") 借助谷歌LiteRT構(gòu)建下一代高性能端側(cè)AI
借助谷歌LiteRT構(gòu)建下一代高性能端側(cè)AI

作者 /Lu Wang (Senior Staff Software Engineer)、Chintan Parikh (Senior Product Manager)、Jingjiang Li (Staff Software Engineer)、Terry Heo (Senior Software Engineer)
自 2024 年LiteRT問世以來,我們一直致力于將機(jī)器學(xué)習(xí)技術(shù)棧從其 TensorFlow Lite (TFLite) 基礎(chǔ)之上演進(jìn)為一個(gè)現(xiàn)代化的端側(cè) AI (On-Device AI) 框架。雖然 TFLite 為傳統(tǒng)端側(cè)機(jī)器學(xué)習(xí)設(shè)定了標(biāo)準(zhǔn),但我們的使命是讓開發(fā)者能夠像過去集成傳統(tǒng)端側(cè)機(jī)器學(xué)習(xí)一樣,無縫地在設(shè)備端部署當(dāng)今最前沿的 AI (如大語言模型)。
LiteRT https://developers.googleblog.com/en/tensorflow-lite-is-now-litert/
在 2025 Google I/O 大會(huì)上,我們?cè)醪秸故玖诉@一演進(jìn)成果: 一個(gè)專為先進(jìn)硬件加速設(shè)計(jì)的高性能運(yùn)行時(shí) (Runtime)。現(xiàn)在,我們很高興地宣布,這些先進(jìn)的加速能力已正式并入 LiteRT 生產(chǎn)級(jí)技術(shù)棧,供所有開發(fā)者使用。
這一演進(jìn)成果 https://developers.googleblog.com/en/litert-maximum-performance-simplified/
這一里程碑鞏固了 LiteRT 在 AI 時(shí)代作為端側(cè)通用推理框架的地位,相比 TFLite 實(shí)現(xiàn)了重大飛躍,其優(yōu)勢(shì)體現(xiàn)在:
更快:提供比 TFLite 快 1.4 倍的 GPU 性能,并引入了全新的、最先進(jìn)的 NPU 加速支持。
更簡(jiǎn)單:為跨邊緣平臺(tái)的 GPU 和 NPU 加速提供統(tǒng)一、簡(jiǎn)化的工作流程。
更強(qiáng)大:支持熱門的開放模型 (例如 Gemma),以實(shí)現(xiàn)卓越的跨平臺(tái)生成式 AI (GenAI) 部署能力。
更靈活:通過無縫模型轉(zhuǎn)換提供一流的 PyTorch/JAX 支持。
在交付上述所有創(chuàng)新成果的同時(shí),我們?nèi)匝永m(xù)了自 TFLite 以來您所信賴的可靠與跨平臺(tái)部署體驗(yàn)。
歡迎您繼續(xù)閱讀,了解 LiteRT 如何幫助您構(gòu)建下一代端側(cè) AI。
高性能跨平臺(tái) GPU 加速
除了在 2025 Google I/O 大會(huì)上宣布初步支持 Android GPU 加速之外,我們很高興地宣布在Android、iOS、macOS、Windows、Linux和 Web上提供全面、綜合的 GPU 支持。這一擴(kuò)展為開發(fā)者提供了一個(gè)可靠、高性能的加速選項(xiàng),其擴(kuò)展能力顯著超越了傳統(tǒng)的 CPU 推理。
* Python 上的 Windows WebGPU 即將推出
LiteRT 通過ML Drift(我們的下一代 GPU 引擎) 引入對(duì)OpenCL、OpenGL、Metal和WebGPU的強(qiáng)大支持,最大限度地?cái)U(kuò)大了覆蓋范圍,使您能夠跨移動(dòng)、桌面和 Web 高效部署模型。在 Android 上,LiteRT 進(jìn)一步優(yōu)化了這一點(diǎn): 在可用時(shí)自動(dòng)優(yōu)先使用 OpenCL 以實(shí)現(xiàn)峰值性能,同時(shí)保留 OpenGL 支持以實(shí)現(xiàn)更廣泛的覆蓋。
在 ML Drift 的支持下,LiteRT GPU 在效率上實(shí)現(xiàn)了顯著飛躍,提供了比傳統(tǒng)的 TFLite GPU 代理平均快 1.4 倍的性能提升,顯著減少了各種模型的延遲。更多基準(zhǔn)測(cè)試結(jié)果請(qǐng)參閱我們之前的文章。
之前的文章 https://developers.googleblog.com/en/litert-maximum-performance-simplified/#:~:text=MLDrift%3A%20Best%20GPU%20Acceleration%20Yet
為了實(shí)現(xiàn)高性能 AI 應(yīng)用,我們還引入了關(guān)鍵的技術(shù)升級(jí)來優(yōu)化端到端延遲,特別是異步執(zhí)行和零拷貝 (zero-copy) 緩沖區(qū)互操作性。這些功能顯著減少了不必要的 CPU 開銷并提高了整體性能,滿足了背景分割(Segmentation)和語音識(shí)別 (ASR) 等實(shí)時(shí)用例的嚴(yán)格要求。正如我們的分割示例應(yīng)用所展示的那樣,實(shí)際上,這些優(yōu)化可以帶來高達(dá)2 倍的性能提升。歡迎參閱我們的技術(shù)深度解析以了解更多詳細(xì)內(nèi)容。
分割示例應(yīng)用 https://github.com/google-ai-edge/litert-samples/tree/main/compiled_model_api/image_segmentation/c%2B%2B_segmentation
技術(shù)深度解析 https://developers.googleblog.com/en/litert-maximum-performance-simplified/#:~:text=Advanced%20Inference%20for%20Performance%20Optimization
以下示例演示了如何在 C++ 中使用新的CompiledModelAPI 輕松利用 GPU 加速:
// 1. Create a compiled model targeting GPU in C++. autocompiled_model = CompiledModel::Create(env,"mymodel.tflite", kLiteRtHwAcceleratorGpu); // 2. Create an input TensorBuffer that wraps the OpenGL buffer (i.e. from image pre-processing) with zero-copy. autoinput_buffer = TensorBuffer::CreateFromGlBuffer(env, tensor_type, opengl_buffer); std::vectorinput_buffers{input_buffer}; autooutput_buffers = compiled_model.CreateOutputBuffers(); // 3. Execute the model. compiled_model.Run(inputs, outputs); // 4. Access model output, i.e. AHardwareBuffer. autoahwb = output_buffer[0]->GetAhwb();
有關(guān)LiteRT 跨平臺(tái)開發(fā)和GPU 加速的更多說明,請(qǐng)?jiān)L問 LiteRT 官方網(wǎng)站。
LiteRT 跨平臺(tái)開發(fā)
https://ai.google.dev/edge/litert/overview#integrate-model
GPU 加速
https://ai.google.dev/edge/litert/next/gpu
簡(jiǎn)化 NPU 集成,釋放峰值性能
雖然 CPU 和 GPU 為 AI 任務(wù)提供了廣泛的通用性,但 NPU 卻是實(shí)現(xiàn)現(xiàn)代應(yīng)用所需的流暢、響應(yīng)迅速和高速 AI 體驗(yàn)的關(guān)鍵。然而,數(shù)百種 NPU SoC 變體之間的碎片化常常迫使開發(fā)者不得不應(yīng)對(duì)由不同編譯器和運(yùn)行時(shí)組成的 "迷宮"。此外,由于傳統(tǒng)的機(jī)器學(xué)習(xí)基礎(chǔ)設(shè)施歷來缺乏與專用 NPU SDK 的深度集成,導(dǎo)致部署工作流程復(fù)雜多變且難以在生產(chǎn)環(huán)境中有效管理。
LiteRT 通過提供統(tǒng)一、簡(jiǎn)化的 NPU 部署工作流程來應(yīng)對(duì)這些挑戰(zhàn),該工作流程抽象了底層的、供應(yīng)商專用的 SDK,并處理了眾多 SoC 變體之間的碎片化。我們已將其簡(jiǎn)化為一個(gè)簡(jiǎn)單的三步流程,助您輕松實(shí)現(xiàn)模型的 NPU 加速部署:
針對(duì)目標(biāo) SoC 進(jìn)行 AOT 編譯(可選): 使用 LiteRT Python 庫為目標(biāo) SoC 預(yù)編譯您的.tflite模型。
通過 Google Play for On-device AI (PODAI) 部署 (Android 專用): 借助 PODAI 服務(wù),自動(dòng)將模型文件及運(yùn)行時(shí)環(huán)境分發(fā)至兼容設(shè)備。
使用 LiteRT 運(yùn)行時(shí)進(jìn)行推理: LiteRT 處理 NPU 委托 (delegation),并在需要時(shí)提供對(duì) GPU 或 CPU 的穩(wěn)健回退機(jī)制。
有關(guān)完整的詳細(xì)指南,包括 Colab 和示例應(yīng)用,請(qǐng)查閱我們的LiteRT NPU 文檔。
LiteRT NPU 文檔
https://ai.google.dev/edge/litert/next/npu
為了提供適合您特定部署需求的靈活集成選項(xiàng),LiteRT 提供提前編譯 (AOT)和端側(cè)即時(shí)編譯 (JIT)。這使您可以根據(jù)應(yīng)用的獨(dú)特需求選擇最佳策略:
AOT 編譯: 最適用于已知目標(biāo) SoC 的復(fù)雜模型。它最大限度地降低了啟動(dòng)時(shí)的初始化耗時(shí)和內(nèi)存占用,以實(shí)現(xiàn) "即時(shí)啟動(dòng)" 的體驗(yàn)。
JIT 編譯: 最適合在各種平臺(tái)上分發(fā)小規(guī)模模型。它不需要準(zhǔn)備,盡管首次運(yùn)行的初始化成本較高。
我們正在與業(yè)界領(lǐng)先的芯片制造商緊密合作,為開發(fā)者帶來高性能 NPU 加速。我們與聯(lián)發(fā)科 (MediaTek)和高通 (Qualcomm)的首批生產(chǎn)就緒型集成方案現(xiàn)已推出。請(qǐng)閱讀我們的技術(shù)深度解析,了解我們?nèi)绾螌?shí)現(xiàn)業(yè)界領(lǐng)先的 NPU 性能,其速度比CPU 快 100 倍,比GPU 快 10 倍:
聯(lián)發(fā)科 NPU 和 LiteRT: 賦能下一代端側(cè) AI
https://developers.googleblog.com/mediatek-npu-and-litert-powering-the-next-generation-of-on-device-ai/
通過 LiteRT 釋放高通 NPU 的峰值性能
https://developers.googleblog.com/unlocking-peak-performance-on-qualcomm-npu-with-litert/
△左圖: 一個(gè)實(shí)時(shí)、端側(cè)的中文助手,具有視覺和音頻多模態(tài)功能,由 Gemma 3n 2B 提供支持。運(yùn)行在搭載聯(lián)發(fā)科天璣 9500 NPU 的 vivo 300 Pro 上。
△右圖: 使用 FastVLM 視覺模態(tài)進(jìn)行場(chǎng)景理解,運(yùn)行在搭載小米 17 Pro Max 的 Snapdragon 8 Elite Gen 5 上。
乘勢(shì)而上,我們正積極將 LiteRT 的 NPU 支持拓展至更廣泛的硬件生態(tài)。敬請(qǐng)期待后續(xù)公告!
卓越的跨平臺(tái) GenAI 支持
開放模型提供了無與倫比的靈活性和定制化能力,但部署它們?nèi)匀皇且粋€(gè)充滿挑戰(zhàn)的過程。處理模型底層轉(zhuǎn)換、推理和基準(zhǔn)測(cè)試的復(fù)雜性通常需要大量的工程開銷。為了彌合這一差距并使開發(fā)者能夠高效地構(gòu)建自定義體驗(yàn),我們提供了以下集成技術(shù)棧:
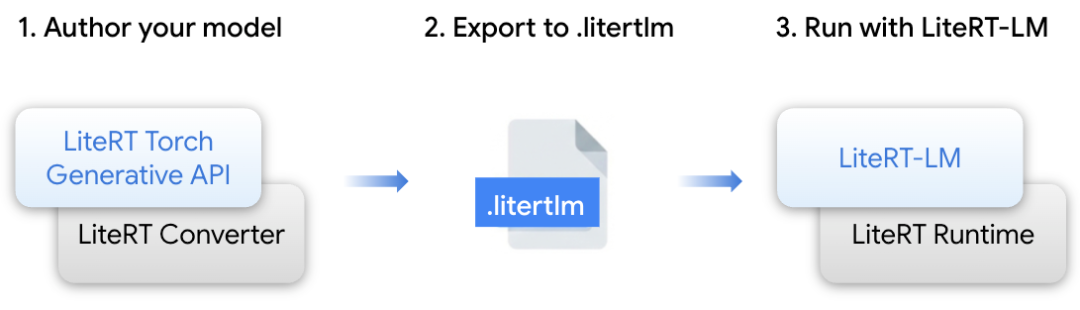
LiteRT Torch Generative API: 一個(gè) Python 模塊,旨在實(shí)現(xiàn)基于 transformer 的 PyTorch 模型的創(chuàng)作和轉(zhuǎn)換,使其適配 LiteRT/LiteRT-LM 格式。它提供了優(yōu)化的構(gòu)建模塊,可確保在邊緣設(shè)備上實(shí)現(xiàn)高性能執(zhí)行。
LiteRT-LM: 一個(gè)構(gòu)建在 LiteRT 之上的專用編排層 (orchestration layer),用于管理大語言模型 (LLM) 特有的復(fù)雜性。它是為 Google 產(chǎn)品 (包括 Chrome 和 Pixel Watch) 提供 Gemini Nano 部署支持的經(jīng)過實(shí)戰(zhàn)考驗(yàn)的基礎(chǔ)設(shè)施。
LiteRT 轉(zhuǎn)換器與運(yùn)行時(shí): 這一基礎(chǔ)引擎提供了高效的模型轉(zhuǎn)換、運(yùn)行時(shí)執(zhí)行和優(yōu)化,為跨 CPU、GPU 和 NPU 的高級(jí)硬件加速賦能,在邊緣平臺(tái)上提供最先進(jìn)的性能。
LiteRT Torch Generative API https://github.com/google-ai-edge/litert-torch/tree/main/litert_torch/generative
LiteRT-LM https://github.com/google-ai-edge/LiteRT-LM
為 Google 產(chǎn)品 (包括 Chrome 和 Pixel Watch) 提供 Gemini Nano 部署支持 https://developers.googleblog.com/on-device-genai-in-chrome-chromebook-plus-and-pixel-watch-with-litert-lm/
LiteRT 轉(zhuǎn)換器與運(yùn)行時(shí) https://github.com/google-ai-edge/LiteRT
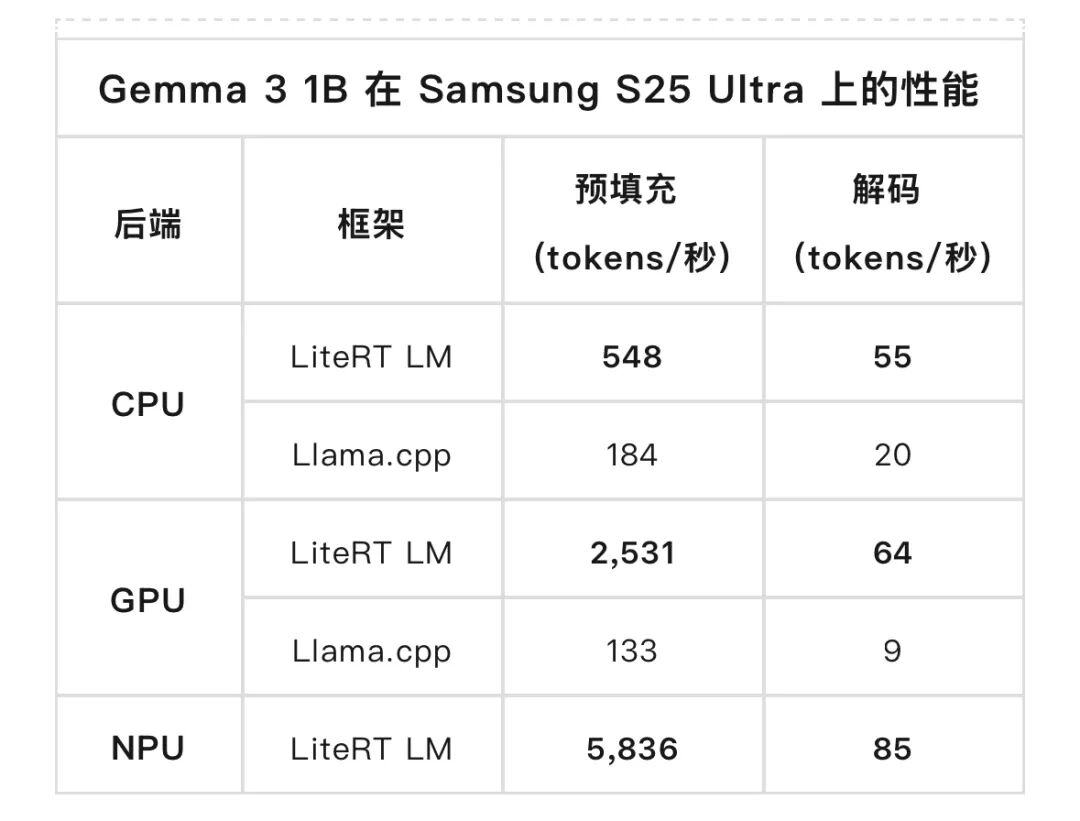
上述這些組件共同為運(yùn)行熱門開放模型提供了具有領(lǐng)先性能的生產(chǎn)級(jí)路徑。為了證明這一點(diǎn),我們?cè)?Samsung Galaxy S25 Ultra 上對(duì)Gemma 3 1B進(jìn)行了基準(zhǔn)測(cè)試,并將 LiteRT 與Llama.cpp進(jìn)行了比較。
Gemma 3 1B https://huggingface.co/litert-community/Gemma3-1B-IT
Llama.cpp https://github.com/ggml-org/llama.cpp
LiteRT 展現(xiàn)出明顯的性能優(yōu)勢(shì),對(duì)于解碼階段 (內(nèi)存密集型),它在CPU上比 llama.cpp 快 3 倍,在GPU 上快 7 倍;對(duì)于預(yù)填充階段 (計(jì)算密集型),它在GPU 上快 19 倍。此外,LiteRT 的 NPU 加速在預(yù)填充階段比 GPU 額外提升了 2 倍性能,從而充分釋放了計(jì)算硬件的潛力。要詳細(xì)了解這些基準(zhǔn)測(cè)試背后的工程技術(shù),請(qǐng)閱讀我們對(duì)LiteRT 幕后優(yōu)化的深入探討。
LiteRT 幕后優(yōu)化
https://developers.googleblog.com/gemma-3-on-mobile-and-web-with-google-ai-edge/#:~:text=current%20activity%20level.-,Under%20the%20hood,-The%20performance%20results
LiteRT 支持廣泛且持續(xù)增長(zhǎng)的主流開放權(quán)重模型,這些模型經(jīng)過精心優(yōu)化和預(yù)轉(zhuǎn)換,可立即部署,包括:
Gemma 模型系列: Gemma 3 (270M、1B)、Gemma 3n、EmbeddingGemma 和 FunctionGemma。
Qwen、Phi、FastVLM等。
△AI Edge Gallery 應(yīng)用演示,由 LiteRT 提供支持: TinyGarden (左) 和 Mobile Actions (右),使用FunctionGemma構(gòu)建。
這些模型可在LiteRT Hugging Face 社區(qū)獲取,并通過Android和iOS上的Google AI Edge Gallery 應(yīng)用進(jìn)行交互式探索。
LiteRT Hugging Face 社區(qū) https://huggingface.co/litert-community
Android https://play.google.com/store/apps/details?id=com.google.ai.edge.gallery
iOS https://testflight.apple.com/join/nAtSQKTF
Google AI Edge Gallery 應(yīng)用 https://github.com/google-ai-edge/gallery
更多開發(fā)細(xì)節(jié),請(qǐng)參閱我們的LiteRT GenAI 文檔。
LiteRT GenAI 文檔
https://ai.google.dev/edge/litert/genai/overview
廣泛的機(jī)器學(xué)習(xí)框架支持
部署不應(yīng)受限于您所選用的訓(xùn)練框架。LiteRT 提供來自業(yè)界最主流機(jī)器學(xué)習(xí)框架的無縫模型轉(zhuǎn)換:PyTorch、TensorFlow 和 JAX。
PyTorch 支持: 借助AI Edge Torch 庫,您可以將 PyTorch 模型通過一個(gè)簡(jiǎn)化的步驟直接轉(zhuǎn)換為.tflite格式。這確保了基于 PyTorch 的架構(gòu)可以立即充分利用 LiteRT 的高級(jí)硬件加速,省去了對(duì)復(fù)雜中間轉(zhuǎn)換的需求。
TensorFlow 和 JAX: LiteRT 持續(xù)為 TensorFlow 生態(tài)系統(tǒng)提供強(qiáng)大、一流的支持,并通過jax2tf橋接工具為 JAX 模型提供可靠的轉(zhuǎn)換路徑。這確保了來自 Google 任何核心機(jī)器學(xué)習(xí)庫的最先進(jìn)研究都可以高效地部署到數(shù)十億設(shè)備上。
AI Edge Torch 庫
https://github.com/google-ai-edge/ai-edge-torch
通過整合這些路徑,無論您的開發(fā)環(huán)境如何,LiteRT 都能支持從研究到生產(chǎn)的快速實(shí)現(xiàn)。您可以在首選框架中構(gòu)建模型,并依賴 LiteRT 在 CPU、GPU 和 NPU 后端上實(shí)現(xiàn)卓越的性能交付。
要開始使用,請(qǐng)?zhí)剿鰽I Edge Torch Colab并親自嘗試轉(zhuǎn)換過程,或在此技術(shù)深度解析中深入了解我們 PyTorch 集成的技術(shù)細(xì)節(jié)。
AI Edge Torch Colab https://ai.google.dev/edge/litert/conversion/pytorch/overview
技術(shù)深度解析 https://developers.googleblog.com/en/ai-edge-torch-high-performance-inference-of-pytorch-models-on-mobile-devices/
值得信賴的可靠性和兼容性
盡管 LiteRT 的能力已顯著擴(kuò)展,但我們對(duì)長(zhǎng)期可靠性和跨平臺(tái)一致性的承諾保持不變。LiteRT 繼續(xù)建立在久經(jīng)考驗(yàn)的.tflite模型格式之上,這是一種行業(yè)標(biāo)準(zhǔn)的單文件格式,可確保您現(xiàn)有的模型在 Android、iOS、macOS、Linux、Windows、Web 和 IOT 上保持可移植性和兼容性。
為了向開發(fā)者提供持續(xù)的體驗(yàn),LiteRT 為現(xiàn)有的和下一代推理路徑提供了強(qiáng)大的支持:
Interpreter API: 您現(xiàn)有的生產(chǎn)模型將繼續(xù)可靠運(yùn)行,保持您所依賴的廣泛設(shè)備覆蓋范圍和堅(jiān)如磐石的穩(wěn)定性。
新的 CompiledModel API: 此現(xiàn)代化接口專為下一代 AI 設(shè)計(jì),提供了無縫路徑來釋放GPU和 NPU 加速的全部潛力,以滿足日益演進(jìn)的新 AI 需求。有關(guān)選擇 CompiledModel API 的更多原因,請(qǐng)參閱文檔。
文檔
https://ai.google.dev/edge/litert/inference#why-compiled-model
未來計(jì)劃
準(zhǔn)備好構(gòu)建端側(cè) AI 的未來了嗎?歡迎您查看相關(guān)資料,輕松上手:
探索LiteRT 文檔以獲取全面的開發(fā)指南。
查看LiteRT GitHub和LiteRT 示例 Github以獲取示例代碼和實(shí)現(xiàn)細(xì)節(jié)。
訪問LiteRT Hugging Face 社區(qū)以獲取 Gemma 等即用型開放模型,并在Android和iOS上試用Google AI Edge Gallery 應(yīng)用來體驗(yàn)實(shí)際運(yùn)行中的 AI。
LiteRT 文檔 https://ai.google.dev/edge/litert
LiteRT GitHub https://github.com/google-ai-edge/litert
LiteRT 示例 Github https://github.com/google-ai-edge/litert-samples
LiteRT Hugging Face 社區(qū) https://huggingface.co/litert-community
Android https://play.google.com/store/apps/details?id=com.google.ai.edge.gallery
iOS https://testflight.apple.com/join/nAtSQKTF
Google AI Edge Gallery 應(yīng)用 https://github.com/google-ai-edge/gallery
歡迎您通過GitHub 頻道與我們進(jìn)行交流,讓我們了解您的反饋和功能請(qǐng)求。我們迫不及待地想看到您用 LiteRT 創(chuàng)造出的精彩內(nèi)容!也歡迎您持續(xù)關(guān)注 "谷歌開發(fā)者" 微信公眾號(hào),及時(shí)了解更多開發(fā)技術(shù)和產(chǎn)品更新等資訊動(dòng)態(tài)。
GitHub 頻道
https://github.com/google-ai-edge/LiteRT/issues
致謝
感謝團(tuán)隊(duì)成員和所有合作者為本次發(fā)布中取得的進(jìn)步所做的貢獻(xiàn): Advait Jain, Andrew Zhang, Andrei Kulik, Akshat Sharma, Arian Arfaian, Byungchul Kim, Changming Sun, Chunlei Niu, Chun-nien Chan, Cormac Brick, David Massoud, Dillon Sharlet, Fengwu Yao, Gerardo Carranza, Jingjiang Li, Jing Jin, Grant Jensen, Jae Yoo, Juhyun Lee, Jun Jiang, Kris Tonthat, Lin Chen, Lu Wang, Luke Boyer, Marissa Ikonomidis, Matt Kreileder, Matthias Grundmann, Majid Dadashi, Marko Risti?, Matthew Soulanille, Na Li, Ping Yu, Quentin Khan, Raman Sarokin, Ram Iyengar, Rishika Sinha, Sachin Kotwani, Shuangfeng Li, Steven Toribio, Suleman Shahid, Teng-Hui Zhu, Terry (Woncheol) Heo, Vitalii Dziuba, Volodymyr Kysenko, Weiyi Wang, Yu-Hui Chen, Pradeep Kuppala 和 gTech 團(tuán)隊(duì)。
-
Android
+關(guān)注
關(guān)注
12文章
4033瀏覽量
134300 -
gpu
+關(guān)注
關(guān)注
28文章
5235瀏覽量
135901 -
AI
+關(guān)注
關(guān)注
91文章
40578瀏覽量
302165
原文標(biāo)題:LiteRT | 釋放極致潛能,構(gòu)建下一代高性能端側(cè) AI
文章出處:【微信號(hào):Google_Developers,微信公眾號(hào):谷歌開發(fā)者】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Kapsch TrafficCom借助TomTom Traffic打造下一代智能出行產(chǎn)品
偉創(chuàng)力攜手博通,推進(jìn)下一代AI液冷解決方案落地

AMD 推出第二代 Kintex UltraScale+ 中端FPGA,助力智能高性能系統(tǒng)

晶晨攜手谷歌,助力端側(cè)大模型Gemini的硬件落地
借助谷歌FunctionGemma模型構(gòu)建下一代端側(cè)智能體

安霸半導(dǎo)體加速推進(jìn)下一代無人機(jī)端側(cè)AI創(chuàng)新
泰凌微:布局端側(cè)AI,產(chǎn)品支持谷歌LiteRT、TVM開源模型
高算力、低功耗!下一代端側(cè)AI芯片排隊(duì)進(jìn)場(chǎng)
AI眼鏡或成為下一代手機(jī)?谷歌、蘋果等巨頭扎堆布局
Microchip推出下一代Switchtec Gen 6 PCIe交換芯片
AI體驗(yàn)躍遷,天璣9500用雙NPU開創(chuàng)端側(cè)AI新時(shí)代

端側(cè)AI需求大爆發(fā)!安謀科技發(fā)布新一代NPU IP,賦能AI終端應(yīng)用
下一代高速芯片晶體管解制造問題解決了!
英特爾與面壁智能宣布建立戰(zhàn)略合作伙伴關(guān)系,共同研發(fā)端側(cè)原生智能座艙,定義下一代車載AI




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論