)額外的 token,預(yù)測(cè)的候選 token 會(huì)被鏈?zhǔn)竭B接,盡管我們有 MTP Eagle 路徑,但目前只支持基于鏈?zhǔn)降?MTP Eagle。因此,一個(gè)因果掩碼即可滿足注意力內(nèi)核對(duì) MTP 的支持需求。在我們的實(shí)現(xiàn)方式中,TensorRT-LLM 將在 Hopper GPU 上使用FP8 FlashMLA生成內(nèi)核,在 Blackwell 上使用 TensorRT-LLM 定制注意力內(nèi)核來實(shí)現(xiàn)更高的性能。
如何運(yùn)行帶有 MTP 功能的 DeepSeek 模型
如要運(yùn)行帶有 MTP 功能的 DeepSeek-V3 / R1 模型,請(qǐng)使用 examples/llm-api/quickstart_advanced.py 并添加以下選項(xiàng):
如要在有 MTP 功能的情況下進(jìn)行最低延遲性能基準(zhǔn)測(cè)試,請(qǐng)按照本文檔準(zhǔn)備數(shù)據(jù)集,然后按照以下步驟操作:
MTP 優(yōu)化:寬松接受
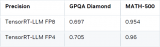
DeepSeek-R1 是一種先輸出一些思考 token,然后為用戶提供實(shí)際輸出的推理模型。其思考過程通常會(huì)消耗大量 token,而思考過程的輸出質(zhì)量對(duì)最終答案的影響有限,因此我們希望采用一種更積極的接受策略——寬松接受以加快思考解碼階段的速度,該策略將權(quán)衡加速幅度與輸出質(zhì)量。從實(shí)驗(yàn)結(jié)果來看,寬松接受對(duì)輸出質(zhì)量的影響不大。
寬松接受
圖 6. 使用 MTP nextn=4 和 top-3 的寬松接受示例。
如圖 1 所示,在之前的驗(yàn)證和接受過程中,我們使用 top-1 從主模型的 logits 中采樣以獲取“預(yù)期” token,此時(shí)僅有一個(gè)選項(xiàng)與候選 token 進(jìn)行比較,我們稱之為“嚴(yán)格接受”。
至于寬松接受,我們首先從 logits 中采樣 top-N 個(gè) token,將有更多候選 token 與輸入的候選 token 進(jìn)行比較。為確保接受的 token 盡可能準(zhǔn)確,我們還引入了一個(gè)概率閾值 delta,我們可通過對(duì) logits 應(yīng)用 softmax 函數(shù)獲得 token 概率。在獲得前 N 個(gè)候選 token 后,我們會(huì)移除概率小于(前 1 個(gè)概率 - delta)的 token。如此一來,我們可獲得多個(gè)候選 token,且所有候選 token 的概率均較高。隨后,我們可以將輸入候選 token 與這些候選 token 進(jìn)行比較,若其中一個(gè)匹配,即可接受該候選 token,從而提高接受率。圖 6 比較了嚴(yán)格接受與寬松接受。
需注意,寬松接受僅在思考階段使用,而嚴(yán)格接受仍在非思考階段使用。目前寬松接受僅支持 DeepSeek-R1 模型。
如何運(yùn)行使用寬松接受策略的
DeepSeek-R1 模型
如要運(yùn)行使用 MTP 寬松接受的 DeepSeek-R1 模型,請(qǐng)使用 examples/llm-api/quickstart_advanced.py 并添加以下選項(xiàng):
如要在使用 MTP 寬松接受策略的情況下進(jìn)行最低延遲性能基準(zhǔn)測(cè)試,請(qǐng)按照本文檔準(zhǔn)備數(shù)據(jù)集,然后按照以下步驟操作:
評(píng)估
通過 MTP 投機(jī)采樣實(shí)現(xiàn)加速
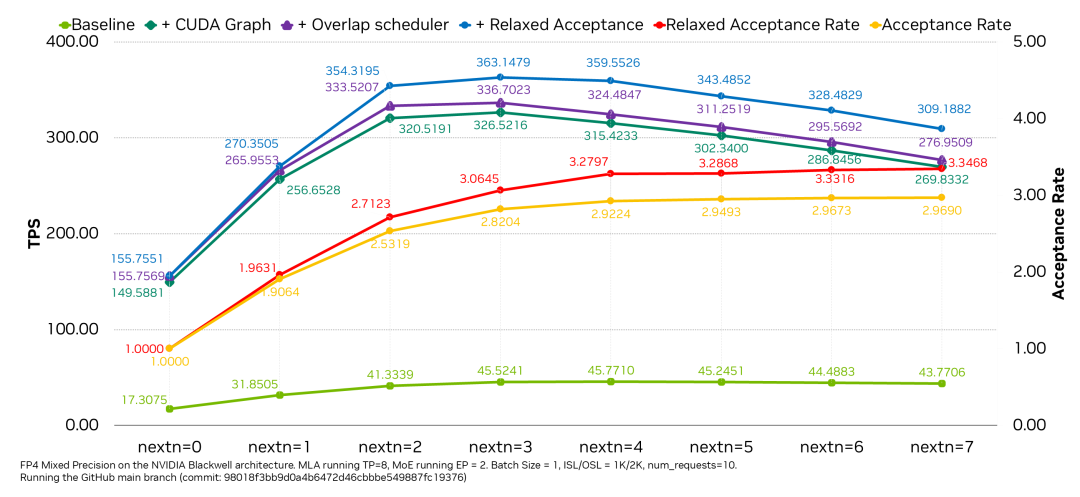
圖 7. DeepSeek-R1-FP4 671B 在不同 MTP next-n 設(shè)置下的最低延遲性能
我們?cè)?GPU 上測(cè)試了 DeepSeek-R1-FP4 模型在不同 MTP next-n 設(shè)置下的最低延遲 (batch size=1) 性能。測(cè)試中設(shè)置 MLA TP=8,MoE EP=2,總共使用 10 個(gè)輸入請(qǐng)求進(jìn)行測(cè)試,輸入序列長(zhǎng)度和輸出序列長(zhǎng)度分別為 1K 和 2K。從圖 7 可以看出,在 8 個(gè) GPU 上 MTP=3 可幫助實(shí)現(xiàn)最佳的最低延遲性能,與基線 nextn=0 相比提速 2.16 倍。而借助寬松接受策略可進(jìn)一步減少最低延遲,提速 2.33 倍。我們還評(píng)估了 CUDA graph 和重疊調(diào)度器的優(yōu)勢(shì)。在此類最低延遲場(chǎng)景中,CUDA graph 可實(shí)現(xiàn)平均提速 7.22 倍,而重疊調(diào)度器則使延遲平均提速 1.03 倍。
使用寬松接受策略時(shí)的準(zhǔn)確性研究
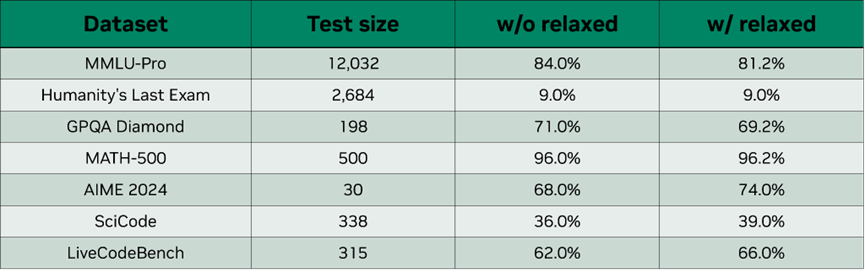
圖 8. 使用寬松接受策略時(shí)的消融結(jié)果,MTP nextn=3、top-10 和 delta=0.6。
我們?cè)诓煌瑪?shù)據(jù)集上驗(yàn)證了寬松接受。圖 8 是 DeepSeek-R1-FP4 模型使用寬松接受策略時(shí)的消融結(jié)果,與嚴(yán)格接受相比,寬松接受對(duì)輸出質(zhì)量的影響不大,精度略微下降,個(gè)別數(shù)據(jù)集上還達(dá)到了更高的精度。
工作展望
樹式投機(jī)采樣支持
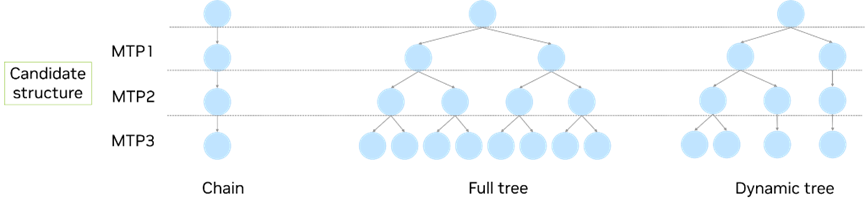
圖 9. 鏈?zhǔn)脚c樹式投機(jī)采樣技術(shù)的比較
TensorRT-LLM PyTorch 后端目前僅支持 MTP Vanilla 和 MTP Eagle 等基于鏈?zhǔn)降耐稒C(jī)采樣。為了提高接受率,Eagle2 和 Eagle3 等此前的先進(jìn)方法廣泛采用樹式投機(jī)采樣技術(shù),TensorRT-LLM 中的 MTP 也可擴(kuò)展以支持樹式投機(jī)采樣技術(shù)。圖 9 比較了鏈?zhǔn)椒椒ㄅc樹式方法,無論是全樹式還是動(dòng)態(tài)樹式方法均有助于擴(kuò)展候選組合,從而提供更多候選 token 供選擇。
Eagle3 支持
Eagle3 同樣是一項(xiàng)重要的技術(shù)。Eagle3 論文的研究結(jié)果表明,使用不同層級(jí)的隱藏狀態(tài)預(yù)測(cè)候選 token 可顯著提高接受率。由于 TensorRT-LLM 已支持 Eagle-3,未來我們還計(jì)劃訓(xùn)練一個(gè) Eagle3 head,結(jié)合 DeepSeek-V3 / R1+Eagle3 以實(shí)現(xiàn)更好的加速。
致謝
支持和優(yōu)化 TensorRT-LLM 中的 MTP 是一項(xiàng)了不起的跨團(tuán)隊(duì)合作成果。我們謹(jǐn)向所有為此做出貢獻(xiàn)的人士致以誠(chéng)摯感謝,該項(xiàng)目涉及多個(gè)技術(shù)層面的系統(tǒng)與算法協(xié)同設(shè)計(jì)方法,包括內(nèi)核優(yōu)化、運(yùn)行時(shí)增強(qiáng)、算法改進(jìn)以及性能測(cè)量與分析等。特別感謝 DeepSeek 團(tuán)隊(duì)開發(fā)了這套 MTP 方法,為本文奠定了基礎(chǔ)。
作者
張國(guó)銘
NVIDIA 性能架構(gòu)師,目前主要從事大模型推理優(yōu)化。
李繁榮
NVIDIA Compute Arch 部門高級(jí)架構(gòu)師,目前主要從事大模型推理優(yōu)化。
cd examples/llm-api
python quickstart_advanced.py--model_dir
YOUR_DATA_PATH=
cd examples/llm-api
python quickstart_advanced.py--model_dir
YOUR_DATA_PATH=
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5663瀏覽量
109957 -
模型
+關(guān)注
關(guān)注
1文章
3778瀏覽量
52187 -
LLM
+關(guān)注
關(guān)注
1文章
348瀏覽量
1367 -
DeepSeek
+關(guān)注
關(guān)注
2文章
837瀏覽量
3337
原文標(biāo)題:DeepSeek R1 MTP 在 TensorRT-LLM 中的實(shí)現(xiàn)與優(yōu)化
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
NVIDIA Blackwell GPU優(yōu)化DeepSeek-R1性能 打破DeepSeek-R1在最小延遲場(chǎng)景中的性能紀(jì)錄

TensorRT-LLM初探(一)運(yùn)行l(wèi)lama
使用NVIDIA Triton和TensorRT-LLM部署TTS應(yīng)用的最佳實(shí)踐

如何在魔搭社區(qū)使用TensorRT-LLM加速優(yōu)化Qwen3系列模型推理部署
如何在NVIDIA Blackwell GPU上優(yōu)化DeepSeek R1吞吐量
TensorRT-LLM中的分離式服務(wù)

了解DeepSeek-V3 和 DeepSeek-R1兩個(gè)大模型的不同定位和應(yīng)用選擇
現(xiàn)已公開發(fā)布!歡迎使用 NVIDIA TensorRT-LLM 優(yōu)化大語言模型推理

魔搭社區(qū)借助NVIDIA TensorRT-LLM提升LLM推理效率
TensorRT-LLM低精度推理優(yōu)化

NVIDIA TensorRT-LLM Roadmap現(xiàn)已在GitHub上公開發(fā)布

解鎖NVIDIA TensorRT-LLM的卓越性能
在NVIDIA TensorRT-LLM中啟用ReDrafter的一些變化

云天勵(lì)飛上線DeepSeek R1系列模型

TensorRT-LLM的大規(guī)模專家并行架構(gòu)設(shè)計(jì)




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論