 SL1680 SoC本地運行DeepSeek R1 1.5B大模型
SL1680 SoC本地運行DeepSeek R1 1.5B大模型

SL1680 SoC本地運行DeepSeek R1 1.5B大模型
自DeepSeek大模型發布以來,深蕾半導體SoC團隊針對在端側運行DeepSeek大模型不斷進行研究,探索將DeepSeek大模型與SoC系列產品相結合的模式。目前已經實現利用深蕾半導體的ASTRA SL1680 SoC本地運行DeepSeek R1 Distill Qwen2.5 1.5B大模型。
DeepSeek R1 Distill Qwen2.5 1.5B是DeepSeek R1發布中最小的模型 - 它可以在ASTRA SL1680上舒適地運行。
一、SL1680本地運行Deepseek-R1-1.5B大模型展示
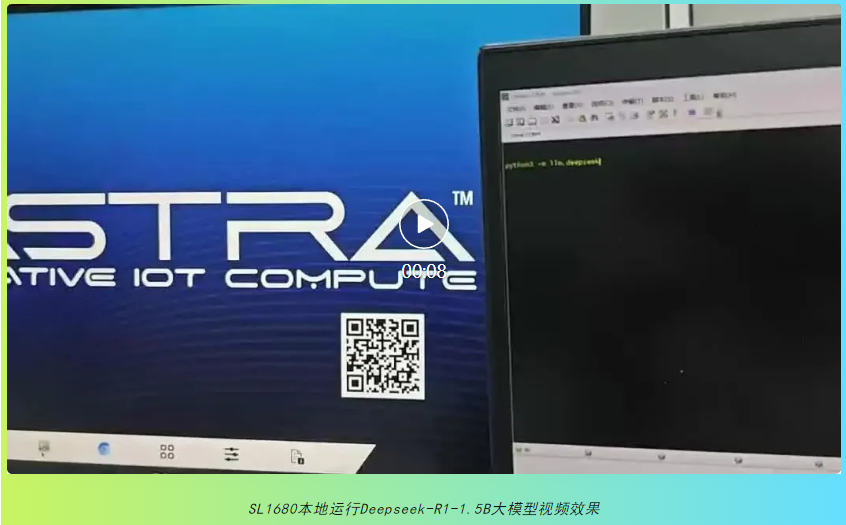
SL1680本地運行Deepseek-R1-1.5B大模型視頻效果
執行過程
要在ASTRA開發板上運行Qwen,我們將使用llama-cpp-python包,它為Georgi Gerganov的llamacpp提供了便捷的Python綁定。
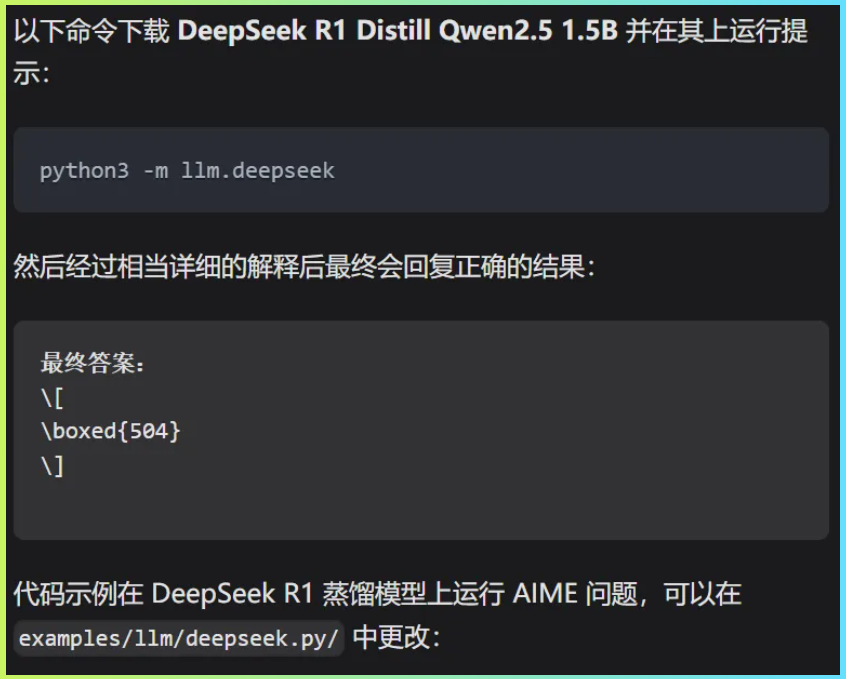
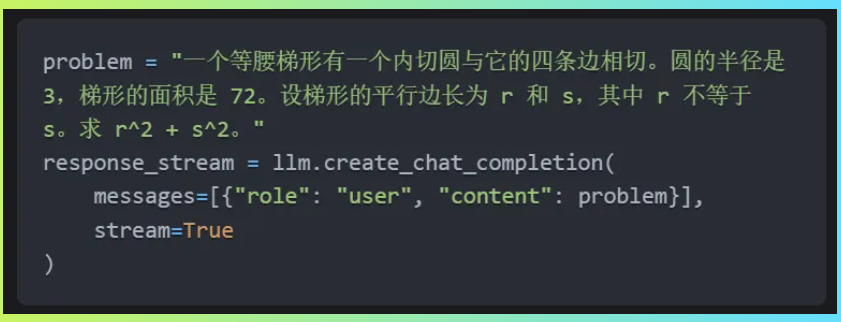
除了在SL1680本地運行Deepseek-R1-1.5B大模型,還實現了運行Llama 3.2 1B大模型。
運行環境
系統:Linux(yocto)
硬件:SL1680 RDK開發板
產品化路徑
對于SL1680產品如何與大模型結合的問題,建議采用端側大模型與云端大模型相結合的工程化方式處理,本地能處理的用戶任務使用端側大模型快速解決和輸出,而較復雜的邏輯以及聯網功能則通過請求云端大模型API的方式實現。
如視頻所展示的,將Deepseek-R1-1.5B大模型部署到SoC本地,能夠實現知識問答、FuntionCall等AI能力。通過將云端的大模型與端側的語音識別、機器視覺功能、端側小參數大模型相結合,從而讓AI賦能我們的產品,提升產品的智能化程度。
二、本地小參數大模型與端云大模型結合的應用場景
1,多媒體終端:本地小參數大模型可在端側如智能大屏,快速處理一些常見的簡單任務,如語音助手對常見指令的快速響應、文本的簡單摘要生成、數據加工整理、設備操控、產品說明、產品售后問題自助解決等。當遇到復雜任務,如深度文本分析、多模態內容生成時,可將任務發送到云側大模型進行處理,利用云側大模型強大的計算能力和豐富的知識儲備來完成。
2,智能辦公設備(MINI PC):本地小參數大模型可以實時處理用戶的語音交互、文字輸入信息處理、智能控制等任務,作為用戶AI助手。而對于一些復雜的邏輯理解、內容生成設計和決策任務等,則借助云側大模型的強大算力和更全面的數據分析能力來完成。
3,零售電商:在商品展示平臺的搜索推薦場景中,本地小參數大模型可以根據用戶在本地設備上的瀏覽歷史、購買行為、環境感知等數據,快速生成初步的推薦結果。當用戶有更復雜的搜索需求,如對比不同商品的詳細參數、詢問商品的使用場景等問題時,云側大模型可以利用其龐大的商品知識庫和強大的語言理解能力,給出更準確、詳細的回答和推薦。
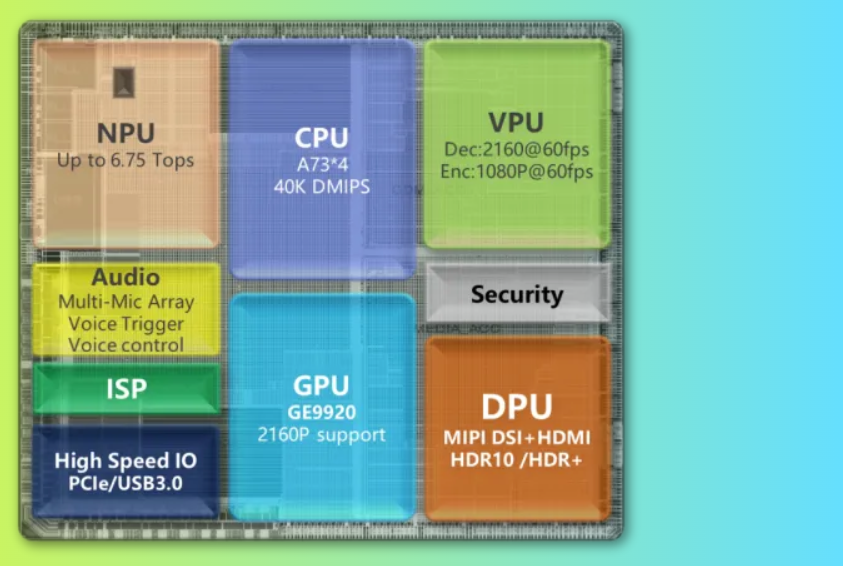
三、ASTRA SL1680 SoC介紹
ASTRA SL1680是一款專為智能應用設計的高性能系統級芯片(SoC),它擁有
Cortex A73是ARM公司設計的一款高性能CPU核心,適用于需要高性能計算的應用場景,能夠提供強大的處理能力和多任務處理能力,為Deepseek-R1-1.5B大模型的運行提供堅實保障。
2,高達7.9 Top NPU算力:
NPU(Neural Processing Unit,神經網絡處理單元)是專門用于加速神經網絡計算的硬件單元。7.9 Top的算力使SL1680在神經網絡計算方面有著極高的性能,為端云結合的應用模式創造了有利條件。
3,64-bit高速內存:
64位內存架構支持更大的內存尋址空間,使得SL1680能夠同時處理更多的數據和運行更復雜的應用程序。高速內存則保證了數據訪問的迅速性,提升了整體性能。
審核編輯 黃宇
-
soc
+關注
關注
40文章
4599瀏覽量
229635 -
大模型
+關注
關注
2文章
3710瀏覽量
5229 -
DeepSeek
+關注
關注
2文章
837瀏覽量
3345
發布評論請先 登錄
基于合眾恒躍rk3576?開發板deepseek-r1-1.5b/7b 部署指南

貿澤開售適用于消費電子和工業應用的 Synaptics全新SL1680嵌入式物聯網處理器

廣和通成功部署DeepSeek-R1-0528-Qwen3-8B模型
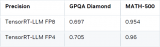
DeepSeek R1 MTP在TensorRT-LLM中的實現與優化

如何在NVIDIA Blackwell GPU上優化DeepSeek R1吞吐量
速看!EASY-EAI教你離線部署Deepseek R1大模型

【VisionFive 2單板計算機試用體驗】3、開源大語言模型部署
【「DeepSeek 核心技術揭秘」閱讀體驗】書籍介紹+第一章讀后心得
DeepSeek開源新版R1 媲美OpenAI o3


【幸狐Omni3576邊緣計算套件試用體驗】CPU部署DeekSeek-R1模型(1B和7B)
DeepSeek R1模型本地部署與產品接入實操



 工商網監
工商網監
評論