 為什么transformer性能這么好?Transformer的上下文學習能力是哪來的?
為什么transformer性能這么好?Transformer的上下文學習能力是哪來的?

有理論基礎,我們就可以進行深度優化了。為什么 transformer 性能這么好?它給眾多大語言模型帶來的上下文學習 (In-Context Learning) 能力是從何而來?在人工智能領域里,transformer 已成為深度學習中的主導模型,但人們對于它卓越性能的理論基礎卻一直研究不足。 最近,來自 Google AI、蘇黎世聯邦理工學院、Google DeepMind 研究人員的新研究嘗試為我們揭開謎底。在新研究中,他們對 transformer 進行了逆向工程,尋找到了一些優化方法。論文《Uncovering mesa-optimization algorithms in Transformers》:
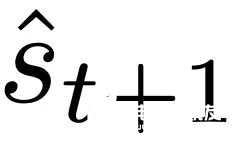 。 該研究的貢獻包括:
。 該研究的貢獻包括:
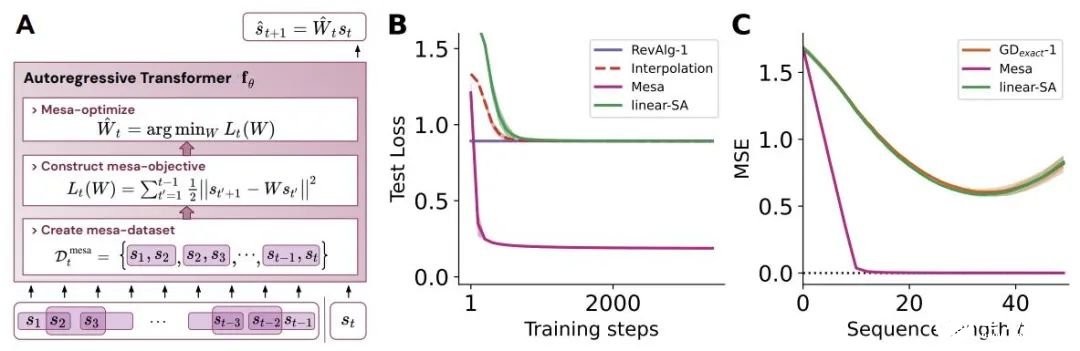
- 概括了 von Oswald 等人的理論,并展示了從理論上,Transformers 是如何通過使用基于梯度的方法優化內部構建的目標來自回歸預測序列下一個元素的。
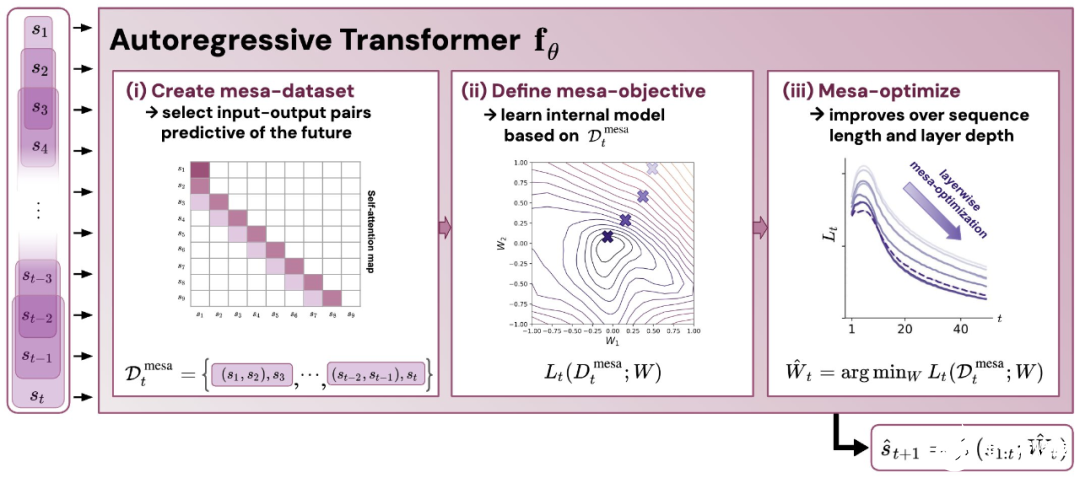
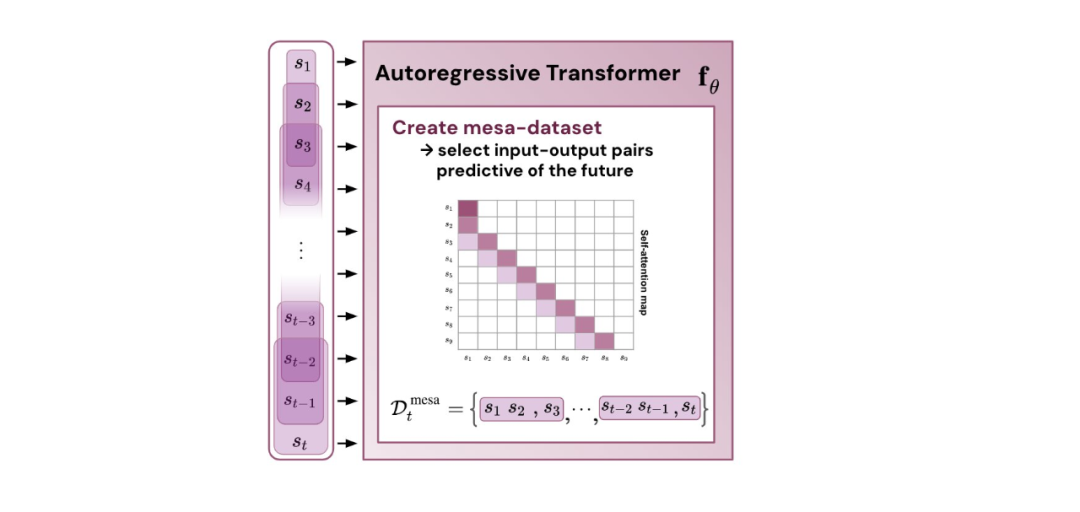
- 通過實驗對在簡單序列建模任務上訓練的 Transformer 進行了逆向工程,并發現強有力的證據表明它們的前向傳遞實現了兩步算法:(i) 早期自注意力層通過分組和復制標記構建內部訓練數據集,因此隱式地構建內部訓練數據集。定義內部目標函數,(ii) 更深層次優化這些目標以生成預測。
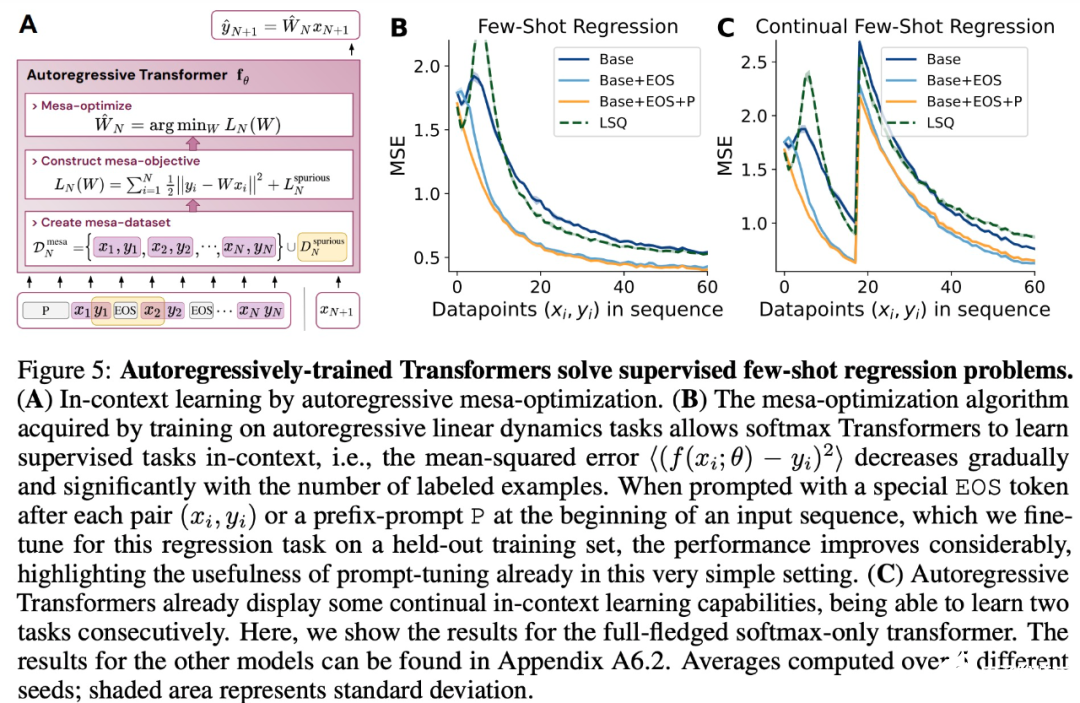
- 與 LLM 類似,實驗表明簡單的自回歸訓練模型也可以成為上下文學習者,而即時調整對于改善 LLM 的上下文學習至關重要,也可以提高特定環境中的表現。
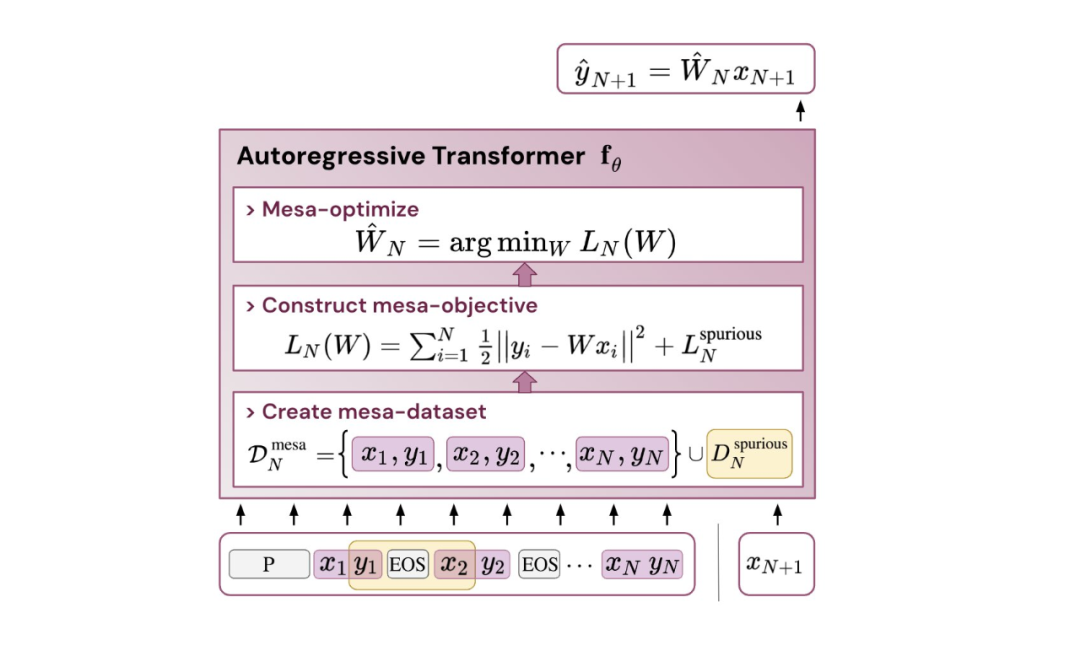
- 受發現注意力層試圖隱式優化內部目標函數的啟發,作者引入了 mesa 層,這是一種新型注意力層,可以有效地解決最小二乘優化問題,而不是僅采取單個梯度步驟來實現最優。實驗證明單個 mesa 層在簡單的順序任務上優于深度線性和 softmax 自注意力 Transformer,同時提供更多的可解釋性。

- 在初步的語言建模實驗后發現,用 mesa 層替換標準的自注意力層獲得了有希望的結果,證明了該層具有強大的上下文學習能力。
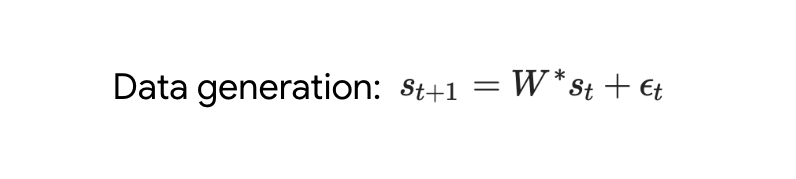
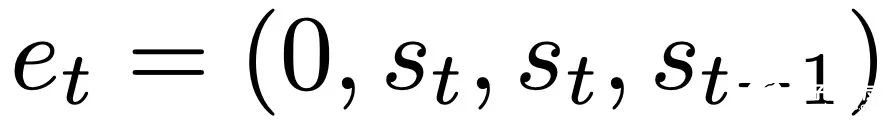 ,這對應于選擇 W_0 = 0。
,這對應于選擇 W_0 = 0。
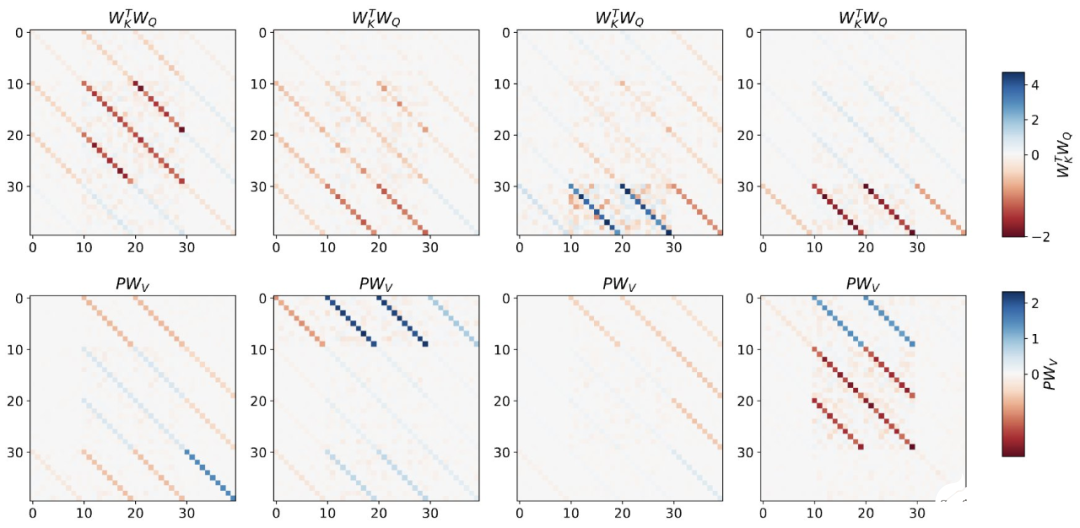
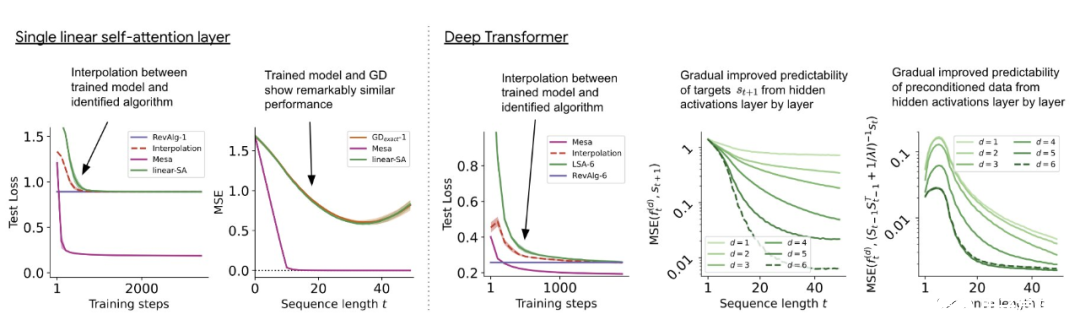
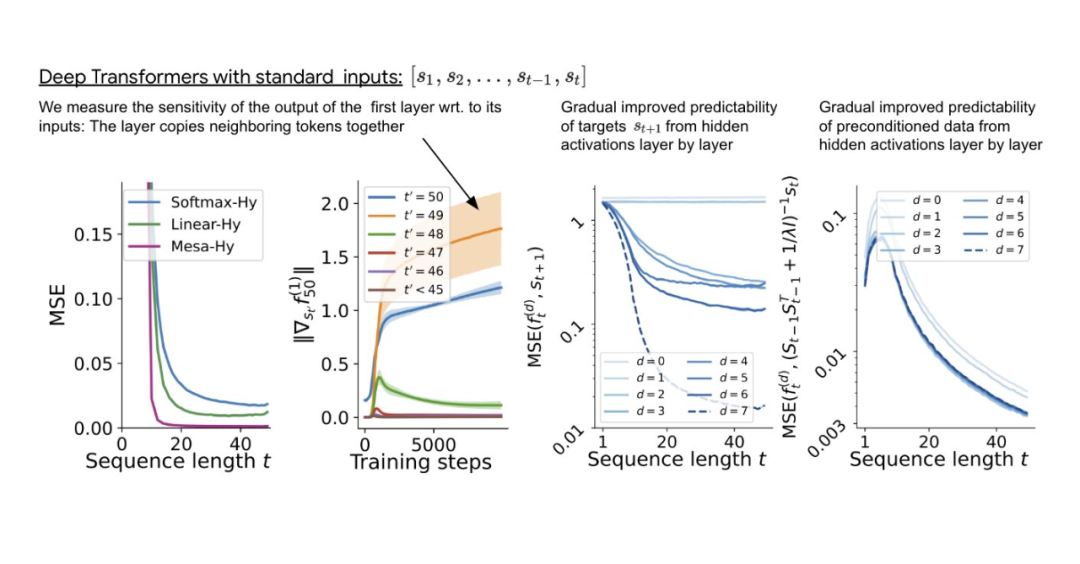
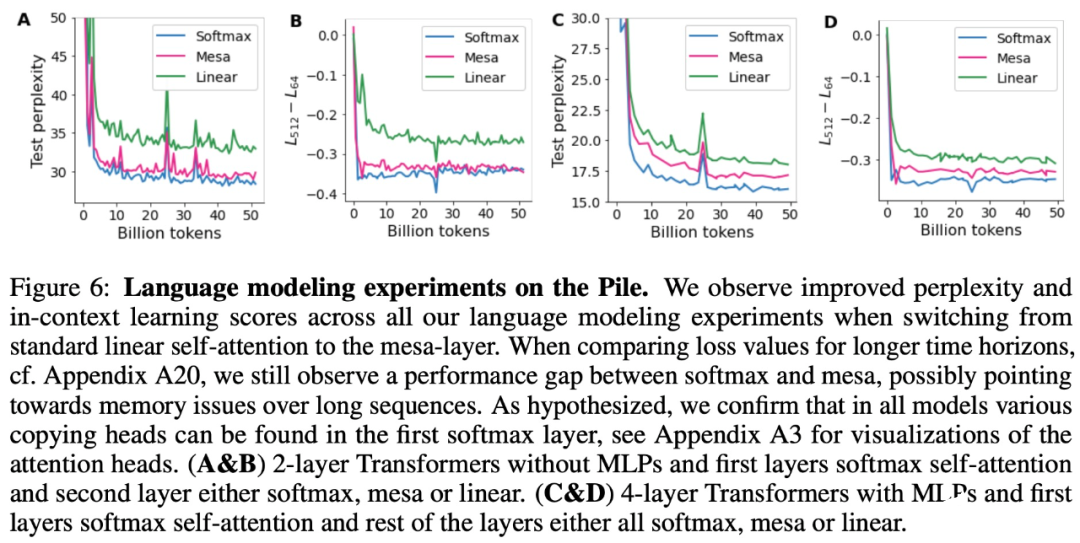
與單層模型一樣,作者在訓練模型的權重中看到了清晰的結構。作為第一個逆向工程分析,該研究利用這個結構并構建一個算法(RevAlg-d,其中 d 表示層數),每個層頭包含 16 個參數(而不是 3200 個)。作者發現這種壓縮但復雜的表達式可以描述經過訓練的模型。特別是,它允許以幾乎無損的方式在實際 Transformer 和 RevAlg-d 權重之間進行插值。 雖然 RevAlg-d 表達式解釋了具有少量自由參數的經過訓練的多層 Transformer,但很難將其解釋為 mesa 優化算法。因此,作者采用線性回歸探測分析(Alain & Bengio,2017;Akyürek et al.,2023)來尋找假設的 mesa 優化算法的特征。 在圖 3 所示的深度線性自注意力 Transformer 上,我們可以看到兩個探針都可以線性解碼,解碼性能隨著序列長度和網絡深度的增加而增加。因此,基礎優化發現了一種混合算法,該算法在原始 mesa-objective Lt (W) 的基礎上逐層下降,同時改進 mesa 優化問題的條件數。這導致 mesa-objective Lt (W) 快速下降。此外可以看到性能隨著深度的增加而顯著提高。 因此可以認為自回歸 mesa-objective Lt (W) 的快速下降是通過對更好的預處理數據進行逐步(跨層)mesa 優化來實現的。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
人工智能
+關注
關注
1817文章
50094瀏覽量
265295 -
深度學習
+關注
關注
73文章
5598瀏覽量
124396 -
DeepMind
+關注
關注
0文章
131瀏覽量
12285 -
Transformer
+關注
關注
0文章
156瀏覽量
6937 -
大模型
+關注
關注
2文章
3648瀏覽量
5179
原文標題:Transformer的上下文學習能力是哪來的?
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
Transformer 入門:從零理解 AI 大模型的核心原理
詞。
erlang
體驗AI代碼助手
代碼解讀
復制代碼
輸入:\"今天天氣真\"
↓
[Transformer 魔法盒子]
↓
輸出:\"好\" (概率 85
發表于 02-10 16:33
NVIDIA BlueField-4為推理上下文記憶存儲平臺提供強大支持
隨著代理式 AI 工作流將上下文窗口擴展到數百萬個 token,并將模型規模擴展到數百萬億個參數,AI 原生企業正面臨著越來越多的擴展挑戰。這些系統目前依賴于智能體長期記憶來存儲跨多輪、工具和會話持續保存的上下文,以便智能體能夠基于先前的推理進行構建,而不是每次請求都從頭

Transformer如何讓自動駕駛大模型獲得思考能力?
在談及自動駕駛時,Transformer一直是非常關鍵的技術,為何Transformer在自動駕駛行業一直被提及?
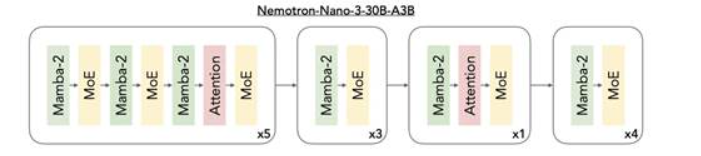
深入解析NVIDIA Nemotron 3系列開放模型
這一全新開放模型系列引入了開放的混合 Mamba-Transformer MoE 架構,使多智能體系統能夠進行快速長上下文推理。
大語言模型如何處理上下文窗口中的輸入
本博客介紹了五個基本概念,闡述了大語言模型如何處理上下文窗口中的輸入。通過明確的例子和實踐中獲得的見解,本文介紹了多個與上下文窗口有關的基本概念,如詞元化、序列長度和注意力等。

Transformer如何讓自動駕駛變得更聰明?
]自動駕駛中常提的Transformer本質上是一種神經網絡結構,最早在自然語言處理里火起來。與卷積神經網絡(CNN)或循環神經網絡(RNN)不同,Transformer能夠自動審視所有輸入信息,并動態判斷哪些部分更為關鍵,同時可以將這些重要信息有效地關聯起來。
請問riscv中斷還需要軟件保存上下文和恢復嗎?
以下是我拷貝的文檔里的說明,這個中斷處理還需要軟件來寫上下文保存和恢復,在使用ARM核的單片機都不需要考慮這些的,使用過的小伙伴能解答嗎?
3.8. 進出中斷的上下文保存和恢復
RISC-V架構
發表于 10-20 09:56
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+第二章 實現深度學習AI芯片的創新方法與架構
徹底改變了自然語義處理的研究和應用。它引入了自注意機制和位置編碼,能夠有效的捕捉輸入序列中的關聯信息,實現更好的上下文理解和建模。
Transformer 模型由一個編碼器和一個解碼器組成,是一種
發表于 09-12 17:30
自動駕駛中Transformer大模型會取代深度學習嗎?
[首發于智駕最前沿微信公眾號]近年來,隨著ChatGPT、Claude、文心一言等大語言模型在生成文本、對話交互等領域的驚艷表現,“Transformer架構是否正在取代傳統深度學習”這一話題一直被

鴻蒙NEXT-API19獲取上下文,在class中和ability中獲取上下文,API遷移示例-解決無法在EntryAbility中無法使用最新版
摘要:隨著鴻蒙系統API升級至16版本(modelVersion5.1.1),多項API已廢棄。獲取上下文需使用UIContext,具體方法包括:在組件中使用getUIContext(),在類中使

Transformer架構中編碼器的工作流程
編碼器是Transformer體系結構的基本組件。編碼器的主要功能是將輸入標記轉換為上下文表示。與早期獨立處理token的模型不同,Transformer編碼器根據整個序列捕獲每個token的

Transformer架構概述
由于Transformer模型的出現和快速發展,深度學習領域正在經歷一場翻天覆地的變化。這些突破性的架構不僅重新定義了自然語言處理(NLP)的標準,而且拓寬了視野,徹底改變了AI的許多方面。

快手上線鴻蒙應用高性能解決方案:數據反序列化性能提升90%
近日,快手在Gitee平臺上線了鴻蒙應用性能優化解決方案“QuickTransformer”,該方案針對鴻蒙應用開發中廣泛使用的三方庫“class-transformer”進行了深度優化,有效提升
發表于 05-15 10:01
如何應對邊緣設備上部署GenAI的挑戰
過去十年間,人工智能(AI)和機器學習(ML)領域發生了巨大的變化。卷積神經網絡(CNN)和循環神經網絡(RNN)逐漸被Transformer和生成式人工智能(GenAI)所取代,這標志著該領域進入了一個全新的發展階段。這一轉變源于人們需要更準確、高效且具備
S32K在AUTOSAR中使用CAT1 ISR,是否需要執行上下文切換?
如果我們在 AUTOSAR 中使用 CAT1 ISR,是否需要執行上下文切換?另外,是否需要返回指令才能跳回到作系統?您有沒有帶有 CAT1 ISR 的 S32K3x4 微控制器的示例?
發表于 03-27 07:34



 工商網監
工商網監
評論