") 詳解RAD端到端強(qiáng)化學(xué)習(xí)后訓(xùn)練范式
詳解RAD端到端強(qiáng)化學(xué)習(xí)后訓(xùn)練范式

RAD
端到端智駕強(qiáng)化學(xué)習(xí)后訓(xùn)練范式
受限于算力和數(shù)據(jù),大語言模型預(yù)訓(xùn)練的 scalinglaw 已經(jīng)趨近于極限。DeepSeekR1/OpenAl01通過強(qiáng)化學(xué)習(xí)后訓(xùn)練涌現(xiàn)了強(qiáng)大的推理能力,掀起新一輪技術(shù)革新。當(dāng)下主流的端到端智駕模型采用模仿學(xué)習(xí)訓(xùn)練范式,即從大量的人類駕駛數(shù)據(jù)中擬合類人的駕駛策略。與大語言模型預(yù)訓(xùn)練范式相對應(yīng),模仿學(xué)習(xí)的 scaling law 也將觸及瓶頸,其上限是人類的駕駛水平,難以實現(xiàn)遠(yuǎn)超人類的高階自動駕駛。此外,模仿學(xué)習(xí)天然存在因果混淆和開環(huán)閉環(huán)差異性兩方面的局限性,其下限(安全性和穩(wěn)定性)也難以保證。
我們提出端到端強(qiáng)化學(xué)習(xí)后訓(xùn)練范式 RAD(ReinforcedAutonomous Driving),基于 3DGS 技術(shù)構(gòu)建真實物理世界的孿生數(shù)字世界,讓端到端模型在數(shù)字世界中控制車輛行駛,像人類駕駛員一樣不斷地與環(huán)境交互并獲得反饋,基于安全性相關(guān)的獎勵函數(shù),通過強(qiáng)化學(xué)習(xí)微調(diào)引導(dǎo)模型建模物理世界的因果關(guān)系。強(qiáng)化學(xué)習(xí)和模仿學(xué)習(xí)天然地互補(bǔ),在模仿學(xué)習(xí)scalinglaw 的基礎(chǔ)上,強(qiáng)化學(xué)習(xí)scaling law 將進(jìn)一步拓展端到端智駕模型的能力邊界。
項目主頁:https://hgao-cv.github.io/RAD 論文地址:https://arxiv.org/pdf/2502.13144
概述
受限于算力和數(shù)據(jù),大語言模型預(yù)訓(xùn)練的scaling law已經(jīng)趨近于極限。DeepSeek R1 / OpenAI o1 通過強(qiáng)化學(xué)習(xí)后訓(xùn)練涌現(xiàn)了強(qiáng)大的推理能力,掀起新一輪技術(shù)革新。當(dāng)下主流的端到端智駕模型采用模仿學(xué)習(xí)訓(xùn)練范式,即從大量的人類駕駛數(shù)據(jù)中擬合類人的駕駛策略。與大語言模型預(yù)訓(xùn)練范式相對應(yīng),模仿學(xué)習(xí)的scaling law也將觸及瓶頸,其上限是人類的駕駛水平,難以實現(xiàn)遠(yuǎn)超人類的高階自動駕駛。此外,模仿學(xué)習(xí)天然存在因果混淆和開環(huán)閉環(huán)差異性兩方面的局限性,其下限(安全性和穩(wěn)定性)也難以保證。我們提出端到端強(qiáng)化學(xué)習(xí)后訓(xùn)練范式RAD(Reinforced Autonomous Driving),基于3DGS技術(shù)構(gòu)建真實物理世界的孿生數(shù)字世界,讓端到端模型在數(shù)字世界中控制車輛行駛,像人類駕駛員一樣不斷地與環(huán)境交互并獲得反饋,基于安全性相關(guān)的獎勵函數(shù),通過強(qiáng)化學(xué)習(xí)微調(diào)引導(dǎo)模型建模物理世界的因果關(guān)系。強(qiáng)化學(xué)習(xí)和模仿學(xué)習(xí)天然地互補(bǔ),在模仿學(xué)習(xí)scaling law的基礎(chǔ)上,強(qiáng)化學(xué)習(xí)scaling law將進(jìn)一步拓展端到端智駕模型的能力邊界。
模仿學(xué)習(xí)的局限性:因果混淆與開環(huán)閉環(huán)差異
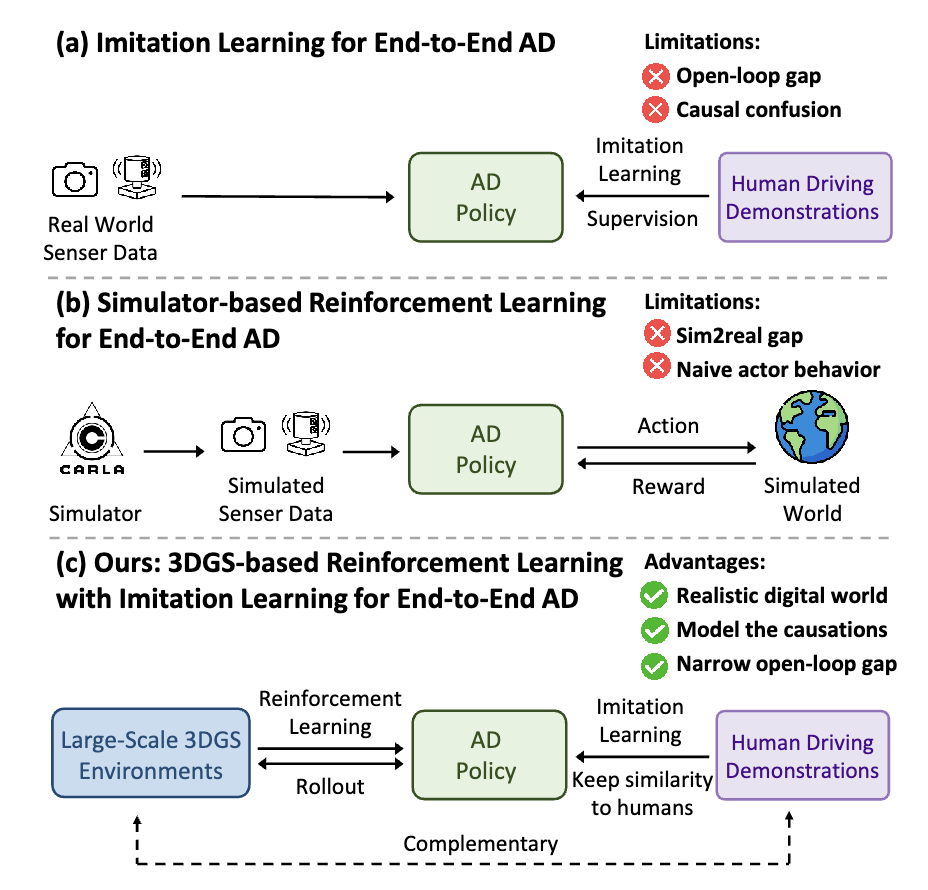
因果混淆(causal confusion)是模仿學(xué)習(xí)訓(xùn)練范式的一大痛點。模仿學(xué)習(xí)的本質(zhì)是使神經(jīng)網(wǎng)絡(luò)模仿人類駕駛員的駕駛策略,其優(yōu)化目標(biāo)是最小化預(yù)測軌跡與專家軌跡之間的差異。模仿學(xué)習(xí)建模的是環(huán)境信息和規(guī)劃軌跡之間的相關(guān)性而非因果關(guān)系,容易造成因果混淆的問題。特別是對于端到端自動駕駛而言,輸入的環(huán)境信息尤為豐富,很難從高維度信息中找出導(dǎo)致規(guī)劃結(jié)果的真實原因,容易導(dǎo)致捷徑學(xué)習(xí)(shortcut learning),例如,從歷史軌跡外推未來軌跡。此外,由于訓(xùn)練集主要由常見的駕駛行為主導(dǎo),在僅使用模仿學(xué)習(xí)訓(xùn)練的情況下,導(dǎo)致對駕駛的安全性不夠敏感。
另外,開環(huán)訓(xùn)練和閉環(huán)部署之間的差距,也是模仿學(xué)習(xí)訓(xùn)練范式難以忽視的問題。模仿學(xué)習(xí)是基于良好的分布內(nèi)駕駛數(shù)據(jù)以開環(huán)方式進(jìn)行訓(xùn)練,但真實世界的駕駛系統(tǒng)是一個閉環(huán)系統(tǒng),開環(huán)與閉環(huán)間存在極大的差異。在閉環(huán)中,單步的微小軌跡誤差會隨時間累積,導(dǎo)致駕駛系統(tǒng)進(jìn)入一個偏離訓(xùn)練集分布的場景。僅經(jīng)過開環(huán)訓(xùn)練的駕駛策略在面對訓(xùn)練集分布外的場景時往往會失效。
RAD訓(xùn)練范式
RAD基于3DGS技術(shù)構(gòu)建真實物理世界的孿生數(shù)字世界,讓端到端模型在數(shù)字世界中控制車輛行駛,像人類駕駛員一樣不斷地與環(huán)境交互并獲得反饋,充分地探索狀態(tài)空間,學(xué)習(xí)應(yīng)對各種復(fù)雜和罕見的分布外場景,基于安全性相關(guān)的獎勵函數(shù),通過強(qiáng)化學(xué)習(xí)微調(diào)讓模型對安全性保持敏感,并建模物理世界的因果關(guān)系。
(1)三階段訓(xùn)練架構(gòu)
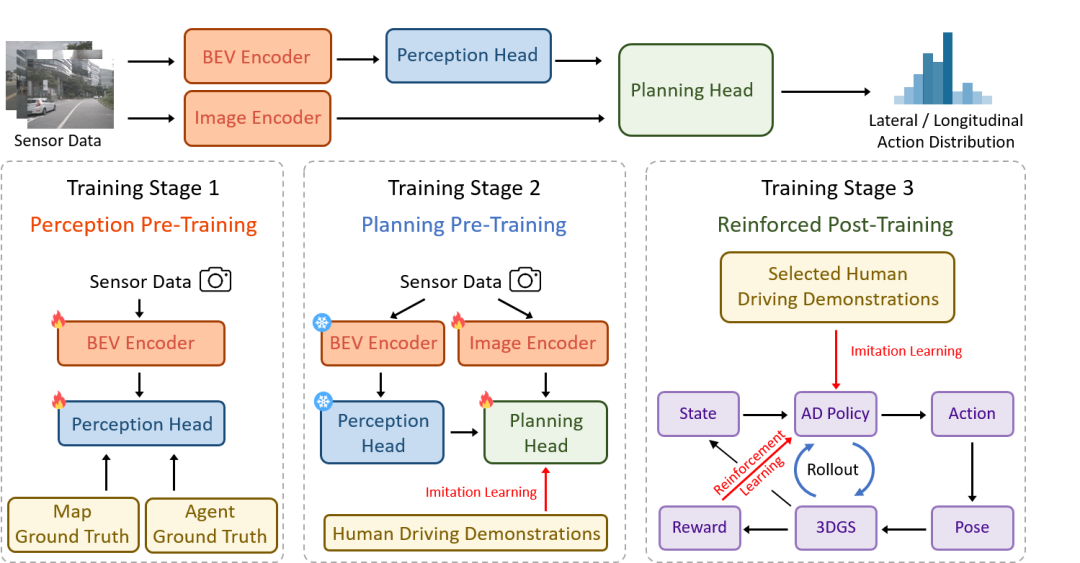
RAD 采用三階段訓(xùn)練范式。在感知預(yù)訓(xùn)練階段,通過監(jiān)督學(xué)習(xí)的方式,訓(xùn)練模型識別駕駛場景的關(guān)鍵元素,建立對周圍環(huán)境的準(zhǔn)確認(rèn)知;規(guī)劃預(yù)訓(xùn)練階段,利用大規(guī)模的真實世界駕駛示范數(shù)據(jù),通過模仿學(xué)習(xí)來初始化動作的概率分布,避免強(qiáng)化學(xué)習(xí)訓(xùn)練的冷啟動問題;在強(qiáng)化后訓(xùn)練階段,強(qiáng)化學(xué)習(xí)和模仿學(xué)習(xí)協(xié)同對策略進(jìn)行微調(diào)。強(qiáng)化學(xué)習(xí)主要負(fù)責(zé)引導(dǎo)策略建模物理世界的因果關(guān)系和適應(yīng)分布外的場景;模仿學(xué)習(xí)作為正則,約束與人類駕駛行為相似性。
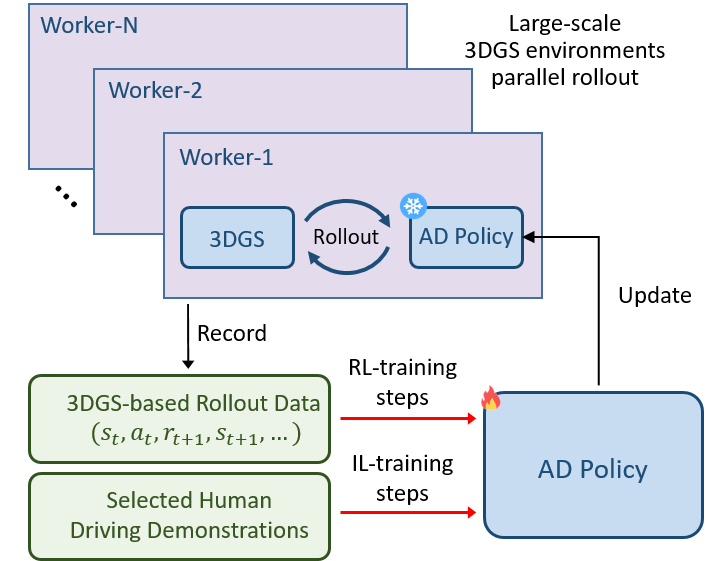
(2)安全導(dǎo)向的獎勵函數(shù)設(shè)計
為了確保自動駕駛汽車在行駛過程中的安全性,RAD 設(shè)計了專門的獎勵機(jī)制。這個機(jī)制主要關(guān)注四個方面:碰撞動態(tài)障礙物、碰撞靜態(tài)障礙物、與專家軌跡的位置偏差和航向偏差。一旦出現(xiàn)不安全的駕駛行為,比如碰撞或者偏離專家軌跡,就會觸發(fā)相應(yīng)的懲罰獎勵。通過這種方式,引導(dǎo)策略有效地應(yīng)對關(guān)鍵安全事件,讓自動駕駛汽車在訓(xùn)練過程中逐漸學(xué)會如何避免危險,更好地理解現(xiàn)實世界中的因果關(guān)系。
(3)策略優(yōu)化與輔助目標(biāo)設(shè)計
為了提高訓(xùn)練效率和效果,RAD將動作解耦為橫向動作和縱向動作,在 0.5 秒的短時間范圍內(nèi)構(gòu)建動作空間,有效降低了動作空間的維度,加快了訓(xùn)練的收斂速度。此外,在策略優(yōu)化方面,RAD 使用廣義優(yōu)勢估計(GAE)來傳播獎勵,優(yōu)化前面步驟的動作分布。考慮到動作空間的解耦,將獎勵和價值函數(shù)也進(jìn)行解耦,分別計算橫向和縱向的優(yōu)勢估計,并根據(jù)近端策略優(yōu)化(PPO)來微調(diào)策略。
同時,針對強(qiáng)化學(xué)習(xí)中常見的稀疏獎勵問題,RAD 引入了輔助目標(biāo)。這些輔助目標(biāo)基于動態(tài)碰撞、靜態(tài)碰撞、位置偏差和航向偏差等多種獎勵源設(shè)計,能夠?qū)εf策略選擇的動作進(jìn)行評估,并通過調(diào)整動作概率分布來懲罰不良行為。例如,當(dāng)前方存在潛在碰撞風(fēng)險時,系統(tǒng)會降低加速動作的概率,并提升減速或制動的概率;當(dāng)車輛偏離預(yù)定軌跡向左偏移時,則增加向右修正方向的動作概率,以減少軌跡偏差。通過這種方式,RAD 為整個動作分布提供密集的指導(dǎo)信息,確保策略能夠更快學(xué)會安全合理的駕駛行為,從而加速訓(xùn)練的收斂。
閉環(huán)驗證
RAD 通過基于大規(guī)模 3DGS 的強(qiáng)化學(xué)習(xí)訓(xùn)練,學(xué)習(xí)到了更有效的駕駛策略。在相同的閉環(huán)評估基準(zhǔn)測試中,RAD 的碰撞率相較于傳統(tǒng)的模仿學(xué)習(xí)策略降低了 3 倍。這一結(jié)果表明,RAD 能在復(fù)雜的交通狀況下有效避免與動靜態(tài)障礙物的碰撞,做出更加安全、合理的決策。例如,在遇到突然闖入道路的行人或車輛時,RAD 能夠迅速做出準(zhǔn)確反應(yīng),及時調(diào)整車速和行駛方向,避免碰撞事故的發(fā)生,而模仿學(xué)習(xí)策略則可能難以應(yīng)對這種突發(fā)情況。 我們提供了一系列典型場景的閉環(huán)結(jié)果,以直觀展示 RAD 與模仿學(xué)習(xí)策略在實際駕駛場景中的關(guān)鍵差異:
場景1:繞行;右轉(zhuǎn)
場景2:U形掉頭
場景3:跟車蠕行
場景4:無保護(hù)左轉(zhuǎn)
場景5:擁擠路口通行
場景6:無保護(hù)左轉(zhuǎn)
場景7:繞行;窄道通行
場景8:無保護(hù)左轉(zhuǎn)
場景9:跟車行駛
后續(xù)工作
RAD作為創(chuàng)新的端到端自動駕駛后訓(xùn)練范式,具有廣闊的應(yīng)用前景和潛力。目前RAD仍存在一些局限性。例如,其他交通參與者的行為是基于場景回放,缺乏交互性的響應(yīng);在非剛性物體的渲染、欠觀測視角和低光照場景等方面,3DGS的效果還有提升的空間。在后續(xù)工作中,我們將進(jìn)一步提升3DGS孿生數(shù)字世界的真實性和交互性,并繼續(xù)探索強(qiáng)化學(xué)習(xí)scaling law的上限。
-
模型
+關(guān)注
關(guān)注
1文章
3751瀏覽量
52099 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
270瀏覽量
11967 -
地平線
+關(guān)注
關(guān)注
0文章
460瀏覽量
16342 -
算力
+關(guān)注
關(guān)注
2文章
1528瀏覽量
16740
原文標(biāo)題:開發(fā)者說|RAD:基于3DGS孿生數(shù)字世界的端到端強(qiáng)化學(xué)習(xí)后訓(xùn)練范式
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
什么是深度強(qiáng)化學(xué)習(xí)?深度強(qiáng)化學(xué)習(xí)算法應(yīng)用分析

深度強(qiáng)化學(xué)習(xí)實戰(zhàn)
將深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)相結(jié)合的深度強(qiáng)化學(xué)習(xí)DRL
人工智能機(jī)器學(xué)習(xí)之強(qiáng)化學(xué)習(xí)
如何構(gòu)建強(qiáng)化學(xué)習(xí)模型來訓(xùn)練無人車算法
研究人員開源RAD以改進(jìn)及強(qiáng)化智能學(xué)習(xí)算法
機(jī)器學(xué)習(xí)中的無模型強(qiáng)化學(xué)習(xí)算法及研究綜述

模型化深度強(qiáng)化學(xué)習(xí)應(yīng)用研究綜述

基于強(qiáng)化學(xué)習(xí)的虛擬場景角色乒乓球訓(xùn)練
《自動化學(xué)報》—多Agent深度強(qiáng)化學(xué)習(xí)綜述

ICLR 2023 Spotlight|節(jié)省95%訓(xùn)練開銷,清華黃隆波團(tuán)隊提出強(qiáng)化學(xué)習(xí)專用稀疏訓(xùn)練框架RLx2

端到端InfiniBand網(wǎng)絡(luò)解決LLM訓(xùn)練瓶頸

如何訓(xùn)練好自動駕駛端到端模型?

強(qiáng)化學(xué)習(xí)會讓自動駕駛模型學(xué)習(xí)更快嗎?




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論