") 如何訓練好自動駕駛端到端模型?
如何訓練好自動駕駛端到端模型?

[首發(fā)于智駕最前沿微信公眾號]最近有位小伙伴在后臺留言提問:端到端算法是怎樣訓練的?是模仿學習、強化學習和離線強化學習這三類嗎?其實端到端(end-to-end)算法在自動駕駛、智能體決策系統(tǒng)里,確實會用到模仿學習(包括行為克隆、逆最優(yōu)控制/逆強化學習等)、強化學習(RL),以及近年來越來越受關(guān)注的離線強化學習(OfflineRL/BatchRL)這三類。

什么是“端到端”訓練?
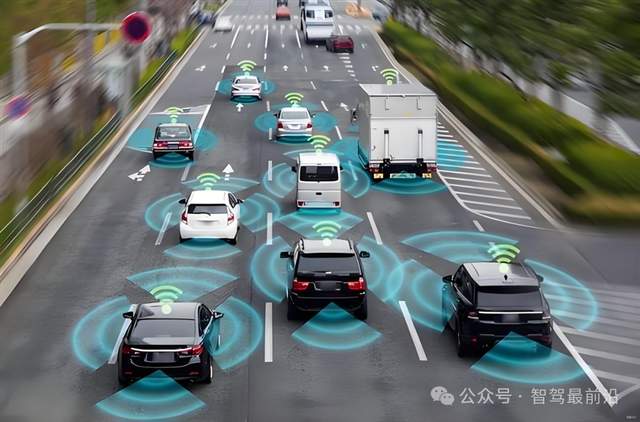
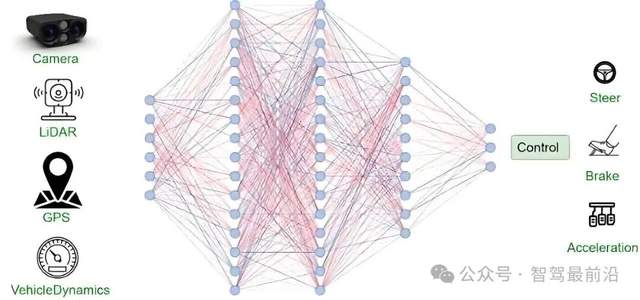
端到端(end-to-end)在自動駕駛中的應用越來越多,所謂端到端,就是指系統(tǒng)直接把最原始的感知輸入(比如攝像頭圖像、傳感器數(shù)據(jù)等)映射到最終控制輸出(比如車輛的轉(zhuǎn)向、加減速、剎車等動作)。不像傳統(tǒng)的自動駕駛把“感知→識別→規(guī)劃→控制”拆成好幾個模塊,每個模塊各自工作,端到端是把這些步驟合并到一個整體神經(jīng)網(wǎng)絡(luò)/模型。

端到端示意圖,圖片源自:網(wǎng)絡(luò)
這樣做的好處是流程簡單、模型整體可優(yōu)化、理論上可以在足夠多數(shù)據(jù)+合適訓練方法下能學到復雜映射邏輯。但對數(shù)據(jù)量、訓練方法、泛化能力要求較高。既然只要有足夠的數(shù)據(jù)就可以訓練出足夠聰明的端到端,那該用什么方式教它?這些方式又有什么優(yōu)缺點呢?

模仿學習(ImitationLearning)
模仿學習,也稱示范學習(learningfromdemonstration),是端到端訓練里最直觀、應用最廣的一類方法。它的核心思想是,假設(shè)你已經(jīng)有專家(人類駕駛員/經(jīng)驗控制系統(tǒng)/優(yōu)秀策略)做的一系列“狀態(tài)-動作”的示范,模型就可以根據(jù)這些示范去學習。
在模仿學習里,比較經(jīng)典的做法是行為克隆(BehaviorCloning,BC)。也就是把專家數(shù)據(jù)當成訓練集,把狀態(tài)作為輸入,把專家對應的動作作為“標簽/groundtruth”,用回歸或分類方式訓練網(wǎng)絡(luò)。
為了讓模型不只是簡單復制動作,還能理解“為什么”這么做,也會用到“逆最優(yōu)控制/逆強化學習”(
InverseOptimalControl/InverseReinforcementLearning,IRL)這類方式,這樣可以從專家行為中反推“獎勵函數(shù)”(即專家為什么做出這些動作、背后的目標是什么),然后再基于這個獎勵函數(shù)訓練policy。
圖片源自:網(wǎng)絡(luò)
優(yōu)點和挑戰(zhàn)
模仿學習/行為克隆最大的優(yōu)點就是簡單直接、數(shù)據(jù)利用高效。它可以將復雜的策略學習問題轉(zhuǎn)化為標準的監(jiān)督學習任務,從而充分利用大量高質(zhì)量的專家示范數(shù)據(jù),快速學會一個在數(shù)據(jù)分布內(nèi)表現(xiàn)合理的策略。在專家行為覆蓋充分、環(huán)境動態(tài)相對穩(wěn)定的場景下,這種方法能取得非常不錯的效果。
模仿學習/行為克隆帶來的問題也不少。模仿學習泛化能力與魯棒性較差,如果模型遇到專家示范里如罕見、危險或者極端情景(緊急剎車、非常規(guī)轉(zhuǎn)向、路況突變等等)等從未出現(xiàn)過的情況,模型因為訓練時沒見過類似場景,也沒有示范動作,可能無法判斷該怎么做。
行為克隆會忽略決策過程的“序列性/時序相關(guān)性”,它把每一幀狀態(tài)與動作當獨立樣本對待,而現(xiàn)實中動作之間高度相關(guān)、且一個動作會影響未來狀態(tài)。這樣做容易導致所謂的分布偏移問題,當系統(tǒng)因為一點錯誤偏離了專家軌跡,就可能越偏越遠。
強化學習(ReinforcementLearning)
端到端訓練中另一種廣泛使用的方法是強化學習(RL)。不同于模仿學習依賴專家示范/標簽數(shù)據(jù),RL是通過智能體(agent)與環(huán)境交互做動作、觀察結(jié)果、得到“獎勵”或“懲罰”,從而形成一個學習策略(policy),最終可以使長期累積的獎勵最大化。
當將強化學習與深度神經(jīng)網(wǎng)絡(luò)相結(jié)合,就發(fā)展出了深度強化學習(DeepRL/DRL)。DRL能夠直接將高維的原始感知輸入(如圖像、激光雷達點云)映射到動作或控制信號,從而實現(xiàn)從感知到?jīng)Q策的端到端學習。這種強大的表征和學習能力,使其在處理自動駕駛、機器人控制等具有復雜輸入和連續(xù)決策需求的任務時,展現(xiàn)出巨大的潛力。

圖片源自:網(wǎng)絡(luò)
優(yōu)點和挑戰(zhàn)
用強化學習訓練端到端模型,有一個明顯好處,那就是它理論上不依賴“專家示范”,而是通過“試錯+獎勵機制”,探索出一個新的,甚至是“專家都沒見過”的策略;在面對復雜、多變、動態(tài)環(huán)境時,有可能獲得比單純模仿更靈活、更強魯棒性的策略。
但想讓強化學習真的落地并不容易。對于RL來說,給出一個能真實反映安全、效率、舒適、法規(guī)等綜合目標的獎勵函數(shù)非常難。如果獎勵函數(shù)設(shè)計不合理,RL容易學出一些奇怪但獎勵高的策略。
RL的訓練過程還依賴大量與環(huán)境的交互和試錯,導致數(shù)據(jù)采集、仿真與訓練的計算成本和時耗都非常高。若直接在真實車輛上部署訓練,則會因為智能體在探索初期產(chǎn)生的策略極不穩(wěn)定,導致危險行為甚至事故的發(fā)生。即便在模擬器中訓練,也存在“模擬?真實”的差異(sim-to-realgap)。
端到端RL的可解釋性也比較差,因為神經(jīng)網(wǎng)絡(luò)內(nèi)部沒有清晰的人類可理解模塊(如“檢測行人→判斷優(yōu)先級→規(guī)劃軌跡→控制”),而是一整個黑箱映射。這樣在出現(xiàn)錯誤或異常行為時,很難追溯到具體的原因。

離線強化學習(OfflineRL/BatchRL)
近年來,有技術(shù)方案中提出離線強化學習(OfflineRL,也叫BatchRL)的方法,以解決將RL用于現(xiàn)實系統(tǒng)(自動駕駛、醫(yī)療、機器人)時面臨的安全/資源/實際交互等難題。離線RL的基本設(shè)定是不讓模型在訓練時與真實環(huán)境互動。而是先收集一批類似于專家示范數(shù)據(jù)或日志的歷史交互數(shù)據(jù),然后用這些靜態(tài)數(shù)據(jù)訓練一個策略。訓練過程中不再需要交互。
離線RL可被視為一種結(jié)合了數(shù)據(jù)驅(qū)動與策略優(yōu)化的混合方案。它既像模仿學習那樣利用靜態(tài)的歷史交互數(shù)據(jù)進行訓練,避免了在線試錯的安全風險與成本;同時又保留了傳統(tǒng)強化學習的核心機制,通過對數(shù)據(jù)中的狀態(tài)與動作價值進行估計與優(yōu)化,使策略能夠在已有數(shù)據(jù)的基礎(chǔ)上進一步提升性能。這種形式使得它能在保證安全的前提下,嘗試學習出比行為克隆更優(yōu)、更魯棒的策略。

圖片源自:網(wǎng)絡(luò)
優(yōu)點和挑戰(zhàn)
離線RL的最大優(yōu)勢是安全性和可用已有數(shù)據(jù),并可以減少對真實世界探索的依賴,對于自動駕駛、醫(yī)療、金融、機器人等高風險領(lǐng)域尤為適用。它將RL的潛力與現(xiàn)實約束結(jié)合起來,是一個很有前景的發(fā)展方向。
但因為其訓練時不能再探索新狀態(tài)/動作,只能依賴數(shù)據(jù)集中已有的狀態(tài)/動作組合,這就帶來“分布偏移”(distributionshift)的問題。也就是說,當訓練出來的策略在現(xiàn)實中使用時,可能遇到數(shù)據(jù)集中沒有覆蓋到的狀態(tài)/動作,從而表現(xiàn)不可靠。為了解決這個問題,有技術(shù)方案中提出引入各種約束/正則/不確定性懲罰/動作空間限制/模型-基方法等機制,從而約束模型行為。

其他學習方法
1)自監(jiān)督學習(Self-SupervisedLearning)
對于自動駕駛這種依賴大量視覺/傳感器數(shù)據(jù)的系統(tǒng),數(shù)據(jù)量極大,但手工標注不僅費時成本也高。于是有技術(shù)方案中引入自監(jiān)督學習思路,讓系統(tǒng)先從大量未標注的原始數(shù)據(jù)中學習有意義的特征/表示,再用于downstream的端到端控制/決策任務,這樣可以減少對人工標注的依賴。
2)“教師-學生”(Teacher-Student)/特權(quán)信息蒸餾
這種方法被稱為教師—學生框架。其采用分階段訓練的思路,先利用仿真或數(shù)據(jù)中才可獲得的信息(如精確地圖、物體真實狀態(tài)等),訓練一個強大的“教師”模型,使其掌握決策與規(guī)劃能力;接著訓練一個“學生”模型,它僅能使用實際車輛可獲取的傳感器輸入信息(如攝像頭圖像、雷達點云),通過模仿教師模型的決策輸出,間接學習到教師的推理能力。
這樣可以把現(xiàn)實中可獲取的信息+強模型決策能力結(jié)合起來,降低了直接從原始感知信號進行端到端策略學習的難度,是提升系統(tǒng)性能與可靠性的重要途徑。

圖片源自:網(wǎng)絡(luò)
3)混合/混合階段訓練(Hybrid/StagedTraining)
訓練端到端模型可以不單靠一種訓練方式,也可以組合多種方式,如先用模仿學習或自監(jiān)督學習做“預訓練/初始化”(
pre-training/behaviorcloning/feature-learning),然后再用強化學習或離線RL在此基礎(chǔ)上fine-tune/優(yōu)化策略。在這樣的“混合訓練pipeline”中,可以兼顧“模仿專家行為”的初步安全/合理性,以及“探索和優(yōu)化策略”的靈活性/魯棒性。
4)進化/進化式學習方法(如Neuroevolution)
除了基于梯度下降的反向傳播與強化學習,還有一種值得關(guān)注的技術(shù)路徑是進化算法在神經(jīng)網(wǎng)絡(luò)優(yōu)化中的應用,即神經(jīng)進化。該方法不依賴梯度計算,而是通過模擬自然進化中的種群生成、變異、交叉與適者生存機制,迭代地優(yōu)化網(wǎng)絡(luò)結(jié)構(gòu)、參數(shù)或行為策略。這種梯度無關(guān)的優(yōu)化方式,能夠處理不可導或獎勵稀疏的復雜環(huán)境,具備一定的魯棒性與探索優(yōu)勢。雖然在當前自動駕駛端到端系統(tǒng)中并非主流方案,但它為應對傳統(tǒng)方法難以解決的優(yōu)化問題提供了一種補充思路。

最后的話
對于端到端而言,訓練算法的選擇固然重要,但想讓車輛學會安全、可靠的駕駛能力,更取決于數(shù)據(jù)質(zhì)量、訓練策略、場景覆蓋與運行監(jiān)控等要素。這些因素有時會比模型結(jié)構(gòu)本身更重要。
審核編輯 黃宇
-
自動駕駛
+關(guān)注
關(guān)注
794文章
14926瀏覽量
180548
發(fā)布評論請先 登錄
自動駕駛端到端為什么會出現(xiàn)黑盒現(xiàn)象?

端到端智駕模擬軟件推薦:為什么aiSim是業(yè)界領(lǐng)先的自動駕駛模擬平臺?
端到端智駕模擬軟件推薦——為什么選擇Keymotek的aiSim?
自動駕駛中端到端仿真與基于規(guī)則的仿真有什么區(qū)別?
自動駕駛中“一段式端到端”和“二段式端到端”有什么區(qū)別?
西井科技端到端自動駕駛模型獲得國際認可
一文讀懂特斯拉自動駕駛FSD從輔助到端到端的演進
端到端自動駕駛相較傳統(tǒng)自動駕駛到底有何提升?
Nullmax端到端自動駕駛最新研究成果入選ICCV 2025
為什么自動駕駛端到端大模型有黑盒特性?

端到端數(shù)據(jù)標注方案在自動駕駛領(lǐng)域的應用優(yōu)勢
一文帶你厘清自動駕駛端到端架構(gòu)差異
自動駕駛中基于規(guī)則的決策和端到端大模型有何區(qū)別?



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論