") TensorRT-LLM中的分離式服務(wù)
TensorRT-LLM中的分離式服務(wù)

在之前的技術(shù)博客中,我們介紹了低延遲和高吞吐場(chǎng)景的優(yōu)化方法。對(duì)于生產(chǎn)部署,用戶還關(guān)心在滿足特定延遲約束的情況下,每個(gè) GPU 的吞吐表現(xiàn)。本文將圍繞“吞吐量-延遲”性能場(chǎng)景,介紹 TensorRT-LLM 分離式服務(wù)的設(shè)計(jì)理念、使用方法,以及性能研究結(jié)果。
初衷
LLM 推理通常分為上下文 (prefill) 和生成 (decode) 兩個(gè)階段。在上下文階段,模型會(huì)根據(jù)提示詞計(jì)算鍵值 (KV) 緩存,而在生成階段,則利用這些緩存值逐步生成每一個(gè) Token。這兩個(gè)階段在計(jì)算特性上存在顯著差異。
LLM 推理請(qǐng)求的服務(wù)方式有兩種:
聚合式 LLM 服務(wù)(在本文中有時(shí)也稱為 IFB):上下文和生成階段通常在同一個(gè) GPU 上運(yùn)行。
分離式 LLM 服務(wù):上下文和生成階段通常在不同 GPU 上運(yùn)行。
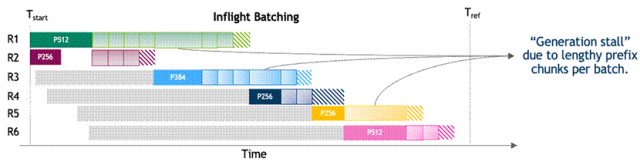
圖 1. 聚合式 LLM 服務(wù)執(zhí)行時(shí)間線
(該圖片來源于 NVIDIA 團(tuán)隊(duì)論文:Beyond the Buzz:
A Pragmatic Take on Inference Disaggregation,若您有任何疑問或需要使用該圖片,請(qǐng)聯(lián)系該文作者)
在聚合式 LLM 服務(wù)中,上下文和生成階段共享相同的 GPU 資源和并行策略。這種資源耦合會(huì)干擾上下文階段的 Token 生成速度,并且增加 Token 間延遲 (TPOT),從而影響用戶交互體驗(yàn),正如圖 1:聚合式 LLM 服務(wù)的執(zhí)行時(shí)間線所示。聚合式 LLM 服務(wù)還強(qiáng)制兩個(gè)階段使用相同的 GPU 類型和并行配置,盡管它們的計(jì)算需求并不相同。在這種耦合約束下,優(yōu)化某一項(xiàng)指標(biāo)(如首 Token 生成時(shí)間 TTFT)往往會(huì)以犧牲另一項(xiàng)指標(biāo) (如 TPOT) 為代價(jià)。
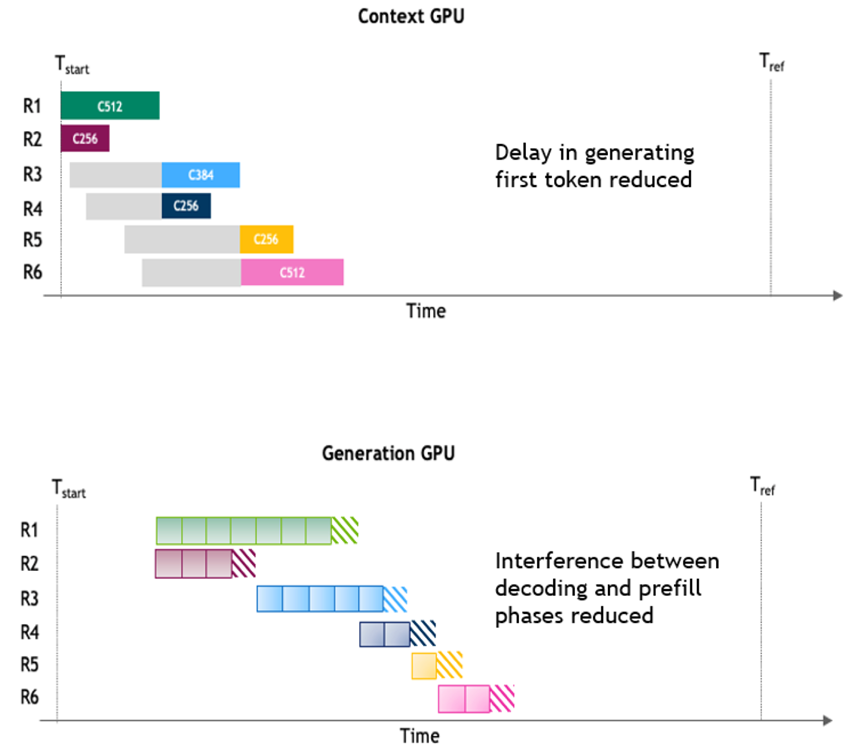
圖 2. 分離式 LLM 服務(wù)執(zhí)行時(shí)間線
(該圖片來源于 NVIDIA 團(tuán)隊(duì)論文:Beyond the Buzz:
A Pragmatic Take on Inference Disaggregation,若您有任何疑問或需要使用該圖片,請(qǐng)聯(lián)系該文作者)
分離式服務(wù)通過解耦上下文階段與生成階段有效解決了上述問題。兩個(gè)階段可分別運(yùn)行在不同的 GPU 池上,并采用各自優(yōu)化的并行策略,從而避免了資源干擾。如圖 2 所示,這種分離式的運(yùn)行方式消除了上下文和生成階段之間性能沖突,使得 TTFT 和 TPOT 能夠分別進(jìn)行針對(duì)性優(yōu)化。盡管在兩個(gè)階段之間傳輸 KV 緩存塊會(huì)帶來一定開銷,但在輸入序列較長(zhǎng)、輸出長(zhǎng)度適中的工作負(fù)載下,這種架構(gòu)的優(yōu)勢(shì)依然十分顯著——尤其是在此類場(chǎng)景中,IFB 干擾最為嚴(yán)重。
關(guān)于更多分離式服務(wù)的原理和設(shè)計(jì)細(xì)節(jié),請(qǐng)參考這篇論文:
https://arxiv.org/pdf/2506.05508
使用 TensorRT-LLM 執(zhí)行分離服務(wù)
使用 TensorRT-LLM 進(jìn)行 LLM 分離式推理共有三種不同方法,每種方法在架構(gòu)設(shè)計(jì)和運(yùn)行特性上各具優(yōu)勢(shì),適用于不同的部署場(chǎng)景。
trtllm-serve
trtllm-serve是一個(gè)命令行工具,用于部署與 OpenAI 兼容的 TensorRT-LLM 服務(wù)。
使用 TensorRT-LLM 進(jìn)行 LLM 分離式推理的第一種方法是通過trtllm-serve為每個(gè)上下文和生成實(shí)例分別啟動(dòng)獨(dú)立的 OpenAI 服務(wù)。同時(shí),trtllm-serve還會(huì)啟動(dòng)一個(gè)稱為“分離服務(wù)器”的調(diào)度器,用于接收客戶端請(qǐng)求,并通過 OpenAI REST API 將請(qǐng)求分發(fā)至對(duì)應(yīng)的上下文或生成服務(wù)器。圖 3 展示了該方法的工作流程。當(dāng)上下文實(shí)例完成提示詞的 KV 緩存生成后,會(huì)將結(jié)果返回給分離式服務(wù)器,其中包含提示詞 Token、首個(gè)生成Token以及與上下文相關(guān)的元數(shù)據(jù)(稱為ctx_params)。這些參數(shù)隨后被生成實(shí)例用于與上下文實(shí)例建立連接,并檢索與請(qǐng)求相關(guān)的 KV 緩存塊。
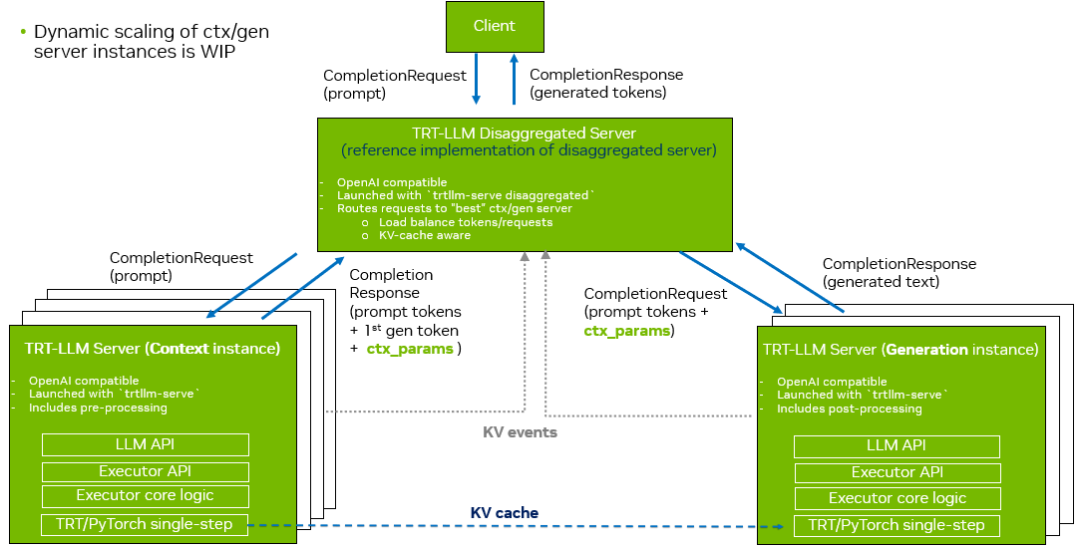
圖 3. 使用 trtllm-serve 進(jìn)行分離式服務(wù)
在以下示例中,上下文階段的服務(wù)分別運(yùn)行在端口 8001 和 8002 上,生成階段的服務(wù)則分別在端口 8003 和 8004 上。分離式服務(wù)器監(jiān)聽端口 8000,用于接收客戶端請(qǐng)求,并在上下文與生成階段之間進(jìn)行調(diào)度。
# Launching context servers trtllm-serve TinyLlama/TinyLlama-1.1B-Chat-v1.0--host localhost --port8001--kv_cache_free_gpu_memory_fraction0.15&> output_ctx0 & trtllm-serve TinyLlama/TinyLlama-1.1B-Chat-v1.0--host localhost --port8002--kv_cache_free_gpu_memory_fraction0.15&> output_ctx1 & # Launching generation servers trtllm-serve TinyLlama/TinyLlama-1.1B-Chat-v1.0--host localhost --port8003--kv_cache_free_gpu_memory_fraction0.15&> output_gen0 & trtllm-serve TinyLlama/TinyLlama-1.1B-Chat-v1.0--host localhost --port8004--kv_cache_free_gpu_memory_fraction0.15&> output_gen1 & # Launching disaggregated server trtllm-serve disaggregated -c disagg_config.yaml
# disagg_config.yaml hostname: localhost port: 8000 context_servers: num_instances: 2 router: type: round_robin urls: -"localhost:8001" -"localhost:8002" generation_servers: num_instances: 2 urls: -"localhost:8003" -"localhost:8004"
分離式服務(wù)支持多種負(fù)載均衡策略,包括輪詢 (round-robin) 及基于 KV 緩存的路由。此外,該架構(gòu)已支持動(dòng)態(tài)擴(kuò)縮容,能夠靈活應(yīng)對(duì)不同規(guī)模的推理負(fù)載。
了解更多信息,請(qǐng)參見示例:
https://github.com/NVIDIA/TensorRT-LLM/tree/main/examples/disaggregated#trt-llm-disaggregated-serving
Dynamo
第二種方法是使用Dynamo—— 一個(gè)專為 LLM 工作負(fù)載設(shè)計(jì)的數(shù)據(jù)中心級(jí)推理服務(wù)器。Dynamo 提供了許多高級(jí)功能,包括預(yù)處理與后處理線程的解耦,特別適用于高并發(fā)場(chǎng)景。其工作流程如圖 4 所示。
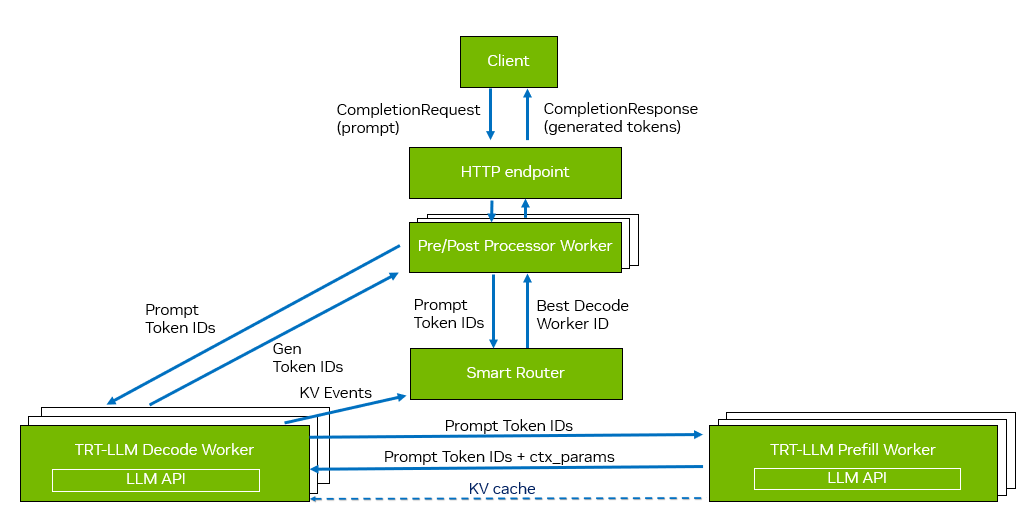
圖 4. 使用 Dynamo 進(jìn)行分離服務(wù)
在 Dynamo 的工作流程中,首先由預(yù)處理和后處理工作線程處理請(qǐng)求,隨后它們會(huì)查詢智能路由器,以確定將請(qǐng)求路由到哪個(gè)最優(yōu)的生成器。根據(jù) KV 緩存塊的可用性,生成器可能跳過上下文階段,或?qū)⒄?qǐng)求轉(zhuǎn)發(fā)至上下文工作線程。一旦上下文階段完成提示詞的處理,KV 緩存塊即可通過上圖所示的 ctx_params 元數(shù)據(jù)發(fā)送至生成階段,用于后續(xù)的 Token 生成。
Dynamo 還內(nèi)置了對(duì) Kubernetes 部署、監(jiān)測(cè)和指標(biāo)采集的支持。我們正在積極推進(jìn)動(dòng)態(tài)實(shí)例擴(kuò)展,進(jìn)一步提高其在生產(chǎn)環(huán)境中的適用性與彈性。
更多有關(guān)如何將 Dynamo 與 TensorRT-LLM 集成的信息,請(qǐng)參見此文檔:
https://docs.nvidia.com/dynamo/latest/examples/trtllm.html
Triton 推理服務(wù)
第三種方法是使用 Triton 推理服務(wù)器,通過 Triton 的 ensemble 模型實(shí)現(xiàn)分離式推理。該模型由預(yù)處理器、調(diào)度器(基于 Python BLS 后端)和后處理器組成。如圖 5 所示,調(diào)度器負(fù)責(zé)將客戶端請(qǐng)求路由至上下文和生成實(shí)例,管理提示 Token 的流轉(zhuǎn),并處理生成 Token 的返回結(jié)果。該方法依賴于 Triton 的 TensorRT-LLM 后端及其 Executor API,目前僅支持 TensorRT 后端。如需了解更多信息,請(qǐng)參閱此文檔:
https://github.com/NVIDIA/TensorRT-LLM/tree/main/triton_backend/all_models/disaggregated_serving#running-disaggregated-serving-with-triton-tensorrt-llm-backend
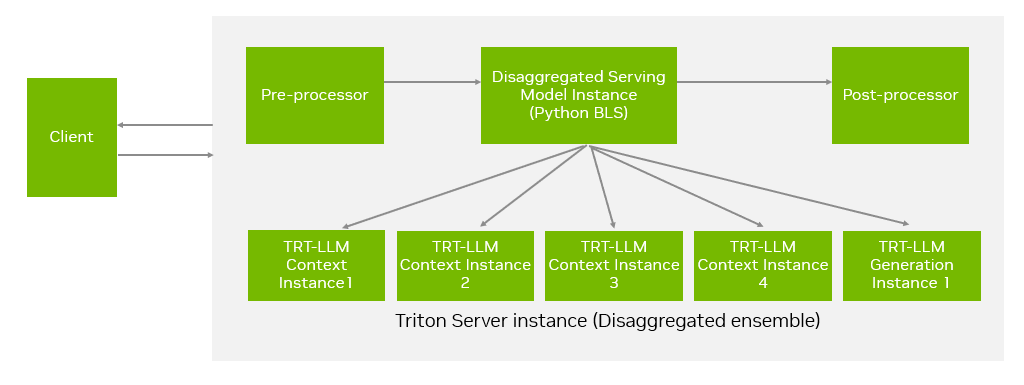
圖 5. 使用 Triton 進(jìn)行分離服務(wù)
KV 緩存?zhèn)鬏?/strong>
多后端支持
如圖 6 所示,在 TensorRT-LLM 中,KV 緩存交換模塊、KV 緩存管理器及底層通信庫(kù)采用模塊化解耦設(shè)計(jì)。KV 緩存交換模塊負(fù)責(zé)高效傳輸緩存、及時(shí)釋放緩存空間,并在交換過程中按需轉(zhuǎn)換緩存布局。目前,TensorRT-LLM 支持主流通信協(xié)議,包括 MPI、UCX 和 NIXL,其底層通信協(xié)議采用 RDMA / NVLink。我們推薦使用 UCX 和 NIXL 后端,因?yàn)樗鼈冎С謩?dòng)態(tài)擴(kuò)縮容功能,使用戶能夠根據(jù)流量需求調(diào)整負(fù)載,或在上下文和生成角色之間進(jìn)行動(dòng)態(tài)切換。
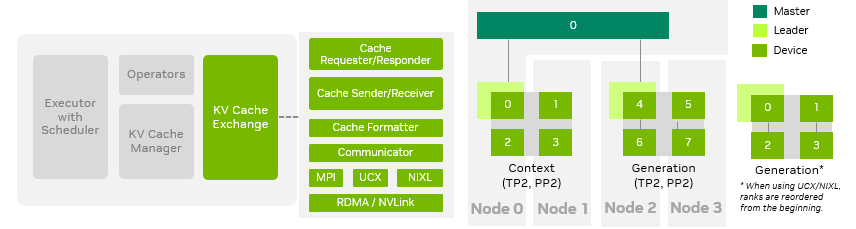
圖 6. KV 緩存交換架構(gòu)
并行優(yōu)化
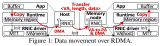
為了提高分離式服務(wù)的整體性能,TensorRT-LLM 將 KV 緩存?zhèn)鬏斉c請(qǐng)求計(jì)算過程重疊。如圖 7 所示,當(dāng)一個(gè)請(qǐng)求正在發(fā)送或接收其 KV 緩存塊時(shí),其他請(qǐng)求可以繼續(xù)進(jìn)行計(jì)算。此外,如果上下文或生成階段使用了多個(gè) GPU,不同 GPU 之間的 KV 緩存?zhèn)鬏斠部梢圆⑿羞M(jìn)行。
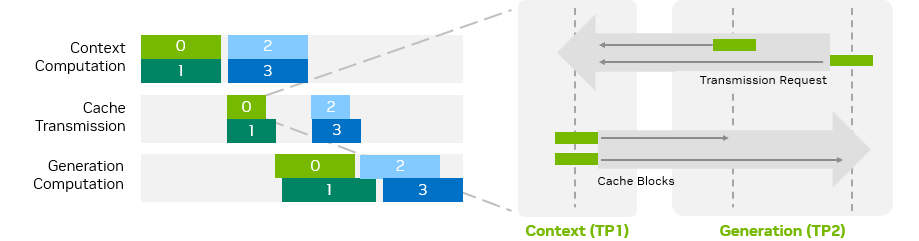
圖 7. KV 緩存交換時(shí)序圖
緩存布局轉(zhuǎn)換
為了最大限度地降低 KV 緩存?zhèn)鬏斞舆t,TensorRT-LLM 采用在設(shè)備顯存間直接傳輸緩存的方式。KV 緩存?zhèn)鬏斨С衷谏舷挛暮蜕呻A段采用不同的并行策略,此時(shí)需謹(jǐn)慎地映射兩個(gè)階段間的對(duì) KV 緩存塊布局。圖 8 通過一個(gè)示例進(jìn)行了說明:上下文階段采用 TP2 并行策略,而生成階段采用 PP2 并行策略。在這種異構(gòu)并行配置下,緩存塊的正確布局映射至關(guān)重要。
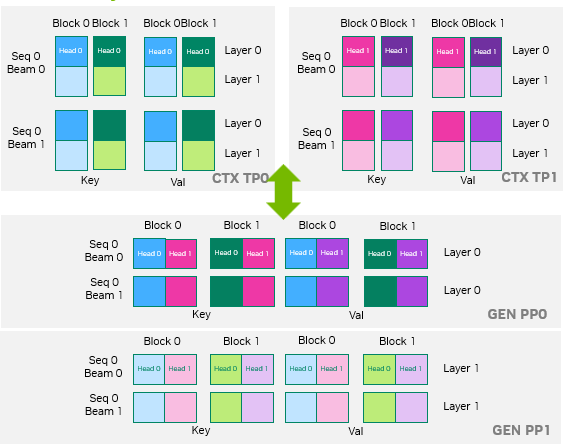
圖 8. KV 緩存布局轉(zhuǎn)換
KV 緩存?zhèn)鬏斔璧膬?yōu)化策略會(huì)因具體部署環(huán)境而異,例如單節(jié)點(diǎn)多 GPU、多節(jié)點(diǎn)多 GPU 或 不同 GPU 種類。為此,TensorRT-LLM 提供了一組環(huán)境變量,供用戶根據(jù)實(shí)際運(yùn)行環(huán)境靈活選擇和配置,以實(shí)現(xiàn)最佳性能。詳情請(qǐng)參見此文檔:
https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/advanced/disaggregated-service.md
性能分析
測(cè)量方案
如果要生成 LLM 分離服務(wù)的性能曲線,需全面覆蓋并行化策略的組合,比如 TP(張量并行)、EP(專家并行)、DP(數(shù)據(jù)并行)、PP(流水線并行),以及其他優(yōu)化方法,如投機(jī)采樣(例如 MTP)。這些組合必須分別在上下文階段和生成階段進(jìn)行評(píng)估。隨著上下文 (CTX) 和生成 (GEN) 服務(wù)器數(shù)量的增加,可能的配置數(shù)量呈指數(shù)級(jí)增長(zhǎng),評(píng)估復(fù)雜度也隨之提升。
為了確定最佳配置,我們將測(cè)量過程分為兩步:
速率匹配
測(cè)量上下文服務(wù)器的請(qǐng)求吞吐量(以請(qǐng)求數(shù) / 秒 / GPU 為單位),針對(duì)滿足 TTFT 約束的不同 TP / EP / DP / PP 映射,選擇最優(yōu)配置。
針對(duì)不同的 TP / EP / DP / PP 映射、并發(fā)級(jí)別,以及投機(jī)采樣開關(guān)的情況,測(cè)量生成服務(wù)器的總吞吐量(以Token/ 秒為單位)和延遲(以Token/ 秒 /用戶為單位)。
確定上下文服務(wù)器與生成服務(wù)器的比例,使得在給定工作負(fù)載的輸入序列長(zhǎng)度 (ISL) 和輸出序列長(zhǎng)度 (OSL) 下,上下文服務(wù)器的總吞吐量與生成服務(wù)器的總吞吐量相匹配。
使用以下公式計(jì)算每個(gè) GPU 的吞吐量:

一旦計(jì)算出上下文與生成服務(wù)器的最佳比例,即可構(gòu)建“速率匹配”帕累托曲線 (Pareto curve),以便在不同延遲(Token / 秒 / 用戶)下識(shí)別最佳配置。
端到端性能測(cè)量
在考慮可用 GPU 總數(shù)量的實(shí)際限制的前提下,對(duì)最具優(yōu)勢(shì)的配置進(jìn)行trtllm-serve分離式部署的基準(zhǔn)測(cè)試。
DeepSeek R1
我們?cè)?ISL 和 OSL 不同的數(shù)據(jù)集上對(duì) DeepSeek R1 進(jìn)行了性能測(cè)試。以下所有實(shí)驗(yàn)均在 NVIDIA GPU 上進(jìn)行。
ISL 4400 - OSL 1200(機(jī)器翻譯數(shù)據(jù)集)
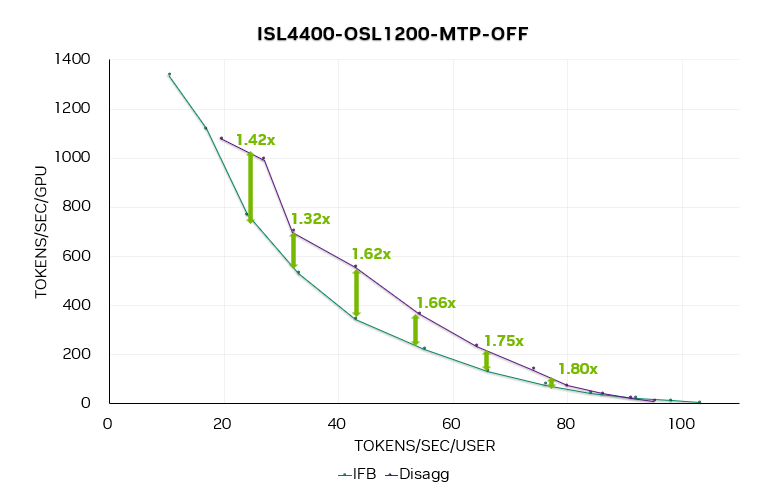
圖 9. 關(guān)閉 MTP 時(shí)的 DeepSeek R1“速率匹配”帕累托曲線
圖 9 是 DeepSeek R1 在關(guān)閉 MTP 時(shí)的速率匹配帕累托曲線。該曲線考慮了 ADP 和 ATP 配置,每個(gè)實(shí)例使用 4、8、16 或 32 個(gè) GPU。分離式實(shí)現(xiàn)的加速比為1.4 至 1.8 倍,尤其在低并發(fā)水平下效果更為顯著。
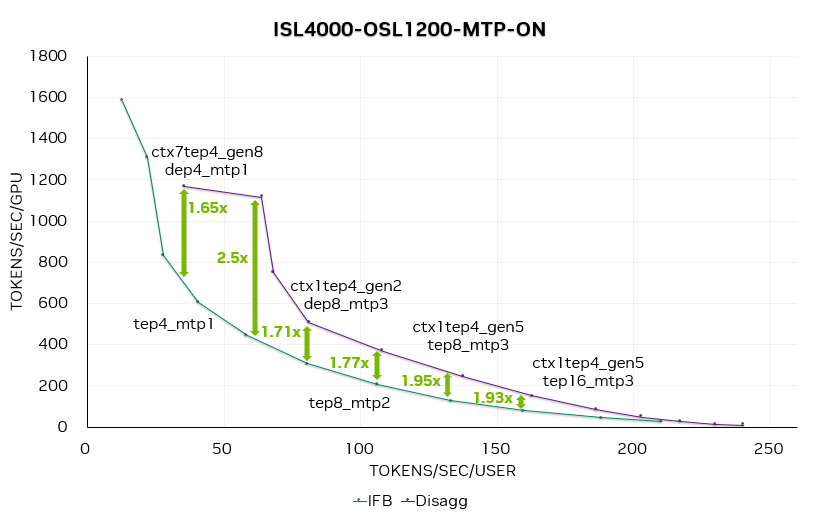
圖 10. 啟用 MTP 時(shí)的 DeepSeek R1 帕累托曲線
我們?cè)谛阅芮€中選取一些數(shù)據(jù)點(diǎn)標(biāo)注了上下文 / 生成實(shí)例的數(shù)量和并行策略。例如,CTX=1xTEP-4|GEN=2xDEP-8表示由 1 個(gè) TEP4 上下文實(shí)例和 2 個(gè) DEP8 生成實(shí)例組成一個(gè)完整的 LLM 處理實(shí)例。
如圖 10 所示,啟用 MTP 后,分離式服務(wù)相較于聚合式服務(wù)的加速比進(jìn)一步提升,平均比關(guān)閉 MTP 時(shí)高出 20% 至 30%。
ISL 8192 - OSL 256(合成數(shù)據(jù)集)
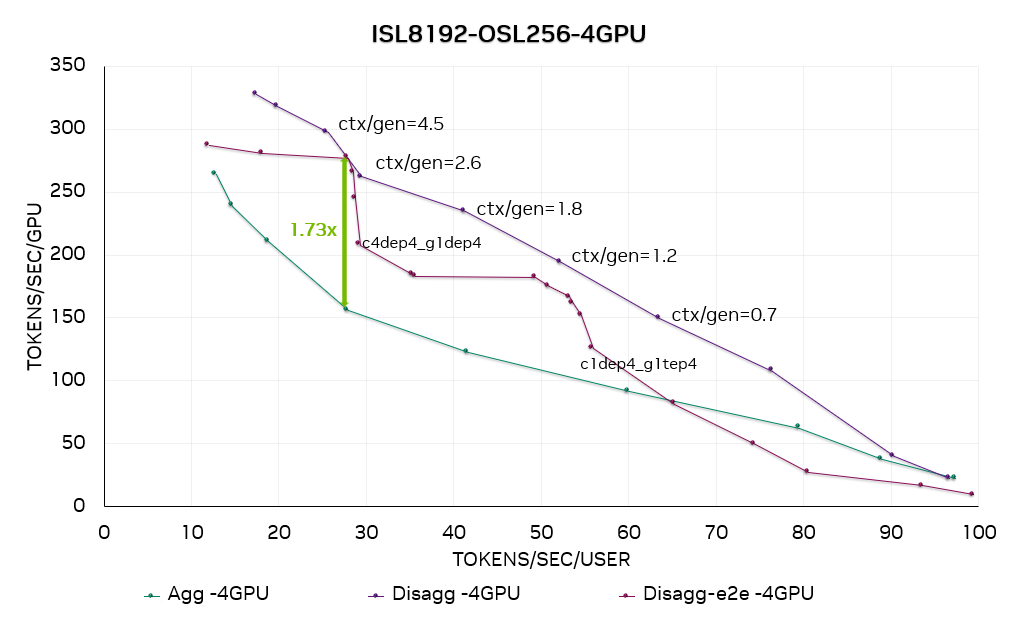
圖 11. DeepSeek R1 4-GPU 帕累托曲線。ctx/gen=4.5 表示上下文與生成階段的 SOL 速率匹配,該配置僅用于 SOL 性能收集。c4dep4_g1dep4 表示 4 個(gè) DEP4 上下文實(shí)例加上 1 個(gè) DEP4 生成實(shí)例組成一個(gè)完整的 LLM 服務(wù)實(shí)例。
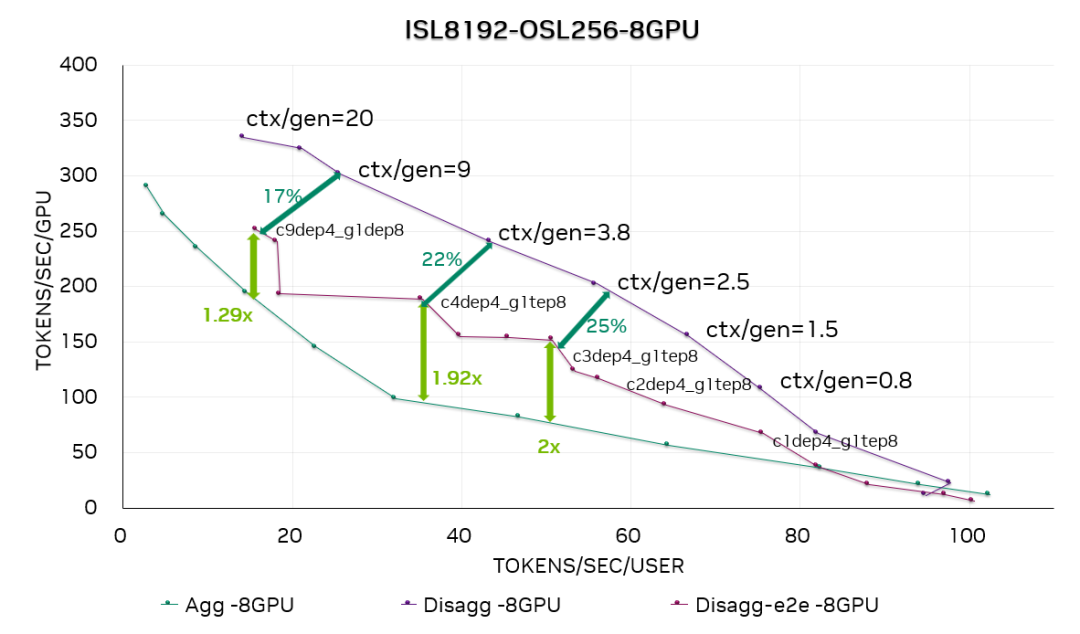
圖 12. DeepSeek R1 8-GPU 帕累托曲線
圖 11 和圖 12 分別是在每個(gè)生成實(shí)例使用 4 個(gè) GPU (GEN4) 和 8 個(gè)GPU (GEN8) 的情況下,在 DeepSeek R1 上運(yùn)行 ISL8192-OSL256 數(shù)據(jù)集的性能曲線。我們同時(shí)繪制了分離式服務(wù)的“速率匹配”結(jié)果(基于上下文與生成階段之間的理想速率匹配)和端到端結(jié)果(用戶可在生產(chǎn)部署環(huán)境中直接復(fù)現(xiàn)該結(jié)果)。
結(jié)果顯示,在此 ISL / OSL 設(shè)置下,分離服務(wù)的性能明顯優(yōu)于合并服務(wù)——在 GEN4 配置下加速比最高可達(dá)1.73 倍,GEN8 配置下最高可達(dá)2 倍。
通過將分離式服務(wù)的端到端結(jié)果與“速率匹配”曲線進(jìn)行比較,我們觀察到性能差距在 0%–25% 之間。這種差異是符合預(yù)期的,因?yàn)?SOL 性能依賴于理想化假設(shè),例如 ctx:gen 比例極小、KV 緩存?zhèn)鬏敳划a(chǎn)生開銷等。
ISL 4096 - OSL 1024(機(jī)器翻譯數(shù)據(jù)集)
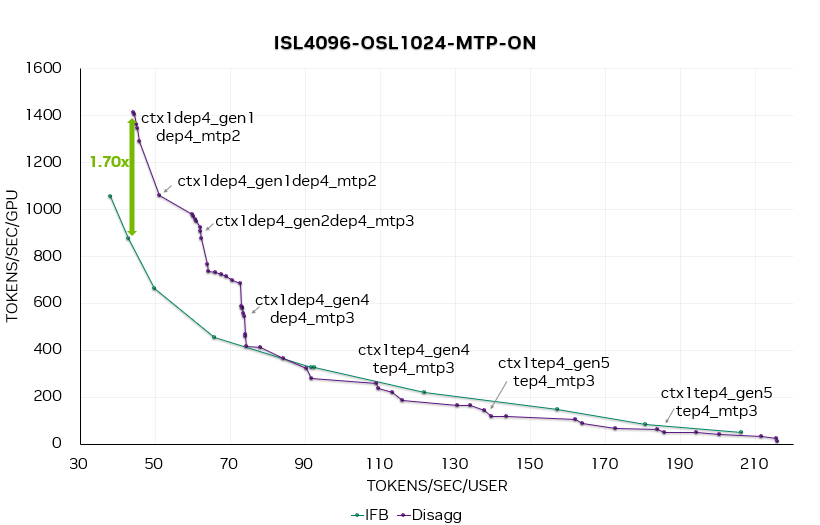
圖 13. DeepSeek R1 端到端帕累托曲線,MTP = 1、2、3。在此圖中,ctx1dep4-gen2dep4-mtp3 表示 1 個(gè) DEP4 上下文實(shí)例加 2 個(gè) DEP4 生成實(shí)例,且 MTP = 3。
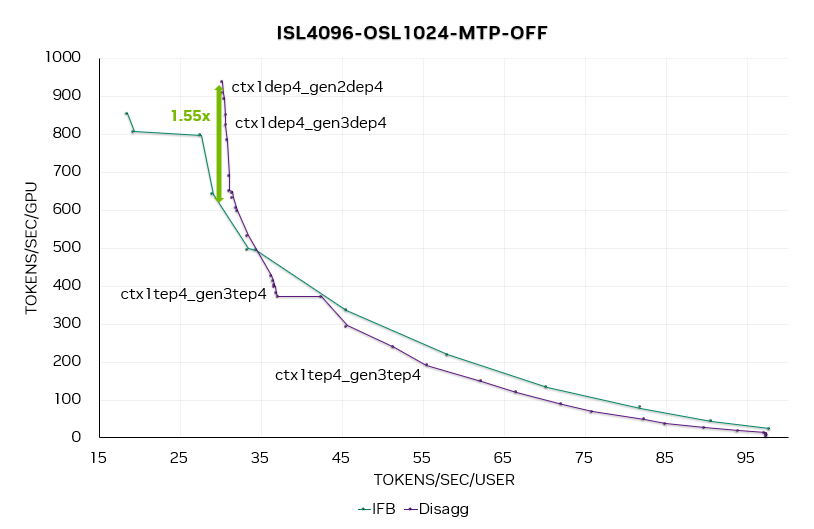
圖 14. 關(guān)閉 MTP 時(shí)的 DeepSeek R1 端到端帕累托曲線
圖 13 和 14 分別為合并服務(wù)和分離服務(wù)在開關(guān) MTP 時(shí)的端到端帕累托曲線。
在 MTP = 1、2、3 的帕累托曲線上,可以觀察到,在 50 Token / 秒 / 用戶(20 毫秒延遲)時(shí),分離服務(wù)的性能提升達(dá)1.7 倍。隨著并發(fā)度的提高,啟用 MTP 能夠帶來更大的性能收益。
Qwen 3
ISL 8192 - OSL 1024(機(jī)器翻譯數(shù)據(jù)集)
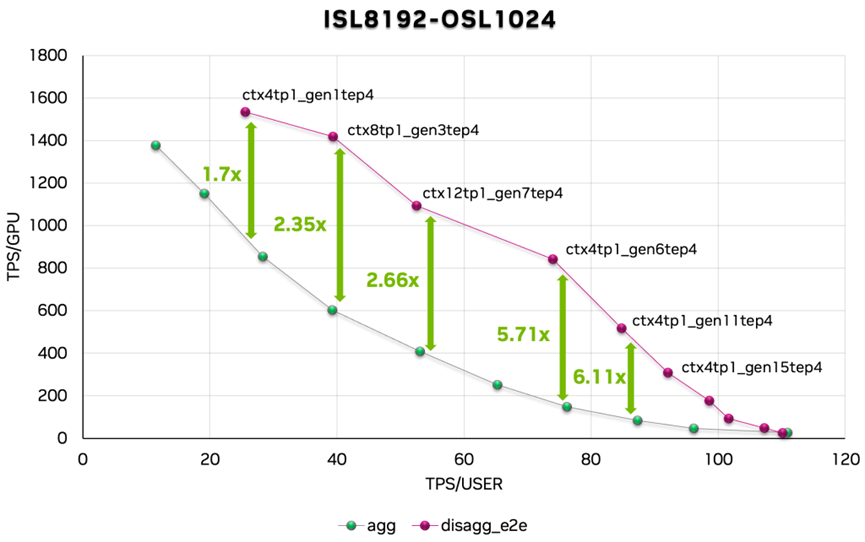
圖 15. Qwen 3 帕累托曲線
我們還對(duì) Qwen 3 進(jìn)行了性能評(píng)估。數(shù)據(jù)顯示,分離服務(wù)實(shí)現(xiàn)的加速比在 1.7 至 6.11 倍之間。
性能復(fù)現(xiàn)
我們提供了一組腳本用于復(fù)現(xiàn)本論文中展示的性能數(shù)據(jù)。請(qǐng)參見此文檔中的使用說明:
https://github.com/NVIDIA/TensorRT-LLM/tree/main/examples/disaggregated/slurm
工作展望
我們已經(jīng)通過使用 TensorRT-LLM 進(jìn)行 LLM 分離式推理獲得了性能優(yōu)勢(shì),我們還將會(huì)進(jìn)一步提高性能和易用性,所需的工作包括:
提供詳細(xì)的步驟和腳本,以自動(dòng)化生成用于比較聚合式與分離服務(wù)的吞吐量-延遲性能曲線。
繼續(xù)提升大規(guī)模部署場(chǎng)景下的性能(如大規(guī)模 EP)。
支持根據(jù)流量負(fù)載動(dòng)態(tài)調(diào)整上下文和生成實(shí)例。
支持按層計(jì)算傳輸KV 緩存。
致謝
在 TensorRT-LLM 中增加分離式服務(wù)支持是一個(gè)典型的跨團(tuán)隊(duì)協(xié)作項(xiàng)目,需要在內(nèi)核級(jí)優(yōu)化、運(yùn)行時(shí)增強(qiáng)以及系統(tǒng)化性能分析與調(diào)優(yōu)等方面緊密配合。我們?yōu)檫@支敬業(yè)樂群的工程師團(tuán)隊(duì)感到驕傲,正是他們深厚的專業(yè)知識(shí)大幅提升了 TensorRT-LLM 的整體性能。除本文作者外,我們誠(chéng)摯感謝 Iman Tabrizian、張順康、段政和網(wǎng)絡(luò)團(tuán)隊(duì)等同事為項(xiàng)目所作的代碼貢獻(xiàn)。通過此次協(xié)作,團(tuán)隊(duì)在進(jìn)一步提升大語(yǔ)言模型推理的 GPU 利用率方面積累了寶貴經(jīng)驗(yàn)。我們希望本文能夠?yàn)?a target="_blank">開發(fā)者社區(qū)提供有益參考,助力大家在關(guān)鍵 LLM 推理應(yīng)用中更充分地釋放 NVIDIA GPU 的潛力。
關(guān)于作者
Patrice Castonguay
NVIDIA TensorRT-LLM 的首席軟件工程師,擁有計(jì)算流體力學(xué) (CFD) 背景。他長(zhǎng)期領(lǐng)導(dǎo)開發(fā)面向稀疏線性代數(shù)、語(yǔ)音識(shí)別、語(yǔ)音合成及大型語(yǔ)言模型的 GPU 加速庫(kù)。并擁有斯坦福大學(xué)航空航天學(xué)博士學(xué)位。
陳曉明
NVIDIATensorRT-LLM 性能團(tuán)隊(duì)的首席架構(gòu)師和高級(jí)經(jīng)理,對(duì)深度學(xué)習(xí)模型的算法軟硬件協(xié)同設(shè)計(jì)感興趣,最近在做大語(yǔ)言模型推理的性能建模、分析和優(yōu)化。
石曉偉
NVIDIA 軟件工程師,目前主要參與 TensorRT-LLM 框架開發(fā)及性能優(yōu)化。
朱闖
NVIDIA 軟件工程師,目前主要從事 TensorRT-LLM 大語(yǔ)言模型的推理優(yōu)化。
喬顯杰
NVIDIA Compute Arch 部門高級(jí)架構(gòu)師, 主要負(fù)責(zé) LLM 推理的性能評(píng)估和優(yōu)化。加入 NVIDIA 之前,他曾從事推薦系統(tǒng)的 GPU 加速研發(fā)工作。
Jatin Gangani
NVIDIA 深度學(xué)習(xí)計(jì)算團(tuán)隊(duì)的高級(jí)計(jì)算架構(gòu)師,專注于提升數(shù)據(jù)中心中 AI 推理的軟硬件性能。他近期的工作重點(diǎn)是優(yōu)化 TensorRT-LLM 軟件的性能表現(xiàn)。擁有北卡羅來納州立大學(xué)計(jì)算機(jī)工程碩士學(xué)位。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5665瀏覽量
109977 -
gpu
+關(guān)注
關(guān)注
28文章
5227瀏覽量
135853 -
模型
+關(guān)注
關(guān)注
1文章
3778瀏覽量
52195 -
LLM
+關(guān)注
關(guān)注
1文章
348瀏覽量
1370
原文標(biāo)題:TensorRT-LLM 中的分離式服務(wù)
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
DeepSeek R1 MTP在TensorRT-LLM中的實(shí)現(xiàn)與優(yōu)化

TensorRT-LLM初探(一)運(yùn)行l(wèi)lama
使用NVIDIA Triton和TensorRT-LLM部署TTS應(yīng)用的最佳實(shí)踐

如何在魔搭社區(qū)使用TensorRT-LLM加速優(yōu)化Qwen3系列模型推理部署
分離式液位傳感器代替浮球傳感器的優(yōu)勢(shì)
分離式熱管換熱器的綜合利用
分離式獨(dú)立按鍵電路原理圖免費(fèi)下載

可直接訪問的分離式內(nèi)存DirectCXL應(yīng)用案例
現(xiàn)已公開發(fā)布!歡迎使用 NVIDIA TensorRT-LLM 優(yōu)化大語(yǔ)言模型推理

魔搭社區(qū)借助NVIDIA TensorRT-LLM提升LLM推理效率
TensorRT-LLM低精度推理優(yōu)化

NVIDIA TensorRT-LLM Roadmap現(xiàn)已在GitHub上公開發(fā)布

解鎖NVIDIA TensorRT-LLM的卓越性能
在NVIDIA TensorRT-LLM中啟用ReDrafter的一些變化

TensorRT-LLM的大規(guī)模專家并行架構(gòu)設(shè)計(jì)




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論