 迄今最大模型?OpenAI發布參數量高達15億的通用語言模型GPT-2
迄今最大模型?OpenAI發布參數量高達15億的通用語言模型GPT-2

幾個月前谷歌推出的語言模型BERT引發了業內的廣泛關注,其 3 億參數量刷新 11 項紀錄的成績讓人不禁贊嘆。昨天,OpenAI 推出了一種更為強大的算法,這一次模型達到了 15 億參數。
代碼地址:https://github.com/openai/gpt-2
這種機器學習算法不僅在很多任務上達到了業內最佳水平,還可以根據一小段話自動「腦補」出大段連貫的文本,如有需要,人們可以通過一些調整讓計算機模擬不同的寫作風格。看起來可以用來自動生成「假新聞」。對此,OpenAI 甚至表示:「出于對模型可能遭惡意應用的擔憂,我們本次并沒有發布所有預訓練權重。」
如此強大的模型卻不公開所有代碼?Kyunghyun Cho 并不滿意:「要是這樣,為了人類我不得不刪除迄今為止自己公開的所有模型權重了。」Yann LeCun 表示贊同。
OpenAI 訓練了一個大型無監督語言模型,能夠生產連貫的文本段落,在許多語言建模基準上取得了 SOTA 表現。而且該模型在沒有任務特定訓練的情況下,能夠做到初步的閱讀理解、機器翻譯、問答和自動摘要。
該模型名為 GPT-2(GPT二代)。訓練 GPT-2 是為了預測 40GB 互聯網文本中的下一個單詞。考慮到可能存在的對該技術的惡意使用,OpenAI 沒有發布訓練模型,而是發布了一個較小模型供研究、實驗使用,同時 OpenAI 也公布了相關技術論文(見文后)。
GPT-2 是基于 transformer 的大型語言模型,包含 15 億參數、在一個 800 萬網頁數據集上訓練而成。訓練 GPT-2 有一個簡單的目標:給定一個文本中前面的所有單詞,預測下一個單詞。數據集的多樣性使得這一簡單目標包含不同領域不同任務的自然事件演示。GPT-2 是對 GPT 模型的直接擴展,在超出 10 倍的數據量上進行訓練,參數量也多出了 10 倍。
15 億的參數量已經是非常非常多了,例如我們認為龐大的 BERT 也就 3.3 億的參數量,我們認為視覺中參數量巨大的 VGG-19 也不過 1.44 億參數量(VGG-16 為 1.38 億),而 1001 層的 ResNet 不過 0.102 億的參數量。所以根據小編的有偏估計,除了 bug 級的大規模集成模型以外,說不定 GPT-2 就是當前最大的模型~
GPT-2 展示了一系列普適而強大的能力,包括生成當前最佳質量的條件合成文本,其中我們可以將輸入饋送到模型并生成非常長的連貫文本。此外,GPT-2 優于在特定領域(如維基百科、新聞或書籍)上訓練的其它語言模型,而且還不需要使用這些特定領域的訓練數據。在知識問答、閱讀理解、自動摘要和翻譯等任務上,GPT-2 可以從原始文本開始學習,無需特定任務的訓練數據。雖然目前這些下游任務還遠不能達到當前最優水平,但 GPT-2 表明如果有足夠的(未標注)數據和計算力,各種下游任務都可以從無監督技術中獲益。
Zero-shot
GPT-2 在多個領域特定的語言建模任務上實現了當前最佳性能。該模型沒有在這些任務的特定數據上進行訓練,只是最終測試時在這些數據上進行了評估。這被稱為「zero-shot」設置。在這些數據集上進行評估時,GPT-2 的表現要優于那些在領域特定數據集(如維基百科、新聞、書籍)上訓練的模型。下圖展示了在 zero-shot 設定下 GPT-2 的所有當前最佳結果。
(+)表示該領域得分越高越好,(-)表示得分越低越好。
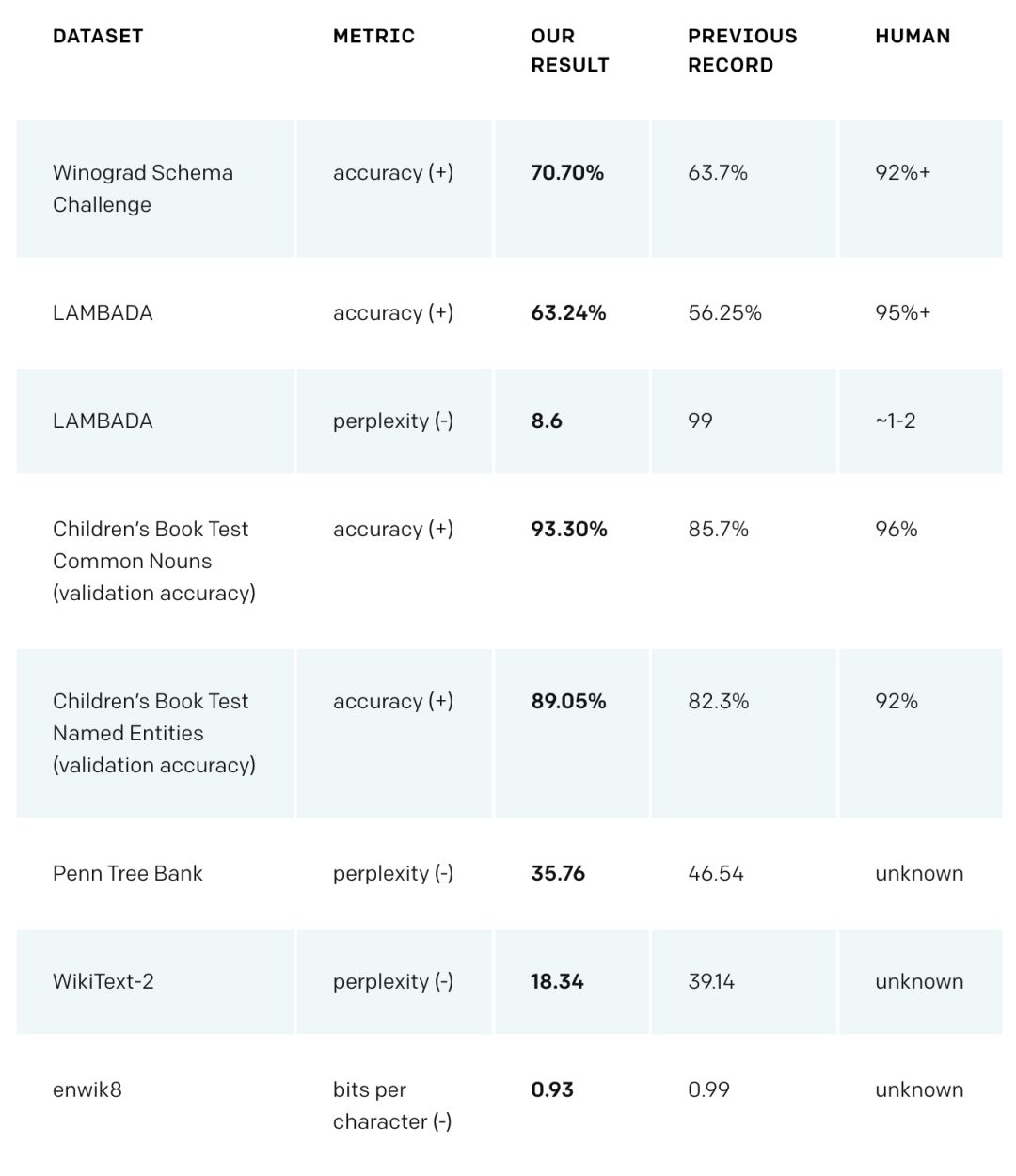

GPT-2 在 Winograd Schema、LAMBADA 和其他語言建模任務中達到了當前最佳性能。
在問答、閱讀理解、自動摘要、翻譯等其他語言任務中,無需對 GPT-2 模型做任何微調,只需以正確的方式增強模型,就能取得令人驚艷的結果,雖然其結果仍遜于專門系統。
OpenAI 假設,既然這些任務是通用語言建模的子集,那么增加計算量和數據就能獲得進一步的性能提升。《Learning and Evaluating General Linguistic Intelligence》等其他研究也有類似假設。OpenAI 還預期微調能夠對下游任務的性能提升有所幫助,盡管還沒有全面的實驗能證明這一點。
策略建議
大型通用語言模型可能產生巨大的社會影響以及一些近期應用。OpenAI 預期 GPT-2 這樣的系統可用于創建:
AI 寫作助手
更強大的對話機器人
無監督語言翻譯
更好的語音識別系統
此外,OpenAI 還設想了此類模型有可能用于惡意目的,比如:
生成誤導性新聞
網上假扮他人
自動生產惡意或偽造內容,并發表在社交媒體上
自動生產垃圾/釣魚郵件
這些研究成果與合成圖像和音視頻方面的早期研究結果表明,技術正在降低生產偽造內容、進行虛假信息活動的成本。公眾將需要對在線文本內容具備更強的批判性,就像「deep fakes」導致人們對圖像持懷疑態度一樣。
今天,惡意活動參與者(其中一些是政治性的)已經開始瞄準共享網絡社區,他們使用「機器人工具、偽造賬號和專門團隊等,對個人施加惡意評論或誹謗,致使大眾不敢發言,或很難被別人傾聽或信任」。OpenAI 認為,我們應該意識到,合成圖像、視頻、音頻和文本生成等方面研究的結合有可能進一步解鎖這些惡意參與者的能力,使之達到前所未有的高度,因此研究者應當尋求創建更好的技術和非技術應對措施。此外,這些系統的底層技術創新是基礎人工智能研究的核心,因此控制這些領域的研究必將拖慢 AI 領域的整體發展。
因此,OpenAI 對這一新研究成果的發布策略是:「僅發布 GPT-2 的較小版本和示例代碼,不發布數據集、訓練代碼和 GPT-2 模型權重」。
論文:Large Language Models are Unsupervised Multitask Learners

論文地址:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
摘要:問答、機器翻譯、閱讀理解、自動摘要這樣的自然語言處理任務的典型方法是在任務特定數據集上進行監督式學習。我們證明,在包含數百萬網頁的全新數據集 WebText 上訓練時,語言模型開始在沒有任何明確監督的情況下學習這些任務。計算條件概率并生成條件樣本是語言模型在大量任務上取得良好結果(且無需精調)所必需的能力。當以文檔+問題為條件時,在沒有使用 127000 多個訓練樣本中任何一個樣本的情況下,語言模型生成的答案在 CoQA 數據集上達到 55F1,媲美于或者超越了 4 個基線系統中的 3 個。語言模型的容量對 zero-shot 任務的成功遷移非常重要,且增加模型的容量能夠以對數線性的方式在多任務中改進模型性能。我們最大的模型 GPT-2 是一個包含 15 億參數的 Transformer,在 zero-shot 設定下,該模型在 8 個測試語言建模數據集中的 7 個數據集上取得了 SOTA 結果,但仍舊欠擬合 WebText 數據集。來自該模型的樣本反映了這些改進且包含連貫的文本段落。這些發現展示了一種構建語言處理系統的潛在方式,即根據自然發生的演示學習執行任務。
-
機器人
+關注
關注
213文章
31073瀏覽量
222188 -
AI
+關注
關注
91文章
39755瀏覽量
301364 -
機器翻譯
+關注
關注
0文章
141瀏覽量
15526
原文標題:迄今最大模型?OpenAI發布參數量高達15億的通用語言模型GPT-2
文章出處:【微信號:aicapital,微信公眾號:全球人工智能】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
GPT-5震撼發布:AI領域的重大飛躍

上海交大發布國產光學大模型Optics GPT

如何在NVIDIA Jetson AGX Thor上部署1200億參數大模型

GPT-5.1發布 OpenAI開始拼情商
谷歌與耶魯大學合作發布最新C2S-Scale 27B模型
如何在TPU上使用JAX訓練GPT-2模型
NVIDIA從云到邊緣加速OpenAI gpt-oss模型部署,實現150萬TPS推理

澎峰科技完成OpenAI最新開源推理模型適配
訊飛星辰MaaS平臺率先上線OpenAI最新開源模型
OpenAI或在周五凌晨發布GPT-5 OpenAI以低價向美國政府提供ChatGPT
【VisionFive 2單板計算機試用體驗】3、開源大語言模型部署
華為助力中國石油發布3000億參數昆侖大模型

用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

?VLM(視覺語言模型)?詳細解析




 工商網監
工商網監
評論