") 大模型競(jìng)爭(zhēng)白熱化!智譜、MiniMax密集發(fā)布,DeepSeek V4路線圖曝光
大模型競(jìng)爭(zhēng)白熱化!智譜、MiniMax密集發(fā)布,DeepSeek V4路線圖曝光

2月11日晚間,智譜發(fā)布新一代旗艦?zāi)P虶LM-5,智譜稱,GLM-5在Coding與Agent能力上,取得開(kāi)源SOTA表現(xiàn),在真實(shí)編程場(chǎng)景的使用體感逼近Claude Opus 4.5,擅長(zhǎng)復(fù)雜系統(tǒng)工程與長(zhǎng)程Agent任務(wù)。
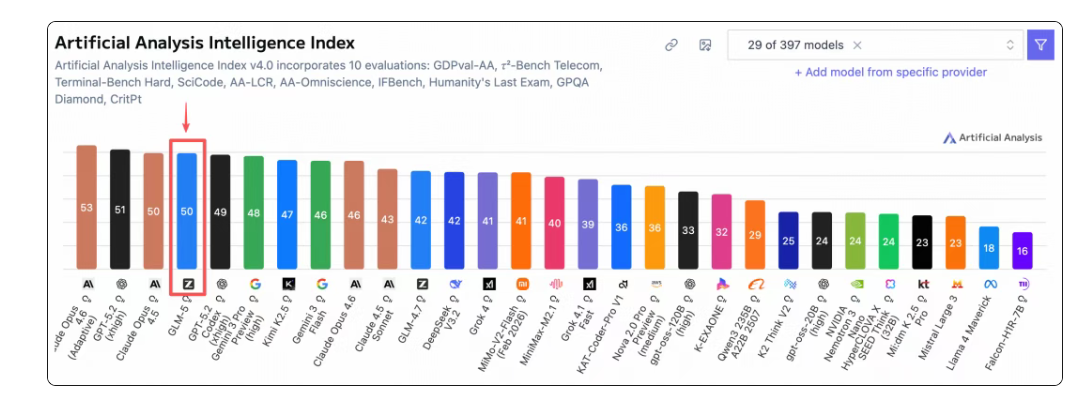
智譜宣布,在全球權(quán)威的 Artificial Analysis 榜單中,GLM-5 位居全球第四、開(kāi)源第一。GLM-5擁有744B(激活 40B)參數(shù)模型,預(yù)訓(xùn)練數(shù)據(jù)從 23T 提升至 28.5T,更大規(guī)模的預(yù)訓(xùn)練算力顯著提升了模型的通用智能水平。
GLM-5構(gòu)建全新的“Slime”框架,支持更大模型規(guī)模及更復(fù)雜的強(qiáng)化學(xué)習(xí)任務(wù),提升強(qiáng)化學(xué)習(xí)后訓(xùn)練流程效率;提出異步智能體強(qiáng)化學(xué)習(xí)算法,使模型能夠持續(xù)從長(zhǎng)程交互中學(xué)習(xí),充分激發(fā)預(yù)訓(xùn)練模型的潛力。在稀疏注意力機(jī)制方面,GLM-5首次集成 DeepSeek Sparse Attention,在維持長(zhǎng)文本效果無(wú)損的同時(shí),大幅降低模型部署成本,提升 Token Efficiency。
智譜稱,GLM-5在編程能力上實(shí)現(xiàn)了對(duì)Claude Opus 4.5的對(duì)齊,在主流基準(zhǔn)測(cè)試中取得開(kāi)源模型SOTA分?jǐn)?shù)。在SWE-bench-Verified和Terminal Bench 2.0中,GLM-5分別獲得77.8和56.2的開(kāi)源模型SOTA分?jǐn)?shù),性能超過(guò)Gemini 3 Pro。
GLM 系列模型受到全球開(kāi)發(fā)者喜愛(ài),在 GLM Coding Plan 全球爆量后,智譜公司不得不啟動(dòng)限售活動(dòng)。值得關(guān)注的是,GLM系列已經(jīng)完成已完成與華為昇騰、摩爾線程、寒武紀(jì)、昆侖芯、沐曦、燧原、海光等國(guó)產(chǎn)算力平臺(tái)的深度推理適配。通過(guò)底層算子優(yōu)化與硬件加速,GLM-5 在國(guó)產(chǎn)芯片集群上已經(jīng)實(shí)現(xiàn)高吞吐、低延遲的穩(wěn)定運(yùn)行。

2月12日,MiniMax宣布上線最新旗艦編程模型MiniMax M2.5,目前在模型界面已經(jīng)可以選擇調(diào)用。據(jù)官方介紹,這是一個(gè)為智能體場(chǎng)景原生設(shè)計(jì)的生產(chǎn)級(jí)模型,其編程與智能體性能對(duì)標(biāo)國(guó)際頂尖模型Claude Opus 4.6,支持PC、App、跨端應(yīng)用的全棧編程開(kāi)發(fā),尤其適配 Excel高階處理、深度調(diào)研、PPT等生產(chǎn)力場(chǎng)景。M2.5模型激活參數(shù)量為10B,在顯存占用和推理能效比上有優(yōu)勢(shì),推理速度超過(guò)國(guó)際頂尖模型。
預(yù)計(jì)2月中旬,DeepSeek將會(huì)發(fā)布新一代旗艦大模型V4,根據(jù)近期由創(chuàng)辦人梁文鋒署名的論文及業(yè)內(nèi)爆料,V4 將引入 mHC 與 Engram 兩項(xiàng)核心架構(gòu)創(chuàng)新,旨在顯著降低訓(xùn)練與推理成本,并在編程能力上挑戰(zhàn)目前的行業(yè)領(lǐng)導(dǎo)者。
在DeepSeek團(tuán)隊(duì)在最新發(fā)布的論文中提出,當(dāng)前模型缺乏原生的知識(shí)查找機(jī)制,導(dǎo)致在處理靜態(tài)知識(shí)時(shí)仍需耗費(fèi)昂貴的算力重復(fù)推導(dǎo)。為此,V4 預(yù)計(jì)將引入 Engram(條件記憶模塊),其設(shè)計(jì)理念是將“記憶”與“計(jì)算”解耦。
透過(guò) Engram 技術(shù),模型能將靜態(tài)知識(shí) (如實(shí)體、固定表達(dá)) 存儲(chǔ)在廉價(jià)的 DRAM 中,而非昂貴的 GPU 高帶寬內(nèi)存 (HBM)。當(dāng)模型需要推理時(shí)再快速查找,這將釋放 GPU 算力專(zhuān)注于復(fù)雜的動(dòng)態(tài)計(jì)算。此外,另一項(xiàng)關(guān)鍵技術(shù) mHC(流形約束超連接) 則解決了超深層 Transformer 模型在訓(xùn)練時(shí),信息流動(dòng)瓶頸與不穩(wěn)定的問(wèn)題,透過(guò)嚴(yán)苛的數(shù)學(xué)「護(hù)欄」,提升模型在數(shù)學(xué)推理等任務(wù)上的表現(xiàn)。
據(jù) 美國(guó)The Information 報(bào)導(dǎo),DeepSeek V4 的內(nèi)部初步測(cè)試顯示,其編程能力已超越市場(chǎng)上的頂級(jí)模型,包括 OpenAI 的 GPT 系列與 Anthropic 的 Claude。盡管 DeepSeek 先前推出的 V3.2 版本已在多項(xiàng)基準(zhǔn)檢驗(yàn)中超越部分競(jìng)爭(zhēng)對(duì)手,但 V4 被視為核心架構(gòu)的正式繼任者,旨在進(jìn)一步鞏固其作為高性能、低成本 AI 方案的地位。
當(dāng)下,大模型的競(jìng)爭(zhēng)已經(jīng)從卷開(kāi)源社區(qū),走向爭(zhēng)奪AI時(shí)代入口的升級(jí)階段。智譜此次發(fā)布新模型之后,大幅提價(jià),說(shuō)明國(guó)產(chǎn)模型的技術(shù)能力和市場(chǎng)競(jìng)爭(zhēng)力明顯提升。在大模型從“技術(shù)競(jìng)賽”轉(zhuǎn)向“商業(yè)兌現(xiàn)”的關(guān)鍵階段,誰(shuí)能通過(guò)開(kāi)源構(gòu)建起活躍的開(kāi)發(fā)者生態(tài),并將其轉(zhuǎn)化為可持續(xù)的收入流,誰(shuí)才真正贏得下一階段。
-
DeepSeek
+關(guān)注
關(guān)注
2文章
837瀏覽量
3355
發(fā)布評(píng)論請(qǐng)先 登錄
全球唯一?IBM更新量子計(jì)算路線圖:2029年交付!

昆侖萬(wàn)維天工AI大模型SkyReels V4登上Artificial Analysis榜單全球第一
沐曦曦云C500/C550 GPU產(chǎn)品深度適配MiniMax M2.5模型
大模型 ai coding 比較
投票總數(shù)超44萬(wàn)!星特杯投票進(jìn)入白熱化
天數(shù)智芯重磅公布四代架構(gòu)路線圖,對(duì)標(biāo)英偉達(dá)

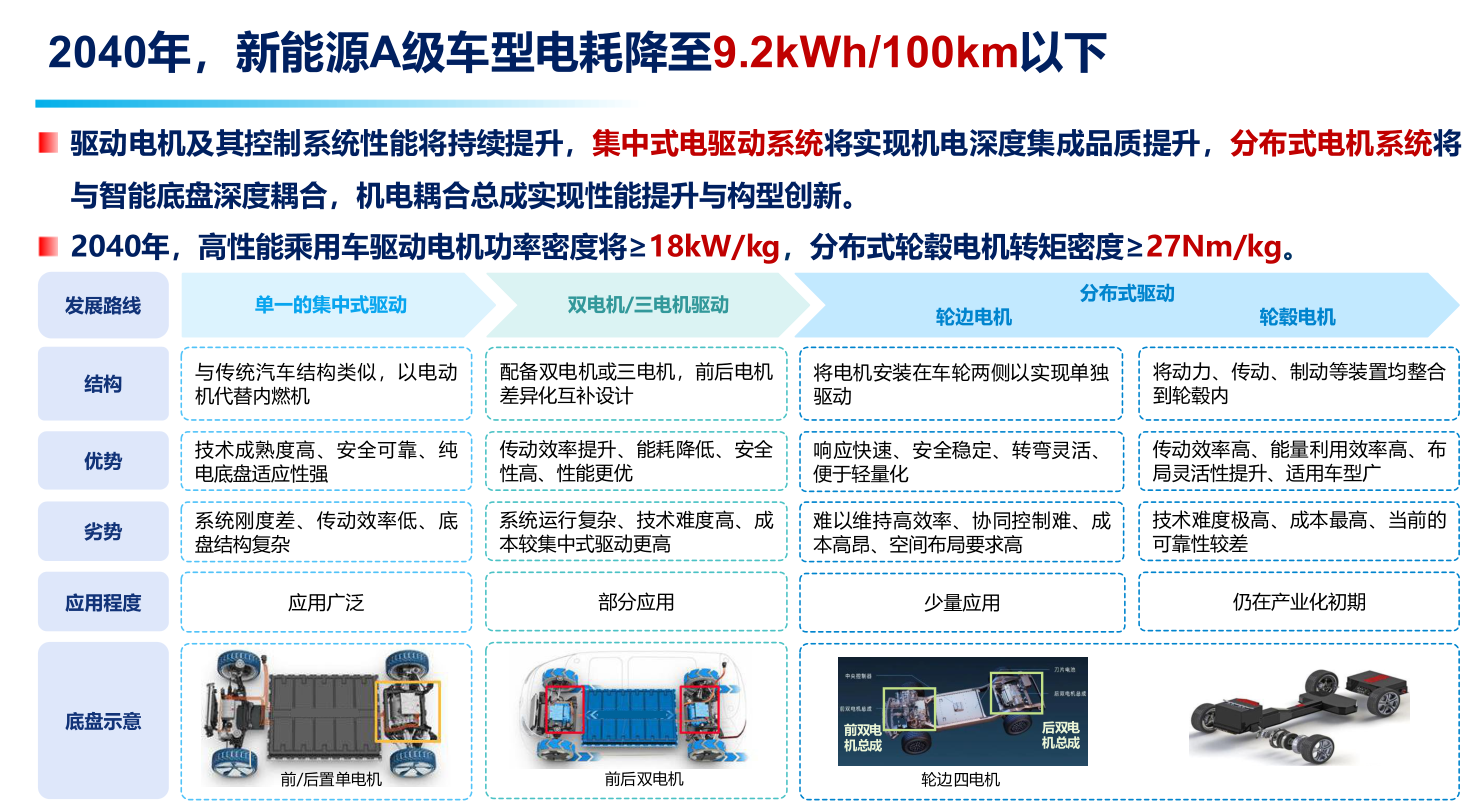
中國(guó)2040年汽車(chē)技術(shù)路線圖發(fā)布!內(nèi)燃機(jī)還能再戰(zhàn)15年?
納芯微參編節(jié)能與新能源汽車(chē)技術(shù)路線圖3.0正式發(fā)布
曦華科技參編節(jié)能與新能源汽車(chē)技術(shù)路線圖3.0正式發(fā)布
儲(chǔ)能戰(zhàn)略規(guī)劃:企業(yè)級(jí)儲(chǔ)能技術(shù)路線圖的制定方法與實(shí)踐指南




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論