 多智能體強化學習(MARL)核心概念與算法概覽
多智能體強化學習(MARL)核心概念與算法概覽

本文轉自:DeepHub IMBA
作者:Syntal
訓練單個 RL 智能體的過程非常簡單,那么我們現在換一個場景,同時訓練五個智能體,而且每個都有自己的目標、只能看到部分信息,還能互相幫忙。
這就是多智能體強化學習(Multi-Agent Reinforcement Learning,MARL),但是這樣會很快變得混亂。
什么是多智能體強化學習
MARL 是多個決策者(智能體)在同一環境中交互的強化學習。
環境類型可以很不一樣。競爭性的,比如國際象棋,一方贏一方輸。合作性的,比如團隊運動,大家共享目標。還有混合型的,更像現實生活——現在是隊友,過會兒可能是對手,有時候兩者同時存在。
但是這里有一個關鍵的問題:從任何一個智能體的視角看世界變成了非平穩的,因為其他智能體也在學習、在改變行為。也就是說在學規則的時候,規則本身也在變。
MARL 在現實中的位置
單智能體 RL 適合系統只有一個"大腦"的情況,而MARL 則出現在世界有多個"大腦"的時候。
現實世界中有很多這樣的案例,比如交通信號控制:每個路口是一個智能體,一個信號燈"貪婪"了,下游路口就會卡死;倉庫機器人:每個機器人自己選路徑,碰撞和擁堵天然是多智能體問題;廣告競價和市場:智能體用不斷變化的策略爭奪有限資源;網絡安全:攻擊者和防御者是相互適應的智能體對;在線游戲和模擬:協調、欺騙、配合、自我對弈——這些都是MARL 的經典試驗場。
核心概念
大多數真實場景中,智能體只能看到狀態的一部分。所以 MARL 里的策略通常基于局部觀測,而不是完整的全局狀態。
單智能體 RL 里環境動態是穩定的,而MARL 不一樣"環境"包括其他智能體。它們在學習,你的轉移動態也就跟著變了。
這正是經典的 Qlearn在多智能體環境里容易震蕩、甚至崩潰的原因。
合作任務中團隊拿到獎勵,但功勞該算誰的?團隊成功了,是智能體 2 的動作起了作用,還是智能體 5 在 10 步之前的作用?這就是信用分配問題,這是MARL 里最頭疼的實際難題之一。
集中式與分布式
集中訓練、分布式執行(CTDE)
這是目前最常見的模式。訓練時智能體可以用額外信息,比如全局狀態或其他智能體的動作。執行時每個智能體只根據自己的局部觀測行動。
這樣的好處是,既有集中學習的穩定性,又不需要在運行時獲取不現實的全局信息。
完全分布式學習
智能體只從局部經驗學習。這個聽起來是對的,而且簡單任務也能用。但實際中往往不夠穩定,合作任務尤其如此。
算法總覽
合作性基于價值的方法:Independent Q-Learning(IQL)是最簡單的基線,容易實現但通常不穩定;VDN 和 QMIX 通過混合各智能體的價值來學全局團隊價值,合作處理得更好。
策略梯度和 Actor-Critic 方法:MADDPG 用集中式 Critic 配分布式 Actor,概念上是很好的切入點;MAPPO 在很多合作任務里是靠譜的默認選擇。
自我對弈(Self-play):和自己不同版本對打來建立泛化的策略。思路簡單粗暴效果也很好。
用 Python 從零搭一個小 MARL 環境
來做個玩具游戲:兩個智能體必須協調。經典設定——兩者選同一個動作才有獎勵。每個智能體選 0 或 1,動作一致拿 +1,不一致拿 0。
我們這里刻意設計得簡單,這樣方便我們聚焦在 MARL 機制本身。
import random
from collections import defaultdict
class CoordinationGame:
def step(self, a0, a1):
reward = 1 if a0 == a1 else 0
done = True # single-step episode
return reward, done
接下來是最小化的 Independent Q-Learning 設置,每個智能體學自己的 Q 表。這里沒有狀態,Q 只取決于動作。
def epsilon_greedy(Q, eps=0.1):
if random.random() < eps: ?
return random.choice([0, 1])
return 0 if Q[0] >= Q[1] else 1
Q0 = defaultdict(float) # Q0[action]
Q1 = defaultdict(float) # Q1[action]
alpha = 0.1
eps = 0.2
env = CoordinationGame()
for episode in range(5000):
a0 = epsilon_greedy(Q0, eps)
a1 = epsilon_greedy(Q1, eps)
r, done = env.step(a0, a1)
# One-step update (no next-state)
Q0[a0] += alpha * (r - Q0[a0])
Q1[a1] += alpha * (r - Q1[a1])
# Inspect learned preferences
print("Agent0 Q:", dict(Q0))
print("Agent1 Q:", dict(Q1))
多數運行會收斂到兩種"慣例"之一:兩者都學會總是選 0,或者都學會總是選 1。
這就是協調從學習中涌現出來的樣子。雖然小但和大型合作 MARL 系統里依賴的模式是同一類東西。
這個玩具例子太友好了。難一點的任務里,IQL 常常變得不穩定,因為每個智能體都在追一個移動靶。
讓例子更"MARL"一點
常見技巧是加共享團隊獎勵,同時保證足夠長的探索期來發現協調,下面是一個帶衰減 epsilon 的訓練循環:
Q0 = defaultdict(float)
Q1 = defaultdict(float)
alpha = 0.1
eps = 0.9
eps_decay = 0.999
eps_min = 0.05
env = CoordinationGame()
for episode in range(20000):
a0 = epsilon_greedy(Q0, eps)
a1 = epsilon_greedy(Q1, eps)
r, _ = env.step(a0, a1)
Q0[a0] += alpha * (r - Q0[a0])
Q1[a1] += alpha * (r - Q1[a1])
eps = max(eps_min, eps * eps_decay)
print("Agent0 Q:", dict(Q0))
print("Agent1 Q:", dict(Q1))
這當然不會解決 MARL,但它演示了一個真實原則:早期探索幫助智能體"找到"一個穩定的協調慣例。
總結
一旦解決了單步協調問題,還會有三個問題會反復出現:
虛假學習信號:智能體可能覺得"是自己動作導致了獎勵",實際上是另一個智能體的動作起了作用。
糟糕的均衡陷阱:在競爭性游戲里,智能體可能卡在穩定但不強的弱策略上。
規模爆炸:多智能體的狀態和動作空間膨脹很快,需要更好的函數逼近(神經網絡)、更好的訓練方案(CTDE),通常還需要更講究的環境設計。
應對這些問題沒有萬能解法,但有一些經過驗證的思路。針對虛假學習信號,可以用 CTDE 架構讓 Critic 看到全局信息,幫助每個智能體更準確地評估自己動作的貢獻。均衡陷阱的問題,自我對弈加上一定的探索機制能幫智能體跳出局部最優。規模問題則需要參數共享、注意力機制等技術來降低復雜度。
實際項目中,建議先在概念上理解集中式 Critic 的工作原理,不用急著寫完整的深度 RL 代碼。這一步會改變你思考可觀測性和穩定性的方式,后面上手具體算法會順暢很多。
-
智能體
+關注
關注
1文章
534瀏覽量
11639 -
強化學習
+關注
關注
4文章
273瀏覽量
11994
發布評論請先 登錄
基于多智能體深度強化學習的體系任務分配方法
什么是強化學習?純強化學習有意義嗎?強化學習有什么的致命缺陷?

多智體深度強化學習研究中首次將概率遞歸推理引入AI的學習過程
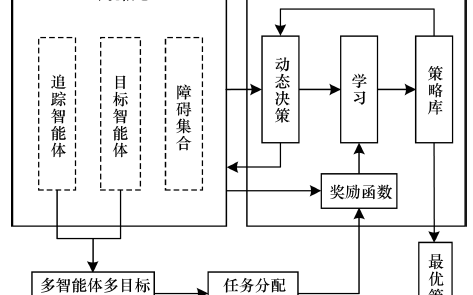
一種基于多智能體協同強化學習的多目標追蹤方法
《自動化學報》—多Agent深度強化學習綜述

強化學習的基礎知識和6種基本算法解釋
強化學習的基礎知識和6種基本算法解釋

基于強化學習的目標檢測算法案例
語言模型做先驗,統一強化學習智能體,DeepMind選擇走這條通用AI之路




 工商網監
工商網監
評論