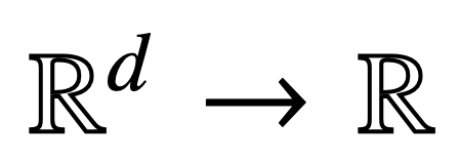
為什么 transformer 性能這么好?它給眾多大語言模型帶來的上下文學習 (In-Context Learning) 能力是從何而來?在人工智能領域里,transformer 已成為深度學習中
2023-09-25 12:05:37 2223
2223 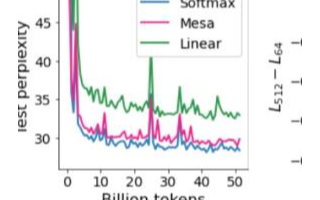
在之前的內容中,我們已經介紹過流水線并行、數據并行(DP,DDP和ZeRO)。 今天我們將要介紹最重要,也是目前基于Transformer做大模型預訓練最基本的并行范式:來自NVIDIA的張量模型
2023-05-31 14:38:234295 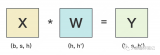
基于transformer模型的,模型結構主要有兩大類:encoder-decoder(代表模型是T5)和decoder-only,具體的,decoder-only結
2023-07-10 09:13:5714746 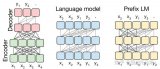
Transformer 本質上是一個 Encoder-Decoder 架構。因此中間部分的 Transformer 可以分為兩個部分:編碼組件和解碼組件。
2023-11-17 10:34:521022 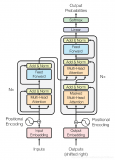
Transformer模型在強化學習領域的應用主要是應用于策略學習和值函數近似。強化學習是指讓機器在與環境互動的過程中,通過試錯來學習最優的行為策略。
2024-02-20 09:55:3524823 
Transformer 模型在 2017 年由 Vaswani 等人在論文《Attentionis All You Need》中首次提出。其設計初衷是為了解決自然語言處理(Nature
2025-02-06 10:21:456017 
[首發于智駕最前沿微信公眾號]近年來,隨著ChatGPT、Claude、文心一言等大語言模型在生成文本、對話交互等領域的驚艷表現,“Transformer架構是否正在取代傳統深度學習”這一話題一直被
2025-08-13 09:15:594010 
for Language Understanding》,BERT模型橫空出世,并橫掃NLP領域11項任務的最佳成績。而在BERT中發揮重要作用的結構就是Transformer,之后又相繼出現XLNET、roBERT等模型擊
2023-12-25 08:36:006285 
ABBYY PDF Transformer+有三種不同類型的 PDF 文檔。僅包含頁面圖像的文檔不可搜索,其包含的文本也不可編輯。包含文本層的文檔可以搜索,包含在這些文檔中的文本也可進行復制。本文
2017-11-13 18:11:34
類似于C語言中的結構體,結構體中又包含數組,如何快速解析出來呢
2013-09-11 15:15:38
體系結構標準定義了網絡互聯的七層框架(物理層、數據鏈路層、網絡層、傳輸層、會話層、表示層和應用層),即OSI開放系統互連參考模型。這里根據筆者的理解以及相關資料的查詢,覺得這個OSI通信與筆者...
2021-07-30 06:08:26
PROFIBUS協議模型與ISO/OSI協議模型的關系 PROFIBUS協議結構
2009-11-17 10:33:24
深入探討關于RF放大器模型結構,看完秒懂!
2021-02-22 06:14:52
模型(逐字節),我也得到了信息傳遞字符串。這意味著我可以總是使用模型(逐字節)代替文件I/O類型的讀/寫傳輸模型?或者最后一個模型比字節模型有更多的應用程序?此外,緩沖隊列傳輸模型是最復雜的理解模型。有人能幫助我理解這個模型的實際應用嗎?非常感謝你。
2020-04-23 13:56:48
1、YOLOv5 網絡結構解析 YOLOv5針對不同大小(n, s, m, l, x)的網絡整體架構都是一樣的,只不過會在每個子模塊中采用不同的深度和寬度, 分別應對yaml文件中
2022-10-31 16:30:17
在畫路時,需要用到電流互感器,需要選擇哪個模型呢?一下這些transformer 分別是什么意思?那些在我們設計電路時候比較常用?一些變壓器的表述中“Transformer (Coupled Inductor Model)”的耦合電感模型是什么意思?
2014-12-01 16:32:10
收集海量的文本數據作為訓練材料。這些數據集不僅包括語法結構的學習,還包括對語言的深層次理解,如文化背景、語境含義和情感色彩等。
自監督學習:模型采用自監督學習策略,在大量無標簽文本數據上學
2024-08-02 11:03:41
地選擇適合的模型。不同的模型具有不同的特點和優勢。在客服領域,常用的模型包括循環神經網絡(RNN)、長短時記憶網絡(LSTM)、門控循環單元(GRU)、Transformer等,以及基于這些架構的預
2024-12-17 16:53:12
全面剖析大語言模型的核心技術與基礎知識。首先,概述自然語言的基本表示,這是理解大語言模型技術的前提。接著,詳細介紹自然語言處理預訓練的經典結構Transformer,以及其工作原理,為構建大語言
2024-05-05 12:17:03
Transformer架構,利用自注意力機制對文本進行編碼,通過預訓練、有監督微調和強化學習等階段,不斷提升性能,展現出強大的語言理解和生成能力。
大語言模型的涌現能力,是指隨著模型規模的增長,展現出
2024-05-04 23:55:44
通過超越語言應用(如音樂、語音、圖像和視頻生成)對該領域產生重大影響。在這篇文章中,我們將努力深入Reformer模型并試著去理解一些可視化方面的指南。準備好了嗎?為什么是Transformer?在
2022-11-02 15:19:41
樹模型的一些理解
2020-05-22 09:40:45
解鎖
我理解的是基于深度學習,需要訓練各種數據知識最后生成自己的的語言理解和能力的交互模型。
對于常說的RNN是處理短序列的數據時表現出色,耳真正厲害的是Transformer,此框架被推出后直接
2024-05-12 23:57:34
在模型預測控制中,把狀態空間模型轉換成MPC狀態空間模型,結果得到一個矩陣,如何去理解這個矩陣代表的意義?
2019-03-20 16:09:03
何為變量?變量一般可以細分為如下圖:本節重點為了讓大家理解內存模型的“棧”,暫時不考慮“靜態變量” 的情況,并約定如下:“全局變量”僅僅默認為“普通全局變量”;“局部變量”僅僅默認為“普...
2021-12-22 07:30:05
怎樣去搭建一種電力電子仿真模型?如何對雙母線結構模型進行仿真?
2021-09-24 10:28:46
在安裝ABBYY PDF Transformer+時會讓您選擇界面語言。此語言將用于所有消息、對話框、按鈕和菜單項。在特殊情況下,您可能需要在安裝完成后更改界面語言以適應需求,方法其實很簡單,本文
2017-10-11 16:13:38
【追蹤嫌犯的利器】定位技術原理解析(4)
2020-05-04 12:20:20
`手機通信原理解析:第 1 章 無線通信原理第2 章 移動通信系統第3 章 移動通信系統的多址接入技術第4 章 移動通信系統的語音編碼第5 章 GSM移動通信系統的數字
2011-12-14 14:31:20
做題之前要先理解一下按鍵的內部結構。矩陣鍵盤中有兩個I/O端口,一個作為輸入,一個作為輸出。當按鍵按下時,兩個端口相連導通(我是這樣認為的),當作為輸入的I/O端口輸入高電平時,輸出就是高電平,反之就是低電平。矩陣鍵盤掃描原理...
2022-01-12 06:25:28
【理解】線結構光成像模型
2020-06-09 16:48:46
【鋰知道】鋰電池基本原理解析:充電及放電機制電池充電最重要的就是這三步:第一步:判斷電壓
2021-09-15 06:47:08
單片機的結構原理解析
一、單片機的外部結構拿到一塊芯片,想要使用它,首先必須要知道怎樣連線,我們用的一塊稱之為 89C51 的芯片,下面我們就看一
2010-04-09 14:53:11 41
41 MPOA的模型結構,MPOA的模型結構是什么?
(1)基本組成
MPOA采用了LANE、NHRP、交換路由器(Switched Router)三種互補的
2010-04-07 13:27:02678 高速緩沖存儲器部件結構及原理解析
高速緩存 CACHE用途 設置在 CPU 和 主存儲器之間,完成高速與 CPU交換信息,盡量避免 CPU不必要地多次直
2010-04-15 11:18:505036 組合邏輯控制器組成結構及工作原理解析
按照控制信號產生的方式不同,控制器分為微程序控制器和組合邏輯控制器兩類
微程序控制器是
2010-04-15 11:20:5113270 虛擬存儲器部件原理解析
2010-04-15 14:25:203561 觸摸屏的應用與工作原理解析
2017-02-08 02:13:1738 爪極發電機因其特殊的轉子結構導致磁場空間分布復雜,通常需要建立三維有限元模型對其進行計算分析。而三維有限元方法計算費時,且不便于分析發電機結構及電磁參數對磁場和電磁力的影響,因此提出一種氣隙磁場
2018-02-10 10:02:162 我們已經了解了模型的主要部分,接下來我們看一下各種向量或張量(譯注:張量概念是矢量概念的推廣,可以簡單理解矢量是一階張量、矩陣是二階張量。)是怎樣在模型的不同部分中,將輸入轉化為輸出的。
2019-01-10 15:15:106878 
剛剛,Google Brain 高級研究科學家 Barret Zoph 發帖表示,他們設計了一個名叫「Switch Transformer」的簡化稀疏架構,可以將語言模型的參數量擴展至 1.6 萬億
2021-01-13 16:50:494200 基于Transformer結構的各類語言模型(Bert基于其encoder,Gpt-2基于其decoder)早已經在各類NLP任務上大放異彩,面對讓人眼花繚亂的transformer堆疊方式,你是否
2021-03-08 10:27:064948 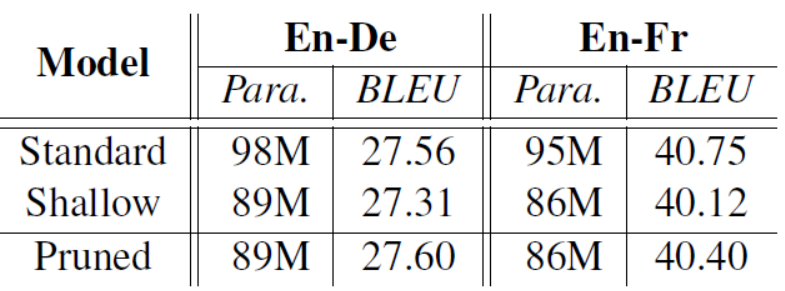
機器閱讀理解是一項針對給定文本和特定問題自動生成或抽取相應答案的問答任務,該任務是評估計機系統對自然語言理解程度的重要任務之一。相比于傳統的閱讀理解任務,多文檔閱讀理解需要計算模型具備更高的推理
2021-03-16 11:41:3810 問句理解是模型將自然語言冋句轉換成SαL的重要基礎。目前多數利用深度學習的模型僅是通過數據庫結構,未結合數據庫內容充分理解問句生成SQL查詢。在 SQLOVA模型的基礎上,提出一種基于表結構和內容
2021-03-22 11:09:2914 隨著Transformer在視覺中的崛起,Transformer在多模態中應用也是合情合理的事情,甚至以后可能會有更多的類似的paper。
2021-03-25 09:29:5911785 
引言 Transformer是近年來非常流行的處理序列到序列問題的架構,其self-attention機制允許了長距離的詞直接聯系,可以使模型更容易學習序列的長距離依賴。由于其優良的可并行性以及可觀
2021-04-01 16:07:2813603 
)是Facebook研究團隊巧妙地利用了Transformer 架構開發的一個目標檢測模型。在這篇文章中,我將通過分析DETR架構的內部工作方式來幫助提供一些關于它的含義。下面,我將解釋一些結構,但是
2021-04-25 10:45:493198 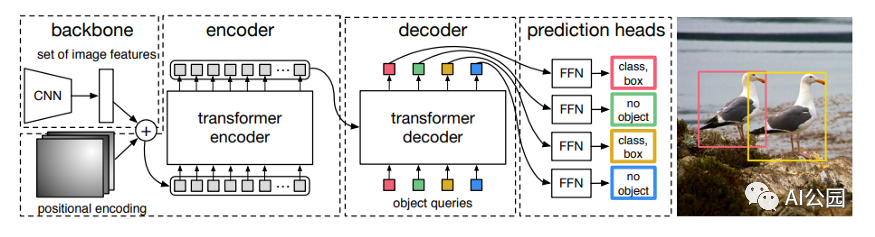
用了Transformer 架構開發的一個目標檢測模型。在這篇文章中,我將通過分析DETR架構的內部工作方式來幫助提供一些關于它的直覺。 下面,我將解釋一些結構,但是如果你只是想了解如何使用模型,可以直接跳到代碼部分
2021-06-10 16:04:392863 
【導讀】GMP 模型是讓 go 語言輕量快速高效的重要調度模型,本文從 GMP 源碼出發直觀地解析了這一模型。 這篇文章就來看看 golang 的調度模型-GPM 模型的源碼結構。 Go 版本
2021-07-06 11:55:042843 的25個Transformers模型 總結 ACL 2021中的25個Transformers模型 NLP中的層次結構Hi-Transformer: Hierarchical Interactive Transformer for Efficient and Effective Long Docume
2021-09-01 09:27:437482 
NVIDIA Megatron 是一個基于 PyTorch 的框架,用于訓練基于 Transformer 架構的巨型語言模型。本系列文章將詳細介紹Megatron的設計和實踐,探索這一框架如何助力
2021-10-11 16:46:054364 
NVIDIA Megatron 是一個基于 PyTorch 的框架,用于訓練基于 Transformer 架構的巨型語言模型。本系列文章將詳細介紹Megatron的設計和實踐,探索這一框架如何助力
2021-10-20 09:25:433517 Microsoft 的目標是,通過結合使用 Azure 與 NVIDIA GPU 和 Triton 推理軟件,率先將一系列強大的 AI Transformer 模型投入生產用途。
2022-03-28 09:43:381848 Microsoft 的目標是,通過結合使用 Azure 與 NVIDIA GPU 和 Triton 推理軟件,率先將一系列強大的 AI Transformer 模型投入生產用途。
2022-04-02 13:04:212347 所以我們為此文章寫了篇注解文檔,并給出了一行行實現的Transformer的代碼。本文檔刪除了原文的一些章節并進行了重新排序,并在整個文章中加入了相應的注解。此外,本文檔以Jupyter
2022-06-20 14:26:504694 史密斯圓圖和阻抗匹配原理解析
2022-11-02 20:16:232717 什么是晶振 晶振工作原理解析
2022-12-30 17:13:575336 
Transformer的主要優點是它可以并行地處理輸入序列中的所有位置,因此在訓練和推理時都有著很好的效率。此外,Transformer沒有使用循環結構,因此它不會受長序列的影響,并且在處理長序列時不會出現梯度消失或爆炸的問題。
2023-03-08 15:36:001568 Thinking Like Transformers 這篇論文中提出了 transformer 類的計算框架,這個框架直接計算和模仿 Transformer 計算。使用 RASP 編程語言,使每個程序編譯成一個特殊的 Transformer。
2023-03-08 09:39:001510 結構化剪枝是一種重要的模型壓縮算法,它通過移除神經網絡中冗余的結構來減少參數量,從而降低模型推理的時間、空間代價。在過去幾年中,結構化剪枝技術已經被廣泛應用于各種神經網絡的加速,覆蓋了ResNet、VGG、Transformer等流行架構。
2023-03-29 11:23:526189 。 2)Transformer模型沒有使用傳統的CNN和RNN結構,其完全是由Attention機制組成,其中Self-Attention(自注意力)是Transformer的核心。 3)OpenAI的GPT模型和Google的BERT模型雖然都是基于Transformer所構建,但GPT模型僅使用了解
2023-03-29 16:57:061 Transformer是當前各種大模型所采用的主要結構,而ChatGPT的火爆讓人們逐漸意識到人工智能有著更高的上限,并可以在計算機視覺領域發揮出巨大潛能。相比于在云端用GPU部署Transformer大模型,在邊緣側、端側部署Transformer最大的挑戰則來自功耗
2023-05-30 11:04:021794 
本文首先詳細介紹Transformer的基本結構,然后再通過GPT、BERT、MT-DNN以及GPT-2等基于Transformer的知名應用工作的介紹并附上GitHub鏈接,看看Transformer是如何在各個著名的模型中大顯神威的。
2023-06-08 09:56:223188 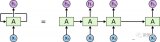
與基于 RNN 的編碼器-解碼器模型類似,基于 transformer 的編碼器-解碼器模型由一個編碼器和一個解碼器組成,且其編碼器和解碼器均由 殘差注意力模塊 (residual attention blocks) 堆疊而成。
2023-06-11 14:17:343129 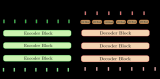
本文旨在更好地理解基于 Transformer 的大型語言模型(LLM)的內部機制,以提高它們的可靠性和可解釋性。 隨著大型語言模型(LLM)在使用和部署方面的不斷增加,打開黑箱并了解它們的內部
2023-06-25 15:08:492367 
預訓練的2D圖像或語言Transformer:作為基礎Transformer模型,具有豐富的特征表示能力。作者選擇了先進的2D Transformer模型作為基礎模型,例如Vision Transformers (ViTs) 或者語言模型(如BERT)。
2023-07-03 10:59:431592 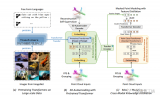
,并能做出屬于自己的 SAM 模型,那么接下這篇 Transformer-Based 的 Segmentation Survey 是不容錯過!近期,南洋理工大學和上海人工智能實驗室幾位研究人員寫了一篇
2023-07-05 10:18:391996 
理解Transformer背后的理論基礎,比如自注意力機制(self-attention), 位置編碼(positional embedding),目標查詢(object query)等等,網上的資料比較雜亂,不夠系統,難以通過自學做到深入理解并融會貫通。
2023-07-09 14:35:39936 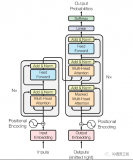
?動機&背景 Transformer 模型在各種自然語言任務中取得了顯著的成果,但內存和計算資源的瓶頸阻礙了其實用化部署。低秩近似和結構化剪枝是緩解這一瓶頸的主流方法。然而,作者通過分析發現,結構
2023-07-17 10:50:433517 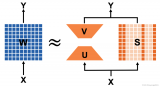
理解Transformer背后的理論基礎,比如自注意力機制(self-attention), 位置編碼(positional embedding),目標查詢(object query)等等,網上的資料比較雜亂,不夠系統,難以通過自學做到深入理解并融會貫通。
2023-07-18 12:54:131036 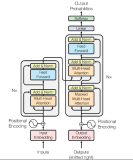
接著 大模型部署框架 FastLLM 簡要解析 這篇文章首先梳理了一下FastLLM的調用鏈和關鍵的數據結構,然后解析了 FastLLM 的一些實現細節和CPU/GPU后端實現采用的優化技巧。
2023-07-27 10:48:274523 
掌握基于Transformer的目標檢測算法的思路和創新點,一些Transformer論文涉及的新概念比較多,話術沒有那么通俗易懂,讀完論文仍然不理解算法的細節部分。
2023-08-16 10:51:261016 
BEV人工智能transformer? 人工智能Transformer技術是一種自然語言處理領域的重要技術,廣泛應用于自然語言理解、機器翻譯、文本分類等任務中。它通過深度學習算法從大規模語料庫中自動
2023-08-22 15:59:281461 理解Transformer背后的理論基礎,比如自注意力機制(self-attention), 位置編碼(positional embedding),目標查詢(object query)等等,網上的資料比較雜亂,不夠系統,難以通過自學做到深入理解并融會貫通。
2023-08-24 11:19:41635 
這些embedding可以使用谷歌Word2vec (單詞的矢量表示) 找到。在我們的數值示例中,我們將假設每個單詞的embedding向量填充有 (0和1) 之間的隨機值。
2023-09-06 14:44:172172 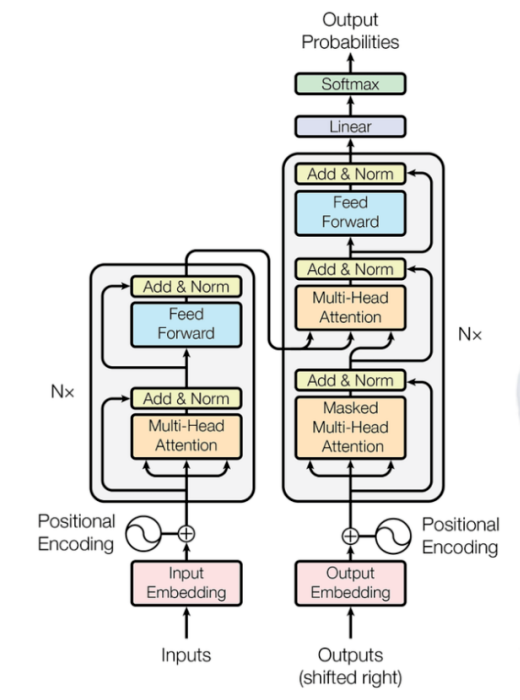
寫在前面:本文將對 Nvidia BERT 推理解決方案 Faster Transformer 源碼進行深度剖析,詳細分析作者的優化意圖,并對源碼中的加速技巧進行介紹,希望對讀者有所幫助。本文源碼
2023-09-08 10:20:331956 
集成電路(IC),一種將數以千計的晶體管、電阻和電容等微小元件,集成在一小塊半導體材料(通常是硅)上的微型結構,它的出現徹底改變了電子行業的發展。為了更深入理解集成電路,讓我們從它的基本結構與分類入手進行解析。
2023-09-27 09:11:095173 
最后是在ADE20K val上的LeaderBoard,通過榜單也可以看出,在榜單的前幾名中,Transformer結構依舊占據是當前的主力軍。
2023-12-07 09:39:151450 
基于Transformer架構的大型模型在人工智能領域中發揮著日益重要的作用,特別是在自然語言處理(NLP)和計算機視覺(CV)領域。
2024-02-22 16:27:191415 
近期,Hochreiter在arXiv平臺發表論文,推出了一款新型的XLSTM(擴展LSTM)架構,有效克服了傳統LSTM互聯網結構“僅能按時間順序處理信息”的局限性,有望挑戰當前熱門的Transformer架構。
2024-05-13 10:31:441458 自2022年,ChatGPT發布之后,大語言模型(LargeLanguageModel),簡稱LLM掀起了一波狂潮。作為學習理解LLM的開始,先來整體理解一下大語言模型。一、發展歷史大語言模型的發展
2024-06-04 08:27:472712 
Transformer模型自其問世以來,在自然語言處理(NLP)領域取得了巨大的成功,并成為了許多先進模型(如BERT、GPT等)的基礎。本文將深入解讀如何使用PyTorch框架搭建Transformer模型,包括模型的結構、訓練過程、關鍵組件以及實現細節。
2024-07-02 11:41:453272 隨著人工智能技術的飛速發展,語音識別和語音生成作為人機交互的重要組成部分,正逐漸滲透到我們生活的各個方面。而Transformer模型,自其誕生以來,憑借其獨特的自注意力機制和并行計算能力,在
2024-07-03 18:24:422618 基于Transformer架構的預訓練語言模型,它可以生成連貫、自然的文本。ChatGPT使用GPT模型作為基礎,通過微調和訓練來實現對話生成和理解。 以下是一
2024-07-09 09:55:492494 任務,隨后迅速擴展到其他NLP任務中,如文本生成、語言理解、問答系統等。本文將詳細介紹Transformer語言模型的原理、特點、優勢以及實現過程。
2024-07-10 11:48:453835 近日,國內領先的GPU創新企業摩爾線程宣布了一項重大技術突破——正式開源其自主研發的音頻理解大模型MooER(摩耳)。這一舉動標志著我國在音頻處理與理解領域邁出了堅實的一步,特別是在基于國產硬件的AI模型研發上取得了顯著成就。
2024-08-27 15:24:591247 感知、理解和預測方面表現得更為強大,徹底終結了2D直視圖+CNN時代。BEV+Transformer通過鳥瞰視角與Transformer模型的結合,顯著提升了自動駕駛
2024-11-07 11:19:202276 
盡管名為 Transformer,但它們不是電視銀幕上的變形金剛,也不是電線桿上垃圾桶大小的變壓器。
2024-11-20 09:27:161540 
如果想在 AI 領域引領一輪新浪潮,就需要使用到 Transformer。
2024-11-20 09:28:242504 
原子是物質的基本單位,由原子核和電子組成。原子結構模型的發展經歷了幾個階段,每個階段都有其特點和局限性。 一、原子結構模型的演變 道爾頓模型(1803年) 英國化學家約翰·道爾頓提出了原子論,認為
2024-12-17 15:22:287243 的舊圖像模型,也不能運行CNN、RNN或LSTM。 但對于transformer來說,Sohu是有史以來最快的芯片。 借助Llama 70B每秒超過50萬個token的吞吐量,Sohu可以讓您構建在GPU上無法實現的產品
2025-01-06 09:13:101756 
的詳細解析: 1. 核心組成與工作原理 視覺編碼器 :提取圖像特征,常用CNN(如ResNet)或視覺Transformer(ViT)。 語言模型 :處理文本輸入/輸出,如GPT、BERT等,部分模型
2025-03-17 15:32:407974 
編碼器是Transformer體系結構的基本組件。編碼器的主要功能是將輸入標記轉換為上下文表示。與早期獨立處理token的模型不同,Transformer編碼器根據整個序列捕獲每個token的上下文。
2025-06-10 14:27:47922 
狀態的主觀理解。隨后,該模型再將理解結果交由行為規劃子模塊去執行,使得端到端過程具有一定結構化邏輯,從而兼顧可解釋性與泛化能力。
2025-08-03 11:03:001197 和使用AI。 大模型 Transformer vs. Mixture of Experts 混合專家 (MoE) 是一種流行的架構,它使用不同的“專家”來改進 Transformer 模型。 下圖解釋了
2025-10-21 09:48:13516 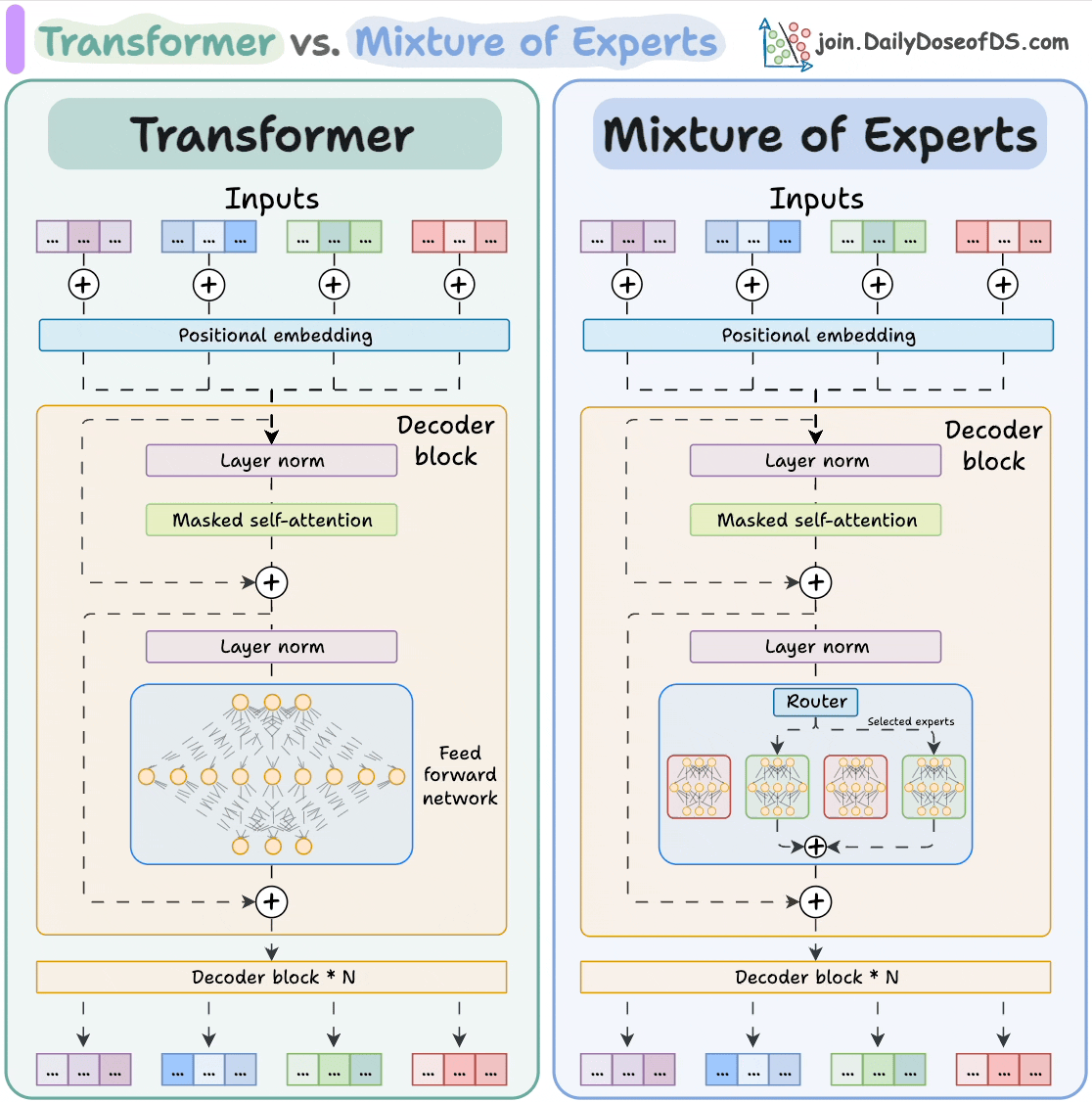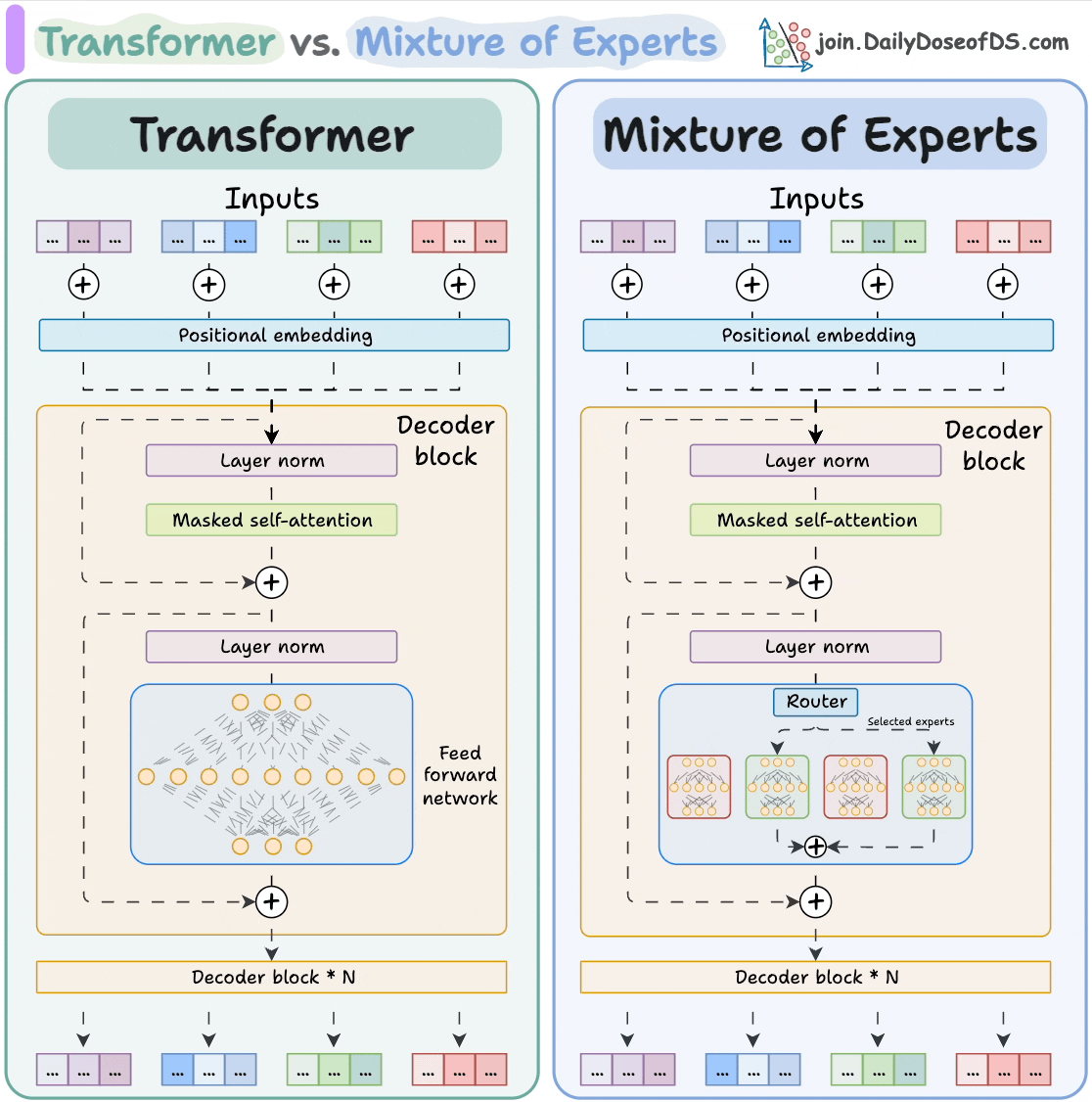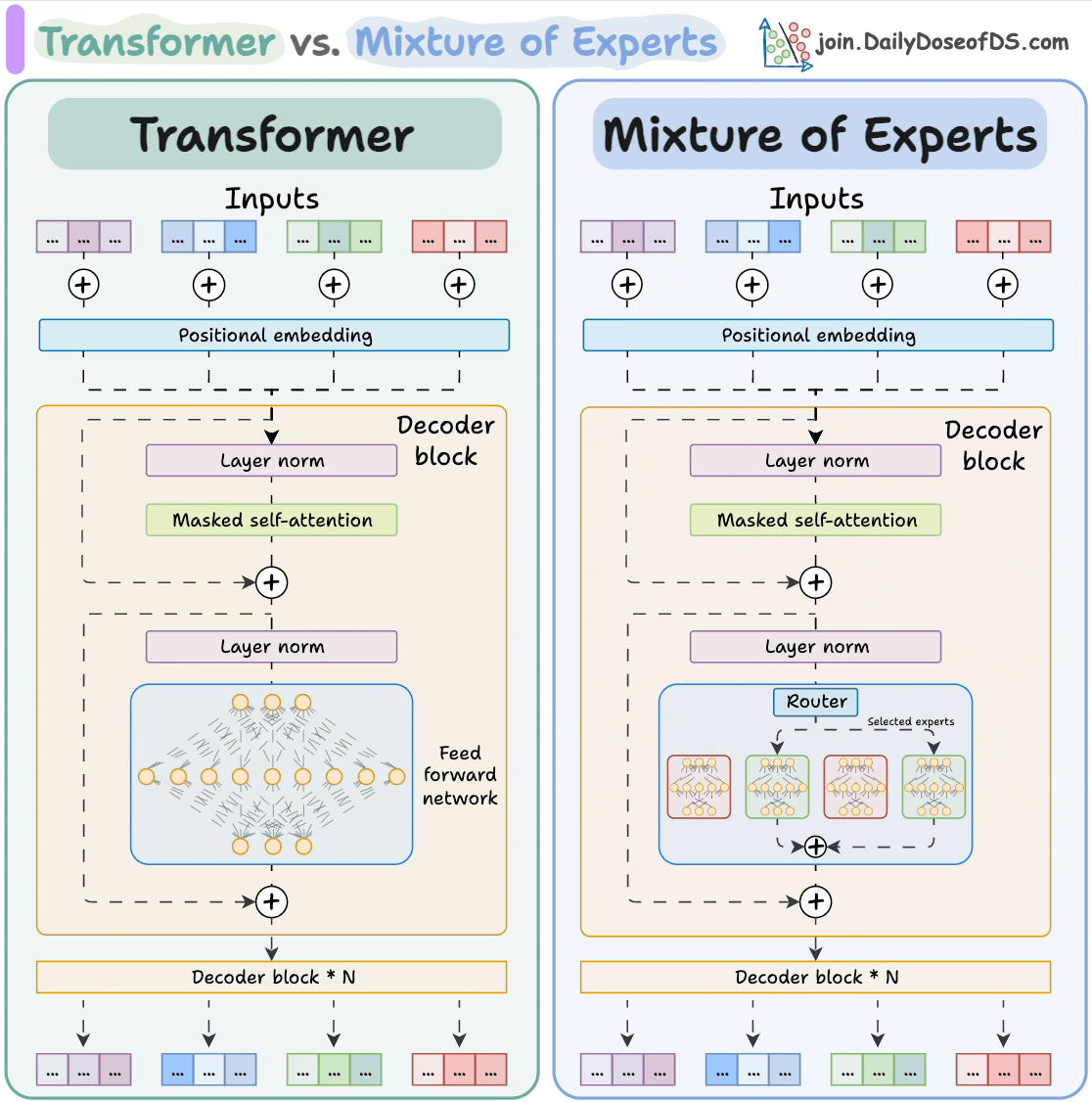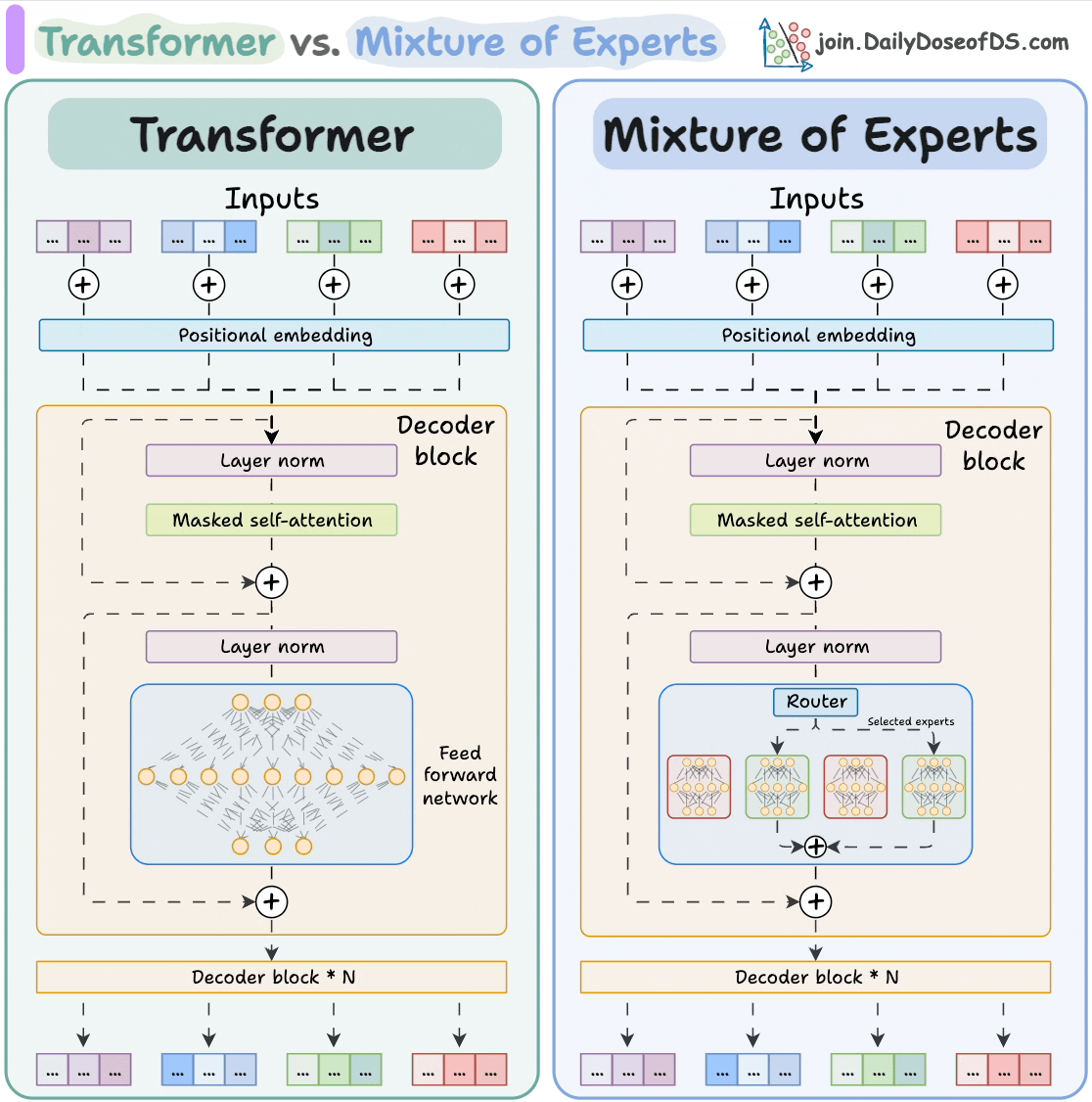
 電子發燒友App
電子發燒友App



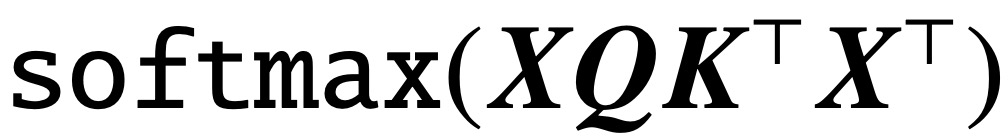

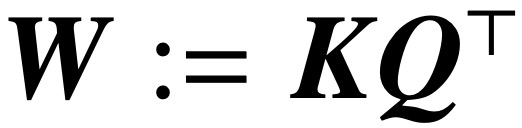

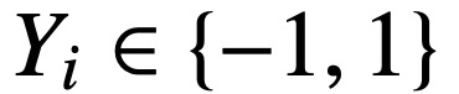
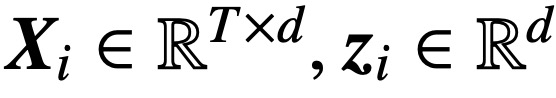

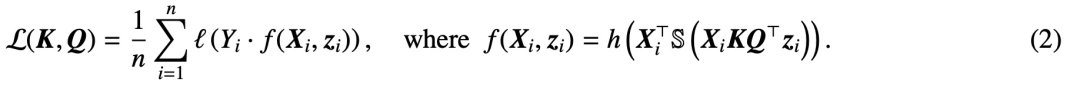
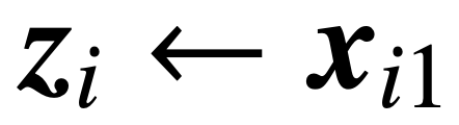

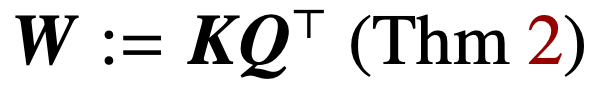
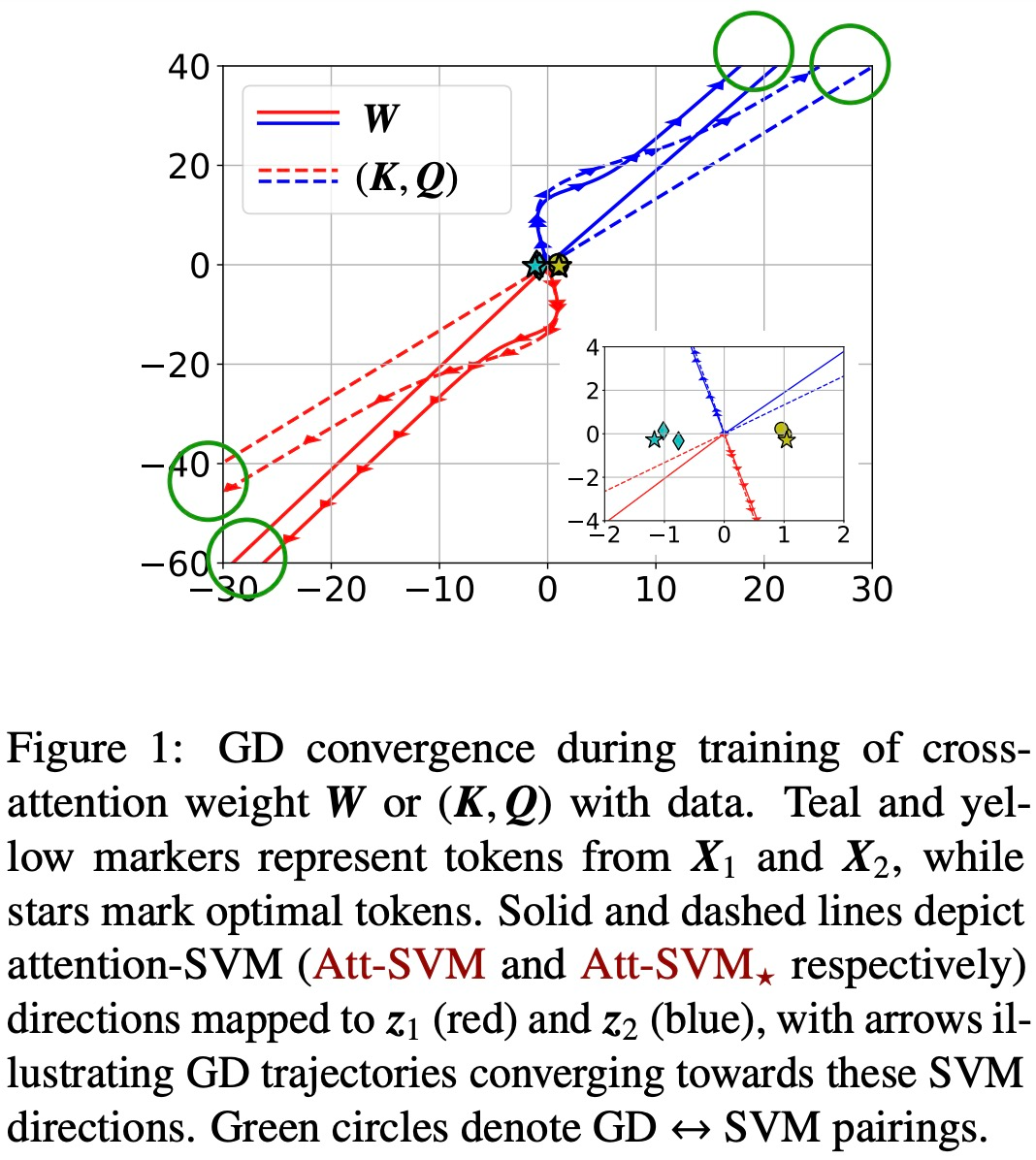
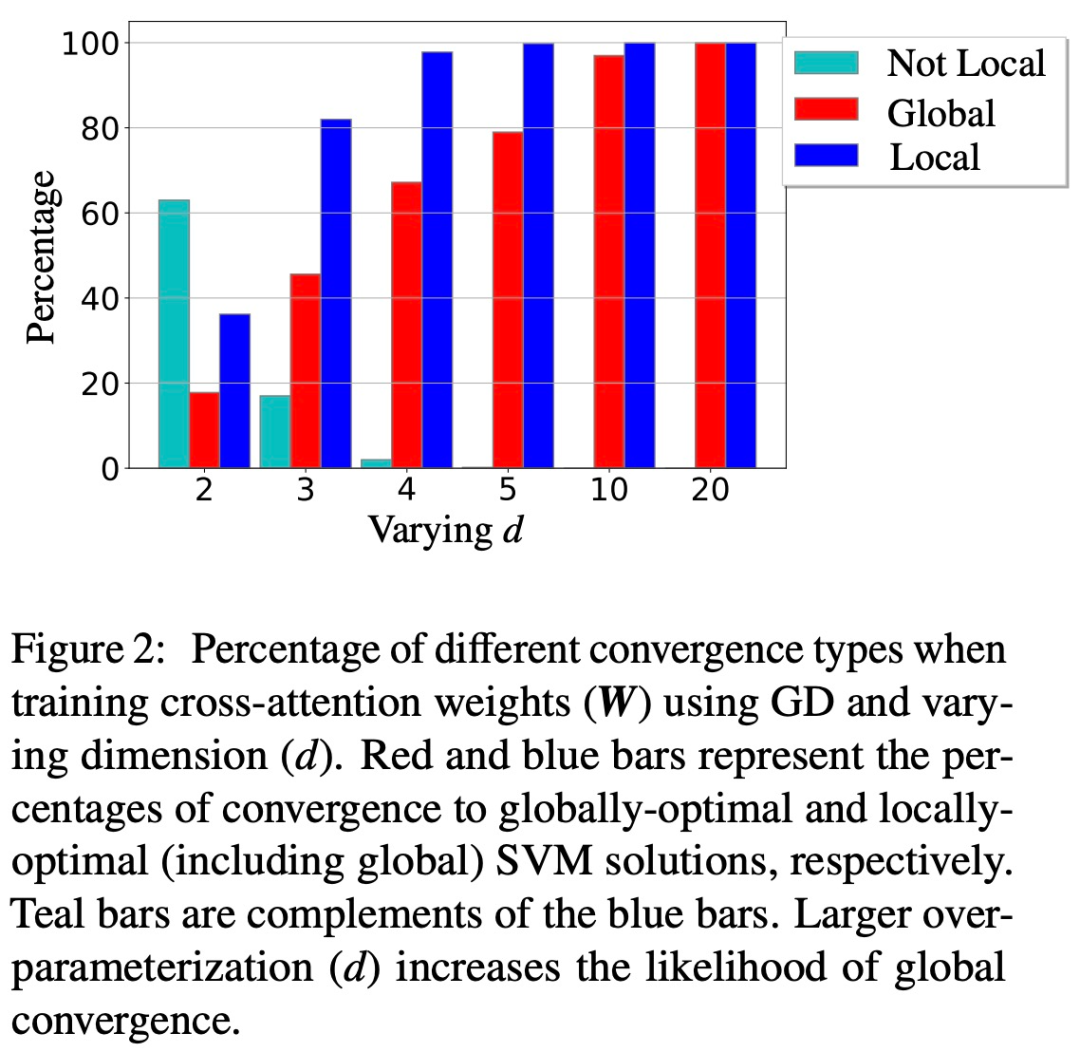






 工商網監
工商網監
評論