") 中國(guó)研究人員提出StructGPT,提高LLM對(duì)結(jié)構(gòu)化數(shù)據(jù)的零樣本推理能力
中國(guó)研究人員提出StructGPT,提高LLM對(duì)結(jié)構(gòu)化數(shù)據(jù)的零樣本推理能力

大型語言模型 (LLM) 最近在自然語言處理 (NLP) 方面取得了重大進(jìn)展。現(xiàn)有研究表明,LLM) 具有很強(qiáng)的零樣本和少樣本能力,可以借助專門創(chuàng)建的提示完成各種任務(wù),而無需針對(duì)特定任務(wù)進(jìn)行微調(diào)。盡管它們很有效,但根據(jù)目前的研究,LLM 可能會(huì)產(chǎn)生與事實(shí)知識(shí)不符的不真實(shí)信息,并且無法掌握特定領(lǐng)域或?qū)崟r(shí)的專業(yè)知識(shí)。這些問題可以通過在LLM中添加外部知識(shí)源來修復(fù)錯(cuò)誤的生成來直接解決。
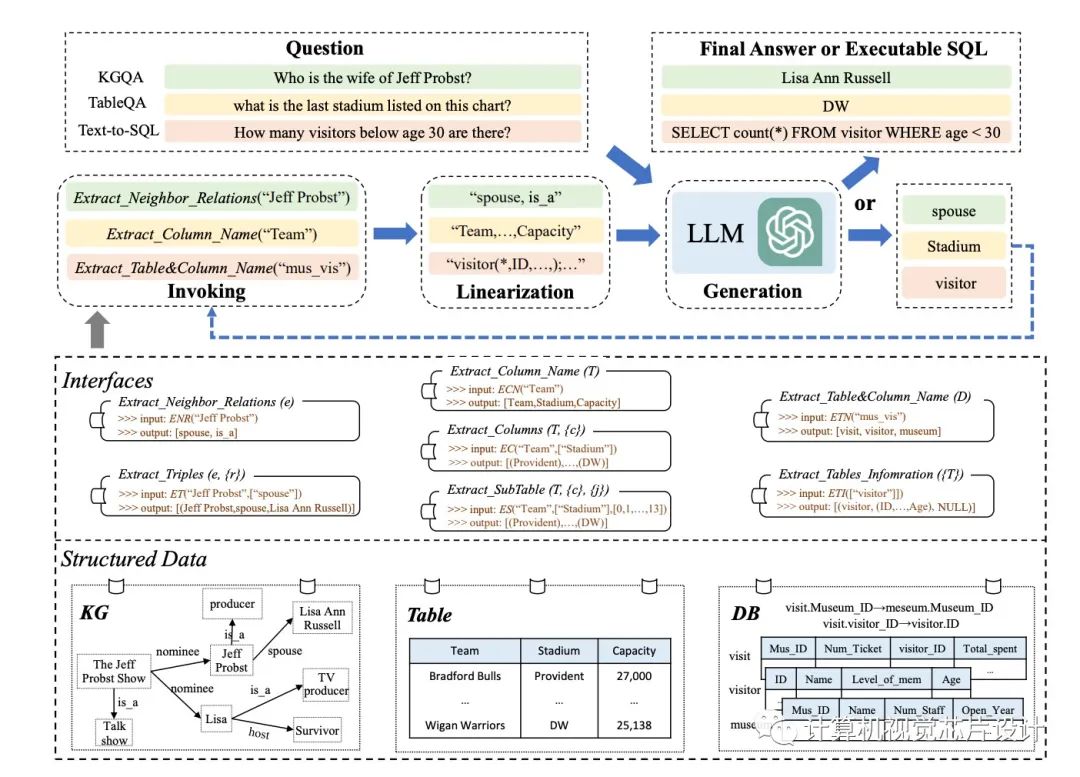
結(jié)構(gòu)化數(shù)據(jù),如數(shù)據(jù)庫(kù)和知識(shí)圖譜,已被常規(guī)用于在各種資源中攜帶 LLM 所需的知識(shí)。但是,由于結(jié)構(gòu)化數(shù)據(jù)使用 LLM 在預(yù)訓(xùn)練期間未接觸過的獨(dú)特?cái)?shù)據(jù)格式或模式,因此他們可能需要幫助才能理解它們。與純文本相反,結(jié)構(gòu)化數(shù)據(jù)以一致的方式排列并遵循特定的數(shù)據(jù)模型。數(shù)據(jù)表按行排列為列索引記錄,而知識(shí)圖 (KG) 經(jīng)常組織為描述頭尾實(shí)體之間關(guān)系的事實(shí)三元組。
盡管結(jié)構(gòu)化數(shù)據(jù)的體量往往非常巨大,但不可能容納輸入提示中的所有數(shù)據(jù)記錄(例如,ChatGPT 的最大上下文長(zhǎng)度為 4096)。將結(jié)構(gòu)化數(shù)據(jù)線性化為 LLM 可以輕松掌握的語句是解決此問題的簡(jiǎn)單方法。工具操作技術(shù)激勵(lì)他們?cè)鰪?qiáng) LLM 解決上述困難的能力。他們策略背后的基本思想是使用專門的接口來更改結(jié)構(gòu)化數(shù)據(jù)記錄(例如,通過提取表的列)。在這些接口的幫助下,他們可以更精確地定位完成特定活動(dòng)所需的證據(jù),并成功地限制數(shù)據(jù)記錄的搜索范圍。
來自中國(guó)人民大學(xué)、北京市大數(shù)據(jù)管理與分析方法重點(diǎn)實(shí)驗(yàn)室和中國(guó)電子科技大學(xué)的研究人員在這項(xiàng)研究中著重于為某些任務(wù)設(shè)計(jì)合適的接口,并將它們用于 LLM 的推理,這些接口是應(yīng)用界面增強(qiáng)方法需要解決的兩個(gè)主要問題。以這種方式,LLM 可以根據(jù)從界面收集的證據(jù)做出決定。為此,他們?cè)诒狙芯恐刑峁┝艘环N稱為 StructGPT 的迭代閱讀然后推理 (IRR) 方法,用于解決基于結(jié)構(gòu)化數(shù)據(jù)的任務(wù)。他們的方法考慮了完成各種活動(dòng)的兩個(gè)關(guān)鍵職責(zé):收集相關(guān)數(shù)據(jù)(閱讀)和假設(shè)正確的反應(yīng)或?yàn)橄乱徊叫袆?dòng)制定策略(推理)。
據(jù)他們所知,這是第一項(xiàng)著眼于如何使用單一范式幫助 LLM 對(duì)各種形式的結(jié)構(gòu)化數(shù)據(jù)(例如表、KG 和 DB)進(jìn)行推理的研究。從根本上說,他們將 LLM 的閱讀和推理兩個(gè)過程分開:他們使用結(jié)構(gòu)化數(shù)據(jù)接口來完成精確、有效的數(shù)據(jù)訪問和過濾,并依靠他們的推理能力來確定下一步的行動(dòng)或查詢的答案。
對(duì)于外部接口,他們特別建議調(diào)用線性化生成過程,以幫助 LLM 理解結(jié)構(gòu)化數(shù)據(jù)并做出決策。通過使用提供的接口重復(fù)此過程,他們可能會(huì)逐漸接近對(duì)查詢的期望響應(yīng)。
他們對(duì)各種任務(wù)(例如基于知識(shí)圖譜的問答、基于表的問答和基于數(shù)據(jù)庫(kù)的文本到 SQL)進(jìn)行了全面試驗(yàn),以評(píng)估其技術(shù)的有效性。八個(gè)數(shù)據(jù)集的實(shí)驗(yàn)結(jié)果表明,他們建議的方法可能會(huì)顯著提高 ChatGPT 在結(jié)構(gòu)化數(shù)據(jù)上的推理性能,甚至達(dá)到與全數(shù)據(jù)監(jiān)督調(diào)優(yōu)方法競(jìng)爭(zhēng)的水平。
? KGQA。他們的方法使 KGQA 挑戰(zhàn)的 WebQSP 上的 Hits@1 增加了 11.4%。借助他們的方法,ChatGPT 在多跳 KGQA 數(shù)據(jù)集(例如 MetaQA-2hop 和 MetaQA-3hop)中的性能可能分別提高了 62.9% 和 37.0%。
? 質(zhì)量保證表。在 TableQA 挑戰(zhàn)中,與直接使用 ChatGPT 相比,他們的方法在 WTQ 和 WikiSQL 中將標(biāo)注準(zhǔn)確度提高了大約 3% 到 5%。在 TabFact 中,他們的方法將表格事實(shí)驗(yàn)證的準(zhǔn)確性提高了 4.2%。
? 文本到SQL。在 Text-to-SQL 挑戰(zhàn)中,與直接使用 ChatGPT 相比,他們的方法將三個(gè)數(shù)據(jù)集的執(zhí)行準(zhǔn)確性提高了約 4%。
作者已經(jīng)發(fā)布了 Spider 和 TabFact 的代碼,可以幫助理解 StructGPT 的框架,整個(gè)代碼庫(kù)尚未發(fā)布。
審核編輯 :李倩
-
數(shù)據(jù)管理
+關(guān)注
關(guān)注
1文章
343瀏覽量
20618 -
自然語言處理
+關(guān)注
關(guān)注
1文章
630瀏覽量
14703 -
知識(shí)圖譜
+關(guān)注
關(guān)注
2文章
132瀏覽量
8342 -
LLM
+關(guān)注
關(guān)注
1文章
349瀏覽量
1381
原文標(biāo)題:中國(guó)研究人員提出StructGPT,提高LLM對(duì)結(jié)構(gòu)化數(shù)據(jù)的零樣本推理能力
文章出處:【微信號(hào):計(jì)算機(jī)視覺芯片設(shè)計(jì),微信公眾號(hào):計(jì)算機(jī)視覺芯片設(shè)計(jì)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
結(jié)構(gòu)化布線系統(tǒng)有哪些難題
泰克儀器助力研究人員首次通過太赫茲復(fù)用器實(shí)現(xiàn)超高速數(shù)據(jù)傳輸
TrustZone結(jié)構(gòu)化消息是什么?
結(jié)構(gòu)化設(shè)計(jì)分為哪幾部分?結(jié)構(gòu)化設(shè)計(jì)的要求有哪些
白光LED結(jié)構(gòu)化涂層制備及其應(yīng)用研究
融合零樣本學(xué)習(xí)和小樣本學(xué)習(xí)的弱監(jiān)督學(xué)習(xí)方法綜述

形狀感知零樣本語義分割
一個(gè)通用的自適應(yīng)prompt方法,突破了零樣本學(xué)習(xí)的瓶頸

基準(zhǔn)數(shù)據(jù)集(CORR2CAUSE)如何測(cè)試大語言模型(LLM)的純因果推理能力
什么是零樣本學(xué)習(xí)?為什么要搞零樣本學(xué)習(xí)?
跨語言提示:改進(jìn)跨語言零樣本思維推理

什么是LLM?LLM的工作原理和結(jié)構(gòu)
LLM大模型推理加速的關(guān)鍵技術(shù)
使用ReMEmbR實(shí)現(xiàn)機(jī)器人推理與行動(dòng)能力
詳解 LLM 推理模型的現(xiàn)狀




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論